文章目录
- 0x0. 前言
- 0x1. Megatron使用单卡训练GPT2
- 依赖安装
- 准备训练数据
- 训练详细流程和踩坑
- 0x2. Megatron使用单卡预测训练好的GPT2模型
- 0x3. 参数量和显存估计
- 参数量估计
- 训练显存占用估计
- 0x4. Megatron使用多卡训练GPT2模型
- 2卡数据并行
- 2卡模型并行
- 0x5. 总结
0x0. 前言
本文基于DeepSpeedExamples仓库中给出的Megatron相关例子探索一下训练GPT2模型的流程。主要包含3个部分,第一个部分是基于原始的Megatron如何训练GPT2模型,第二个部分是如何结合DeepSpeed的特性进行训练Megatron GPT2,由于篇幅原因这篇文章只写了第一部分,主要是非常细致的记录了跑起来Megatron GPT2训练流程碰到的一些问题和如何解决的。本文主要以 https://github.com/microsoft/DeepSpeedExamples/tree/bdf8e59aede8c8e0577e8d4d557298ca8515268f 这里的codebase展开写作。
0x1. Megatron使用单卡训练GPT2
首先阅读 https://github.com/microsoft/DeepSpeedExamples/tree/bdf8e59aede8c8e0577e8d4d557298ca8515268f/Megatron-LM 这里的README。这里不关注BERT的部分,目的是把GPT2的训练和推理跑起来。
首先提到,Megatron是一款大型且强大的Transformer,这个代码库用于进行大的Transformer语言模型的持续研究。目前,Megatron支持GPT2和BERT的模型并行、多节点训练,并采用混合精度。Megatron的代码库能够使用512个GPU进行8路模型和64路数据并行来高效地训练一个72层、83亿参数的GPT2语言模型。作者发现,更大的语言模型(指的是前面的83亿参数的GPT2)能够在仅5个训练epoch内超越当前GPT2-1.5B wikitext perplexities。
依赖安装
首先进入到Megatron-LM目录,安装一下依赖,pip install -r requirements.txt,注意在requirements.txt里面依赖了TensorFlow,这个是和BERT训练相关,我这里不关心,就不安装TensorFlow了。requiresment.txt的内容如下:
nltk>=3.4
numpy>=1.15.4
pandas>=0.24.0
sentencepiece>=0.1.8
# tensorflow>=1.12.0
boto3==1.11.11
regex==2020.1.8
安装的时候会报错:
ERROR: Could not find a version that satisfies the requirement boto3==1.11.11 (from versions: none)
ERROR: No matching distribution found for boto3==1.11.11
我直接使用 pip install boto3 安装了个最新版本。
接着按照教程,执行bash scripts/pretrain_gpt2.sh。这里有一个PyTorch的报错:
ModuleNotFoundError: No module named 'torch._six'
这个错误是由于PyTorch版本变化产生的,搜索了一下,发现只需要把from torch._six import inf 这行代码改成 from torch import inf 就可以了。继续执行,报错为:AssertionError: make sure to set PATH for wikipedia data_utils/corpora.py 。这是因为在 scripts/pretrain_gpt2.sh 里面指定了训练的数据集为 wikipedia ,所以需要在 DeepSpeedExamples/Megatron-LM/data_utils/corpora.py 这里的 PATH = 'data/wikipedia/wikidump_lines.json' 指定我们本地下载的 wikipedia 数据路径。
准备训练数据
下载数据的时候发现这个 wikipedia 数据实在太大了, 所以改用 webtext 数据集,关于这个数据集 Megatron 的README介绍如下:
“我们”利用公开可用的OpenWebText(https://github.com/eukaryote31/openwebtext)库,该库由jcpeterson(https://github.com/jcpeterson/openwebtext)和eukaryote31(https://github.com/eukaryote31/openwebtext)共同开发,用于下载URL。然后,我们根据我们在openwebtext目录中描述的过程对所有下载的内容进行了过滤、清理和去重。对于截至2018年10月的Reddit URL对应的内容,我们得到了约37GB的内容。37G对于跑训练来说还是太大了,所以我只下载了几十个url中的第一个1url文件。
然后把这个文件复制到Megatron-LM的openwebtxt目录下:
接下来按照 openwebtext 的 README 开始执行。
pip install ftfy langdetect numpy torch pandas nltk sentencepiece boto3 tqdm regex bs4 newspaper3k htmlmin tldextract
git clone https://github.com/mattilyra/LSH
cd LSH
python setup.py install
安装 LSH 碰到了两个 Python 版本不兼容引起的问题:
lsh/cMinhash.cpp:19292:21: error: ‘PyThreadState’ {aka ‘struct _ts’} has no member named ‘exc_type’; did you mean ‘curexc_type’?
19292 | *type = tstate->exc_type;
可以将exc_type替换为curexc_type来解决这个问题。
lsh/cMinhash.cpp:17704:26: error: ‘PyTypeObject’ {aka ‘struct _typeobject’} has no member named ‘tp_print’
17704 | __pyx_type___pyx_array.tp_print = 0;
可以将tp_print替换为tp_vectorcall_offset来解决这个问题。
接下来,执行去重url的命令:
python3 blacklist_urls.py RS_2011-01.bz2.deduped.txt clean_urls.txt
我发现执行这个命令之后clean_urls.txt是空的。看了下代码发现这个脚本要求去重的url文件必须在一个目录下,并且把这个目录的路径传递给脚本。

因此,在当前文件夹下新建一个 urls 目录,把刚才的url文件放进去。如下所示:
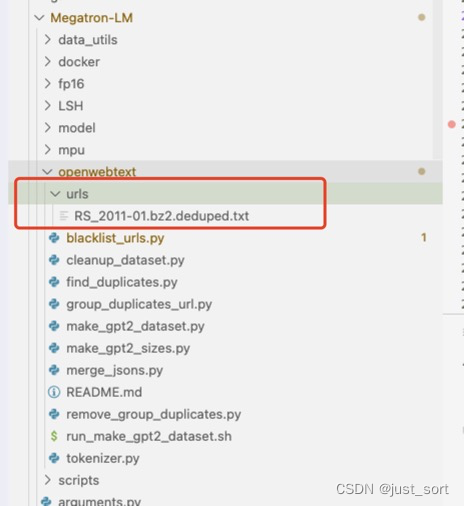
然后执行:python3 blacklist_urls.py urls clean_urls.txt 就可以完成去重了。接下来使用https://github.com/eukaryote31/openwebtext/blob/master/download.py 下载去重后的 url 对应的文本。
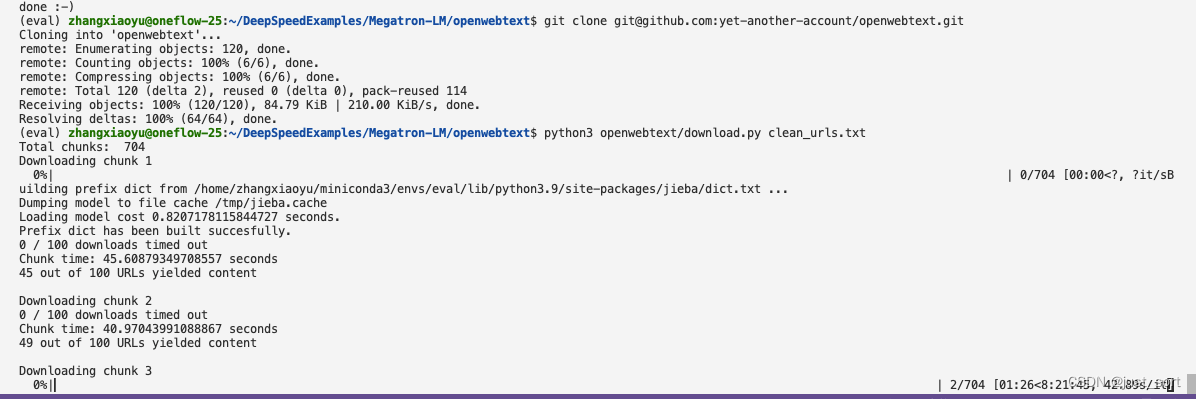
这里要全部下载完需要的时间很长,我只下载50条url对应的数据做一个演示作用。这里要把下载的每条url对应的数据保存为json文件需要修改一下download.py里面的--sqlite_meta和--save_uncompressed默认值,分别改成False和True,这样执行python3 openwebtext/download.py clean_urls.txt 之后就会生成一个scraped文件夹,每个url下载的文本就保存在data子文件夹下:
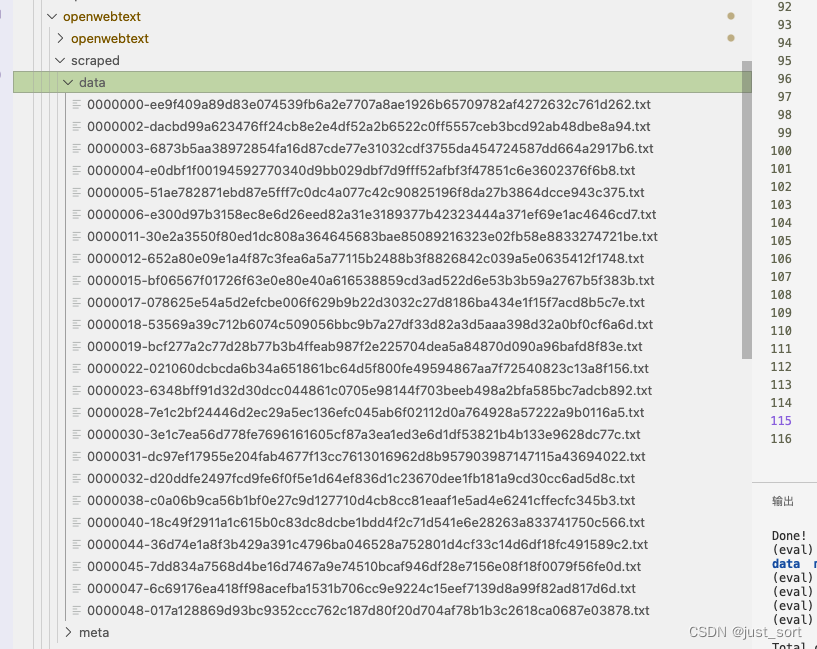
然后我们使用下面的脚本(merge_jsons.py)来把文件夹中的所有txt合并成一个json文件,其中每一行都作为一个text字段对应的内容:
import glob
import sys
import json
import argparse
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument("--data_path", type=str, default=".",
help="path where all the json files are located")
parser.add_argument("--output_file", type=str, default="merged_output.json",
help="filename where the merged json should go")
args = parser.parse_args()
data_path = args.data_path
out_file = args.output_file
text_files = glob.glob(data_path + '/*.txt')
counter = 0
with open(out_file, 'w') as outfile:
for fname in text_files:
counter += 1
if counter % 1024 == 0:
print("Merging at ", counter, flush=True)
with open(fname, 'r') as infile:
for row in infile:
tmp = {}
tmp['text'] = row
outfile.write(json.dumps(tmp))
outfile.write('\n')
print("Merged file", out_file, flush=True)
执行这个脚本获得merged_output.json:python3 merge_jsons.py --data_pathDeepSpeedExamples/Megatron-LM/openwebtext/scraped/data。
