在实际项目开发中,从稳定性和效率的角度考虑,重复造轮子是不被提倡的。但是,自己在学习过程中造轮子绝对是对自己百利而无一害的,造轮子是一种特别能够提高自己系统编程能力的手段。
今天分享几个我常用的开源工具库:
1、MyExcel: 功能全面的 Excel 处理工具,内存占用低,性能也很优秀。
2、OSHI:一款为 Java 语言提供的基于 JNA 的(本机)操作系统和硬件信息库。
3、JsonPath:读取 JSON 的 Java DSL
4、Caffeine:强大的本地缓存
5、Hutool:超全的 Java 工具库
以下是较为详细一点的介绍,建议小伙伴们看完,方便自己快速上手,用在自己的项目中来提高生产效率。
MyExcel:Excel 处理
项目介绍
EasyExcel 大家应该都不陌生,这是阿里开源的一款 Excel 处理工具,可以避免大文件内存溢出问题,我之前也推荐过几次这个项目。
MyExcel 也是一个 Excel 处理工具,同样可以避免大文件内存溢出问题,并且功能更全面,内存占用更低,性能也更优秀(根据官方测试对比结果得出)。
根据项目 wiki 中的测试数据:
24.3M Excel,50 万行,8 列,循环 40 次读取,内存平均占用约 75 兆左右,与阿里 EasyExcel(V2.1.6)同文件测试对比,内存占用约为 MyExcel 的三分之一

MyExcel和EasyExcel内存占用对比
MyExcel 的核心优势如下:

MyExcel 的核心优势
依赖信息
Maven 仓库地址:https://mvnrepository.com/artifact/com.github.liaochong/myexcel 。
Maven :
<dependency>
<groupId>com.github.liaochong</groupId>
<artifactId>myexcel</artifactId>
<version>4.3.0.RC4</version>
</dependency>
Gradle :
implementation 'com.github.liaochong:myexcel:4.3.0.RC4'
功能演示
MyExcel 的功能比较多,这里只挑选个别介绍,详细介绍可以查看官方 wiki:https://github.com/liaochong/myexcel/wiki 。
1、流式导出
MyExcel 支持流式导出,采用生产者消费者模式,允许分批获取数据,内存占用极低。另外,流式导出支持 zip 压缩包等独有特性。
DefaultStreamExcelBuilder<ArtCrowd> streamExcelBuilder = DefaultStreamExcelBuilder
.of(ArtCrowd.class) // 如导出Map类型数据,请使用of(Map.class)
.threadPool(Executors.newFixedThreadPool(10))// 线程池,可选
.templateHandler(FreemarkerTemplateHandler.class)// 追加模板数据,可选,适合极度个性化数据导出
.capacity(10_000)// 容量设定,在主动划分excel使用,可选
.start();
2、自定义样式
MyExcel 支持自定义样式,包含宽度、高度、背景色、边框、字体等样式的调整,具体介绍请参考:https://github.com/liaochong/myexcel/wiki/Style-support 。
标题(title)样式自定义:
ExcelColumn(style={"title->color:red","cell->color:green"})
Integer age;
内容行样式自定义:
@ExcelColumn(style="cell->color:green")
Integer age;
方法调用设定样式:
DefaultExcelBuilder.of(ArtCrowd.class)
