-
cmake -DSM=60 -DCMAKE_BUILD_TYPE=Release .. -
-DCMAKE_BUILD_TYPEcmake编译类型通常默认为debug,但是在编译软件时,一般都需要使用release版本的,debug太慢了。设置为release版本可以在cmake文件里进行,也可以在运行cmake命令时使用参数进行指定。 -
STREQUAL 用于比较字符串,相同返回 true
-
找不CUDA编译器,需要设置CUDACXX或CMAKE_CUDA_COMPILER变量,或者增加PATH。
-
CMake Error at CMakeLists.txt:15 (project): No CMAKE_CUDA_COMPILER could be found. -
SOLVE:
Tell CMake where to find the compiler by setting either the environment variable "CUDACXX" or the CMake cache entry CMAKE_CUDA_COMPILER to the full path to the compiler, or to the compiler name if it is in the PATH.
set(CMAKE_CUDA_COMPILER /usr/local/cuda-11.1/bin/nvcc)
set(CUDACXX /usr/local/cuda-11.1/bin/nvcc)
fastertransformer
cmake_minimum_required(VERSION 3.8 FATAL_ERROR)
project(FasterTransformer LANGUAGES CXX CUDA)
find_package(CUDA 10.0 REQUIRED)
option(BUILD_TRT "Build in TensorRT mode" OFF)
option(BUILD_TF "Build in TensorFlow mode" OFF)
set(CUDA_PATH ${CUDA_TOOLKIT_ROOT_DIR})
set(TF_PATH "" CACHE STRING "TensorFlow path")
#set(TF_PATH "/usr/local/lib/python3.5/dist-packages/tensorflow")
if(BUILD_TF AND NOT TF_PATH)
message(FATAL_ERROR "TF_PATH must be set if BUILD_TF(=TensorFlow mode) is on.")
endif()
set(TRT_PATH "" CACHE STRING "TensorRT path")
#set(TRT_PATH "/myspace/TensorRT-5.1.5.0")
if(BUILD_TRT AND NOT TRT_PATH)
message(FATAL_ERROR "TRT_PATH must be set if BUILD_TRT(=TensorRT mode) is on.")
endif()
list(APPEND CMAKE_MODULE_PATH ${CUDA_PATH}/lib64)
find_package(CUDA REQUIRED)
set (SM 60)
# setting compiler flags
if (SM STREQUAL 70 OR
SM STREQUAL 75 OR
SM STREQUAL 61 OR
SM STREQUAL 60)
set(CMAKE_CUDA_FLAGS "${CMAKE_CUDA_FLAGS} -gencode=arch=compute_${SM},code=\\\"sm_${SM},compute_${SM}\\\" -rdc=true")
if (SM STREQUAL 70 OR SM STREQUAL 75)
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -DWMMA")
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -DWMMA")
