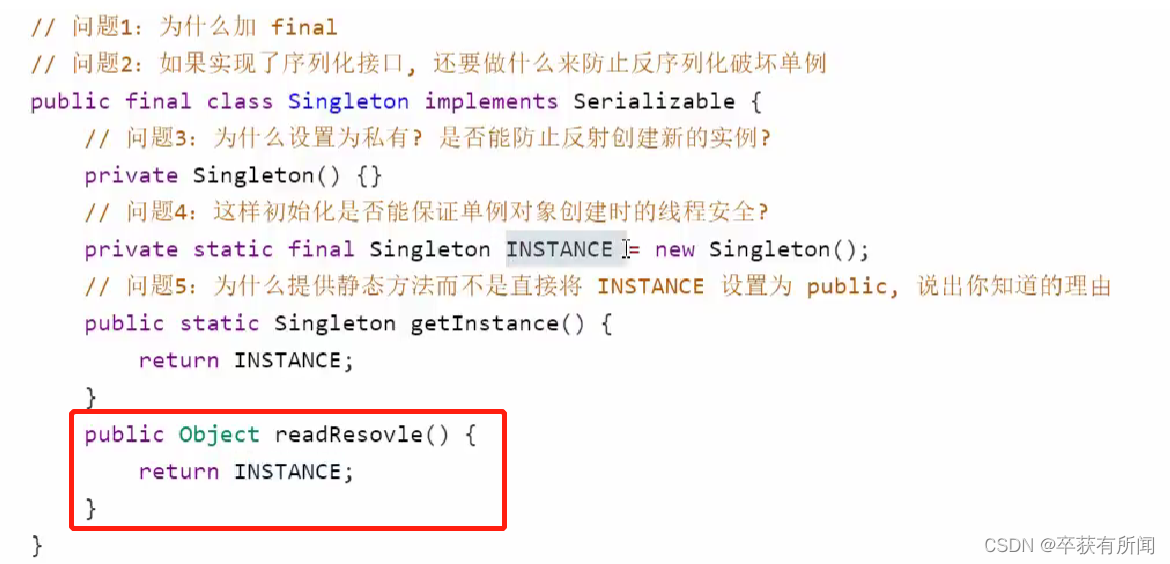
本文演示了如何使用 Kubernetes (K8s) 和分布式 SQL 构建云原生 Node.js 应用程序。
开发可扩展且可靠的应用程序是一项热爱的工作。一个云原生系统可能包括单元测试、集成测试、构建测试,以及用于构建和部署应用程序的完整管道,只需单击一个按钮即可。
可能需要一些中间步骤才能交付可靠的产品。随着分布式和容器化的应用程序涌入市场,像Kubernetes这样的容器编排工具也是如此。Kubernetes 允许我们跨节点集群构建分布式应用程序,具有容错、自我修复和负载平衡——以及许多其他功能。
让我们通过在 Node.js 中构建一个由 YugabyteDB分布式 SQL数据库支持的分布式待办事项列表应用程序来探索其中的一些工具。
入门
生产部署可能会涉及设置完整的CI/CD 管道,以将容器化构建推送到 Google Container Registry,以便在Google Kubernetes Engine或类似的云服务上运行。
出于演示目的,让我们专注于在本地运行类似的堆栈。我们将开发一个简单的 Node.js 服务器,它被构建为一个 docker 镜像,可以在我们机器上的 Kubernetes 上运行。
我们将使用此 Node.js 服务器连接到 YugabyteDB 分布式 SQL 集群并从休息端点返回记录。
安装依赖
我们首先安装一些依赖项来构建和运行我们的应用程序。
-
Docker桌面
-
Docker 用于构建容器映像,我们将在本地托管这些映像。
-
-
Minikube
-
创建一个本地 Kubernetes 集群来运行我们的分布式应用程序
-
YugabyteDB托管
接下来,我们创建一个YugabyteDB托管帐户并在云中启动一个集群。YugabyteDB 与 PostgreSQL 兼容,因此您也可以在其他地方运行 PostgreSQL 数据库,或者如果需要,可以在本地运行 YugabyteDB。
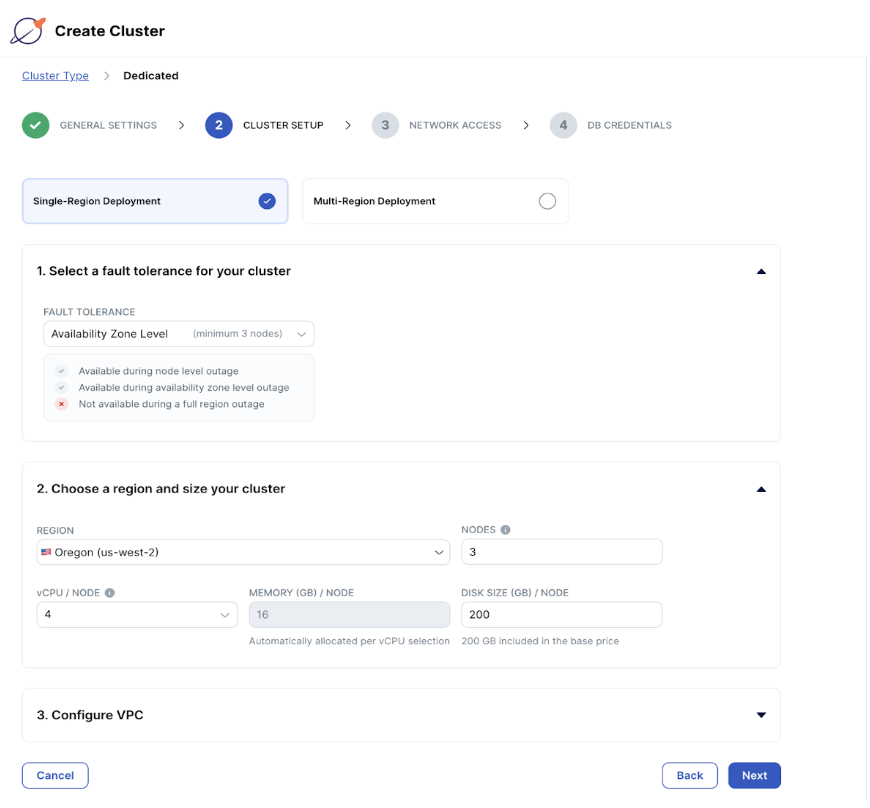
为了实现高可用性,我创建了一个在 AWS 上运行的 3 节点数据库集群,但出于演示目的,一个免费的单节点集群运行良好。
播种我们的数据库
一旦我们的数据库在云中启动并运行,就可以创建一些表和记录了。YugabyteDB Managed 有一个云外壳,可用于通过网络浏览器进行连接,但我选择在本地计算机上使用 YugabyteDB客户端外壳。
在连接之前,我们需要从云控制台下载根证书。
我创建了一个 SQL 脚本用于创建一个todos表和一些记录。
CREATE TYPE todo_status AS ENUM ('complete', 'in-progress', 'incomplete');
CREATE TABLE todos (
id serial PRIMARY KEY,
description varchar(255),
status todo_status
);
INSERT INTO
todos (description, status)
VALUES
(
'Learn how to connect services with Kuberenetes',
