点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
作者介绍

李逸轩
上海交通大学2022级硕士研究生,研究兴趣主要是三维人脸生成
报告题目
具有三维感知的换脸算法
内容简介
AI换脸旨在将一张给定目标图片中的人脸五官替换成源图片中的另一个人,其在影视制作、隐私保护等领域有着广泛的应用。以往的换脸算法研究往往忽略了人脸的3D特性,仅以2D图像处理的角度生成单一视角下换脸结果。针对这一问题,本文提出了首个能生成多视角结果与几何形状的换脸框架3dSwap。具体来说,我们设计了一个伪多视角的优化方法,通过将输入的2D图片映射到3D生成模型的隐空间中来提取人脸几何与纹路先验;而后,我们提出使用一个参数自适应的插值模块直接在隐空间中获取对应换脸结果的隐码,有效地完成了身份信息的迁移。与现有方法相比,3dSwap在权威的高清人脸数据集CelebA-HQ上取得了最好的身份迁移准确性。
代码链接:https://lyx0208.github.io/3dSwap
01
Background
Face swapping
Face swapping,即换脸,它的问题定义是:给定两张人脸的图片,将其中一张人脸的五官迁移到另一张人脸上,并保留原图中五官以外的部分,例如脸型、肤色、发色等。这两张照片中提供五官的人脸照片,我们称之为source image,而被换脸的照片则称之为target image。

换脸算法是计算机视觉领域一个重要且历史悠久的研究方向,一些研究者在2000年左右便开始涉及这一方向。对于一张照片是否被换过脸的检测,我们称之为face forgery detection,也是计算机视觉领域一个热门的研究问题。
Existing face swapping approaches
现有的换脸算法大致可以分为两类:基于3D模型的换脸算法和基于对抗生成网络的换脸算法。早期的换脸算法都属于第一类,他们大多将输入的人脸照片fit到一个参数化的人脸模型(例如3DMM)上,再进行换脸。2014年,对抗生成网络被提出以后,研究者便将其引入到了换脸算法的领域中,并取得了较好成果。由于计算资源的限制,大多基于GAN的换脸算法生成的结果的分辨率都在256*256或512*512的分辨率,近期的一些工作将GAN反演(GAN inversion)与换脸相结合,利用能生成高分辨率人脸的预训练GAN模型来生成高清换脸结果。

Problems of existing approaches
这两大类换脸算法中,基于3D模型的方法更多地考虑了人脸几何信息,但这些参数化人脸模型提供的脸部纹路较为有限,生成的换脸结果往往较为模糊。而基于GAN的方法由于仅从2D照片中提取特征,更多地考虑了人脸纹路信息而没有很好地利用几何先验,在一些输入照片人脸角度差异较大的情况下可能生成的结果不够理想。因此,我们思考是否可以设计一种换脸算法,同时考虑几何与纹路先验,这也是我们本篇文章的研究动机。
Challenges of 3D-aware face swapping task
但是想要实现一个3D-aware的换脸算法,我们需要解决以下两大挑战:
1)如何从单一视角的输入照片中同时提取几何与纹理先验?
2)如何利用这些先验来实现一个3D-aware的换脸?
02
Method
我们回到之前提出的两个问题上。首先是:如何从单一视角的输入照片中同时提取几何与纹理先验?针对这一问题,我们给出的解决方案是:设计一个3D GAN反演的框架,将输入的2D照片投影到3D-aware生成模型的隐空间中,并将得到的隐码作为先验信息。在设计这样一个3D GAN inversion的框架时,我们需要考虑到其与常规的2D GAN inversion的不同点。以下是2D GAN inversion和3D GAN inversion的表达形式,我们可以注意到其唯一的区别在于2D GAN模型是直接使用w来生成结果,而3D GAN的输入除了w之外还有相机参数p。