set(CMAKE_CUDA_FLAGS "${CMAKE_CUDA_FLAGS} -DWMMA")
endif()
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS}")
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS}")
set(CMAKE_CUDA_FLAGS "${CMAKE_CUDA_FLAGS} -Xcompiler -Wall")
message("-- Assign GPU architecture (sm=${SM})")
else()
set(CMAKE_CUDA_FLAGS "${CMAKE_CUDA_FLAGS} -gencode=arch=compute_60,code=\\\"sm_60,compute_60\\\" -rdc=true")
message("-- Unknown or unsupported GPU architecture (set sm=60)")
endif()
set(CMAKE_C_FLAGS_DEBUG "${CMAKE_C_FLAGS_DEBUG} -Wall -O0")
set(CMAKE_CXX_FLAGS_DEBUG "${CMAKE_CXX_FLAGS_DEBUG} -Wall -O0")
set(CMAKE_CUDA_FLAGS_DEBUG "${CMAKE_CUDA_FLAGS_DEBUG} -O0 -G -Xcompiler -Wall")
set(CMAKE_CXX_STANDARD 11)
set(CMAKE_CXX_STANDARD_REQUIRED ON)
if(CMAKE_CXX_STANDARD STREQUAL "11")
set(CMAKE_CUDA_FLAGS "${CMAKE_CUDA_FLAGS} --expt-extended-lambda")
set(CMAKE_CUDA_FLAGS "${CMAKE_CUDA_FLAGS} --expt-relaxed-constexpr")
set(CMAKE_CUDA_FLAGS "${CMAKE_CUDA_FLAGS} --std=c++11")
endif()
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -O3")
set(CMAKE_CUDA_FLAGS "${CMAKE_CUDA_FLAGS} -Xcompiler -O3")
set(CMAKE_ARCHIVE_OUTPUT_DIRECTORY ${CMAKE_BINARY_DIR}/lib)
set(CMAKE_LIBRARY_OUTPUT_DIRECTORY ${CMAKE_BINARY_DIR}/lib)
set(CMAKE_RUNTIME_OUTPUT_DIRECTORY ${CMAKE_BINARY_DIR}/bin)
set(COMMON_HEADER_DIRS
${PROJECT_SOURCE_DIR}
${CUDA_PATH}/include
)
set(COMMON_LIB_DIRS
${CUDA_PATH}/lib64
)
if(BUILD_TF)
list(APPEND COMMON_HEADER_DIRS ${TF_PATH}/include)
list(APPEND COMMON_LIB_DIRS ${TF_PATH})
endif()
if(BUILD_TRT)
list(APPEND COMMON_HEADER_DIRS ${TRT_PATH}/include)
list(APPEND COMMON_LIB_DIRS ${TRT_PATH}/lib)
endif()
include_directories(
${COMMON_HEADER_DIRS}
)
link_directories(
${COMMON_LIB_DIRS}
)
add_subdirectory(tools/gemm_test)
add_subdirectory(fastertransformer)
add_subdirectory(sample)
if(BUILD_TF)
add_custom_target(copy ALL COMMENT "Copying tensorflow test scripts")
