介绍史上最全PYTHON文件类型读写库大盘点!包含常用和不常用的大量文件格式!文本、音频、视频应有尽有!废话不多说!走起来!
先给大家快捷总结:
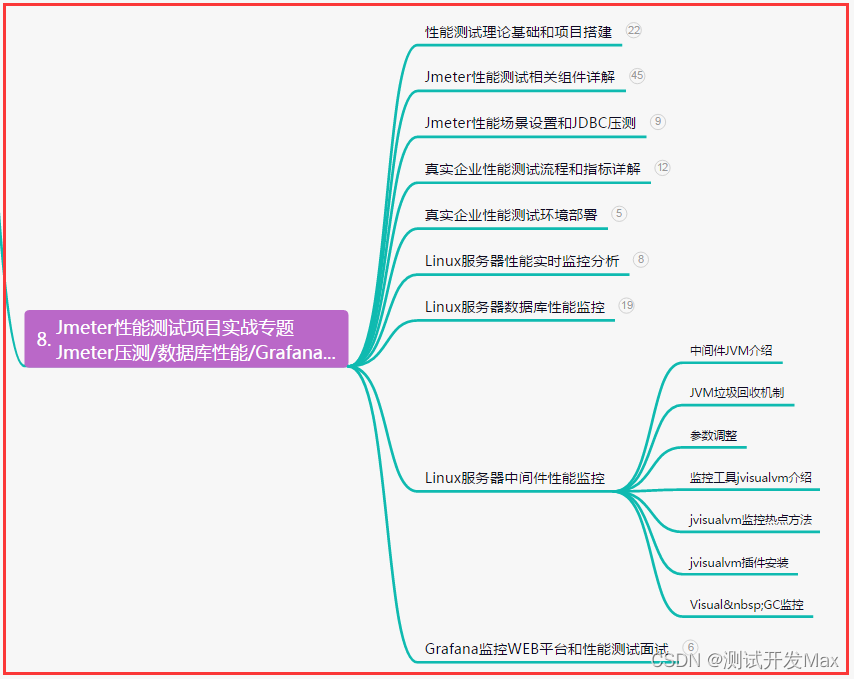
| 文件格式 | Python库 |
|---|---|
| 文本文件 | 内置open函数 |
| CSV文件 | csv |
| JSON文件 | json |
| XML文件 | xml.etree.ElementTree |
| 二进制文件 | 内置open函数 |
| 图片文件 | PIL (Python Imaging Library) |
| Word文件 | python-docx |
| XLSX文件 | openpyxl |
| PDF文件 | PyPDF2 |
| SQLite数据库文件 | sqlite3 |
| 音频文件 | pydub |
| 视频文件 | moviepy |
| HTML文件 | BeautifulSoup |
| YAML文件 | pyyaml |
| ZIP文件 | zipfile |
正文开始!
1. 文本文件
在Python中,处理文本文件是最基础的文件操作,我们使用内置的open函数打开一个文件,然后使用文件对象的read或write方法进行读写操作。
# 写入文本文件
with open('example.txt', 'w') as f:
f.write('Hello, Python!')
# 读取文本文件
with open('example.txt', 'r') as f:
print(f.read())在这里,open函数的第一个参数是文件名,第二个参数是文件模式,其中'r'代表读模式,'w'代表写模式。使用'with'语句可以确保文件在操作完成后被正确关闭。这是一个标准的文件操作模式,也适用于其他类型的文件。
2. CSV文件
CSV(Comma-Separated Values)文件是一种常用的数据交换格式,每行表示一条记录,各字段之间由逗号分隔。Python的csv模块提供了用于读写CSV文件的工具。
import csv
# 写入CSV文件
with open('example.csv', 'w', newline='') as f:
writer = csv.writer(f)
writer.writerow(['name', 'age'])
writer.writerow(['Alice', 20])
writer.writerow(['Bob', 25])
# 读取CSV文件
with open('example.csv', 'r') as f:
reader = csv.reader(f)
for row in reader:
print(row)这里,csv.writer和csv.reader函数分别返回一个写入器和读取器对象,我们可以使用这些对象进行CSV文件的读写操作。
3. JSON文件
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,易于阅读和编写,同时也易于机器解析和生成。Python的json模块提供了用于读写JSON文件的工具。
import json
# 写入JSON文件
data = {
'name': 'Alice',
'age': 20,
}
with open('example.json', 'w') as f:
json.dump(data, f)
# 读取JSON文件
with open('example.json', 'r') as f:
data = json.load(f)
print(data)在这里,json.dump和json.load函数分别用于将Python对象转换为JSON格式并写入文件,以及从文件中读取JSON数据并转换为Python对象。
4. XML文件
XML(eXtensible Markup Language)是一种标记语言,可以用来描述数据的结构。Python的xml模块提供了用于读写XML文件的工具。
from xml.etree import ElementTree as ET
# 写入XML文件
root = ET.Element('root')
child = ET.Element('child')
child.text = 'Hello, Python!'
