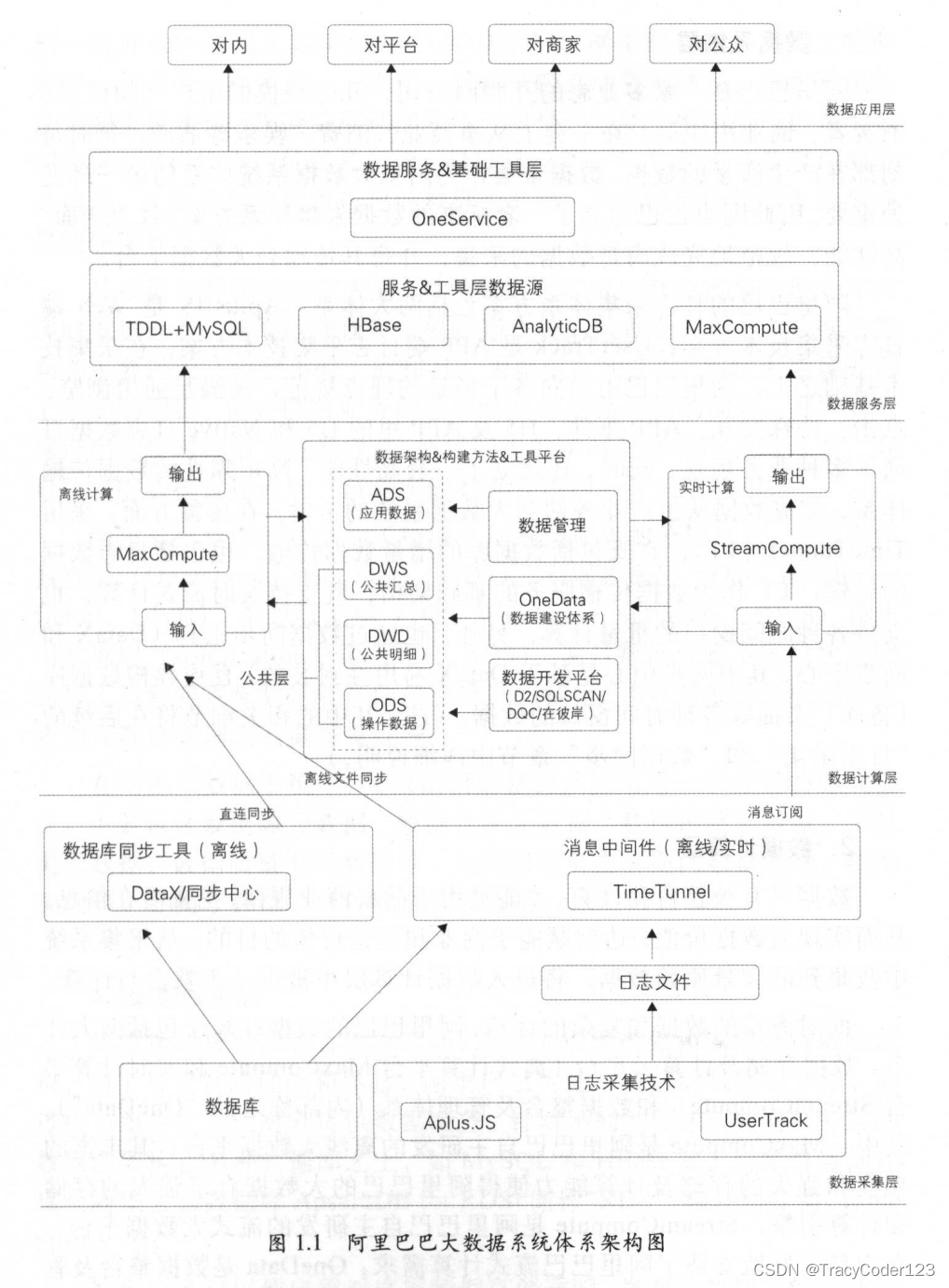
1.环境安装
conda activate mmpre # 激活创建好的环境,确保安装好pytorch,可以使用gpu
git clone https://github.com/open-mmlab/mmpretrain.git # 下载mmpre源码
cd mmpretrain # 进入mmpretrian目录
pip install openmim # 安装管理工具
mim install -e ".[multimodal]"
2.代码演示
import mmpretrain
print(mmpretrain.__version__)
from mmpretrain import get_model,list_models,inference_model
print(list_models(task="Image Classification",pattern='resnet18'))#打印分类任务相关且名字中包含resnet18的模型
print(list_models(task="Image Caption",pattern='blip'))#打印图像描述任务相关且名字中包含blip的模型
2.1 构建模型部分:
#获取模型
model=get_model('resnet18_8xb16_cifar10')
print(type(model))# 查看模型类型
model =get_model('resnet18_8xb32_in1k')
print(type(model.backbone))#查看模型的backbone的类型
2.2 模型推理部分:
#未加载预训练权重的情况下模型推理
inference_model(model,'demo/bird.jpg',show=True)
#加载预训练权重
list_model(task='Image Caption',pattern='blip')
inference_model('blip-base_3rdparty_caption','demo/cat-dog.png',show=True)
3.基于分类数据集的微调训练
3.1 数据集准备:
从kaggle上找到一个类似的数据集,下载地址:https://www.kaggle.com/datasets/esuarez7/cats_dogs_dataset/download?datasetVersionNumber=1
预训练权重的下载地址:https://download.openmmlab.com/mmclassification/v0/resnet/resnet18_8xb32_in1k_20210831-fbbb1da6.pth
mkdir data # 创建data文件夹
cd data # 进入data文件夹
tar -xff ~/Downloads/cats_dogs_dataset.tar #将下载好的数据集解压到data文件夹下
cd cats_dogs_dataset #进入解压后的文件夹
ls #列出当前目录下的文件
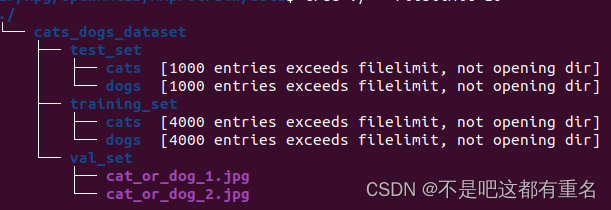
tree ./ --filelimit=10 #列出文件目录结构
3.2 配置文件
介绍:
#回到mmpretrain文件夹下后
ls conmfig #列出config目录下的文件
ls configs/resnet18 #查看resnet18相关的配置文件
配置文件主要分为4部分:
(1)model(backbone、neck、head)
(2)dataset(数据预处理、训练、验证、测试数据流程配置)
(3)schedules(优化器配置等)
(4)runtime(包括日志配置、权重保存配置、随机性可指定随机种子)
配置自定义配置文件:
mkdir projects/cat_dog #创建cat_dog文件夹
cd projects/cat_dog #进入文件夹
vim resnet18_finetune.py #新建配置文件
以下是完整的配置文件中的内容
# model settings
model = dict(
type='ImageClassifier',
backbone=dict(
type='ResNet',
depth=18,
num_stages=4,
out_indices=(3, ),
style='pytorch'),
neck=dict(type='GlobalAveragePooling'),