.style("title->color:red","background-color:green;")
.build(dataList);
3、下拉列表
MyExcel 支持生成下拉列表,只需要传入 List 或者 Array 参数即可。
@ExcelColumn(title="下拉列表")
List<String> options;
相关地址
-
项目地址:https://github.com/liaochong/myexcel
-
官方文档:https://github.com/liaochong/myexcel/wiki
OSHI:本机信息获取

项目介绍
OSHI 是一款为 Java 语言提供的基于 JNA 的(本机)操作系统和硬件信息库。
[JNA(Java Native Access)](https://github.com/java-native-access/jna "JNA(Java Native Access "JNA(Java Native Access)")")是一个开源的 Java 框架,是 Sun 公司推出的一种调用本地方法的技术,是建立在经典的 JNI 基础之上的一个框架。之所以说它是 JNI 的替代者,是因为 JNA 大大简化了调用本地方法的过程,使用很方便,基本上不需要脱离 Java 环境就可以完成。
JNI (Java Native Interface)即 Java 本地接口,它建立了 Java 与其他编程语言的桥梁,允许 Java 程序调用其他语言(尤其是 C/C++ )编写的程序或者代码库。并且, JDK 本身的实现也大量用到 JNI 技术来调用本地 C 程序库。
通过 OSHI ,我们不需要安装任何其他本机库,就能查看内存和 CPU 使用率、磁盘和分区使用情况、设备、传感器等信息。
OSHI 旨在提供一种跨平台的实现来检索系统信息,支持 Windows、Linux、MacOS、Unix 等主流操作系统。
官方是这样介绍 oshi 的:(翻译 Chrome 插件:Mate Translate):
使用 oshi 你可以轻松制作出项目常用的系统监控功能,如下图所示:

依赖信息
Maven 仓库地址:https://mvnrepository.com/artifact/com.github.oshi/oshi-core 。
Maven:
<dependency>
<groupId>com.github.oshi</groupId>
<artifactId>oshi-parent</artifactId>
<version>6.4.1</version>
<type>pom</type>
</dependency>
Gradle:
implementation 'com.github.oshi:oshi-core:6.4.1'
功能演示
获取硬件信息对象HardwareAbstractionLayer :
//系统信息
SystemInfo si = new SystemInfo();
//操作系统信息
OperatingSystem os = si.getOperatingSystem();
//硬件信息
HardwareAbstractionLayer hal = si.getHardware();
// 磁盘信息
List<HWDiskStore> diskStores = hal.getDiskStores();
有了代表硬件信息的对象HardwareAbstractionLayer 之后,我们就可以获取硬件相关的信息了!
下面简单演示一下获取内存和 CPU 相关信息。
1、获取内存相关信息
//内存相关信息
GlobalMemory memory = hal.getMemory();
//获取内存总容量
String totalMemory = FormatUtil.formatBytes(memory.getTotal());
//获取可用内存的容量
