来自B站视频,API查阅,TORCH.NN
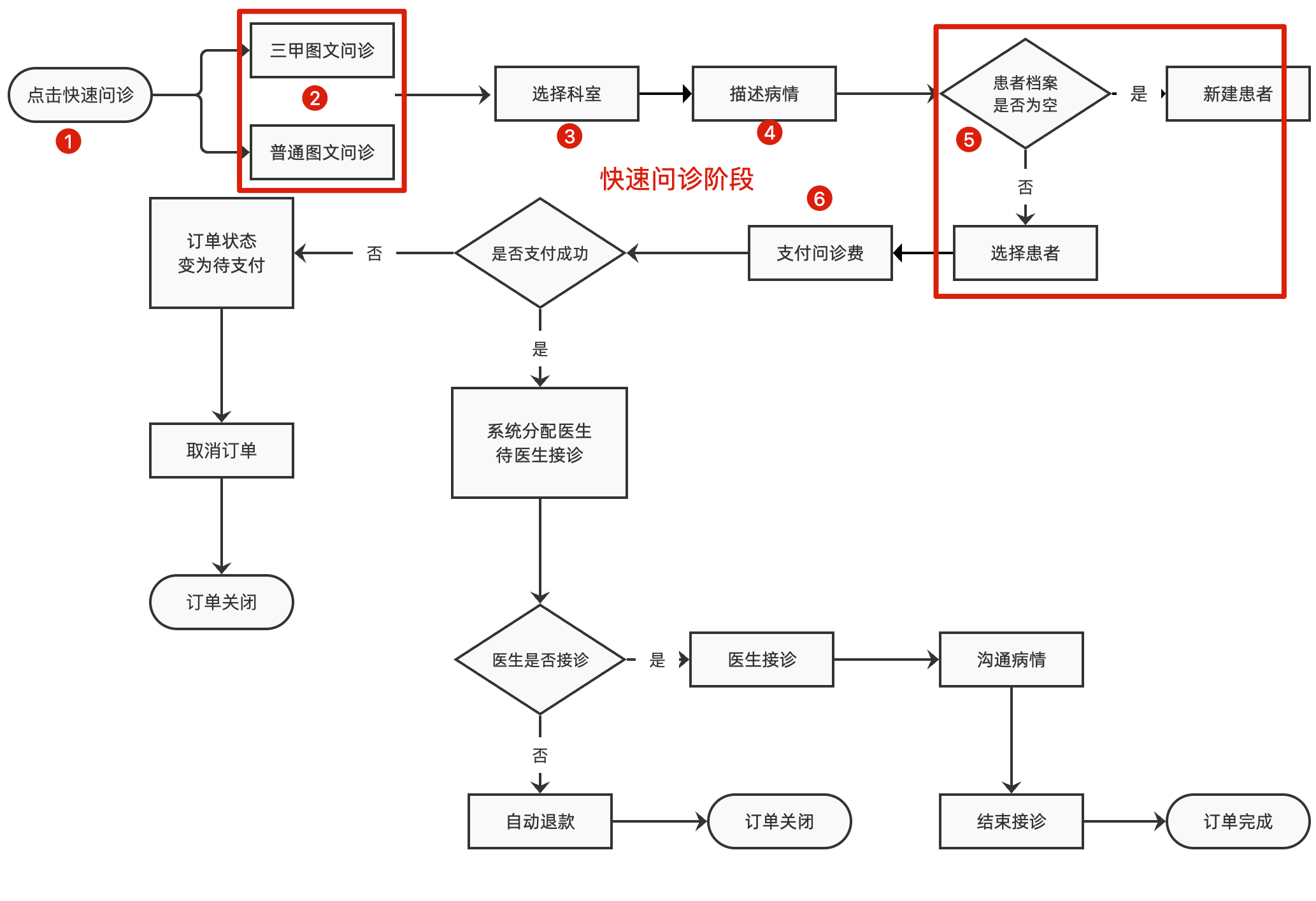
- seq2seq 可以是 CNN,RNN,transformer
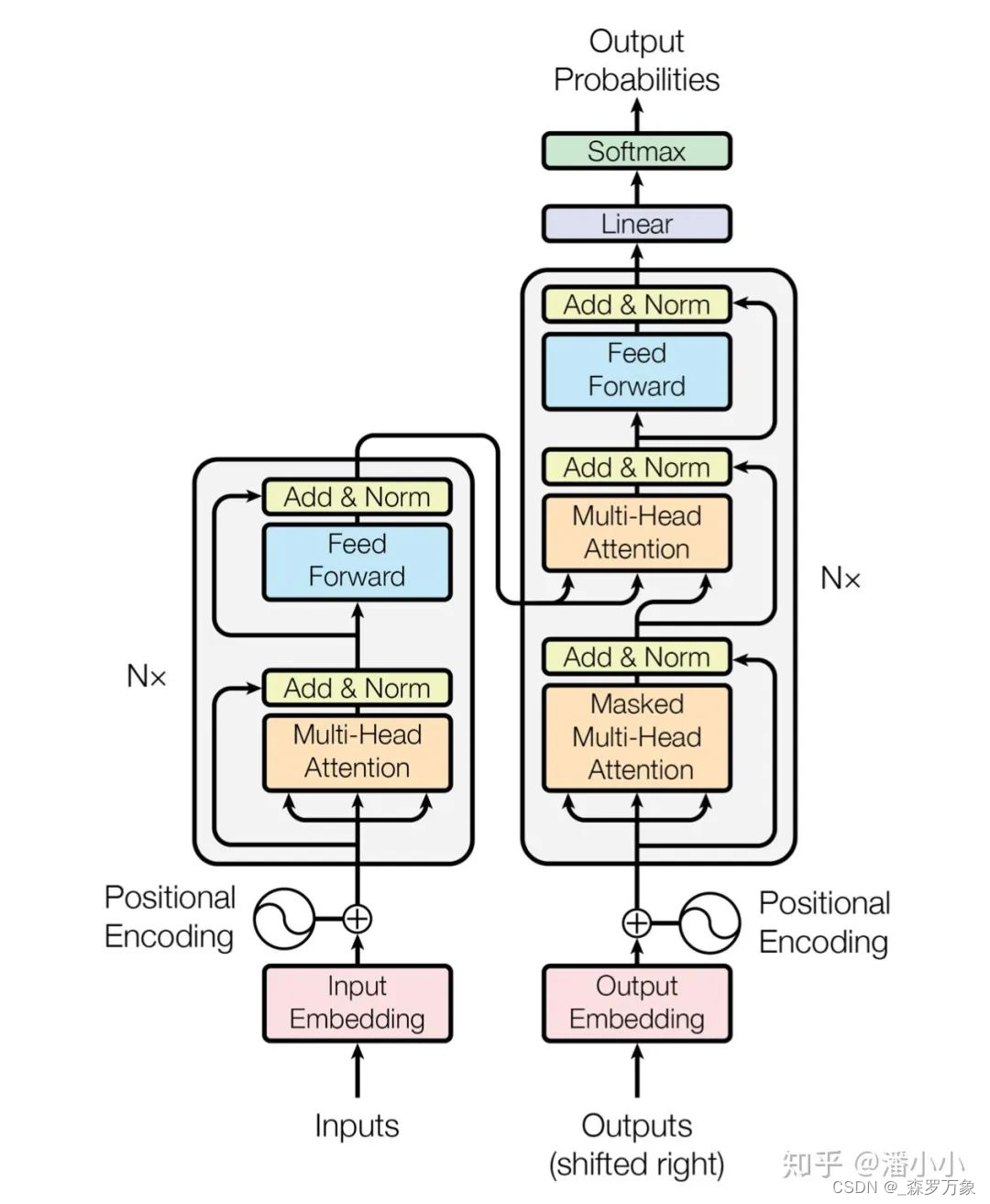
- nn.Transformer 关键源码:
encoder_layer = TransformerEncoderLayer(d_model, nhead, dim_feedforward, dropout,
activation, layer_norm_eps, batch_first, norm_first,
**factory_kwargs)
encoder_norm = LayerNorm(d_model, eps=layer_norm_eps, **factory_kwargs)
self.encoder = TransformerEncoder(encoder_layer, num_encoder_layers, encoder_norm)
decoder_layer = TransformerDecoderLayer(d_model, nhead, dim_feedforward, dropout,
activation, layer_norm_eps, batch_first, norm_first,
**factory_kwargs)
decoder_norm = LayerNorm(d_model, eps=layer_norm_eps, **factory_kwargs)
self.decoder = TransformerDecoder(decoder_layer, num_decoder_layers, decoder_norm)
memory = self.encoder(src, mask=src_mask, src_key_padding_mask=src_key_padding_mask)
