前言
这里结合前面学过的LeNet5 模型,总结一下卷积网络搭建,训练的整个流程
目录:
1: LeNet-5
2: 卷积网络总体流程
3: 代码
一 LeNet-5
LeNet-5是一个经典的深度卷积神经网络,由Yann LeCun在1998年提出,旨在解决手写数字识别问题,被认为是卷积神经网络的开创性工作之一。该网络是第一个被广泛应用于数字图像识别的神经网络之一,也是深度学习领域的里程碑之一

| 层 | 参数 | 输出shape |
| 输入层 | [batch,channel,32,32] | |
| C1(卷积层) | 6@5x5 卷积核 ,stride=1 ,padding=0 | [batch,6,28,28] |
| S2(池化层) | kernel_size=2,stride=2,padding=0 | [batch,6,14,14] |
| C3(卷积层)
| 16@5x5 卷积核,stride=1,padding=0 | [batch,16,10,10] |
| S4(池化层) | kernel_size=2,stride=2,padding=0 | [batch,16,5,5] |
| C5(卷积层)
| 120@5x5卷积核,stride=1,padding=0 | [batch,120,1,1] |
| F6层-全连接层 | nn.Linear(in_features=120, out_features=84) | [batch,120] |
| Output层-全连接层 | nn.Linear(in_features=120, out_features=10) | [batch,10] |
二 卷积网络的总体流程
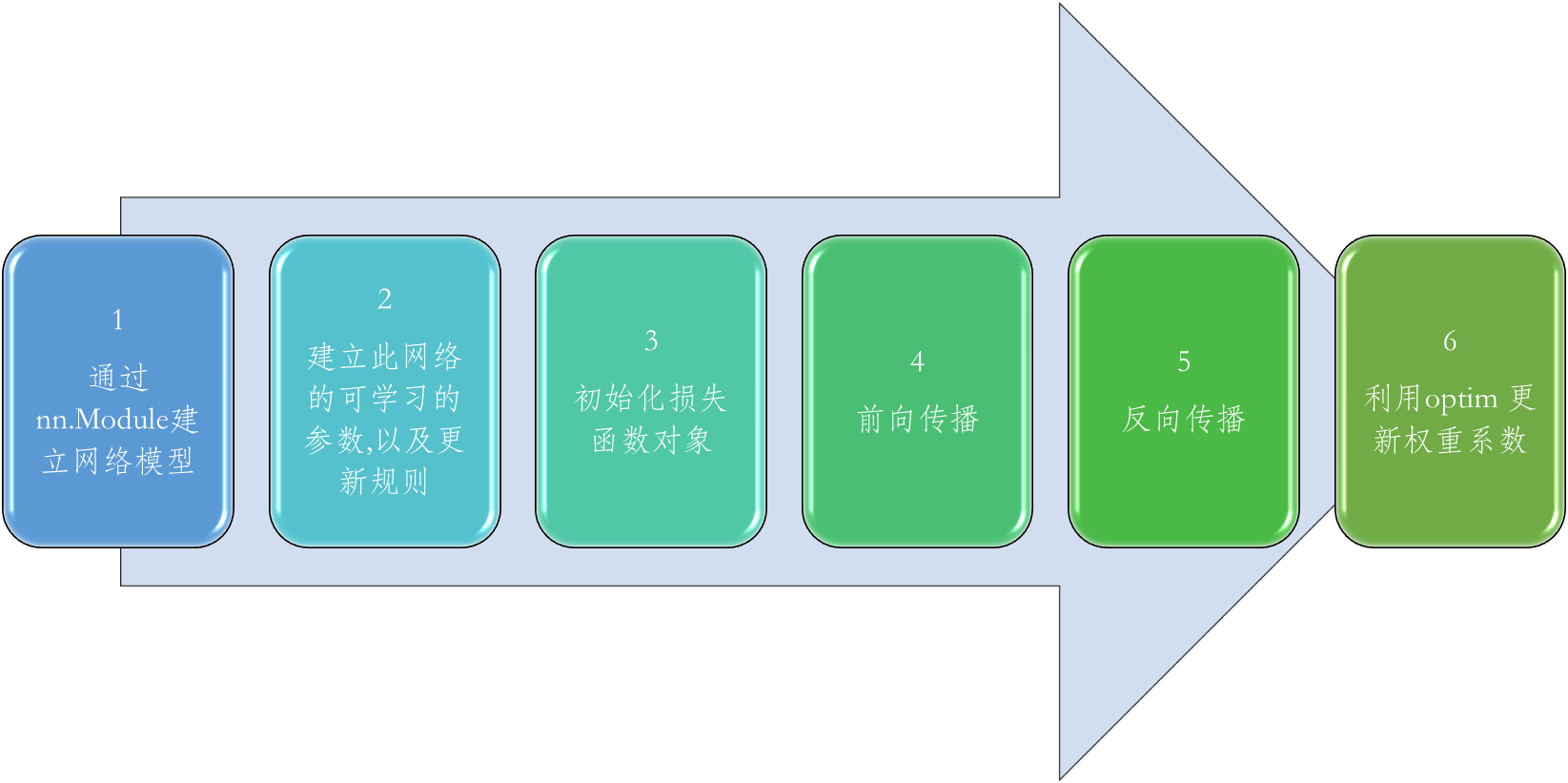
2.1、nn.Module建立神经网络模型
model = LeNet5()
2.2、建立此网络的可学习的参数,以及更新规则
optimizer = optim.Adam(model.Parameters(), lr=1e-3)
梯度更新的公式
2.3、构建损失函数
损失函数模型
criteon = nn.CrossEntropyLoss()
2.4 前向传播
logits = model(x)
根据现有的权重系数,预测输出
2.5 反向传播
optimizer.zero_grad() #先将梯度归零w_grad
loss.backward() #反向传播计算得到每个参数的梯度值w_grad
通过当前的loss ,计算梯度
2.6 利用optim 更新权重系数
optimizer.step() #更新权重系数W
利用优化器更新权重系数
三 代码
# -*- coding: utf-8 -*-
"""
Created on Thu Jun 15 14:32:54 2023
@author: chengxf2
"""
import torch
from torch import nn
from torch.nn import functional as F
from torchvision import datasets
from torchvision import transforms
from torch.utils.data import DataLoader
import torch.optim as optim
import ssl
class LeNet5(nn.Module):
"""
for cifar10 dataset
"""
def __init__(self):
super(LeNet5, self).__init__()
self.conv_unit = nn.Sequential(
#卷积层1 x:[b,3,32,32] => [b,6, 30,30]
nn.Conv2d(in_channels=3, out_channels=6, kernel_size=5,stride=1,padding=0),
#池化层1
nn.MaxPool2d(kernel_size=2,stride=2, padding =0),
#卷积层2
nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5,stride=1, padding=0),
#池化层2
nn.MaxPool2d(kernel_size=2,stride=2, padding =0)
#x:[b,16,5,5]
)
self.flatten = nn.Flatten(start_dim =1, end_dim = -1)
self.fc_unit = nn.Sequential(
nn.Linear(in_features=16*5*5, out_features=120),
nn.ReLU(),
nn.Linear(in_features=120, out_features=84),
nn.ReLU(),
nn.Linear(in_features=84, out_features=10)
)
def forward(self, x):