root.append(child)
tree = ET.ElementTree(root)
tree.write('example.xml')
# 读取XML文件
tree = ET.parse('example.xml')
root = tree.getroot()
for child in root:
print(child.text)在这里,我们使用xml.etree.ElementTree模块创建一个XML文件的树形结构,然后使用ElementTree对象的write方法将其写入文件。读取XML一个ElementTree对象,然后通过遍历这个对象来读取XML数据。
5.二进制文件
二进制文件是直接包含二进制数据的文件,例如图像文件、音频文件等。Python使用'b'模式打开二进制文件,然后使用文件对象的read或write方法进行读写操作。
# 写入二进制文件
data = b'Hello, Python!'
with open('example.bin', 'wb') as f:
f.write(data)
# 读取二进制文件
with open('example.bin', 'rb') as f:
data = f.read()
print(data)在这里,'wb'和'rb'分别代表二进制写模式和二进制读模式。注意我们使用bytes类型的数据进行二进制写操作。
6. 图片文件
处理图片文件一般需要借助第三方库,如PIL(Python Imaging Library)。
from PIL import Image
# 读取图片文件
img = Image.open('example.jpg')
# 修改图片
img = img.rotate(45) # 旋转45度
# 写入图片文件
img.save('example_rotated.jpg')这里,Image.open和Image.save函数分别用于读取和保存图片文件。PIL库提供了丰富的图像处理功能,例如旋转、裁剪、缩放等。
7. Word文件
处理Word文件,我们可以使用python-docx库,这是一个创建、修改和提取Microsoft Word文件的Python库。
|
|
在这里,我们首先创建一个Document对象,然后使用add_paragraph方法添加段落,最后使用save方法保存文档。读取Word文件时,我们遍历Document对象的paragraphs属性,打印出每个段落的文本。
8. XLSX文件
处理Excel文件,我们可以使用openpyxl库,这是一个读写Excel 2010 xlsx/xlsm/xltx/xltm文件的Python库。
from openpyxl import Workbook, load_workbook
# 创建新的Excel文件
wb = Workbook()
ws = wb.active
ws['A1'] = 'Hello,'
ws['B1'] = 'Python!'
wb.save('example.xlsx')
# 读取Excel文件
wb = load_workbook('example.xlsx')
ws = wb.active
print(ws['A1'].value, ws['B1'].value)在这里,我们首先创建一个Workbook对象和Worksheet对象,然后使用字典方式访问单元格并赋值,最后使用save方法保存工作簿。读取Excel文件时,我们使用load_workbook函数加载工作簿,然后访问激活的工作表的单元格。
9. PDF文件
PDF是一种常见的文件格式,我们可以使用Python的PyPDF2库来处理PDF文件。
import PyPDF2
# 读取PDF文件
with open('example.pdf', 'rb') as f:
reader = PyPDF2.PdfFileReader(f)
page = reader.getPage(0)
print(page.extractText())
# 注意:PyPDF2不能直接创建PDF文件,但可以合并、裁剪和旋转PDF文件在这里,我们使用PdfFileReader对象读取PDF文件,然后使用getPage方法获取某一页,最后使用extractText方法提取文本。注意PyPDF2不能直接创建PDF文件,但可以合并、裁剪和旋转PDF文件。
10. SQLite数据库文件
SQLite是一种嵌入式数据库,它的数据库全都保存在一个单独的文件中。Python的sqlite3模块提供了对SQLite数据库的支持。
import sqlite3
# 创建并写入SQLite数据库
conn = sqlite3.connect('example.db')
c = conn.cursor()
c.execute("CREATE TABLE test (name text, age integer)")
c.execute("INSERT INTO test VALUES ('Alice', 20)")
conn.commit()
conn.close()
# 读取SQLite数据库
conn = sqlite3.connect('example.db')
c = conn.cursor()
for row in c.execute("SELECT * FROM test"):
print(row)
conn.close()在这里,我们首先创建一个数据库连接和游标对象,然后使用execute方法执行SQL语句,最后使用commit方法提交事务。读取SQLite数据库时,我们遍历execute方法的结果,打印出每一行。