接着,我们在openwebtext文件夹下执行一下cleanup_dataset.py来把tokens数量少于128的文本都删掉。python3 cleanup_dataset.py merged_output.json merged_cleand.json。
训练详细流程和踩坑
数据准备好之后,我们修改一下DeepSpeedExamples/Megatron-LM/scripts/pretrain_gpt2.sh下面的--train-data为webtext。此外将DeepSpeedExamples/Megatron-LM/data_utils/corpora.py中webtext类的path设置为我们刚才获得的merged_cleand.json所在的路径。
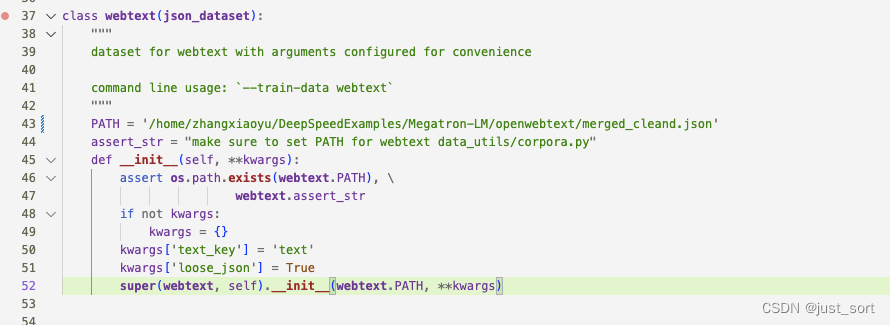
此外,由于我这里只用了几十条数据来做训练过程的演示,这里还需要改一下DeepSpeedExamples/Megatron-LM/scripts/pretrain_gpt2.sh下面的--split参数,将其改成400,300,300,也就是训练,测试,验证集的数据比例为4:3:3,这样才可以避免把测试集的数量设成0。
接下来就可以使用bash scripts/pretrain_gpt2.sh来启动训练了。给一些训练日志出来:
Setting ds_accelerator to cuda (auto detect)
using world size: 1 and model-parallel size: 1
> using dynamic loss scaling
> initializing model parallel with size 1
Pretrain GPT2 model
arguments:
pretrained_bert .............. False
attention_dropout ............ 0.1
num_attention_heads .......... 16
hidden_size .................. 1024
intermediate_size ............ None
num_layers ................... 24
layernorm_epsilon ............ 1e-05
hidden_dropout ............... 0.1
max_position_embeddings ...... 1024
vocab_size ................... 30522
deep_init .................... False
make_vocab_size_divisible_by . 128
cpu_optimizer ................ False
cpu_torch_adam ............... False
fp16 ......................... True
fp32_embedding ............... False
fp32_layernorm ............... False
fp32_tokentypes .............. False
fp32_allreduce ............... False
hysteresis ................... 2
loss_scale ................... None
loss_scale_window ............ 1000
min_scale .................... 1
batch_size ................... 8
weight_decay ................. 0.01
checkpoint_activations ....... True
checkpoint_num_layers ........ 1
deepspeed_activation_checkpointing False
clip_grad .................... 1.0
train_iters .................. 320000
log_interval ................. 100
exit_interval ................ None
seed ......................... 1234
reset_position_ids ........... False
reset_attention_mask ......... False
lr_decay_iters ............... None
lr_decay_style ............... cosine
lr ........................... 0.00015
warmup ....................... 0.01
save ......................... checkpoints/gpt2_345m
save_interval ................ 5000
no_save_optim ................ False
no_save_rng .................. False
load ......................... checkpoints/gpt2_345m
no_load_optim ................ False
no_load_rng .................. False
finetune ..................... False
resume_dataloader ............ True
distributed_backend .......... nccl
local_rank ................... None
eval_batch_size .............. None
eval_iters ................... 100
eval_interval ................ 1000
eval_seq_length .............. None
eval_max_preds_per_seq ....... None
overlapping_eval ............. 32
cloze_eval ................... False
eval_hf ...................... False
load_openai .................. False
temperature .................. 1.0
top_p ........................ 0.0
top_k ........................ 0
out_seq_length ............... 256
model_parallel_size .......... 1
shuffle ...................... False
train_data ................... ['webtext']
use_npy_data_loader .......... False
train_data_path ..............
val_data_path ................
test_data_path ...............
input_data_sizes_file ........ sizes.txt
delim ........................ ,
text_key ..................... sentence
eval_text_key ................ None
valid_data ................... None
split ........................ 400,300,300
test_data .................... None
lazy_loader .................. True
loose_json ................... False
presplit_sentences ........... False
num_workers .................. 2
tokenizer_model_type ......... bert-large-uncased
tokenizer_path ............... tokenizer.model
tokenizer_type ............... GPT2BPETokenizer
cache_dir .................... cache
use_tfrecords ................ False
seq_length ................... 1024
max_preds_per_seq ............ None
deepspeed .................... False
deepspeed_config ............. None
deepscale .................... False
deepscale_config ............. None
deepspeed_mpi ................ False
cuda ......................... True
rank ......................... 0
world_size ................... 1
dynamic_loss_scale ........... True
> initializing model parallel cuda seeds on global rank 0, model parallel rank 0, and data parallel rank 0 with model parallel seed: 3952 and data parallel seed: 1234
configuring data
> padded vocab (size: 50257) with 47 dummy tokens (new size: 50304)
> found end-of-document token: 50256
building GPT2 model ...
