python获取知乎热搜数据
- 一、获取目标、准备工作
- 二、开始编码
- 三、总结
一、获取目标、准备工作
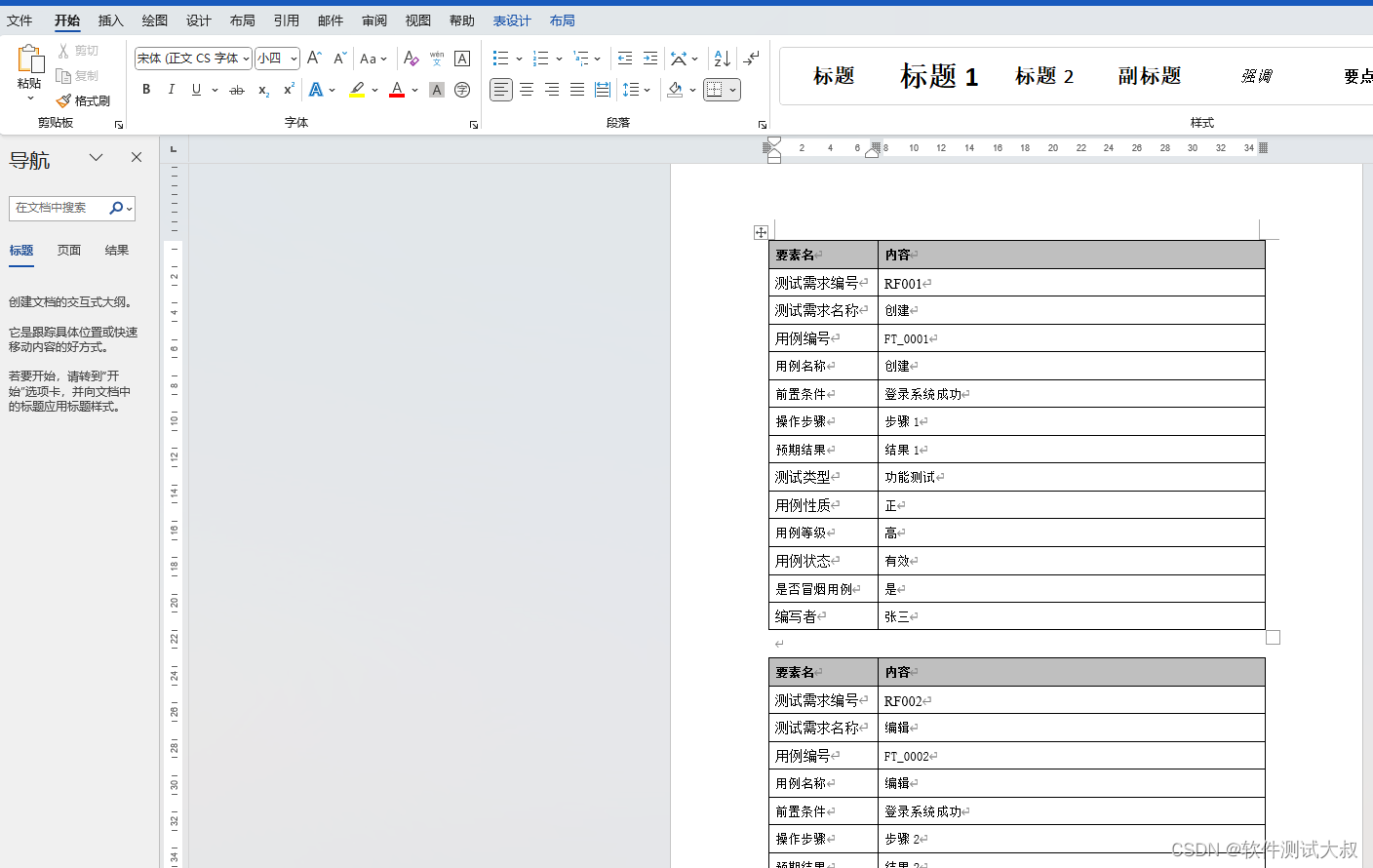
1、获取目标: 本次获取教程目标:某乎热搜
2、准备工作
- 环境python3.x
- requests
- pandas
requests跟pandas为本次教程所需的库,requests用于模拟http请求,pandas用于数据处理(将结果保存为Excel)。
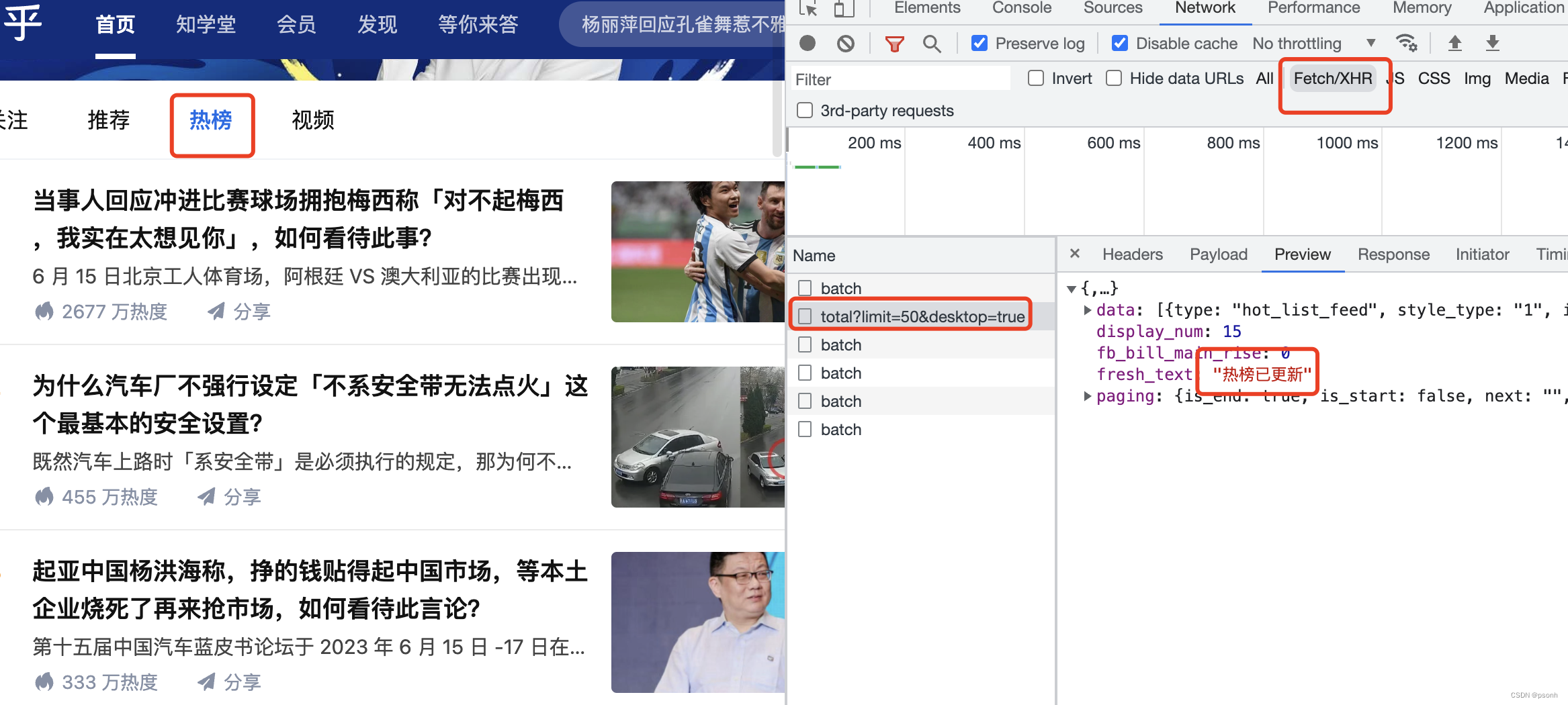
- 在Chrome浏览器中打开需要请求的页面,然后F12打开浏览器的控制台。点击Network选择网络,然后再点击XHR。找到相应的XHR请求,就能获取到热搜数据接口了。
二、开始编码
- 导入所依赖的库
import requests
import pandas as pd
- 构造一个请求头:
browse_header = {
"Accept": "application/json, text/plain, */*",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.60 Safari/537.36",
"Host": "www.zhihu.com",
"Referer": "https://www.zhihu.com/hot",
"Cookie": "_xsrf=Pd0NpG6J8kZdHtzBVnNyQP1g0rO7NKeg; _zap=d7f27b9f-4fe3-4ef4-9376-df278af16940;"
}
- 定义一个请求接口,即数据地址
url = "https://www.zhihu.com/api/v3/feed/topstory/hot-lists/total?limit=50&desktop=true"