head=dict(
type='LinearClsHead',
num_classes=1000,
in_channels=512,
loss=dict(type='CrossEntropyLoss', loss_weight=1.0),
topk=(1, 5),
))
# dataset settings
dataset_type = 'ImageNet'
data_preprocessor = dict(
num_classes=1000,
# RGB format normalization parameters
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
# convert image from BGR to RGB
to_rgb=True,
)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='RandomResizedCrop', scale=224),
dict(type='RandomFlip', prob=0.5, direction='horizontal'),
dict(type='PackInputs'),
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='ResizeEdge', scale=256, edge='short'),
dict(type='CenterCrop', crop_size=224),
dict(type='PackInputs'),
]
train_dataloader = dict(
batch_size=32,
num_workers=5,
dataset=dict(
type=dataset_type,
data_root='data/imagenet',
ann_file='meta/train.txt',
data_prefix='train',
pipeline=train_pipeline),
sampler=dict(type='DefaultSampler', shuffle=True),
)
val_dataloader = dict(
batch_size=32,
num_workers=5,
dataset=dict(
type=dataset_type,
data_root='data/imagenet',
ann_file='meta/val.txt',
data_prefix='val',
pipeline=test_pipeline),
sampler=dict(type='DefaultSampler', shuffle=False),
)
val_evaluator = dict(type='Accuracy', topk=(1, 5))
# If you want standard test, please manually configure the test dataset
test_dataloader = val_dataloader
test_evaluator = val_evaluator
# optimizer
optim_wrapper = dict(
optimizer=dict(type='SGD', lr=0.1, momentum=0.9, weight_decay=0.0001))
# learning policy
param_scheduler = dict(
type='MultiStepLR', by_epoch=True, milestones=[30, 60, 90], gamma=0.1)
# train, val, test setting
train_cfg = dict(by_epoch=True, max_epochs=100, val_interval=1)
val_cfg = dict()
test_cfg = dict()
# NOTE: `auto_scale_lr` is for automatically scaling LR,
# based on the actual training batch size.
auto_scale_lr = dict(base_batch_size=256)
# defaults to use registries in mmpretrain
default_scope = 'mmpretrain'