add_custom_command(TARGET copy
POST_BUILD
COMMAND cp ${PROJECT_SOURCE_DIR}/sample/tensorflow/*.py ${PROJECT_SOURCE_DIR}/build/
)
endif()
gemm
- 修改后能单独编译的cmakelist文件为:
cmake_minimum_required(VERSION 3.8)
set(CMAKE_CUDA_COMPILER /usr/local/cuda-11.1/bin/nvcc)
set(CUDACXX /usr/local/cuda-11.1/bin/nvcc) # Detecting CXX compile features
project(gemm_test LANGUAGES CXX CUDA)
set(gemm_fp16_files
gemm_fp16.cu
)
set(gemm_fp32_files gemm_fp32.cu
)
add_executable(gemm_fp32 ${gemm_fp32_files}) # 生成目标可执行文件
set_target_properties(gemm_fp32 PROPERTIES CUDA_RESOLVE_DEVICE_SYMBOLS ON)
target_link_libraries(gemm_fp32 PUBLIC -lcublas -lcudart ${CMAKE_THREAD_LIBS_INIT})
add_executable(gemm_fp16 ${gemm_fp16_files})
set_target_properties(gemm_fp16 PROPERTIES CUDA_RESOLVE_DEVICE_SYMBOLS ON)
target_link_libraries(gemm_fp16 PUBLIC -lcublas -lcudart ${CMAKE_THREAD_LIBS_INIT})
- 运行
~/test/FastT/FasterTransformer/tools/gemm_test/cmake-build-debug$ ./gemm_fp16 1 128 12 64
代码注释
// 该程序首先包括几个标准C++和CUDA库,以及一个名为“common.h”的自定义头文件。然后,它定义了一个称为“diffTime”的函数,该函数以毫秒为单位计算两个时间戳之间的差。
#include <cstdio>
#include <cstdlib>
#include <cuda_fp16.h>
#include <cuda_profiler_api.h>
#include <ctime>
#include <unistd.h>
#include <sys/time.h>
#include "common.h"
using namespace std;
double diffTime(timeval start, timeval end)
{
return (end.tv_sec - start.tv_sec) * 1000 + (end.tv_usec - start.tv_usec) * 0.001;
}
// 这是一个C++程序,使用CUDA和cuBLAS库测试矩阵乘法运算的性能。该程序创建几个矩阵,并对它们执行不同类型的矩阵乘法,测量每次乘法的执行时间,并为每次乘法选择最快的算法。
int main()
{
//主函数首先打开一个名为“gemm_config.in”的文件
FILE* fd = fopen("gemm_config.in", "w");
if(fd == NULL)
{
printf("Cannot write to file gemm_config.in\n");
return 0;
}
struct cudaDeviceProp prop;
cudaGetDeviceProperties(&prop, 0);
printf("Device %s\n", prop.name);
//为矩阵乘法中使用的矩阵的维数设置几个常量。
const int batch_size = atoi("1");
const int seq_len = atoi("12");
const int head_num = atoi("12");
const int size_per_head = atoi("12");