String availableMemory = FormatUtil.formatBytes(memory.getAvailable());
有了内存总容量和内存可用容量,你就可以计算出当前内存的利用率了。
2、获取 CPU 相关信息
//CPU相关信息
CentralProcessor processor = hal.getProcessor();
//获取CPU名字
String processorName = processor.getProcessorIdentifier().getName();
//获取物理CPU数
int physicalPackageCount = processor.getPhysicalPackageCount();
//获取物理核心数
int physicalProcessorCount = processor.getPhysicalProcessorCount();
相关地址
-
项目地址:https://github.com/oshi/oshi
-
官网:https://www.oshi.ooo/
JsonPath:读取 JSON 的 Java DSL
项目介绍
JsonPath 一种面向 JSON 结构的查询语言。相当于 XPATH 对于 XML、SQL 对于关系型数据库,它们都是比较通用的 DSL 。
JsonPath 提供了多种语言的实现版本,包括:Java、Javascript、Python、PHP、Ruby、Go 等。我们这里以 Java 版本的实现为例。
依赖信息
Maven 仓库地址:https://mvnrepository.com/artifact/com.jayway.jsonpath/json-path 。
Maven:
<dependency>
<groupId>com.jayway.jsonpath</groupId>
<artifactId>json-path</artifactId>
<version>2.8.0</version>
</dependency>
Gradle:
implementation 'com.jayway.jsonpath:json-path:2.8.0'
功能演示
测试 json 文档内容如下:
{
"store": {
"book": [
{
"category": "reference",
"author": "Nigel Rees",
"title": "Sayings of the Century",
"price": 8.95
},
{
"category": "fiction",
"author": "Evelyn Waugh",
"title": "Sword of Honour",
"price": 12.99
},
{
"category": "fiction",
"author": "Herman Melville",
"title": "Moby Dick",
"isbn": "0-553-21311-3",
"price": 8.99
},
{
"category": "fiction",
"author": "J. R. R. Tolkien",
"title": "The Lord of the Rings",
"isbn": "0-395-19395-8",
"price": 22.99
}
],
"bicycle": {
"color": "red",
"price": 19.95
}
},
"expensive": 10
}
读取所有书籍的作者:
List<String> authors = JsonPath.read(json, "$.store.book[*].author");
读取所有书籍并过滤:
// 所有价格低于 10 的书籍
List<Map<String, Object>> books = JsonPath.parse(json)
.read("$.store.book[?(@.price < 10)]");
// 也可以通过 Filter API 来进行过滤