> number of parameters on model parallel rank 0: 354871296
Optimizer = FusedAdam
learning rate decaying cosine
WARNING: could not find the metadata file checkpoints/gpt2_345m/latest_checkpointed_iteration.txt
will not load any checkpoints and will start from random
Partition Activations False and Correctness Check False
iteration 100/ 320000 | elapsed time per iteration (ms): 963.3 | learning rate 3.937E-06 | lm loss 8.995377E+00 | loss scale 131072.0 |
/home/zhangxiaoyu/miniconda3/envs/eval/lib/python3.9/site-packages/torch/cuda/memory.py:416: FutureWarning: torch.cuda.memory_cached has been renamed to torch.cuda.memory_reserved
warnings.warn(
/home/zhangxiaoyu/miniconda3/envs/eval/lib/python3.9/site-packages/torch/cuda/memory.py:424: FutureWarning: torch.cuda.max_memory_cached has been renamed to torch.cuda.max_memory_reserved
warnings.warn(
after 100 iterations memory (MB) | allocated: 6784.88427734375 | max allocated: 11927.470703125 | cached: 13826.0 | max cached: 13826.0
time (ms) | forward: 276.11 | backward: 672.99 | allreduce: 13.96 | optimizer: 14.00 | batch generator: 5.22 | data loader: 4.53
iteration 200/ 320000 | elapsed time per iteration (ms): 950.6 | learning rate 8.625E-06 | lm loss 3.041360E+00 | loss scale 131072.0 |
time (ms) | forward: 259.24 | backward: 674.56 | allreduce: 13.45 | optimizer: 16.63 | batch generator: 0.78 | data loader: 0.14
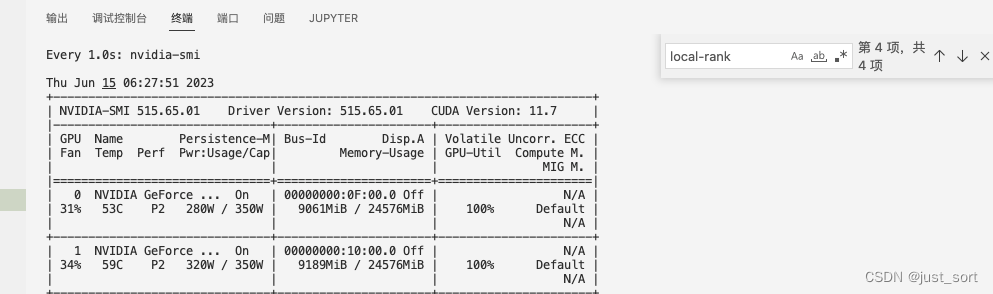
从 nvidia-smi 的截图里也可以看到megatron的训练正在卡0运行:
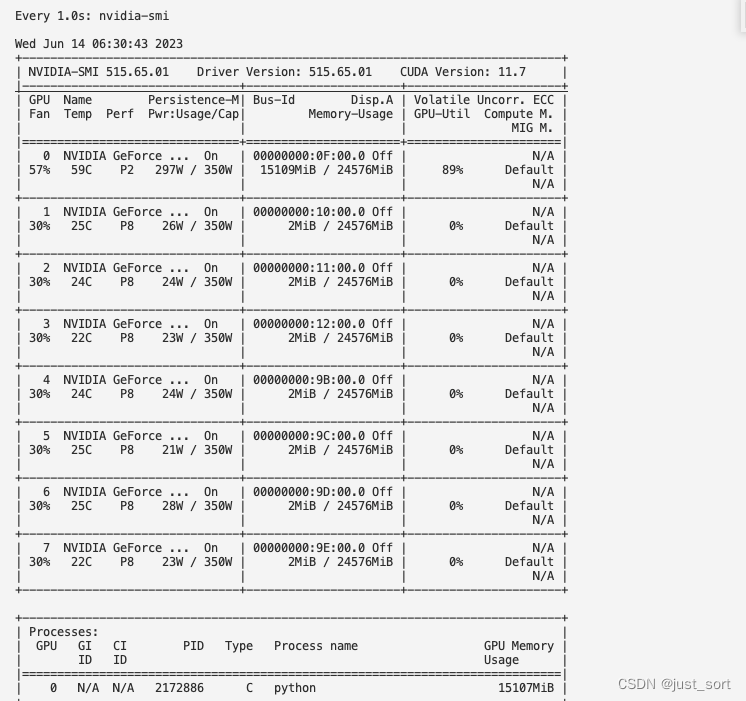
在训练的时候可能会发生下面的 StopIteration 错误:
time (ms) | forward: 259.07 | backward: 671.87 | allreduce: 13.03 | optimizer: 16.64 | batch generator: 0.76 | data loader: 0.13
╭─────────────────────────────── Traceback (most recent call last) ────────────────────────────────╮
│ /home/zhangxiaoyu/DeepSpeedExamples/Megatron-LM/pretrain_gpt2.py:713 in <module> │
│ │
│ 710 │
│ 711 │
│ 712 if __name__ == "__main__": │
│ ❱ 713 │ main() │
│ 714 │
│ │
│ /home/zhangxiaoyu/DeepSpeedExamples/Megatron-LM/pretrain_gpt2.py:686 in main │
│ │
│ 683 │ iteration = 0 │
│ 684 │ if args.train_iters > 0: │
│ 685 │ │ if args.do_train: │
│ ❱ 686 │ │ │ iteration, skipped = train(model, optimizer, │
│ 687 │ │ │ │ │ │ │ │ │ lr_scheduler, │
│ 688 │ │ │ │ │ │ │ │ │ train_data_iterator, │
│ 689 │ │ │ │ │ │ │ │ │ val_data_iterator, │
│ │
│ /home/zhangxiaoyu/DeepSpeedExamples/Megatron-LM/pretrain_gpt2.py:415 in train │
│ │
│ 412 │ report_memory_flag = True │
│ 413 │ while iteration < args.train_iters: │
│ 414 │ │ │
│ ❱ 415 │ │ lm_loss, skipped_iter = train_step(train_data_iterator, │
│ 416 │ │ │ │ │ │ │ │ │ │ model, │
│ 417 │ │ │ │ │ │ │ │ │ │ optimizer, │
│ 418 │ │ │ │ │ │ │ │ │ │ lr_scheduler, │
│ │
│ /home/zhangxiaoyu/DeepSpeedExamples/Megatron-LM/pretrain_gpt2.py:369 in train_step │
│ │
│ 366 │ │
│ 367 │ # Forward model for one step. │
│ 368 │ timers('forward').start() │