// 设置了几个数组来存储关于每个矩阵乘法运算的信息,例如所涉及的矩阵的维数和正在执行的运算的描述。
const int gemm_num = 5;
int M[gemm_num];
int N[gemm_num];
int K[gemm_num];
int batchCount[gemm_num] = {1,1,1,1,1};
char mess[gemm_num][256];
//gemm1
M[0] = batch_size * seq_len;
K[0] = head_num * size_per_head;
N[0] = K[0];
strcpy(mess[0], "from_tensor * weightQ/K/V, attr * output_kernel");
//gemm2
M[1] = M[0];
K[1] = K[0];
N[1] = 4 * N[0];
strcpy(mess[1], "attr_output * inter_kernel");
//gemm3
M[2] = M[0];
K[2] = 4 * K[0];
N[2] = N[0];
strcpy(mess[2], "inter_matmul * output_kernel");
M[3] = seq_len;
N[3] = seq_len;
K[3] = size_per_head;
batchCount[3] = batch_size * head_num;
strcpy(mess[3], "attention batched Gemm1");
M[4] = seq_len;
N[4] = size_per_head;
K[4] = seq_len;
batchCount[4] = batch_size * head_num;
strcpy(mess[4], "attention batched Gemm2");
// 然后,该程序创建一个cuBLAS句柄 cublasHandle_t是表示cuBLAS库的句柄的类型,cuBLAS是基本线性代数子程序(BLAS)库。它提供了在NVIDIA GPU上执行矩阵运算的各种例程。
// 总之,这两行代码为使用cuBLAS库在NVIDIA GPU上执行矩阵运算奠定了必要的基础设施。
cublasHandle_t cublas_handle;///usr/local/cuda-11.1/targets/x86_64-linux/include/cublas_api.h
cublasCreate(&cublas_handle);// cublasCreate(&cublas_handle)初始化cublas库并为其创建一个句柄。该函数将指向cublasHandle_t变量的指针作为参数,并将其设置为指向新创建的cublas句柄。这个句柄可以用来调用cuBLAS库提供的各种矩阵运算。
typedef __half T;
cudaDataType_t AType = CUDA_R_16F;
cudaDataType_t BType = CUDA_R_16F;
cudaDataType_t CType = CUDA_R_16F;
cudaDataType_t computeType = CUDA_R_16F;
const int ites = 100;
struct timeval start, end;
// 两行代码定义了要测试的cuBLAS GEMM(通用矩阵乘法)算法的范围。 CUBLAS_GEMM_DEFAULT_TENSOR_OP和CUBLAS-GEMM_ALEGO15_TENSOR_OP是表示不同CUBLAS GEMM算法的常数。
int startAlgo = (int)CUBLAS_GEMM_DEFAULT_TENSOR_OP;//CUBLAS_GEMM_DEFAULT_TENSOR_OP是指CUBLAS提供的默认算法,该算法针对大多数矩阵大小进行了优化。
int endAlgo = (int)CUBLAS_GEMM_ALGO15_TENSOR_OP; //CUBLAS_GEMM_ALGO15_TENSOR_OP是指由数字15标识的特定算法,该算法针对中小型矩阵进行了优化。
// 通过定义一系列要测试的算法,代码可以比较计算中使用的给定矩阵大小的不同算法的性能。函数cublasGemmEx()可以用startAlgo和endAlgo之间的不同算法调用,以测试它们,并确定哪种算法在给定的问题大小下产生最佳性能。