Filter cheapFictionFilter = filter(
where("category").is("fiction").and("price").lte(10D)
);
List<Map<String, Object>> books = JsonPath.parse(json).read("$.store.book[?]", cheapFictionFilter);
相关地址
-
项目地址:https://github.com/json-path/JsonPath
-
JSONPath 介绍:https://goessner.net/articles/JsonPath/
Caffeine:强大的本地缓存
项目介绍
Caffeine 是我最常用的一款本地缓存,类似于 ConcurrentMap,但提供缓存功能更全面,性能也非常强悍。
性能有多牛呢?官方文档的基准测试中已经给出了详细的答案,地址:https://github.com/ben-manes/caffeine/wiki/Benchmarks 。
下图是 8 线程 对一个配置了最大容量的缓存进行并发读和写,常见的本地缓存实现方案的性能对比。
并发读:
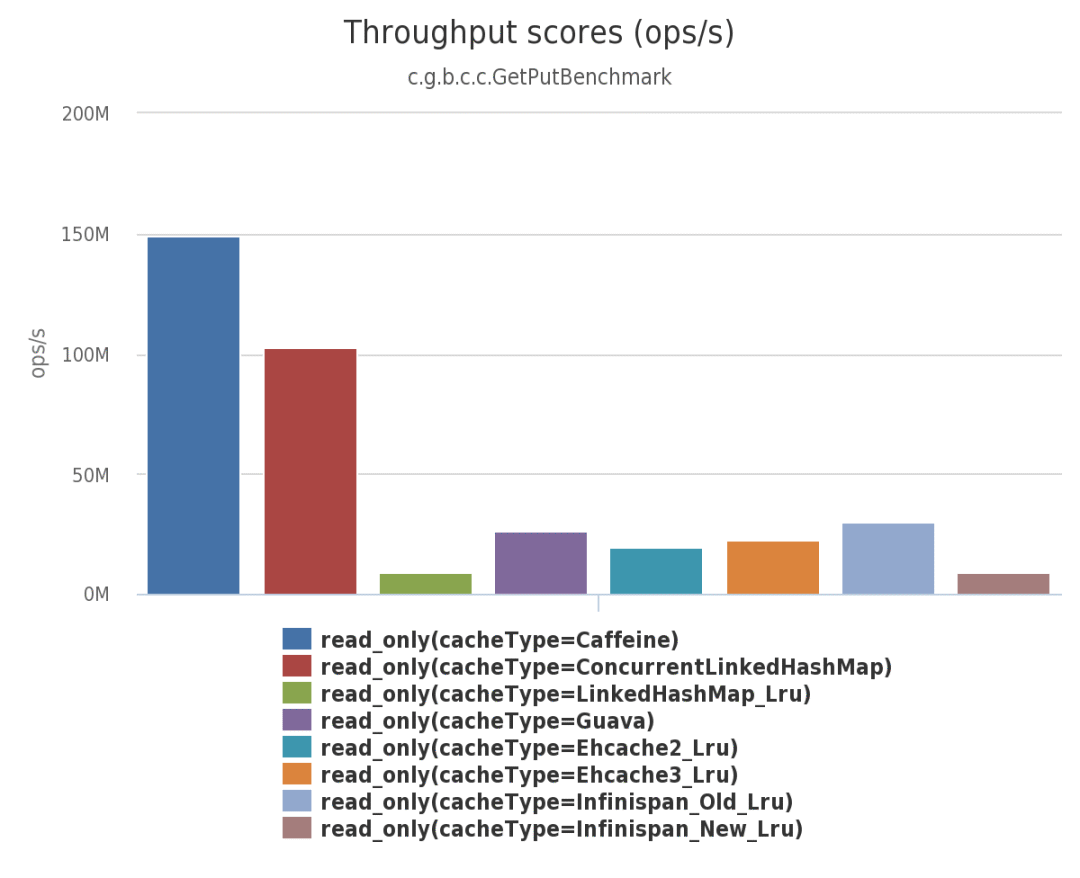
常见本地缓存并发读性能对比
并发写:
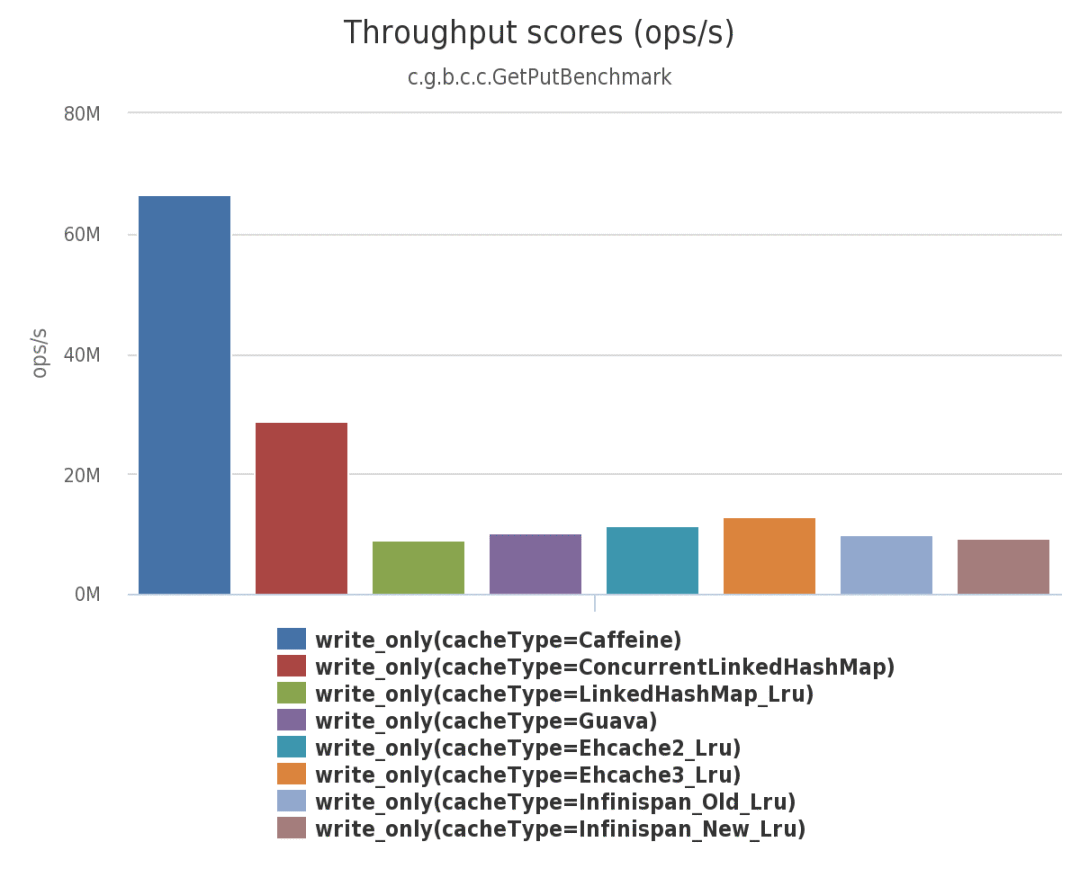
常见本地缓存并发写性能对比
除了基本的缓存功能之外,Caffeine 还提供了过期、异步加载等功能。
Caffeine 算的上是本地缓存的最佳选择,像 Redisson、Cassandra、Hbase、Neo4j、Druid 等知名开源项目都用到了 Caffeine。
依赖信息
Maven 仓库地址:https://mvnrepository.com/artifact/com.github.ben-manes.caffeine/caffeine 。
Java 11 及以上版本使用 3.x ,否则使用2.x。
Maven:
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
<version>3.1.5</version>
</dependency>
Gradle:
implementation 'com.github.ben-manes.caffeine:caffeine:3.1.5'
功能演示
Caffeine 和 API 和 Guava 很像,借鉴了 Guava 的设计。
创建缓存:
Cache<Key, Graph> cache = Caffeine.newBuilder()
.expireAfterWrite(10, TimeUnit.MINUTES)
.maximumSize(10_000)
.build();
手动移除缓存:
// 单个key
cache.invalidate(key)
// 批量key
cache.invalidateAll(keys)
// 所有key
cache.invalidateAll()
统计:
// 统计缓存命中率、缓存回收数量、加载新值的平均时间
Cache<String, Object> cache = Caffeine.newBuilder()
.maximumSize(10_000)
.recordStats()
.build();
相关地址
-
项目地址:https://github.com/ben-manes/caffeine
-
官方文档:https://github.com/ben-manes/caffeine/wiki
Hutool:超全的 Java 工具库

项目介绍
Hutool 是一个非常使用的 Java 工具类库,对文件、流、加密解密、转码、正则、线程、XML 等 JDK 方法进行了封装。
真心是一个不错的工具库,功能全面,非常适合在自己的项目中使用。
官方是这样介绍 Hutool 的:

Hutool 介绍
依赖信息