'incomplete'
),
(
'Build container images with Docker',
'incomplete'
),
(
'Provision multi-region distributed SQL database',
'incomplete'
);我们可以使用此脚本为我们的数据库播种。
> ./ysqlsh "user=admin \
host=<DATABASE_HOST> \
sslmode=verify-full \
sslrootcert=$PWD/root.crt" -f db.sql为我们的数据库播种后,我们就可以通过 Node.js 连接到它了。
构建 Node.js 服务器
使用 node-postgres 驱动程序连接到我们的数据库很简单。YugabyteDB 在此库之上构建了 YugabyteDB Node.js智能驱动程序,该驱动程序具有解锁分布式 SQL 功能的附加功能,包括负载平衡和拓扑感知。
> npm install express
> npm install @yugabytedb/pg
const express = require("express");
const App = express();
const { Pool } = require("@yugabytedb/pg");
const fs = require("fs");
let config = {
user: "admin",
host: "<DATABASE_HOST>",
password: "<DATABASE_PASSWORD>",
port: 5433,
database: "yugabyte",
min: 5,
max: 10,
idleTimeoutMillis: 5000,
connectionTimeoutMillis: 5000,
ssl: {
rejectUnauthorized: true,
ca: fs.readFileSync("./root.crt").toString(),
servername: "<DATABASE_HOST>",
},
};
const pool = new Pool(config);
App.get("/todos", async (req, res) => {
try {
const data = await pool.query("select * from todos");
res.json({ status: "OK", data: data?.rows });
} catch (e) {
console.log("error in selecting todos from db", e);
res.status(400).json({ error: e });
}
});
App.listen(8000, () => {
console.log("App listening on port 8000");
});容器化我们的 Node.js 应用程序
要在Kubernetes中运行我们的 Node.js 应用程序,我们首先需要构建一个容器镜像。在同一目录中创建一个 Dockerfile。
FROM node:latest
WORKDIR /app
COPY . .