11. 音频文件
处理音频文件,我们可以使用pydub库,这是一个处理音频的Python库。
from pydub import AudioSegment
# 读取音频文件
audio = AudioSegment.from_file('example.mp3')
# 修改音频
audio = audio.reverse() # 反转音频
# 保存音频文件
audio.export('example_reversed.mp3', format='mp3')在这里,AudioSegment.from_file函数用于读取音频文件。pydub库提供了丰富的音频处理功能,例如反转、裁剪、合并等。最后使用export方法保存音频文件。
12. 视频文件
处理视频文件,我们可以使用moviepy库,这是一个用于视频编辑的Python库。
from moviepy.editor import VideoFileClip
# 读取视频文件
clip = VideoFileClip('example.mp4')
# 修改视频
clip = clip.subclip(10, 20) # 截取第10秒到第20秒的片段
# 保存视频文件
clip.write_videofile('example_subclip.mp4')在这里,VideoFileClip函数用于读取视频文件。moviepy库提供了丰富的视频处理功能,例如裁剪、拼接、添加音频等。最后使用write_videofile方法保存视频文件。
13. HTML文件
HTML是网页的主要构成元素。我们可以使用Python的beautifulsoup库解析HTML文件。
from bs4 import BeautifulSoup
# 读取HTML文件
with open('example.html', 'r') as f:
soup = BeautifulSoup(f, 'html.parser')
# 解析HTML
print(soup.title.text) # 打印标题
# 注意:BeautifulSoup不能直接创建HTML文件,但可以修改HTML文件在这里,我们使用BeautifulSoup对象解析HTML文件,然后通过标签名访问HTML元素。
14. YAML文件
YAML(YAML Ain't Markup Language)是一种直观的数据序列化格式,常用于配置文件。Python的pyyaml库提供了用于读写YAML文件的工具。
import yaml
# 写入YAML文件
data = {'name': 'Alice', 'age': 20}
with open('example.yaml', 'w') as f:
yaml.dump(data, f)
# 读取YAML文件
with open('example.yaml', 'r') as f:
data = yaml.load(f, Loader=yaml.FullLoader)
print(data)在这里,yaml.dump和yaml.load函数分别用于将Python对象转换为YAML格式并写入文件,以及从文件中读取YAML数据并转换为Python对象。
15. ZIP文件
ZIP是一种常用的压缩文件格式。Python的zipfile模块提供了用于读写ZIP文件的工具。
from zipfile import ZipFile
# 创建ZIP文件
with ZipFile('example.zip', 'w') as zf:
zf.write('example.txt')
# 读取ZIP文件
with ZipFile('example.zip', 'r') as zf:
print(zf.namelist())在这里,我们使用ZipFile对象创建一个ZIP文件,然后使用write方法添加文件。读取ZIP文件时,我们使用namelist方法列出所有文件。
One More Thing
在处理文件时,一个常被忽视但又极其有用的技巧是使用Python的pathlib模块来处理文件路径。pathlib模块提供了一种面向对象的方式来处理文件和目录路径,使得路径的处理变得更加直观和简洁。
from pathlib import Path
# 创建Path对象
p = Path('example.txt')
# 检查文件是否存在
if p.exists():
print('File exists.')
# 获取文件的后缀名
print(p.suffix)在这个例子中,我们使用Path对象表示一个文件路径,然后使用Path对象的方法和属性来进行各种操作,例如检查文件是否存在,获取文件的后缀名等。这是一个非常强大且易用的模块,可以极大地提高我们处理文件路径的效率。
以上就是Python全文件格式输入输出的介绍。希望通过本文,你能够对Python的文件操作有更深入的理解,并能够在实际编程中灵活运用。如果你有任何问题或想法,欢迎在评论区留言分享。
感谢每一个认真阅读我文章的人,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走:
资料获取方式:
这份文档和视频资料,对于想从事【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴我走过了最艰难的路程,希望也能帮助到你!以上均可以分享,关注公众号:一个心态巨好的朋友 扣1即可自行领取。