'''
Parameters
----------
x :
[batch,channel=3, width=32, height=32].
Returns
-------
out :
DESCRIPTION.
'''
#[b,3,32,32] =>[b,16,5,5]
out = self.conv_unit(x)
#print("\n 卷积层输出 :",out.shape)
#[b,16,5,5]=>[b,16*5*5]
out = self.flatten(out)
#print("\n flatten层输出 :",out.shape)
#[b,400]=>[b,10]
out = self.fc_unit(out)
#print("\n 全连接层输出 :",out.shape)
#pred = F.softmax(out,dim=1)
return out
def train():
x = torch.randn(8,3,32,32)
net = LeNet5()
out = net(x)
print(out.shape)
def main():
batchSize =32
maxIter = 10
dataset_trans = transforms.Compose([transforms.ToTensor(),transforms.Resize((32,32))])
imgDir='./data'
print("\n ---beg----")
cifar_train = datasets.CIFAR10(root= imgDir,train=True, transform= dataset_trans,download =False)
cifar_test = datasets.CIFAR10(root= imgDir,train=False,transform= dataset_trans,download =False)
train_data = DataLoader(cifar_train, batch_size=batchSize,shuffle=True)
test_data = DataLoader(cifar_test, batch_size=batchSize,shuffle=True)
print("\n --download finsh---")
device = torch.device('cuda')
# DataLoader迭代产生训练数据提供给模型
model = LeNet5().to(device)
criteon = nn.CrossEntropyLoss() #前向传播计算loss
optimizer = optim.Adam(model.parameters(), lr=1e-3, betas=(0.9, 0.999)) #反向传播
for epoch in range(maxIter):
for batchindex,(x,label) in enumerate(train_data):
#x: [b,3,32,32]
#label: [b]
x,label = x.to(device),label.to(device)
logits = model(x)
loss = criteon(logits, label)
#backpop
optimizer.zero_grad()
loss.backward()
optimizer.step() #更新梯度
if batchindex%500 ==0:
print('batchindex {}, loss {}'.format(batchindex, loss.item()))
model.eval()
total_correct =0.0
total_num = 0.0
with torch.no_grad():
for batchindex,(x,label) in enumerate(test_data):
x,label = x.to(device),label.to(device)
logits = model(x)
pred = logits.argmax(dim=1)
total_correct += torch.eq(pred, label).float().sum()
total_num += x.size(0)
acc = total_correct/total_num
print('\n epoch: {} ,acc: {} total_num: {}'.format(epoch, acc, total_num))
if __name__ == "__main__":
main()
因为不是灰度图,训练10轮,acc 只有 epoch: 9 ,acc: 0.6310999989509583 total_num: 10000.0
可以把卷积核调整小一点
参考:
https://mp.csdn.net/mp_blog/creation/editor/131209651
课时79 卷积神经网络训练_哔哩哔哩_bilibili
课时77 卷积神经网络实战-1_哔哩哔哩_bilibili