Maven 仓库地址:https://mvnrepository.com/artifact/cn.hutool/hutool-all 。
Maven:
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.16</version>
</dependency>
Gradle:
implementation 'cn.hutool:hutool-all:5.8.16'
功能演示
简单演示几个个人觉得比较实用的功能。
类型转换
Convert 类封装了针对 Java 常见类型的转换。
long[] b = {1,2,3,4,5};
String bStr = Convert.toStr(b);//"[1, 2, 3, 4, 5]"
double a = 67556.32;
String digitUppercase = Convert.digitToChinese(a);//"陆万柒仟伍佰伍拾陆元叁角贰分"
邮件
在 Java 中发送邮件主要品依靠 javax.mail 包,但是由于使用比较繁琐,因此 Hutool 针对其做了封装。
在 classpath(在标准 Maven 项目中为src/main/resources)的 config 目录下新建mail.setting文件,完整配置如下(邮件服务器必须支持并打开 SMTP 协议):
# 邮件服务器的SMTP地址,可选,默认为smtp.<发件人邮箱后缀>
host = smtp.yeah.net
# 邮件服务器的SMTP端口,可选,默认25
port = 25
# 发件人(必须正确,否则发送失败)
from = hutool@yeah.net
# 用户名,默认为发件人邮箱前缀
user = hutool
# 密码(注意,某些邮箱需要为SMTP服务单独设置授权码,详情查看相关帮助)
pass = q1w2e3
发送邮件非常简单:
MailUtil.send("hutool@foxmail.com", "测试", "邮件来自Hutool测试", false);
支持群发:
ArrayList<String> tos = CollUtil.newArrayList(
"person1@bbb.com",
"person2@bbb.com",
"person3@bbb.com",
"person4@bbb.com");
MailUtil.send(tos, "测试", "邮件来自Hutool群发测试", false);
支持添加一个或者多个附件:
MailUtil.send("hutool@foxmail.com", "测试", "<h1>邮件来自Hutool测试</h1>", true, FileUtil.file("d:/aaa.xml"));
除了使用配置文件定义全局账号以外,MailUtil.send方法同时提供重载方法可以传入一个MailAccount对象,这个对象为一个普通 Bean,记录了邮件服务器信息。
MailAccount account = new MailAccount();
account.setHost("smtp.yeah.net");
account.setPort("25");
account.setAuth(true);
account.setFrom("hutool@yeah.net");
account.setUser("hutool");
account.setPass("q1w2e3");
MailUtil.send(account, CollUtil.newArrayList("hutool@foxmail.com"), "测试", "邮件来自Hutool测试", false);
唯一 ID
在分布式环境中,唯一 ID 生成应用十分广泛,生成方法也多种多样,Hutool 针对一些常用生成策略做了简单封装。
Hutool 提供的唯一 ID 生成器的工具类,涵盖了:
-
UUID
-
ObjectId(MongoDB)
-
Snowflake(Twitter)
拿 UUID 举例!