│ ❱ 369 │ lm_loss = forward_step(data_iterator, model, args, timers) │
│ 370 │ timers('forward').stop() │
│ 371 │ │
│ 372 │ #print_rank_0("loss is {}".format(lm_loss)) │
│ │
│ /home/zhangxiaoyu/DeepSpeedExamples/Megatron-LM/pretrain_gpt2.py:286 in forward_step │
│ │
│ 283 │ │
│ 284 │ # Get the batch. │
│ 285 │ timers('batch generator').start() │
│ ❱ 286 │ tokens, labels, loss_mask, attention_mask, position_ids = get_batch( │
│ 287 │ │ data_iterator, args, timers) │
│ 288 │ timers('batch generator').stop() │
│ 289 │
│ │
│ /home/zhangxiaoyu/DeepSpeedExamples/Megatron-LM/pretrain_gpt2.py:257 in get_batch │
│ │
│ 254 │ # Broadcast data. │
│ 255 │ timers('data loader').start() │
│ 256 │ if data_iterator is not None: │
│ ❱ 257 │ │ data = next(data_iterator) │
│ 258 │ else: │
│ 259 │ │ data = None │
│ 260 │ timers('data loader').stop() │
│ │
│ /home/zhangxiaoyu/miniconda3/envs/eval/lib/python3.9/site-packages/torch/utils/data/dataloader.p │
│ y:633 in __next__ │
│ │
│ 630 │ │ │ if self._sampler_iter is None: │
│ 631 │ │ │ │ # TODO(https://github.com/pytorch/pytorch/issues/76750) │
│ 632 │ │ │ │ self._reset() # type: ignore[call-arg] │
│ ❱ 633 │ │ │ data = self._next_data() │
│ 634 │ │ │ self._num_yielded += 1 │
│ 635 │ │ │ if self._dataset_kind == _DatasetKind.Iterable and \ │
│ 636 │ │ │ │ │ self._IterableDataset_len_called is not None and \ │
│ │
│ /home/zhangxiaoyu/miniconda3/envs/eval/lib/python3.9/site-packages/torch/utils/data/dataloader.p │
│ y:1318 in _next_data │
│ │
│ 1315 │ │ │ │ # no valid `self._rcvd_idx` is found (i.e., didn't break) │
│ 1316 │ │ │ │ if not self._persistent_workers: │
│ 1317 │ │ │ │ │ self._shutdown_workers() │
│ ❱ 1318 │ │ │ │ raise StopIteration │
│ 1319 │ │ │ │
│ 1320 │ │ │ # Now `self._rcvd_idx` is the batch index we want to fetch │
│ 1321 │
╰──────────────────────────────────────────────────────────────────────────────────────────────────╯
StopIteration
不用担心,这个错误表示的是数据量不够训练这么多个iter,这个发生的原因是因为在构造dataloader的时候使用了torch.utils.data.SequentialSampler对dataset进行采样,这个采样器是根据dataset的长度来采样,所以无法和args.train_iters关联起来,导致训练到很多iter之后数据读完了就抛出StopIteration错误了。
我们调整一下脚本,把iter数改成600,并且把checkpoint的保存间隔设置为500,保证megatron可以存下一个checkpoint。再次运行脚本:
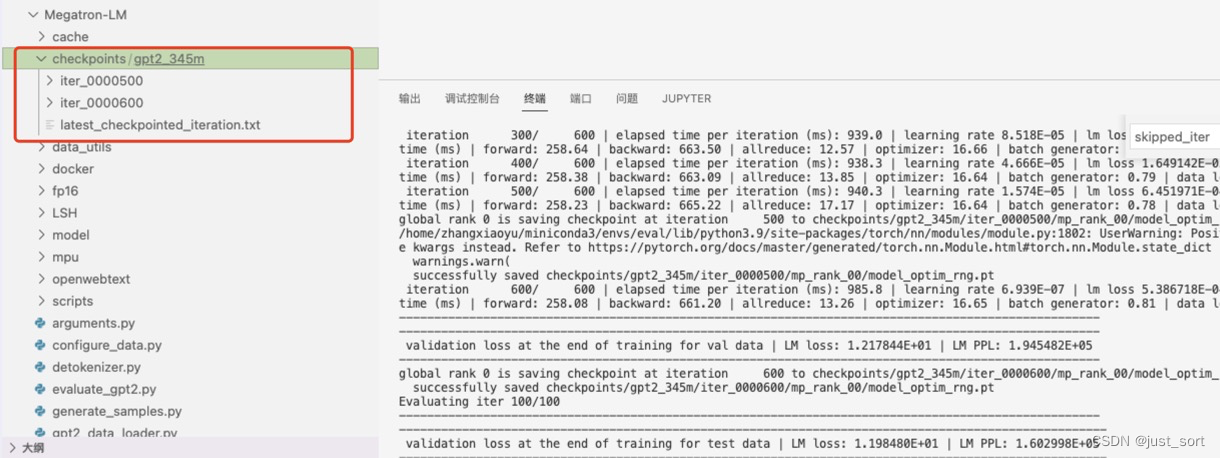
0x2. Megatron使用单卡预测训练好的GPT2模型
修改DeepSpeedExamples/Megatron-LM/scripts/generate_text.sh这里的CHECKPOINT_PATH为我们训练出来的模型路径,我们这里改成DeepSpeedExamples/Megatron-LM/checkpoints/gpt2_345m,然后在Megatron的根目录执行一下:bash scripts/generate_text.sh。但报错了:
Setting ds_accelerator to cuda (auto detect)
Generate Samples
WARNING: No training data specified
using world size: 1 and model-parallel size: 1
> using dynamic loss scaling
> initializing model parallel with size 1
> initializing model parallel cuda seeds on global rank 0, model parallel rank 0, and data parallel rank 0 with model parallel seed: 3952 and data parallel seed: 1234
prepare tokenizer done
building GPT2 model ...