T alpha = (T)1.0f;
T beta = (T)0.0f;
printf("***FP16 Gemm Testing***\n");
for(int i = 0; i < gemm_num; ++i)
{
int m = M[i], n = N[i], k = K[i];
printf("\n-----------------------------\n");
printf("GEMM test %d: [M: %d, K: %d, N: %d] %s\n", i, m, k, n, mess[i]);
T* d_A;
T* d_B;
T* d_C;
check_cuda_error(cudaMalloc((void**)&d_A, sizeof(T) * m * k * batchCount[i]));
check_cuda_error(cudaMalloc((void**)&d_B, sizeof(T) * k * n * batchCount[i]));
check_cuda_error(cudaMalloc((void**)&d_C, sizeof(T) * m * n * batchCount[i]));
float exec_time = 99999.0f;
int fast_algo = 0;
for(int algo = startAlgo; algo <= endAlgo; algo++)
{
cudaDeviceSynchronize();
gettimeofday(&start, NULL);
for(int ite = 0; ite < ites; ++ite)
{
if(i < 3)
{
check_cuda_error(cublasGemmEx(cublas_handle,
CUBLAS_OP_N, CUBLAS_OP_N,
n, m, k,
&alpha,
d_B, BType, n,
d_A, AType, k,
&beta,
d_C, CType, n,
computeType,
static_cast<cublasGemmAlgo_t>(algo)));
}
else if(i == 3)
{
check_cuda_error(cublasGemmStridedBatchedEx(cublas_handle,
CUBLAS_OP_T, CUBLAS_OP_N,
seq_len, seq_len, size_per_head,
&alpha,
d_B, BType, size_per_head, seq_len * size_per_head,
d_A, AType, size_per_head, seq_len * size_per_head,
&beta,
d_C, CType, seq_len, seq_len * seq_len,
batch_size * head_num,
computeType,
static_cast<cublasGemmAlgo_t>(algo)));
}
else
{
check_cuda_error(cublasGemmStridedBatchedEx(cublas_handle,
CUBLAS_OP_N, CUBLAS_OP_N,
size_per_head, seq_len, seq_len,
&alpha,
d_B, BType, size_per_head, seq_len * size_per_head,
d_A, AType, seq_len, seq_len * seq_len,
&beta,
d_C, CType, size_per_head, seq_len * size_per_head,
batch_size * head_num,
computeType,
static_cast<cublasGemmAlgo_t>(algo)));
}
}
cudaDeviceSynchronize();
gettimeofday(&end, NULL);
printf("algo_%d costs %.3fms \n", algo, diffTime(start, end) / ites);
if(diffTime(start, end) / ites < exec_time)
{
