自然语言处理的前提是文本表示(Representation),即如何将人类符号化的文本转换成 计算机所能“理解”的表征形式。早期的自然语言表征主要采用离散表示。近年来,随着深度 学习的不断发展,基于神经网络的分布式词向量技术在对海量语料进行算法训练的基础上, 将符号化的句词嵌入到低维的稠密向量空间中,在解析句法与分析语义等方面都显示出强大 的潜力与应用效果。 分布式词向量表征的核心思路是通过大量的上下文语料与算法学习,使得计算机能够自 动构建上下文与目标词之间的映射关系。其主要思想是词与上下文信息可以单独构成一个可 行的语义向量,这种假设具有深刻的语言学理论根源。泽利格·哈里斯(Zellig S. Harris, 1954)提出分布假说(Distributional Hypothesis),认为分布相似的词,其语义也相似,这成 为早期词向量表征的理论渊源之一。伦敦学派奠基人弗斯(John Rupert Firth,1957)继承并 发扬了人类学家布罗尼斯拉夫·马林诺夫斯基(Bronislaw Malinowski)的“情景语境”(Context of Situation)理论,提出语境对词义的重要作用,为词向量的分布式表示与语义计算提供了 思想基础。在分布假说与情景理论的基础上,词向量通过神经网络对上下文,以及上下文和 目标词之间的关系进行语言建模,自动抽取特征,从而表达相对复杂的语义关系并进行语义 计算。
2. 词的表征 作为表达语义的基本单位之一,词是自然语言处理的主要对象。进行词向量运算的前提 是要将人类符号化的词进行数值或向量化表征。目前的词表征方式主要有离散式和分布式两 种。
2.1 离散表示(One-hot Representation)
传统的基于规则的统计方法通常将词用离散的方式表示。这种方法把每个词表示为一个 长向量①,这个向量的维度由词表②大小确定,并且该向量中只有一个维度的值为 1,其余维 度的值都为 0。例如,一个语料库 A 中有三个文本,如下: 文本 1: never trouble trouble until trouble troubles you. 文本 2: trouble never sleeps. 文本 3: trouble is a friend. 那么,该语料库的词表便由[never, trouble, until, you, sleep, is, a, friend]八个单词组成。每 个单词可以分别表示成一个维度为八的向量,根据单词在词表中所处的位置来计算,具体如 下:{“never”: [1 0 0 0 0 0 0 0]}、{“trouble”: [0 1 0 0 0 0 0 0]}、…、{“a”: [0 0 0 0 0 0 0 1 0]}、 {“friend”: [0 0 0 0 0 0 0 0 1]}。可以发现,随着语料库的变大,词表也随之增大,每个词维度 也会不断变大,每个词都将成为被大量 0 所包围的 1。因此,这种稀疏的表达方式又被形象 地称为独热表示。离散表示相互独立地表示每个词,忽略了词与词在句子中的相关性,这与 传统统计语言学中的朴素贝叶斯假设③不谋而合。然而,越来越多的实践表明,离散表达存 在两大缺陷。首先是“语义鸿沟”现象,由于独热表示假定词的意义和语法是互相独立的,这 种独立性显然是不适合词汇语义的比较运算,也不符合基本的语言学常识,因此,整篇文本中容易出现语义断层现象。例如我们知道“端午节”与“粽子”是有联系的——端午节通常应该 吃粽子。但是这两个词对应的离散向量是正交的,其余弦相关度为 0,表明两者在相似度上 没有任何关系;其次是“维度灾难”,随着词表规模的增加(视语料大小,一般会达到十万以 上),词向量的维度也会随之变大,向量中的 0 也会越来越多,这种维度的激增会使得数据 过于稀疏,计算量陡增,并对计算机的硬件和运算能力提出更高的要求。 2.2 分布式表示(Distributed Representation) 为解决离散表示的两大局限性,机器需要通过分布式表示来获得低维度、具有语义表达 能力的词向量(Hinton, 1986; Bengio et al. 2003)。分布式表示一般有两种方法:基于统计学 和基于神经网络(详见后文三)。早期,分布式词向量的获取主要通过统计学算法,包括共 现矩阵、奇异值分解等。近年来,随着深度学习技术的不断成熟,神经网络开始被用于训练 分布式词向量,取代了早期的统计方法。目前分布式词向量通常特指基于神经网络获取的低 维度词向量。这种词向量表示的理论源于哈里斯分布假设(Harris, 1954):上下文相似的词, 其语义也相似。分布式表示通过统计或神经网络的方法构建语言模型并获取词向量,具体方 法为利用词和上下文的关系,通过算法将原本离散式的词向量嵌入到一个低纬度的连续向量 空间中,最终把词表达成一个固定长度④的短向量。因此,这种表示方法也被称为词嵌入 (Word Embedding)。此外,根据分布假设——出现在类似上下文中的单词具有类似的语义, 词嵌入利用上下文与目标词的联合训练,可以获取词语的某种语义表达。例如,通过 Python 程序引入 Word2Vec 包并加载训练好的 60 维词向量模型,获得的词嵌入的形式如下:“never” [1.6839292, 0.14593178, …, 0.5776881]。 In[1]: from gensim.models import Word2Vec # 引入 Word2Vec 包 mode = Word2Vec.load(“word60.model”) # 加载训练好的 60 维词向量模型 mode[“never”] # 获取“never”的词向量
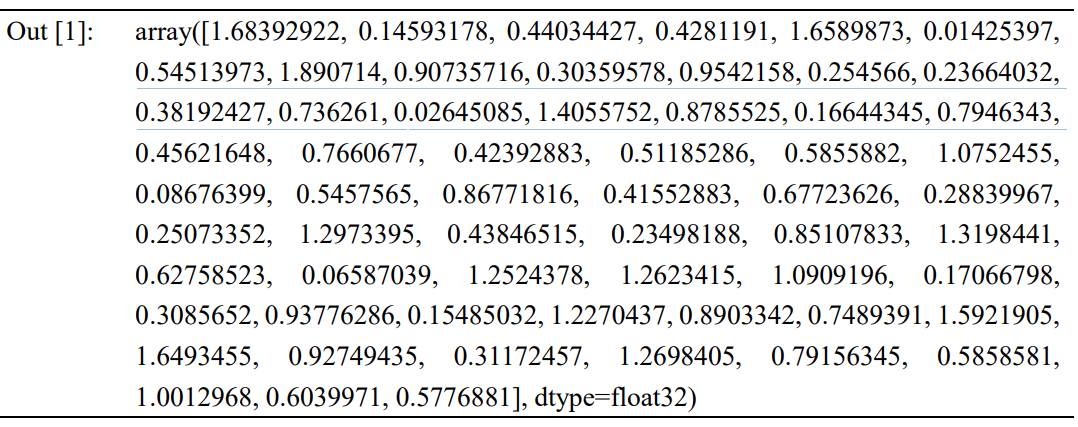 *词嵌入结果基于 Li 等(2018)的 Word2Vec 预训练词向量 3. 词向量训练与语言模型 目前的词表示很少采用离散表示,一般采用分布式表示。分布式词向量的获取方式可分 为两种:基于统计的方法和基于神经网络的方法。 3.1 基于统计的方法 3.1.1 共现矩阵
*词嵌入结果基于 Li 等(2018)的 Word2Vec 预训练词向量 3. 词向量训练与语言模型 目前的词表示很少采用离散表示,一般采用分布式表示。分布式词向量的获取方式可分 为两种:基于统计的方法和基于神经网络的方法。 3.1 基于统计的方法 3.1.1 共现矩阵