> number of parameters on model parallel rank 0: 354823168
global rank 0 is loading checkpoint /home/zhangxiaoyu/DeepSpeedExamples/Megatron-LM/checkpoints/gpt2_345m/iter_0000600/mp_rank_00/model_optim_rng.pt
╭─────────────────────────────── Traceback (most recent call last) ────────────────────────────────╮
│ /home/zhangxiaoyu/DeepSpeedExamples/Megatron-LM/generate_samples.py:277 in <module> │
│ │
│ 274 │
│ 275 │
│ 276 if __name__ == "__main__": │
│ ❱ 277 │ main() │
│ 278 │
│ 279 │
│ 280 │
│ │
│ /home/zhangxiaoyu/DeepSpeedExamples/Megatron-LM/generate_samples.py:267 in main │
│ │
│ 264 │ tokenizer = prepare_tokenizer(args) │
│ 265 │ │
│ 266 │ # Model, optimizer, and learning rate. │
│ ❱ 267 │ model = setup_model(args) │
│ 268 │ │
│ 269 │ #setting default batch size to 1 │
│ 270 │ args.batch_size = 1 │
│ │
│ /home/zhangxiaoyu/DeepSpeedExamples/Megatron-LM/generate_samples.py:80 in setup_model │
│ │
│ 77 │ model = get_model(args) │
│ 78 │ │
│ 79 │ if args.load is not None: │
│ ❱ 80 │ │ _ = load_checkpoint( │
│ 81 │ │ │ model, None, None, args) │
│ 82 │ │
│ 83 │ return model │
│ │
│ /home/zhangxiaoyu/DeepSpeedExamples/Megatron-LM/utils.py:305 in load_checkpoint │
│ │
│ 302 │ │ │
│ 303 │ │ # Model. │
│ 304 │ │ try: │
│ ❱ 305 │ │ │ model.load_state_dict(sd['model']) │
│ 306 │ │ except KeyError: │
│ 307 │ │ │ print_rank_0('A metadata file exists but unable to load model ' │
│ 308 │ │ │ │ │ │ 'from checkpoint {}, exiting'.format(checkpoint_name)) │
│ │
│ /home/zhangxiaoyu/DeepSpeedExamples/Megatron-LM/model/distributed.py:90 in load_state_dict │
│ │
│ 87 │ │ return sd │
│ 88 │ │
│ 89 │ def load_state_dict(self, state_dict, strict=True): │
│ ❱ 90 │ │ self.module.load_state_dict(state_dict, strict=strict) │
│ 91 │ │
│ 92 │ ''' │
│ 93 │ def _sync_buffers(self): │
│ │
│ /home/zhangxiaoyu/DeepSpeedExamples/Megatron-LM/fp16/fp16.py:71 in load_state_dict │
│ │
│ 68 │ │ return self.module.state_dict(destination, prefix, keep_vars) │
│ 69 │ │
│ 70 │ def load_state_dict(self, state_dict, strict=True): │
│ ❱ 71 │ │ self.module.load_state_dict(state_dict, strict=strict) │
│ 72 │
│ 73 # TODO: Update overflow check + downscale to use Carl's fused kernel. │
│ 74 class FP16_Optimizer(object): │
│ │
│ /home/zhangxiaoyu/miniconda3/envs/eval/lib/python3.9/site-packages/torch/nn/modules/module.py:20 │
│ 41 in load_state_dict │
│ │
│ 2038 │ │ │ │ │ │ ', '.join('"{}"'.format(k) for k in missing_keys))) │
│ 2039 │ │ │
│ 2040 │ │ if len(error_msgs) > 0: │
│ ❱ 2041 │ │ │ raise RuntimeError('Error(s) in loading state_dict for {}:\n\t{}'.format( │
│ 2042 │ │ │ │ │ │ │ self.__class__.__name__, "\n\t".join(error_msgs))) │
│ 2043 │ │ return _IncompatibleKeys(missing_keys, unexpected_keys) │
│ 2044 │
╰──────────────────────────────────────────────────────────────────────────────────────────────────╯
RuntimeError: Error(s) in loading state_dict for GPT2Model:
size mismatch for word_embeddings.weight: copying a param with shape torch.Size([50304, 1024]) from checkpoint, the shape in current model is
torch.Size([50257, 1024]).
可以看到加载模型的时候提示word_embeddings.weight的shape不匹配,我们看一下word_embeddings在GPT2中的定义:

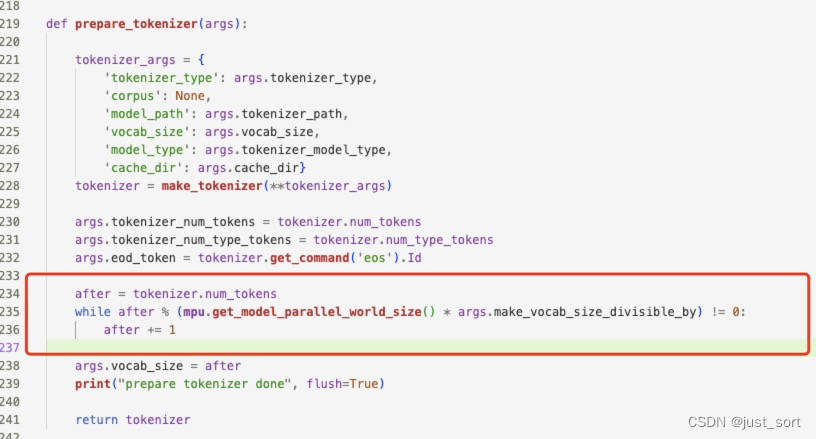
所以这个问题应该是训练和测试的时候的vocab_size不同引起的。定位后发现这是因为训练的时候需要把tokens数num_tokens pad到可以被args.make_vocab_size_divisible_by=128整除,但是预测的时候就没这个限制了,因此导致了embedding的维度不匹配,我们修改一下DeepSpeedExamples/Megatron-LM/generate_samples.py对num_token的处理逻辑,使得和训练一致。
再次执行bash scripts/generate_text.sh,我们就可以和GPT2对话了,输出一条prompt模型会给你不同的补全输出,然后输入stop结束对话。
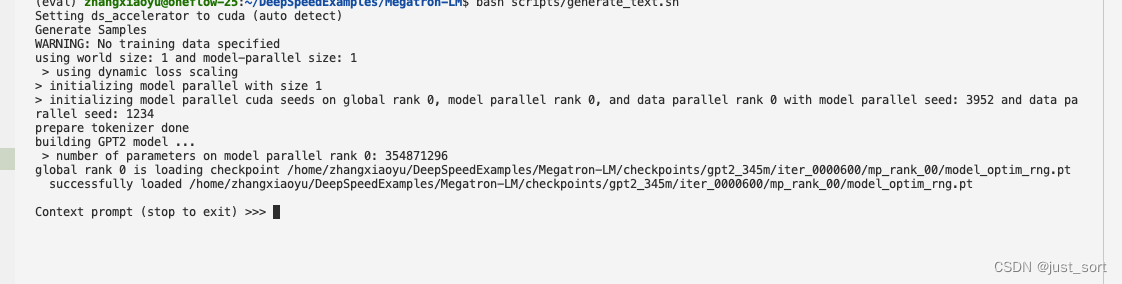
由于这里的模型只用了很少的数据做演示,所以基本没有什么好的补全效果,后面可以加大数据量训练一个更好的GPT2对话模型。
0x3. 参数量和显存估计
在 https://zhuanlan.zhihu.com/p/624740065 这篇文章里面有对 GPT2 这种架构的 Transformer 的参数量和训练显存占用的推导,我们这里套用里面总结的公示计算一下我们当前的GPT2模型的参数量和训练时的理论显存占用。
参数量估计
套用下面的公示: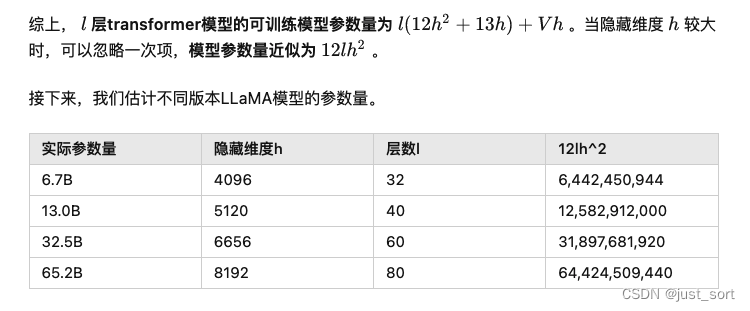
我们这里的:l=24,hidden_size=1024,12lh^2=12x24x1024x1024=301989888=0.3B。所以我们这里训练的GPT2模型只有大约0.3B参数。从模型的命名345M,我们也可以知道这个计算结果和真实大小基本一致。
训练显存占用估计
 根据上述公式,模型参数,梯度,优化器状态在训练时的显存占用大约为301989888*20bytes=6039797760bytes=5898240kb=5760MB=5.6G。然后激活占用的显存如下:
根据上述公式,模型参数,梯度,优化器状态在训练时的显存占用大约为301989888*20bytes=6039797760bytes=5898240kb=5760MB=5.6G。然后激活占用的显存如下:

我们训练的时候 batch_size=8,s=1024,h=1024,a=num-attention-heads=16,l=24,那么
34
b
s
h
+
5
b
s
2
a
=
22951231488
b
y
t
e
s
=
21888
M
i
B
=
21
G
34bsh+5bs^2a=22951231488bytes=21888MiB=21G
34bsh+5bs2a=22951231488bytes=21888MiB=21G。
所以0.3B的GPT2的训练显存占用大约为5.6G+21G=26.6G。但在0x1节中,我们可以看到我们的显卡单卡显存是24G,并且训练过程中的显存消耗只有15107MiB=14.75G,也就是说激活占用的显存并不是我们计算的21G,而是14.75-5.6=9.15G,这是为什么呢?