这一问题最直接的解决方案就是使用大量的数据集,用同一个人不同视角的图片来训练我们的inversion网络,但是目前来看这样的数据集是稀有的。
Pseudo-multi-view train strategy
为解决这一问题,我们设计了一个伪多视角的训练框架来训练一个learning-based的3D GAN inversion模型。此外,我们额外采样了一个随机的相机参数d hat,并且合成了input x,在d hat下的重建结果x hat,作为输入图片在其他视角下的伪输入,并将这一输入再次送到E-G的结构中。
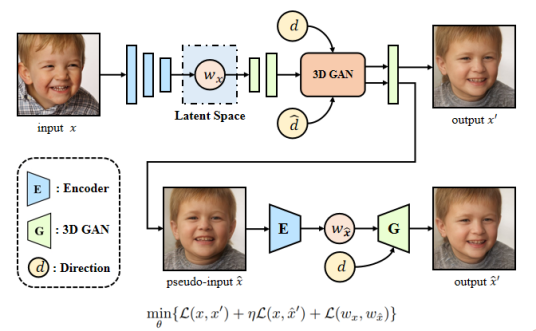
第二个问题:如何利用这些先验来实现一个3D-aware的换脸?我们的解决方案是:设计一个基于latent code的换脸算法计算对应换脸结果的隐码,并使用预训练好的3D GAN直接合成换脸结果。
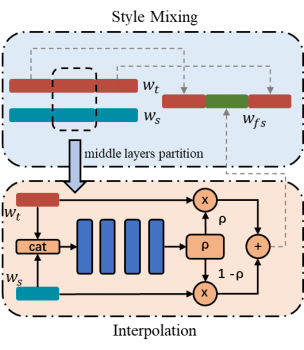
由于latent code包含了人脸所有的信息,而换脸的结果也是两个人脸的某一种中间状态,一个很直接的思路就是使用插值来获得对应换脸结果的隐码。而受之前提到style mixing的启发,较粗糙的style能控制脸部朝向、脸型、发型等high-level的特征,较精细的style控制发色等细节,而这些部分正是换脸中target image不需要被改变的部分,于是我们在插值的基础上将style mixing与插值相结合,保留target粗糙和精细的部分,只在代表五官的中间部分进行插值。插值的表达式为:
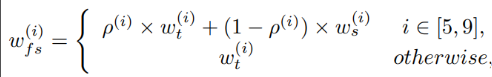
由于3D GAN使用NeRF的方式来渲染最终结果,其inversion质量与直接的2D生成不可避免的有一些差距,同时基于隐码插值的换脸思路还是在一定程度上会对非五官的区域造成一些影响。受pivot tuning inversion的启发,我们设计了一套联合参数优化的方法在测试时微调预训练EG3D的参数,同时增强inversion质量和face swapping的表现。
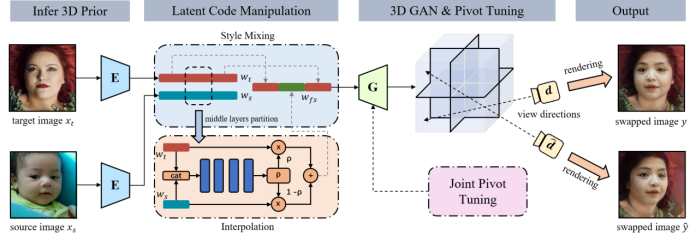
最后,在得到微调参数以及对应的换脸结果之后,我们就可以去合成任意视角下的换脸结果。下图是我们训练的流程图。
03
Experiments
我们的实验数据集主要来自CelebA-HD,下面的实验结果可以证明我们的算法在很多具有挑战的条件设定下的性能。下图中,在性别、年龄、肤色、打光角度有很大差异的情况下,换脸的效果都很好,并且id similarity这一定量指标会比2D方法更好。

下图是与近些年效果较好的2D换脸方法的对比。结果显示,我们的方法在迁移之后与五官的相似性是最好的,能够较好地保留五官的细节。

下图是多视角下的换脸结果,可以看到,不论是在源图片视角还是目标图片视角,我们都能很好地看到原图的五官特征,这说明我们的方法可以生成多视角的结果。

04
Ablation Study
Effectiveness of the learning-based 3D GAN Inversion
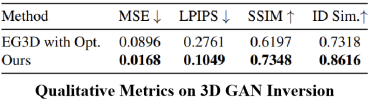
这里主要是证明基于学习的三维GAN反演的有效性,通过对比发现我们的方法在眼睛、眼镜的细节上表现更好,并且定量的指标也是更高的。

Effectiveness of Style Mixing
下图证明了style mixing的有效性。由第三列与第四列的对比可以看出,当使用style mixing时,目标图像能够更好地保留发色、肤色等特征。

05
Conclusion
我们提出了首个具有3D感知的换脸框架,它
(1)通过3D GAN反演从单视角图像中同时提取几何和纹路的人脸先验
(2)使用一种独特的基于隐码的换脸算法
(3)通过一个联合的参数优化弥补了2D生成和3D渲染的之间的效果差距。
整理:陈研
审核:李逸轩
提
醒
点击“阅读原文”跳转到33:11可以查看回放哦!
往期精彩文章推荐

记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了1100多位海内外讲者,举办了逾550场活动,超600万人次观看。

我知道你
在看
哦
~

点击 阅读原文 查看回放!