- 发送请求,由于接口返回的是JSON格式,所以这里一步到位,将响应结果也转成JSON格式。
json = requests.get(url, headers=browse_header).json()
- 提取热搜数据列表。
# 热搜列表
content_list = res['data']
- 然后再分别进行json解析,对应的字段(标题、排名、热搜指数、描述、链接地址)。
df = pd.DataFrame( # 拼装爬取到的数据为DataFrame
{
'热搜标题': title_list,
'热搜排名': order_list,
'热搜指数': score_list,
'描述': desc_list,
'链接地址': url_list
}
)
df.to_excel('百度热搜榜.xlsx', index=False) # 保存结果数据
注意:此份代码中,返回的链接地址有点区别,我们得稍加调整:调整如下:
url_list.append(content['target']['url'].replace('api', 'www').replace('questions', 'question'))
完整代码:
import requests
import pandas as pd
browse_header = {
"Accept": "application/json, text/plain, */*",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.60 Safari/537.36",
"Host": "www.zhihu.com",
"Referer": "https://www.zhihu.com/hot",
"Cookie": "_xsrf=Pd0NpG6J8kZdHtzBVnNyQP1g0rO7NKeg; _zap=d7f27b9f-4fe3-4ef4-9376-df278af16940;"
}
url = "https://www.zhihu.com/api/v3/feed/topstory/hot-lists/total?limit=50&desktop=true"
res = requests.get(url, headers=browse_header).json()
# 热搜列表
content_list = res['data']
title_list = []
order_list = []
score_list = []
desc_list = []
url_list = []
index = 0
for content in content_list:
index += 1
order_list.append(index)
title_list.append(content['target']['title'])
score_list.append(content['detail_text'])
desc_list.append(content['target']['excerpt'])
url_list.append(content['target']['url'].replace('api', 'www').replace('questions', 'question'))
df = pd.DataFrame({
'热搜标题': title_list,
'热搜排名': order_list,
'热搜热度': score_list,
'描述': desc_list,
'链接地址': url_list
})
df.to_excel('知乎热搜榜.xlsx', index=False) # 保存结果数据
最后,查看一下获取到的数据:
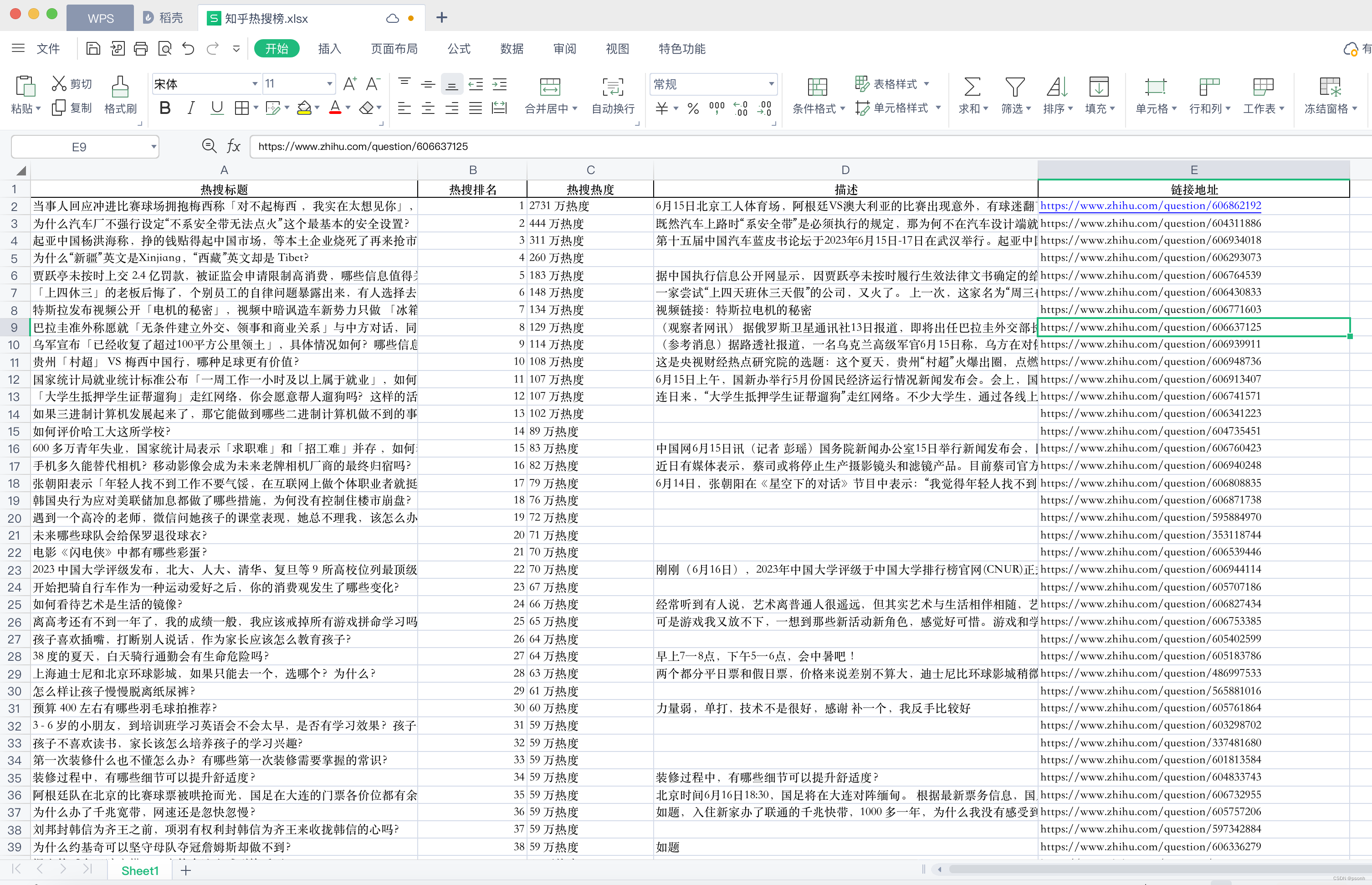
一共50条数据。
三、总结
以上就是整个获取的数据,如果你们有其他数据需要用python获取的,欢迎在评论区留言。最后给你们推荐一个前端JS实用工具:JS在线工具。