Hutool 重写java.util.UUID的逻辑,对应类为cn.hutool.core.lang.UUID,使生成不带-的 UUID 字符串不再需要做字符替换,性能提升一倍左右。
//生成的UUID是带-的字符串,类似于:a5c8a5e8-df2b-4706-bea4-08d0939410e3
String uuid = IdUtil.randomUUID();
//生成的是不带-的字符串,类似于:b17f24ff026d40949c85a24f4f375d42
String simpleUUID = IdUtil.simpleUUID();
HTTP 请求工具类
针对最为常用的 GET 和 POST 请求,HttpUtil 封装了两个方法,
-
HttpUtil.get -
HttpUtil.post
GET 请求:
// 最简单的HTTP请求,可以自动通过header等信息判断编码,不区分HTTP和HTTPS
String result1= HttpUtil.get("https://www.baidu.com");
// 当无法识别页面编码的时候,可以自定义请求页面的编码
String result2= HttpUtil.get("https://www.baidu.com", CharsetUtil.CHARSET_UTF_8);
//可以单独传入http参数,这样参数会自动做URL编码,拼接在URL中
HashMap<String, Object> paramMap = new HashMap<>();
paramMap.put("city", "北京");
String result3= HttpUtil.get("https://www.baidu.com", paramMap);
POST 请求:
HashMap<String, Object> paramMap = new HashMap<>();
paramMap.put("city", "北京");
String result= HttpUtil.post("https://www.baidu.com", paramMap);
文件上传:
HashMap<String, Object> paramMap = new HashMap<>();
//文件上传只需将参数中的键指定(默认file),值设为文件对象即可,对于使用者来说,文件上传与普通表单提交并无区别
paramMap.put("file", FileUtil.file("D:\\face.jpg"));
String result= HttpUtil.post("https://www.baidu.com", paramMap);
缓存
Hutool 提供了常见的几种缓存策略的实现:
-
FIFO(first in first out) :先进先出策略。
-
LFU(least frequently used) :最少使用率策略。
-
LRU(least recently used) :最近最久未使用策略。
-
Timed :定时策略。
-
Weak :弱引用策略。
并且,Hutool 还支持将小文件以 byte[] 的形式缓存到内容中,减少文件的访问,以解决频繁读取文件引起的性能问题。
FIFO(first in first out) 策略缓存使用:
Cache<String,String> fifoCache = CacheUtil.newFIFOCache(3);
//加入元素,每个元素可以设置其过期时长,DateUnit.SECOND.getMillis()代表每秒对应的毫秒数,在此为3秒
fifoCache.put("key1", "value1", DateUnit.SECOND.getMillis() * 3);
fifoCache.put("key2", "value2", DateUnit.SECOND.getMillis() * 3);
fifoCache.put("key3", "value3", DateUnit.SECOND.getMillis() * 3);
//由于缓存容量只有3,当加入第四个元素的时候,根据FIFO规则,最先放入的对象将被移除
fifoCache.put("key4", "value4", DateUnit.SECOND.getMillis() * 3);
//value1为null
String value1 = fifoCache.get("key1");
控制台打印封装
一般情况下,我们打印信息到控制台小伙伴们应该再熟悉不过了!
System.out.println("Hello World");
但是,这种方式不满足很多场景的需要:
-
不支持参数,对象打印需要拼接字符串
-
不能直接打印数组,需要手动调用
Arrays.toString
为此,Hutool 封装了Console对象。
Console对象的使用更加类似于 Javascript 的console.log()方法,这也是借鉴了 JS 的一个语法糖。
String[] a = {"java", "c++", "c"};
Console.log(a);//控制台输出:[java, c++, c]
Console.log("This is Console log for {}.", "test");//控制台输出:This is Console log for test.