这是因为在DeepSpeedExamples/Megatron-LM/scripts/pretrain_gpt2.sh里面打开了--checkpoint-activations,做了Activation Checkpoint。我们可以定位到这部分代码,在DeepSpeedExamples/Megatron-LM/mpu/transformer.py:406-413:
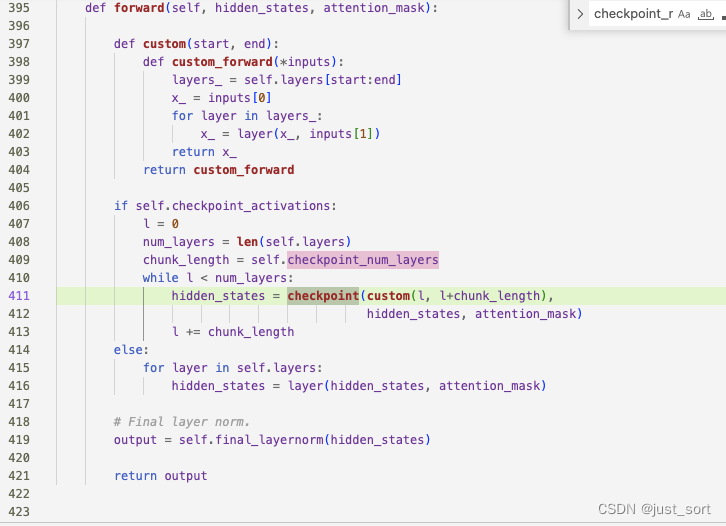
可以看到现在对于每个Transformer层来说,都可以省掉内部Self-Attention和MLP做backward时需要保存的中间激活,达到了减少显存的目的。
0x4. Megatron使用多卡训练GPT2模型
2卡数据并行
上面已经完成了单卡的GPT2模型的训练,启动多卡训练比较简单,修改一下DeepSpeedExamples/Megatron-LM/scripts/pretrain_gpt2_distributed.sh里面的--train-data为webtext,然后--train-iters改成600/num_gpus。实际上这个脚本启动的是数据并行的训练,那么我们只需要把iter数设置为600/num_gpus就可以和单卡扫到一样规模的数据了。训练数据,验证集,测试的配比也要改一下,因为这里只是模拟数据太少了,按照原始的比例会把测试集的数据条数算成0而报错。最后把GPUS_PER_NODE设成2,代表使用2卡进行数据并行训练。接着就可以启动训练了:bash scripts/pretrain_gpt2_distributed.sh,日志如下:
/home/zhangxiaoyu/miniconda3/envs/eval/lib/python3.9/site-packages/torch/distributed/launch.py:181: FutureWarning: The module torch.distributed.launch is deprecated
and will be removed in future. Use torchrun.
Note that --use-env is set by default in torchrun.
If your script expects `--local-rank` argument to be set, please
change it to read from `os.environ['LOCAL_RANK']` instead. See
https://pytorch.org/docs/stable/distributed.html#launch-utility for
further instructions
warnings.warn(
WARNING:torch.distributed.run:
*****************************************
Setting OMP_NUM_THREADS environment variable for each process to be 1 in default, to avoid your system being overloaded, please further tune the variable for optimal performance in your application as needed.
*****************************************
Setting ds_accelerator to cuda (auto detect)
Setting ds_accelerator to cuda (auto detect)
using world size: 2 and model-parallel size: 1
> using dynamic loss scaling
> initializing model parallel with size 1
Pretrain GPT2 model
arguments:
pretrained_bert .............. False
attention_dropout ............ 0.1
num_attention_heads .......... 16
hidden_size .................. 1024
intermediate_size ............ None
num_layers ................... 24
layernorm_epsilon ............ 1e-05
hidden_dropout ............... 0.1
max_position_embeddings ...... 1024
vocab_size ................... 30522
deep_init .................... False
make_vocab_size_divisible_by . 128
cpu_optimizer ................ False
cpu_torch_adam ............... False
fp16 ......................... True
fp32_embedding ............... False
fp32_layernorm ............... False
fp32_tokentypes .............. False
fp32_allreduce ............... False
hysteresis ................... 2
loss_scale ................... None
loss_scale_window ............ 1000
min_scale .................... 1
batch_size ................... 8
weight_decay ................. 0.01
checkpoint_activations ....... True
checkpoint_num_layers ........ 1
deepspeed_activation_checkpointing False
clip_grad .................... 1.0
train_iters .................. 300
log_interval ................. 100
exit_interval ................ None
seed ......................... 1234
reset_position_ids ........... False
reset_attention_mask ......... False
lr_decay_iters ............... None
lr_decay_style ............... cosine
lr ........................... 0.00015
warmup ....................... 0.01
save ......................... checkpoints/gpt2_345m
save_interval ................ 5000
no_save_optim ................ False
no_save_rng .................. False
load ......................... checkpoints/gpt2_345m
no_load_optim ................ False
no_load_rng .................. False
finetune ..................... False
resume_dataloader ............ True
distributed_backend .......... nccl
local_rank ................... 0
eval_batch_size .............. None
eval_iters ................... 100
eval_interval ................ 1000
eval_seq_length .............. None
eval_max_preds_per_seq ....... None
overlapping_eval ............. 32
cloze_eval ................... False
eval_hf ...................... False
load_openai .................. False
temperature .................. 1.0
top_p ........................ 0.0
top_k ........................ 0
out_seq_length ............... 256
model_parallel_size .......... 1
shuffle ...................... False
train_data ................... ['webtext']
use_npy_data_loader .......... False
train_data_path ..............
val_data_path ................
test_data_path ...............
input_data_sizes_file ........ sizes.txt
delim ........................ ,
text_key ..................... sentence
eval_text_key ................ None
valid_data ................... None
split ........................ 400,300,300
test_data .................... None
lazy_loader .................. True
loose_json ................... False
presplit_sentences ........... False
num_workers .................. 2
tokenizer_model_type ......... bert-large-uncased
tokenizer_path ............... tokenizer.model
tokenizer_type ............... GPT2BPETokenizer
cache_dir .................... cache
use_tfrecords ................ False
seq_length ................... 1024
max_preds_per_seq ............ None
deepspeed .................... False
deepspeed_config ............. None
deepscale .................... False
deepscale_config ............. None
deepspeed_mpi ................ False
cuda ......................... True
rank ......................... 0
world_size ................... 2
dynamic_loss_scale ........... True
> initializing model parallel cuda seeds on global rank 0, model parallel rank 0, and data parallel rank 0 with model parallel seed: 3952 and data parallel seed: 1234
configuring data
> padded vocab (size: 50257) with 47 dummy tokens (new size: 50304)
> found end-of-document token: 50256
building GPT2 model ...