exec_time = diffTime(start, end) / ites;
fast_algo = algo;
}
}
printf("fast_algo %d costs %.3f ms\n", fast_algo, exec_time);
fprintf(fd, "%d\n", fast_algo);
}
}
use gemm_config.in file later in “/FasterTransformer/fastertransformer/cuda/open_attention.h”
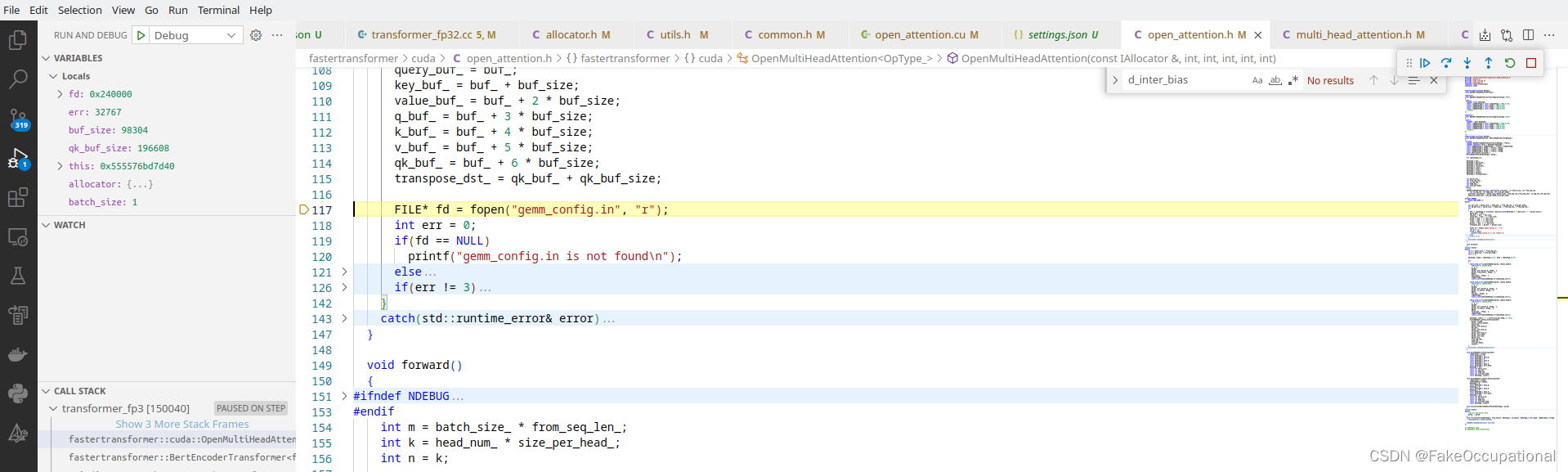
if can’t find will use default (中英混合是因为我的linux系统没有安装中文输入法)
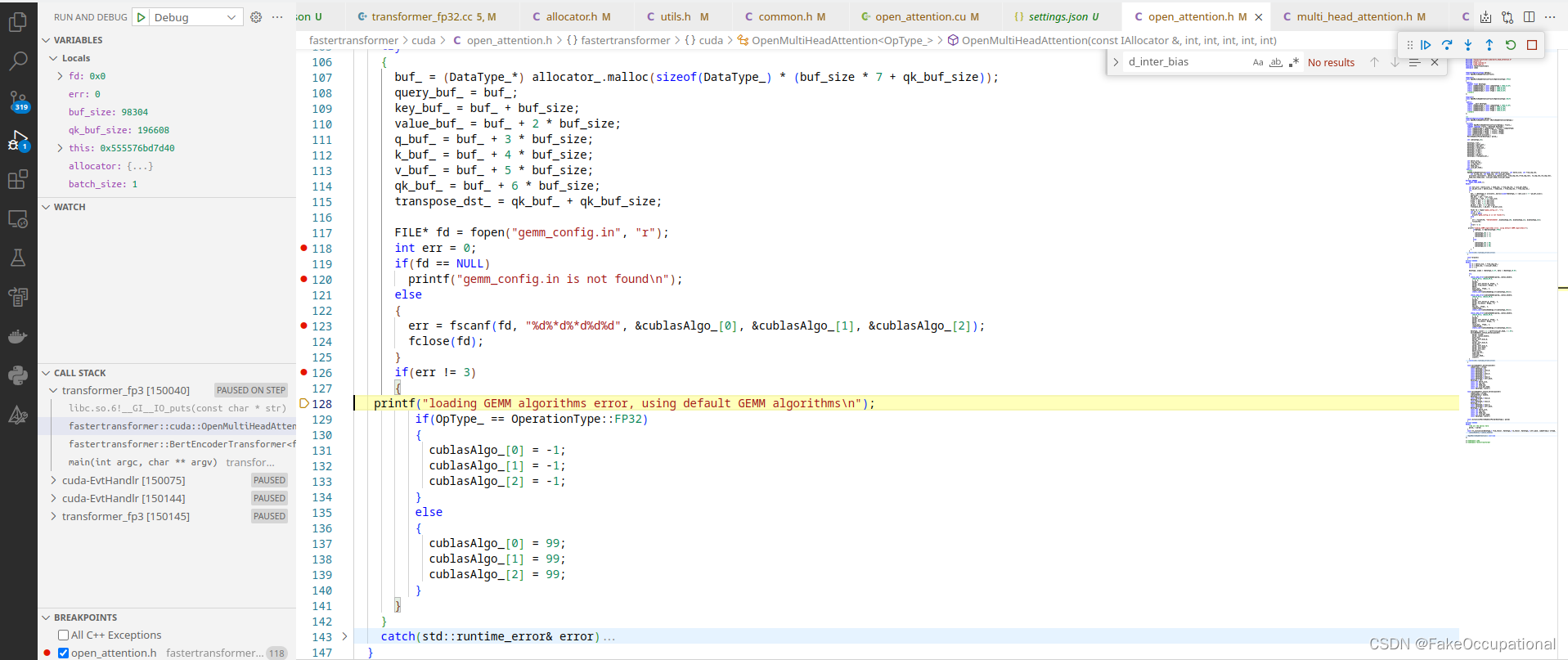
错误与处理
-
Attempt to add link library “-lcublas” to target “gemm_fp32” which is not
-
可能因为配置出问题了degug时 Error running ‘gemm_fp16’: Cannot run program “cmake_device_link.o” (in directory “/home/pdd/test/FastT/FasterTransformer/tools/gemm_test/cmake-build-debug/CMakeFiles/gemm_fp16.dir”): error=13, 权限不够
-
但是可以直接运行
~/test/FastT/FasterTransformer/tools/gemm_test/cmake-build-debug$ ./gemm_fp16 1 128 12 64 -
发现找不到bashrc nvcc的路径了 : / t e s t / F a s t T / F a s t e r T r a n s f o r m e r / t o o l s / g e m m t e s t :~/test/FastT/FasterTransformer/tools/gemm_test : /test/FastT/FasterTransformer/tools/gemmtest nvcc -V
Traceback (most recent call last):
File “/usr/lib/command-not-found”, line 27, in
from CommandNotFound.util import crash_guard
ModuleNotFoundError: No module named ‘CommandNotFound’
CG
-
通用矩阵乘(GEMM)优化与卷积计算
-
VIDEO 【HPC 05】CPU 和 CUDA 的 GEMM 实现
-
https://github.com/mrzhuzhe/riven/tree/main/cuda_test
-
https://stackoverflow.com/questions/66327073/how-to-find-and-link-cuda-libraries-using-cmake-3-15
-
add_executable(test benchmark.cpp)
find_package(CUDALibs)
target_link_libraries(test CUDA::cudart CUDA::cublas CUDA::cufft CUDA::cusolver CUDA::curand CUDA::nppicc CUDA::nppial CUDA::nppist CUDA::nppidei CUDA::nppig CUDA::nppitc CUDA::npps) -
A Visual Studio Code extension for building and debugging CUDA applications.
![深度学习实践篇[17]:模型压缩技术、模型蒸馏算法:Patient-KD、DistilBERT、DynaBERT、TinyBERT](https://img-blog.csdnimg.cn/img_convert/98eeccd497746c2bfa4dd7a8df9b061e.png)