output = self.decoder(tgt, memory, tgt_mask=tgt_mask, memory_mask=memory_mask,
tgt_key_padding_mask=tgt_key_padding_mask,
memory_key_padding_mask=memory_key_padding_mask)
return output
- src_mask 是 padding 的 mask,tgt_mask 是为了 mask 掉目标句子的后续,memory_mask 是 decoder 第二个 mha 的 mask
- The Annotated Transformer 有详细讲解
- PositionalEncoding 是 n x d 的位置矩阵,其中 n 是句子的长度,d 是 embedding 后的长度,即 d_model,实际和 embedding 后的输入shape一样,因为要直接相加
构造一个矩阵可以通过 torch.zeros(),再往里面填充内容

Var(X)=E(X2)-[E(X)]2,因此E(X)=0,Var(X)=1时,E(X2)=1。独立随机变量满足 E(XY)=E(X)E(Y)=0,Var(XY)=E(X2)E(Y2)-[E(XY)]²=1,长度为 d 的向量内积就是 d 个E(X)=0,Var(X)=1 的变量相加,因此点集均值是0,方差为 d
- transformer 的归纳偏置(人为经验)少,泛化能力好,但相对来说,数据量的要求与先验假设的程度成反比
- transformer 核心计算在于计算注意力机制,它是平方复杂度
- FFN 和 Mha 的关系类似于 depth-wise convolution 和 point-wise convolution 的关系,FFN 做通道的信息融合,Mha 做位置的信息融合
- Transformer 使用 Teacher Forcing 进行训练