文章目录
- 一、需求
- 二、选型
- 三、前期设计
- 3.1 运行形态
- 3.2 执行器设计
- 3.3 开发策略
- 四、Datax-Web
- 五、总结
大家好,我是脚丫先生 (o^^o)
在看技术文章的时候,发现有赞平台采用过Datax。想到指北数据中台,数据汇聚采用的是Datax-web二次开发,借鉴经验设计思路,丰富自己方案。
有大平台做基础,优化指北数据中台就会更有思路。
路漫漫其修远兮~~~
一、需求
有赞大数据技术应用的早期,我们使用 Sqoop 作为数据同步工具,满足了 MySQL 与 Hive 之间数据同步的日常开发需求。
随着公司业务发展,数据同步的场景越来越多,主要是 MySQL、Hive 与文本文件之间的数据同步,Sqoop 已经不能完全满足我们的需求。在2017年初,我们已经无法忍受 Sqoop 给我们带来的折磨,准备改造我们的数据同步工具。当时有这么些很最痛的需求:
-
多次因 MySQL 变更引起的数据同步异常。MySQL 需要支持读写分离与分表分库模式,而且要兼容可能的数据库迁移、节点宕机以及主从切换。
-
有不少异常是由表结构变更导致。MySQL 或 Hive 的表结构都可能发生变更,需要兼容多数的表结构不一致情况。
-
MySQL 读写操作不要影响线上业务,不要触发 MySQL 的运维告警,不想天天被 DBA 喷。
-
希望支持更多的数据源,如 HBase、ES、文本文件。
作为数据平台管理员,还希望收集到更多运行细节,方便日常维护:
- 统计信息采集,例如运行时间、数据量、消耗资源
- 脏数据校验和上报
- 希望运行日志能接入公司的日志平台,方便监控
二、选型
基于上述的数据同步需求,我们计划基于开源做改造,考察的对象主要是 DataX 和 Sqoop,它们之间的功能对比如下:

DataX 主要的缺点在于单机运行,而这个可以通过调度系统规避,其他方面的功能均优于 Sqoop,最终我们选择了基于 DataX 开发。
三、前期设计
3.1 运行形态
使用 DataX 最重要的是解决分布式部署和运行问题,DataX 本身是单进程的客户端运行模式,需要考虑如何触发运行 DataX。
我们决定复用已有的离线任务调度系统,任务触发由调度系统负责,DataX 只负责数据同步。这样就复用了系统能力,避免重复开发。
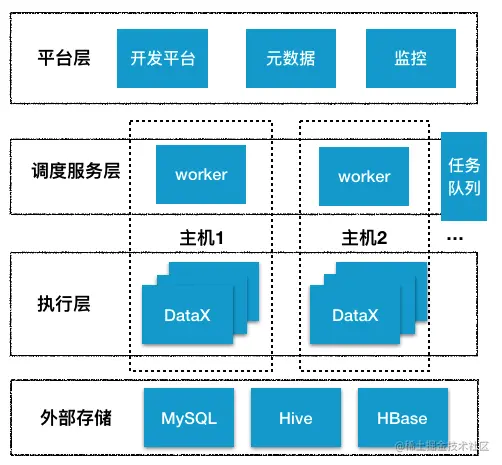
在每个数据平台的 worker 服务器,都会部署一个 DataX 客户端,运行时可同时启动多个进程,这些都由调度系统控制。
3.2 执行器设计
为了与已有的数据平台交互,需要做一些定制修改:
- 符合平台规则的状态上报,如启动/运行中/结束,运行时需上报进度,结束需上报成功失败
- 符合平台规则的运行日志实时上报,用于展示
- 统计、校验、流控等子模块的参数可从平台传入,并需要对结果做持久化
- 需要对异常输入做好兼容,例如 MySQL 主从切换、表结构变更
3.3 开发策略
大致的运行流程是:前置配置文件转换、表结构校验 -> (输入 -> DataX 核心+业务无关的校验 -> 输出) -> 后置统计/持久化。
尽量保证 DataX 专注于数据同步,尽量不隐含业务逻辑,把有赞特有的业务逻辑放到 DataX 之外,数据同步过程无法满足的需求,才去修改源码。
表结构、表命名规则、地址转换这些运行时前置校验逻辑,以及运行结果的持久化,放在元数据系统,而运行状态的监控放在调度系统。
四、Datax-Web
datax是基于脚本化的采集工具,因此小伙伴会问:有可视化界面进行采集任务执行吗?
这必须有。
DataX Web是在DataX之上开发的分布式数据同步工具,提供简单易用的 操作界面,降低用户使用DataX的学习成本,缩短任务配置时间。
- 用户可通过页面选择数据源即可创建数据同步任务。
- 支持RDBMS、Hive、HBase、ClickHouse、MongoDB等数据源,RDBMS数据源可批量创建数据同步任务,支持实时查看数据同步进度及日志并提供终止同步功能,集成并二次开发xxl-job可根据时间、自增主键增量同步数据。
并且提供可视化界面,以菜单的方式进行数据汇聚。
而我们在做大数据汇聚模块过程,是基于datax-web的源码成为一个单独的微服务,以此进行二次开发,最后以容器化的形式部署。
五、总结
有赞平台使用的Datax进行数据的汇聚,采取了多个措施进行了很多的优化。但是现如今而言,我们更多的采用的是集成Datax-Web进行二次开发,可以进行分布式部署。
指北数据中台,是完全源码的方式进行了Datax-Web的集成,包括前端和后端。
在之后,将会对其进行二次开发,包括插件新增,爬虫定制等。




![[PyTorch][chapter 41][卷积网络实战-LeNet5]](https://img-blog.csdnimg.cn/9c51b3254e5745b0ac55bc88f2cd10de.png)