# configure default hooks
default_hooks = dict(
# record the time of every iteration.
timer=dict(type='IterTimerHook'),
# print log every 100 iterations.
logger=dict(type='LoggerHook', interval=100),
# enable the parameter scheduler.
param_scheduler=dict(type='ParamSchedulerHook'),
# save checkpoint per epoch.
checkpoint=dict(type='CheckpointHook', interval=1),
# set sampler seed in distributed evrionment.
sampler_seed=dict(type='DistSamplerSeedHook'),
# validation results visualization, set True to enable it.
visualization=dict(type='VisualizationHook', enable=False),
)
# configure environment
env_cfg = dict(
# whether to enable cudnn benchmark
cudnn_benchmark=False,
# set multi process parameters
mp_cfg=dict(mp_start_method='fork', opencv_num_threads=0),
# set distributed parameters
dist_cfg=dict(backend='nccl'),
)
# set visualizer
vis_backends = [dict(type='LocalVisBackend')]
visualizer = dict(type='UniversalVisualizer', vis_backends=vis_backends)
# set log level
log_level = 'INFO'
# load from which checkpoint
load_from = None
# whether to resume training from the loaded checkpoint
resume = False
# Defaults to use random seed and disable `deterministic`
randomness = dict(seed=None, deterministic=False)
根据需求修改部分
#模型部分
head=dict(
num_classes=2#修改
)
backbone=dict(
init_cfg=dict(type='Pretrained',checkpoint='文件路径')#添加
)
# 数据集部分
dataset_type = 'CustomDataset'
train_dataloader=dict(
dataset=dict(
data_root="../../data/cats_dogs_dataset/training_set"#修改
)
)
val_dataloader=dict(
dataset=dict(
data_root="../../data/cats_dogs_dataset/val_set"#修改
)
)
val_evaluator=dict(type='Accuracy',topk=1)
optim_wrapper=dict(optimizer=dict(type='SGD',lr=0.01,momentum=0.9,weight_decay=0.0001))
train_cfg=dict(by_epoch=True,max_eopchs=5,val_interval=1)
3.3 训练
mim train mmpretrain resnet18_finetune.py --work-dir=./exp
3.4 评估
mim test mmpretrain resnet18_finetune.py --checkpoint exp/epoch_5.pth
mim test mmpretrain resnet18_finetune.py --checkpoint exp/epoch_5.pth --out result.pkl #把结果保存在.pkl文件中

3.5 结果分析
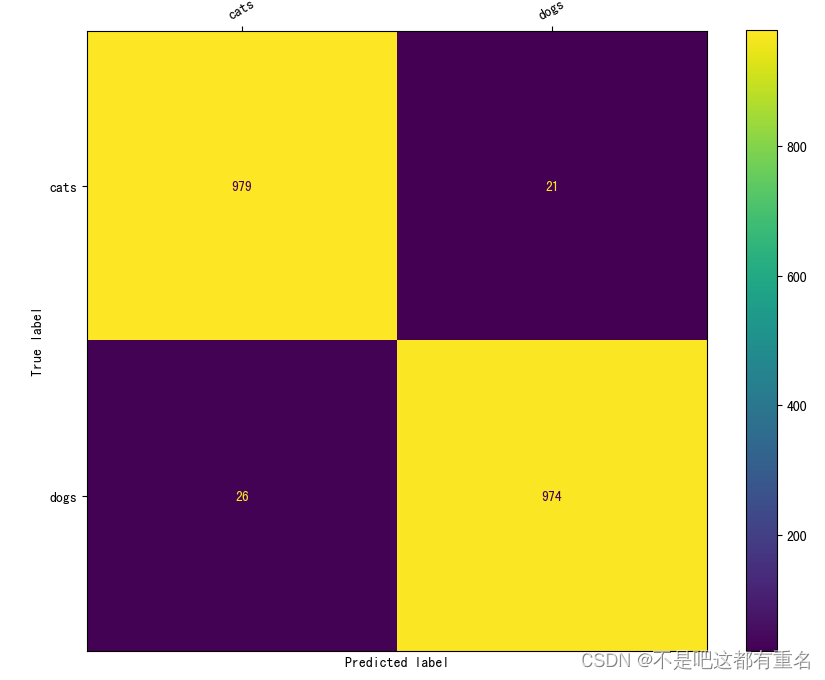
mim run mmpretrain analyze_results resnet18_finetune.py result.pkl --out_dir analyze
mim run mmpretrain confusion_matrix resnet18_finetune.py result.pkl --show --include-values # 画出分类的混淆矩阵
3.6推理
from mmpretrain import ImageClassificationInferencer
inferencer=ImageClassificationInferencer('./resnet18_finetune.py',pretrained='exp/epoch_5.pth')
inferencer("../../data/cats_dogs_dataset/val_set/cat_or_dog_1.jpg")
推理结果如下: