文章目录
- 神经网络历史
- 形式神经元模型(M-P模型)
- 感知器
- 多层感知器
- 误差反向传播算法
- 误差函数和激活函数
- 误差函数
- 二次代价函数
- 交叉熵代价函数
- 激活函数
- sigmoid函数
- RELU函数
- 似然函数
- softmax函数
- 随机梯度下降法
- 批量学习方法
- 在线学习
- 小批量梯度下降法
- 学习率
- 自适应调整学习率---AdaGrad方法
神经网络历史
- 提出形式神经元模型(M-P模型)(1943)
- 提出感知器(1958)
- 感知器无法解决线性不可分问题(1969)
- 提出神经认知机(1980)
- 提出霍普菲尔德模型(1982)
- 提出误差反向传播算法(1986)
- 提出卷积神经网络(1989)
- 提出将 预训练和自编码器 与 深度神经网络 相结合(2006)
- 提出在卷积神经网络中引入ReLU作为激活函数(2012)
形式神经元模型(M-P模型)
- 多个输入结点 x i x_i xi 对应一个输出结点
- 每个输入结点乘以连接权重 w i w_i wi,相加得到 y y y
- y大于阈值h,输出1,否则输出0。
感知器
感知器能够通过训练自动确定参数
引入误差修正学习:根据实际输出与期望输出的差值调整权重 w i w_i wi 和阈值 h h h。
多层感知器
由 多层结构的感知器 递阶组成 输入值向前传播的网络。(前馈网络、正向传播网络)
通常采用三层结构:输入层,中间层,输出层。
误差反向传播算法
通过比较实际输出和期望输出得到的误差信号,把误差信号从输出层逐层向前传播得到各层的误差信号,再通过调整各层的连接权重以减小误差。
通过实际输出和期望输出之间的误差 E E E 和梯度进行调整。
例:
y
1
=
w
1
x
+
1
,
w
1
=
2
y
2
=
w
2
y
1
2
,
w
2
=
1
;
y_1 = w_1x + 1,w_1 = 2\\ y_2 = w_2y_1^2,w_2 = 1;
y1=w1x+1,w1=2y2=w2y12,w2=1;
现输入
x
=
1
x = 1
x=1 ,期望输出
y
2
=
3
y_2 = 3
y2=3
代入求得: y 1 = 2 ∗ 1 + 1 = 3 y_1 = 2 * 1 + 1 = 3 y1=2∗1+1=3, y 2 = 1 ∗ 3 2 = 10 y_2 = 1 * 3^2 = 10 y2=1∗32=10
误差 E E E:与期望值相差 3 − 10 = − 7 3-10 = -7 3−10=−7
误差反向传播的梯度:
∂
y
2
∂
w
2
=
y
1
2
=
9
∂
y
2
∂
w
1
=
∂
(
w
1
x
+
1
)
2
∂
w
1
=
2
x
2
w
1
+
2
x
=
6
或
=
∂
y
2
∂
y
1
∂
y
1
∂
w
1
=
2
w
2
y
1
∗
x
=
6
\frac{\partial y_2}{\partial w_2} = y_1^2 = 9 \\ \quad\\ \frac{\partial y_2}{\partial w_1} = \frac{\partial (w_1x+1)^2}{\partial w_1} = 2x^2w_1 + 2x = 6\\ 或\\ =\frac{\partial y_2}{\partial y_1}\frac{\partial y_1}{\partial w_1} = 2w_2y_1 * x= 6
∂w2∂y2=y12=9∂w1∂y2=∂w1∂(w1x+1)2=2x2w1+2x=6或=∂y1∂y2∂w1∂y1=2w2y1∗x=6
梯度的意义:
∂
y
∂
w
:当
w
=
w
+
△
w
,则
y
=
y
+
∂
y
∂
w
△
w
\frac{\partial y}{\partial w}:当w = w + \bigtriangleup w,则y = y + \frac{\partial y}{\partial w}\bigtriangleup w
∂w∂y:当w=w+△w,则y=y+∂w∂y△w
已知:
误差为
−
7
,梯度
∂
y
2
∂
w
2
=
9
,
∂
y
2
∂
w
1
=
6
误差为-7,梯度 \frac{\partial y_2}{\partial w_2} = 9,\frac{\partial y_2}{\partial w_1} =6
误差为−7,梯度∂w2∂y2=9,∂w1∂y2=6
故可修改(
η
表示学习率,设
η
=
1
\eta 表示学习率,设\eta =1
η表示学习率,设η=1 )
w
1
=
w
1
+
η
E
∂
y
2
∂
w
1
=
2
+
1
∗
(
−
7
)
/
6
=
2
−
7
/
6
=
5
/
6
w
2
=
w
2
+
η
E
∂
y
2
∂
w
2
=
1
+
1
∗
(
−
7
)
/
9
=
1
−
7
/
9
=
2
/
9
w_1 = w_1 + \frac{\eta E}{\frac{\partial y_2}{\partial w_1} } = 2 + 1*(-7)/6 = 2 - 7/6= 5/6\\ \quad\\ w_2 = w_2 + \frac{\eta E}{\frac{\partial y_2}{\partial w_2} } = 1 + 1 * (-7)/9 = 1-7/9 = 2/9
w1=w1+∂w1∂y2ηE=2+1∗(−7)/6=2−7/6=5/6w2=w2+∂w2∂y2ηE=1+1∗(−7)/9=1−7/9=2/9
w
1
,
w
2
已被调整为新值,
w
1
=
5
6
,
w
2
=
2
9
w_1,w_2已被调整为新值,w_1 = \frac{5}{6},w_2=\frac{2}{9}
w1,w2已被调整为新值,w1=65,w2=92
将此值带入原式计算,
y
1
=
11
6
,
y
2
=
121
162
y_1 = \frac{11}{6} , y_2 = \frac{121}{162}
y1=611,y2=162121
可看到,
y
2
y_2
y2从原先的
10
10
10 被调整到了
121
/
162
121/162
121/162,可以看到,通过误差反向传播确实可以修正权值
w
1
,
w
2
w_1,w_2
w1,w2。
但是过大的学习率会导致结果过拟合,如上,我们需要最后值为3,但修改后的值甚至小于了1。因此调整合适的学习率
η
\eta
η是必须的。
误差函数和激活函数
【机器学习基础】2、代价函数\损失函数汇总
误差函数
用于计算误差值 E E E
引自:https://www.cnblogs.com/go-ahead-wsg/p/12346744.html
二次代价函数
C = 1 2 n ∑ x 1 , … x n ∥ y ( x ) − a L ( x ) ∥ 2 C=\frac{1}{2 n} \sum_{x_{1}, \ldots x_{n}}\left\|y(x)-a^{L}(x)\right\|^{2} C=2n1x1,…xn∑ y(x)−aL(x) 2
- C表示代价函数
- x表示样本
- y表示实际值
- a表示输出值
- n表示样本的总数;
其中 a = σ ( z ) , z = ∑ w j ∗ x j + b a=\sigma(z), z=\sum w_j*x_j +b a=σ(z),z=∑wj∗xj+b
- a代表激活函数的输出值
- σ代表sigmoid函数
∂ C ∂ w = ( a − y ) σ ′ ( z ) x ∂ C ∂ b = ( a − y ) σ ′ ( z ) \frac {\partial C} {\partial w} = (a-y)\sigma' (z)x \\\quad\\ \frac {\partial C} {\partial b} = (a-y)\sigma' (z) ∂w∂C=(a−y)σ′(z)x∂b∂C=(a−y)σ′(z)
注:由于反向误差梯度与sigmoid函数的导数有关,而sigmoid函数的导数会在值较大时有较小的倒数,故会导致权值调整较小。
如下图所示:
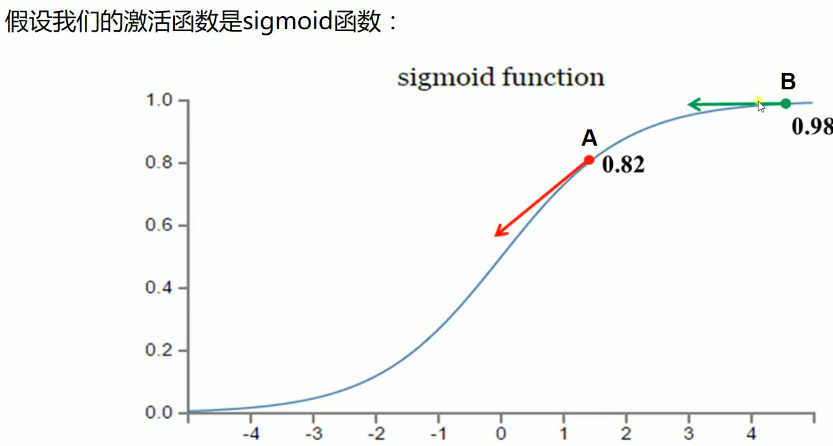
因此引入交叉熵代价函数
交叉熵代价函数
交叉熵代价函数(Cross-entropy cost function)是用来衡量人工神经网络(ANN)的预测值与实际值的一种方式。与二次代价函数相比,它能更有效地促进ANN的训练。
C = − 1 n ∑ x 1 , x n [ y ln a + ( 1 − y ) ln ( 1 − a ) ] C=-\frac{1}{n} \sum_{x_{1}, x_{n}}[y \ln a+(1-y) \ln (1-a)] C=−n1x1,xn∑[ylna+(1−y)ln(1−a)]
- C表示代价函数
- x表示样本
- y表示实际值
- a表示输出值
- n表示样本的总数;
a = σ ( z ) , z = ∑ w j ∗ x j + b σ ′ ( z ) = σ ( z ) ( 1 − σ ( x ) ) a=\sigma(z), z=\sum w_j*x_j +b\\ \quad\\ \sigma'(z) = \sigma(z)(1-\sigma (x)) a=σ(z),z=∑wj∗xj+bσ′(z)=σ(z)(1−σ(x))
梯度求解
∂
C
∂
w
j
=
−
1
n
∑
x
(
y
σ
(
z
)
−
(
1
−
y
)
1
−
σ
(
z
)
)
∂
σ
∂
w
j
=
−
1
n
∑
x
(
y
σ
(
z
)
−
(
1
−
y
)
1
−
σ
(
z
)
)
σ
′
(
z
)
x
j
=
1
n
∑
x
σ
′
(
z
)
x
j
σ
(
z
)
(
1
−
σ
(
z
)
)
(
σ
(
z
)
−
y
)
=
1
n
∑
x
x
j
(
σ
(
z
)
−
y
)
∂
C
∂
b
=
1
n
∑
x
(
σ
(
z
)
−
y
)
\begin{aligned} \frac{\partial C}{\partial w_{j}} & =-\frac{1}{n} \sum_{x}\left(\frac{y}{\sigma(z)}-\frac{(1-y)}{1-\sigma(z)}\right) \frac{\partial \sigma}{\partial w_{j}} \\ & =-\frac{1}{n} \sum_{x}\left(\frac{y}{\sigma(z)}-\frac{(1-y)}{1-\sigma(z)}\right) \sigma^{\prime}(z) x_{j} \\ & =\frac{1}{n} \sum_{x} \frac{\sigma^{\prime}(z) x_{j}}{\sigma(z)(1-\sigma(z))}(\sigma(z)-y) \\ & =\frac{1}{n} \sum_{x} x_{j}(\sigma(z)-y) \\ \frac{\partial C}{\partial b} & =\frac{1}{n} \sum_{x}(\sigma(z)-y) \end{aligned}
∂wj∂C∂b∂C=−n1x∑(σ(z)y−1−σ(z)(1−y))∂wj∂σ=−n1x∑(σ(z)y−1−σ(z)(1−y))σ′(z)xj=n1x∑σ(z)(1−σ(z))σ′(z)xj(σ(z)−y)=n1x∑xj(σ(z)−y)=n1x∑(σ(z)−y)
可以看出:权值
w
w
w 和偏执值
b
b
b 的调整与
σ
′
(
z
)
σ′(z)
σ′(z) 无关,另外,梯度公式中的
σ
(
z
)
−
y
σ(z)−y
σ(z)−y
表示输出值与实际值放入误差。所以当误差越大时,梯度就越大,参数w和b的调整就越快,训练的速度也就越快。
总结:当输出神经元是线性的,那么二次代价函数就是一种合适的选择。如果输出神经元是S型函数,那么比较适合交叉墒代价函数。
激活函数
激活函数类似于人类神经元,对输入信号进行线性或非线性变换。
- M-P模型中使用
step函数作为激活函数 - 多层感知器中使用
sigmoid函数,或tanh函数(双曲正切函数) - 最近几年在深度学习中,修正线性单元(Rectified Linear Unit,ReLU)
sigmoid函数
f
(
u
)
=
1
1
+
e
−
u
u
=
∑
i
=
1
n
w
i
x
i
f(u) = \frac{1}{1+e^{-u}} \\\quad\\ u = \sum_{i=1}^nw_ix_i
f(u)=1+e−u1u=i=1∑nwixi
偏导数:
∂
f
(
u
)
∂
u
=
f
(
u
)
(
1
−
f
(
u
)
)
\frac{\partial f(u)}{\partial u} = f(u)(1-f(u))
∂u∂f(u)=f(u)(1−f(u))
RELU函数
f ( u ) = m a x ( 0 , u ) ∂ f ( u ) ∂ u = 1 f(u) = max(0,u)\\ \quad\\ \frac{\partial f(u)}{\partial u} = 1 f(u)=max(0,u)∂u∂f(u)=1
似然函数
似然函数用于计算多层感知器的输出结果,通常以softmax函数作为似然函数。
softmax函数
p
(
y
k
)
=
e
x
p
(
u
2
k
)
∑
q
=
1
Q
e
x
p
(
u
2
q
)
p(y^k) = \frac{exp(u_{2k})}{\sum_{q=1}^Q exp(u_{2q})}
p(yk)=∑q=1Qexp(u2q)exp(u2k)
softmax函数的分母是对输出层所有单元(q = 1,······,Q)的激活函数值的求和,起到归一化的作用。
随机梯度下降法
使用部分训练样本进行迭代计算,这种方法叫做随机梯度下降法(Stochastic Gradient Descent,SGD),与之相对的是批量学习方法。
批量学习方法
计算时遍历全部训练样本,设第
t
t
t 次迭代各训练样本误差为
E
n
t
E_n^t
Ent ,通过所有误差项计算全部训练样本误差:
E
=
∑
n
=
1
n
E
n
E = \sum_{n=1}^n E_n
E=n=1∑nEn
基于全部训练样本得到权重权重调整值并修正网络连接权重
w
=
w
−
η
∂
E
∂
w
w = w - \eta \frac{\partial E}{\partial w}
w=w−η∂w∂E
然后使用调整后的连接权重测试全部训练样本,如此反复迭代计算权重调整并修正网络。
- 优点:能有效抑制训练集内带噪声的样本所导致的输入模式剧烈变动
- 缺点:每次调整连接权值,所有样本都要参与训练,所有训练时间长
在线学习
逐个输入训练样本
由于在线学习每次迭代计算一个训练样本,所以训练样本的差异会导致结果出现大幅变动。
迭代结果的变动可能导致训练无法收敛。
小批量梯度下降法
介于在线学习和批量学习之间,将训练集分成几个子集D,每次迭代使用一个子集。
小批量下降法能够缩短单次训练时间,又能降低迭代结果的变动。
由于随机梯度下降法只使用部分训练样本,每次迭代后样本集的趋势都会发生变化,所以减少了迭代结果陷入局部最优解的情况。
学习率
用来确定权重连接调整的系数。
如果学习率过大,则有可能修正过头
如果学习率较小,收敛速度会很慢。
自适应调整学习率—AdaGrad方法
用学习率除以截至当前时刻 t t t 的梯度 ▽ E \bigtriangledown E ▽E 的累计值,得到神经网络的连接权重 w w w.
w = w − η ▽ E ( t ) ∑ i = 1 t ( ▽ E ( i ) ) 2 + ε w = w - \eta\frac{\bigtriangledown E^{(t)}}{\sqrt{ \sum_{i=1}^t(\bigtriangledown E^{(i)})^2 +}\varepsilon } w=w−η∑i=1t(▽E(i))2+ε▽E(t)





![[C++11] 智能指针](https://img-blog.csdnimg.cn/a2ac6f2755f94b25b3b5af100288851a.png)