RUN npm install
EXPOSE 8000
ENTRYPOINT [ "npm", "start" ]我们所有的服务器依赖项都将构建到容器映像中。要使用该命令运行我们的应用程序,请使用启动脚本npm start更新您的文件。package.json
…
"scripts": {
"start": "node index.js"
}
…现在,我们已准备好使用 Docker 构建我们的镜像。
> docker build -t todo-list-app .
Sending build context to Docker daemon 458.4MB
Step 1/6 : FROM node:latest
---> 344462c86129
Step 2/6 : WORKDIR /app
---> Using cache
---> 49f210e25bbb
Step 3/6 : COPY . .
---> Using cache
---> 1af02b568d4f
Step 4/6 : RUN npm install
---> Using cache
---> d14416ffcdd4
Step 5/6 : EXPOSE 8000
---> Using cache
---> e0524327827e
Step 6/6 : ENTRYPOINT [ "npm", "start" ]
---> Using cache
---> 09e7c61855b2
Successfully built 09e7c61855b2
Successfully tagged todo-list-app:latest我们的应用程序现已打包并准备好在 Kubernetes 中运行。
使用 Minikube 在本地运行 Kubernetes
要在本地运行 Kubernetes 环境,我们将运行 Minikube,它会在我们机器上运行的 Docker 容器内创建一个 Kubernetes 集群。
> minikube start
那很简单!现在我们可以使用kubectl命令行工具从 Kubernetes 配置文件部署我们的应用程序。
部署到 Kubernetes
首先,我们创建一个名为的配置文件kubeConfig.yaml,它将定义集群的组件。Kubernetes 部署用于保持 pod 运行和最新。todo-app在这里,我们正在创建一个运行我们已经用 Docker 构建的容器的节点集群。
apiVersion: apps/v1
kind: Deployment
metadata:
name: todo-app-deployment
labels:
app: todo-app
spec:
selector:
matchLabels:
app: todo-app
replicas: 3
template:
metadata:
labels:
app: todo-app
spec:
containers:
- name: todo-server
image: todo
ports:
- containerPort: 8000
imagePullPolicy: Never在同一个文件中,我们将创建一个 Kubernetes 服务,用于为您的应用程序设置网络规则并将其公开给客户端。
---
apiVersion: v1
kind: Service
metadata:
name: todo-app-service
spec:
type: NodePort
selector:
app: todo-app
ports:
- name: todo-app-service-port
protocol: TCP
port: 8000
targetPort: 8000
nodePort: 30100
让我们使用我们的配置文件来创建我们的todo-app-deploymentand todo-app-service。这将创建一个网络化的集群,对故障具有弹性并由 Kubernetes 编排!
> kubectl create -f kubeConfig.yaml
在 Minikube 中访问我们的应用程序
> minikube service todo-app-service --url
Starting tunnel for service todo-app-service.
因为你在 darwin 上使用 Docker 驱动程序,所以需要打开终端才能运行它。
我们可以通过执行以下命令找到隧道端口。
> ps -ef | grep docker@127.0.0.1
503 2363 2349 0 9:34PM ttys003 0:00.01 ssh -o UserKnownHostsFile=/dev/null -o StrictHostKeyChecking=no -N docker@127.0.0.1 -p 53664 -i /Users/bhoyer/.minikube/machines/minikube/id_rsa -L 63650:10.107.158.206:8000输出表明我们的隧道在端口 63650 上运行。我们可以通过浏览器中的/todos此URL或通过客户端访问我们的端点。
> curl -X GET http://127.0.0.1:63650/todos -H 'Content-Type: application/json'
{"status":"OK","data":[{"id":1,"description":"Learn how to connect services with Kuberenetes","status":"incomplete"},{"id":2,"description":"Build container images with Docker","status":"incomplete"},{"id":3,"description":"Provision multi-region distributed SQL database","status":"incomplete"}]}
![[n00bzCTF 2023] CPR 全](https://img-blog.csdnimg.cn/9984f416418e43e7837cde50f299679b.png)