加密解密
Hutool 支持对称加密、非对称加密、摘要加密、消息认证码算法、国密。
这里以国密为例,Hutool 针对Bouncy Castle做了简化包装,用于实现国密算法中的 SM2、SM3、SM4。
国密算法需要引入Bouncy Castle库的依赖:
<dependency>
<groupId>org.bouncycastle</groupId>
<artifactId>bcprov-jdk15to18</artifactId>
<version>1.69</version>
</dependency>
SM2 使用自定义密钥对加密或解密 :
String text = "JavaGuide:一份涵盖大部分 Java 程序员所需要掌握的核心知识。准备 Java 面试,首选 JavaGuide!";
System.out.println("原文:" + text);
KeyPair pair = SecureUtil.generateKeyPair("SM2");
// 公钥
byte[] privateKey = pair.getPrivate().getEncoded();
// 私钥
byte[] publicKey = pair.getPublic().getEncoded();
SM2 sm2 = SmUtil.sm2(privateKey, publicKey);
// 公钥加密,私钥解密
String encryptStr = sm2.encryptBcd(text, KeyType.PublicKey);
System.out.println("加密后:" + encryptStr);
String decryptStr = StrUtil.utf8Str(sm2.decryptFromBcd(encryptStr, KeyType.PrivateKey));
System.out.println("解密后:" + decryptStr);
SM2 签名和验签 :
//加签
String sign = sm2.signHex(HexUtil.encodeHexStr(text));
System.out.println("签名:" + sign);
//验签
boolean verify = sm2.verifyHex(HexUtil.encodeHexStr(text), sign);
System.out.println("验签:" + verify);
线程池
Hutool 支持使用建造者的模式创建自定义线程池,这样看着更加清晰。
private static ExecutorService pool = ExecutorBuilder.create()
.setCorePoolSize(10)//初始池大小
.setMaxPoolSize(20) //最大池大小
.setWorkQueue(new LinkedBlockingQueue<>(100))//最大等待数为100
.setThreadFactory(ThreadFactoryBuilder.create().setNamePrefix("IM-Pool-").build())// 线程池命名
.build();
实际项目中,如果一个对象的属性比较多,有限考虑使用建造者模式创建对象。
并且,Hutool 还提供一个全局的线程池,默认所有异步方法在这个线程池中执行。
-
ThreadUtil.execute: 直接在公共线程池中执行线程 -
ThreadUtil.execAsync: 执行异步方法 -
......
Hutool 自身就大量用到了 ThreadUtil,比如敏感词工具类 SensitiveUtil:
public static void init(final Collection<String> sensitiveWords, boolean isAsync){
if(isAsync){
// 异步初始化敏感词树
ThreadUtil.execAsync(new Callable<Boolean>(){
@Override
public Boolean call() throws Exception {
init(sensitiveWords);
return true;
}
});
}else{
// 同步初始化敏感词树
init(sensitiveWords);
}
}
相关地址
-
项目地址:https://github.com/dromara/hutool
-
官网:https://hutool.cn/
后记
Java 的一大优势就是生态特别好, 包含了许多好用的工具类库和框架,几乎覆盖了所有的需求场景。很多事情我们完全不需要自己从头开始做,利用现有的稳定可靠的工具类库可以大大提高开发效率。
比如 Excel 文档处理,你可以考虑下面这几个开源的工具类库:
-
easyexcel[1] :快速、简单避免 OOM 的 Java 处理 Excel 工具。
-
excel-streaming-reader[2]:Excel 流式代码风格读取工具(只支持读取 XLSX 文件),基于 Apache POI 封装,同时保留标准 POI API 的语法。
-
myexcel[3]:一个集导入、导出、加密 Excel 等多项功能的工具包。
再比如 PDF 文档处理:
-
pdfbox[4] :用于处理 PDF 文档的开放源码 Java 工具。该项目允许创建新的 PDF 文档、对现有文档进行操作以及从文档中提取内容。PDFBox 还包括几个命令行实用程序。PDFBox 是在 Apache 2.0 版许可下发布的。
-
OpenPDF[5]:OpenPDF 是一个免费的 Java 库,用于使用 LGPL 和 MPL 开源许可创建和编辑 PDF 文件。OpenPDF 基于 iText 的一个分支。
-
itext7[6]:iText 7 代表了想要利用利用好 PDF 的开发人员的更高级别的 sdk。iText 7 配备了更好的文档引擎、高级和低级编程功能以及创建、编辑和增强 PDF 文档的能力,几乎对每个工作流都有好处。
-
FOP[7] :Apache FOP 项目的主要的输出目标是 PDF。
我的网站上总结了 Java 开发常用的一些工具类库,可以作为参考:https://javaguide.cn/open-source-project/tool-library.html 。

参考资料
[1]
easyexcel: https://github.com/alibaba/easyexcel
[2]
excel-streaming-reader: https://github.com/monitorjbl/excel-streaming-reader
[3]
myexcel: https://github.com/liaochong/myexcel
[4]
pdfbox: https://github.com/apache/pdfbox
[5]
OpenPDF: https://github.com/LibrePDF/OpenPDF
[6]
itext7: https://github.com/itext/itext7
[7]
FOP: https://xmlgraphics.apache.org/fop/