> number of parameters on model parallel rank 0: 354871296
Optimizer = FusedAdam
Optimizer = FusedAdam
learning rate decaying cosine
WARNING: could not find the metadata file checkpoints/gpt2_345m/latest_checkpointed_iteration.txt
will not load any checkpoints and will start from random
Partition Activations False and Correctness Check False
iteration 100/ 300 | elapsed time per iteration (ms): 1048.5 | learning rate 1.258E-04 | lm loss 4.799004E+00 | loss scale 32768.0 |
/home/zhangxiaoyu/miniconda3/envs/eval/lib/python3.9/site-packages/torch/cuda/memory.py:416: FutureWarning: torch.cuda.memory_cached has been renamed to torch.cuda.memory_reserved
warnings.warn(
/home/zhangxiaoyu/miniconda3/envs/eval/lib/python3.9/site-packages/torch/cuda/memory.py:424: FutureWarning: torch.cuda.max_memory_cached has been renamed to torch.cuda.max_memory_reserved
warnings.warn(
/home/zhangxiaoyu/miniconda3/envs/eval/lib/python3.9/site-packages/torch/cuda/memory.py:416: FutureWarning: torch.cuda.memory_cached has been renamed to torch.cuda.memory_reserved
warnings.warn(
/home/zhangxiaoyu/miniconda3/envs/eval/lib/python3.9/site-packages/torch/cuda/memory.py:424: FutureWarning: torch.cuda.max_memory_cached has been renamed to torch.cuda.max_memory_reserved
warnings.warn(
after 100 iterations memory (MB) | allocated: 6784.88427734375 | max allocated: 11927.470703125 | cached: 13826.0 | max cached: 13826.0
time (ms) | forward: 284.78 | backward: 749.95 | allreduce: 93.32 | optimizer: 13.60 | batch generator: 14.88 | data loader: 14.19
iteration 200/ 300 | elapsed time per iteration (ms): 1020.9 | learning rate 5.257E-05 | lm loss 7.708308E-02 | loss scale 32768.0 |
time (ms) | forward: 256.87 | backward: 747.37 | allreduce: 93.08 | optimizer: 16.52 | batch generator: 0.71 | data loader: 0.11
iteration 300/ 300 | elapsed time per iteration (ms): 1018.4 | learning rate 1.806E-06 | lm loss 4.669175E-03 | loss scale 32768.0 |
time (ms) | forward: 256.74 | backward: 744.96 | allreduce: 93.51 | optimizer: 16.53 | batch generator: 0.73 | data loader: 0.12
----------------------------------------------------------------------------------------------------
----------------------------------------------------------------------------------------------------
validation loss at the end of training for val data | LM loss: 1.170473E+01 | LM PPL: 1.211437E+05
----------------------------------------------------------------------------------------------------
global rank 0 is saving checkpoint at iteration 300 to checkpoints/gpt2_345m/iter_0000300/mp_rank_00/model_optim_rng.pt
/home/zhangxiaoyu/miniconda3/envs/eval/lib/python3.9/site-packages/torch/nn/modules/module.py:1802: UserWarning: Positional args are being deprecated, use kwargs instead. Refer to https://pytorch.org/docs/master/generated/torch.nn.Module.html#torch.nn.Module.state_dict for details.
warnings.warn(
successfully saved checkpoints/gpt2_345m/iter_0000300/mp_rank_00/model_optim_rng.pt
Evaluating iter 100/100
----------------------------------------------------------------------------------------------------
-----------------------------------------------------------------------------------------------------
validation loss at the end of training for test data | LM loss: 1.169765E+01 | LM PPL: 1.202885E+05
-----------------------------------------------------------------------------------------------------
显存占用截图:
由于是数据并行,单张卡的显存占用和使用单卡进行训练时差不多。
基于数据并行训练出的模型进行推理也可以正常运行:
2卡模型并行
我们使用这个脚本DeepSpeedExamples/Megatron-LM/scripts/pretrain_gpt2_model_parallel.sh来进行2卡的模型并行训练,除了2卡数据并行相关的修改之外我们还需要去掉这个脚本里面的--deepspeed参数,因为要使用上DeepSpeed还需要执行deepspeed的config配置文件。和deepspeed相关的训练特性,我们留到下一篇文章中探索。
使用bash scripts/pretrain_gpt2_model_parallel.sh 启动2卡的模型并行训练。日志:
/home/zhangxiaoyu/miniconda3/envs/eval/lib/python3.9/site-packages/torch/distributed/launch.py:181: FutureWarning: The module torch.distributed.launch is deprecated
and will be removed in future. Use torchrun.
Note that --use-env is set by default in torchrun.
If your script expects `--local-rank` argument to be set, please
change it to read from `os.environ['LOCAL_RANK']` instead. See
https://pytorch.org/docs/stable/distributed.html#launch-utility for
further instructions
warnings.warn(
WARNING:torch.distributed.run:
*****************************************
Setting OMP_NUM_THREADS environment variable for each process to be 1 in default, to avoid your system being overloaded, please further tune the variable for optimal performance in your application as needed.
*****************************************
Setting ds_accelerator to cuda (auto detect)
Setting ds_accelerator to cuda (auto detect)
using world size: 2 and model-parallel size: 2
> using dynamic loss scaling
> initializing model parallel with size 2
Pretrain GPT2 model
arguments:
pretrained_bert .............. False
attention_dropout ............ 0.1
num_attention_heads .......... 16
hidden_size .................. 1024
intermediate_size ............ None
num_layers ................... 24
layernorm_epsilon ............ 1e-05
hidden_dropout ............... 0.1
max_position_embeddings ...... 1024
vocab_size ................... 30522
deep_init .................... False
make_vocab_size_divisible_by . 128
cpu_optimizer ................ False
cpu_torch_adam ............... False
fp16 ......................... True
fp32_embedding ............... False
fp32_layernorm ............... False
fp32_tokentypes .............. False
fp32_allreduce ............... False
hysteresis ................... 2
loss_scale ................... None
loss_scale_window ............ 1000
min_scale .................... 1
batch_size ................... 8
weight_decay ................. 0.01
checkpoint_activations ....... True
checkpoint_num_layers ........ 1
deepspeed_activation_checkpointing False
clip_grad .................... 1.0
train_iters .................. 600
log_interval ................. 100
exit_interval ................ None
seed ......................... 1234
reset_position_ids ........... False
reset_attention_mask ......... False
lr_decay_iters ............... None
lr_decay_style ............... cosine
lr ........................... 0.00015
warmup ....................... 0.01
save ......................... checkpoints/gpt2_345m_mp2
save_interval ................ 5000
no_save_optim ................ False
no_save_rng .................. False
load ......................... checkpoints/gpt2_345m_mp2
no_load_optim ................ True
no_load_rng .................. False
finetune ..................... False
resume_dataloader ............ True
distributed_backend .......... nccl
local_rank ................... 0
eval_batch_size .............. None
eval_iters ................... 100
eval_interval ................ 1000
eval_seq_length .............. None
eval_max_preds_per_seq ....... None
overlapping_eval ............. 32
cloze_eval ................... False
eval_hf ...................... False
load_openai .................. False
temperature .................. 1.0
top_p ........................ 0.0
top_k ........................ 0
out_seq_length ............... 256
model_parallel_size .......... 2
shuffle ...................... False
train_data ................... ['webtext']
use_npy_data_loader .......... False
train_data_path ..............
val_data_path ................
test_data_path ...............
input_data_sizes_file ........ sizes.txt
delim ........................ ,
text_key ..................... sentence
eval_text_key ................ None
valid_data ................... None
split ........................ 400,300,300
test_data .................... None
lazy_loader .................. True
loose_json ................... False
presplit_sentences ........... False
num_workers .................. 2
tokenizer_model_type ......... bert-large-uncased
tokenizer_path ............... tokenizer.model
tokenizer_type ............... GPT2BPETokenizer
cache_dir .................... None
use_tfrecords ................ False
seq_length ................... 1024
max_preds_per_seq ............ None
deepspeed .................... False
deepspeed_config ............. None
deepscale .................... False
deepscale_config ............. None
deepspeed_mpi ................ False
cuda ......................... True
rank ......................... 0
world_size ................... 2
dynamic_loss_scale ........... True
> initializing model parallel cuda seeds on global rank 0, model parallel rank 0, and data parallel rank 0 with model parallel seed: 3952 and data parallel seed: 1234
configuring data
> padded vocab (size: 50257) with 175 dummy tokens (new size: 50432)
> found end-of-document token: 50256
building GPT2 model ...
> number of parameters on model parallel rank 0: 178100224
> number of parameters on model parallel rank 1: 178100224
Optimizer = FusedAdam
learning rate decaying cosine
WARNING: could not find the metadata file checkpoints/gpt2_345m_mp2/latest_checkpointed_iteration.txt
will not load any checkpoints and will start from random
Optimizer = FusedAdam
Partition Activations False and Correctness Check False
s iteration 100/ 600 | elapsed time per iteration (ms): 810.9 | learning rate 1.444E-04 | lm loss 5.023855E+00 | loss scale 8192.0 |
/home/zhangxiaoyu/miniconda3/envs/eval/lib/python3.9/site-packages/torch/cuda/memory.py:416: FutureWarning: torch.cuda.memory_cached has been renamed to torch.cuda.memory_reserved
warnings.warn(
/home/zhangxiaoyu/miniconda3/envs/eval/lib/python3.9/site-packages/torch/cuda/memory.py:424: FutureWarning: torch.cuda.max_memory_cached has been renamed to torch.cuda.max_memory_reserved
warnings.warn(
/home/zhangxiaoyu/miniconda3/envs/eval/lib/python3.9/site-packages/torch/cuda/memory.py:416: FutureWarning: torch.cuda.memory_cached has been renamed to torch.cuda.memory_reserved
warnings.warn(
/home/zhangxiaoyu/miniconda3/envs/eval/lib/python3.9/site-packages/torch/cuda/memory.py:424: FutureWarning: torch.cuda.max_memory_cached has been renamed to torch.cuda.max_memory_reserved
warnings.warn(
after 100 iterations memory (MB) | allocated: 3447.24365234375 | max allocated: 6237.830078125 | cached: 7890.0 | max cached: 7890.0
time (ms) | forward: 252.44 | backward: 550.96 | allreduce: 12.11 | optimizer: 7.26 | batch generator: 7.15 | data loader: 6.35
iteration 200/ 600 | elapsed time per iteration (ms): 844.2 | learning rate 1.210E-04 | lm loss 1.112287E-01 | loss scale 8192.0 |
time (ms) | forward: 242.53 | backward: 589.63 | allreduce: 11.37 | optimizer: 10.92 | batch generator: 4.28 | data loader: 2.71
iteration 300/ 600 | elapsed time per iteration (ms): 824.7 | learning rate 8.518E-05 | lm loss 8.868908E-03 | loss scale 8192.0 |
time (ms) | forward: 240.10 | backward: 572.66 | allreduce: 11.63 | optimizer: 11.32 | batch generator: 3.64 | data loader: 2.12
iteration 400/ 600 | elapsed time per iteration (ms): 790.5 | learning rate 4.666E-05 | lm loss 2.208042E-03 | loss scale 8192.0 |
time (ms) | forward: 233.81 | backward: 547.29 | allreduce: 11.90 | optimizer: 9.11 | batch generator: 1.16 | data loader: 0.21
iteration 500/ 600 | elapsed time per iteration (ms): 792.8 | learning rate 1.574E-05 | lm loss 8.129998E-04 | loss scale 8192.0 |
time (ms) | forward: 234.04 | backward: 549.56 | allreduce: 13.62 | optimizer: 9.02 | batch generator: 0.91 | data loader: 0.16
iteration 600/ 600 | elapsed time per iteration (ms): 787.7 | learning rate 6.939E-07 | lm loss 6.003926E-04 | loss scale 8192.0 |
time (ms) | forward: 234.25 | backward: 544.30 | allreduce: 10.23 | optimizer: 9.00 | batch generator: 0.83 | data loader: 0.12
----------------------------------------------------------------------------------------------------
----------------------------------------------------------------------------------------------------
validation loss at the end of training for val data | LM loss: 1.231077E+01 | LM PPL: 2.220759E+05
----------------------------------------------------------------------------------------------------
global rank 1 is saving checkpoint at iteration 600 to checkpoints/gpt2_345m_mp2/iter_0000600/mp_rank_01/model_optim_rng.pt
global rank 0 is saving checkpoint at iteration 600 to checkpoints/gpt2_345m_mp2/iter_0000600/mp_rank_00/model_optim_rng.pt
/home/zhangxiaoyu/miniconda3/envs/eval/lib/python3.9/site-packages/torch/nn/modules/module.py:1802: UserWarning: Positional args are being deprecated, use kwargs instead. Refer to https://pytorch.org/docs/master/generated/torch.nn.Module.html#torch.nn.Module.state_dict for details.
warnings.warn(
/home/zhangxiaoyu/miniconda3/envs/eval/lib/python3.9/site-packages/torch/nn/modules/module.py:1802: UserWarning: Positional args are being deprecated, use kwargs instead. Refer to https://pytorch.org/docs/master/generated/torch.nn.Module.html#torch.nn.Module.state_dict for details.
warnings.warn(
successfully saved checkpoints/gpt2_345m_mp2/iter_0000600/mp_rank_01/model_optim_rng.pt
successfully saved checkpoints/gpt2_345m_mp2/iter_0000600/mp_rank_00/model_optim_rng.pt
Evaluating iter 100/100
----------------------------------------------------------------------------------------------------
-----------------------------------------------------------------------------------------------------
validation loss at the end of training for test data | LM loss: 1.215604E+01 | LM PPL: 1.902403E+05
-----------------------------------------------------------------------------------------------------
显存占用截图:
由于对模型参数进行了切分,现在单卡的显存占用峰值从数据并行的15个G左右降低到了9个G。
这里如果直接使用这个模型进行推理,会在load checkpoint的时候出现参数和模型定义不匹配的问题。这是因为这个版本的Meagtron代码没有考虑到加载模型并行训练存储下来的模型,所以这里只能通过把两个模型并行的子模型合并为一个完整的单卡模型来让Megatron加载并进行推理。
 但这但本文所在的这份Megatron-LM源码中也没有提供模型合并的工具,所以这里就不对这个模型并行训练的模型进行推理了。如果你想对模型并行训练的checkpoint进行推理,最简单的方法就是直接用nvidia的Megatron-LM的最新代码进行模型训练和推理,它不仅支持模型并行还支持流水并行并且可以加载任意组合并行的模型进行推理。此外,官方Megatron还提供了工具将原始任意模型并行大小和流水并行大小的checkpoint转换为用户指定的模型并行大小和流水并行大小的checkpoint。(https://github.com/NVIDIA/Megatron-LM/tree/main#evaluation-and-tasks) 如下图所示:
但这但本文所在的这份Megatron-LM源码中也没有提供模型合并的工具,所以这里就不对这个模型并行训练的模型进行推理了。如果你想对模型并行训练的checkpoint进行推理,最简单的方法就是直接用nvidia的Megatron-LM的最新代码进行模型训练和推理,它不仅支持模型并行还支持流水并行并且可以加载任意组合并行的模型进行推理。此外,官方Megatron还提供了工具将原始任意模型并行大小和流水并行大小的checkpoint转换为用户指定的模型并行大小和流水并行大小的checkpoint。(https://github.com/NVIDIA/Megatron-LM/tree/main#evaluation-and-tasks) 如下图所示:

0x5. 总结
文章比较长,关于使用DeepSpeed配合Megatron进行训练放在下篇笔记里面探索吧。推荐几个不错的Megatron相关的源码学习博客(前两篇强烈推荐,大家也可以关注下这个博主,感觉博客写得非常好):
- 图解大模型系列之:Megatron源码解读1,分布式环境初始化
- 图解大模型训练之:Megatron源码解读2,模型并行
- [源码解析] 模型并行分布式训练Megatron (1) — 论文&基础
- [源码解析] 模型并行分布式训练Megatron (2) — 整体架构
- [源码解析] 模型并行分布式训练 Megatron (3) —模型并行实现
- [源码解析] 模型并行分布式训练 Megatron (4) — 如何设置各种并行
- [源码解析] 模型并行分布式训练Megatron (5) --Pipedream Flush


![[C++11] 智能指针](https://img-blog.csdnimg.cn/a2ac6f2755f94b25b3b5af100288851a.png)