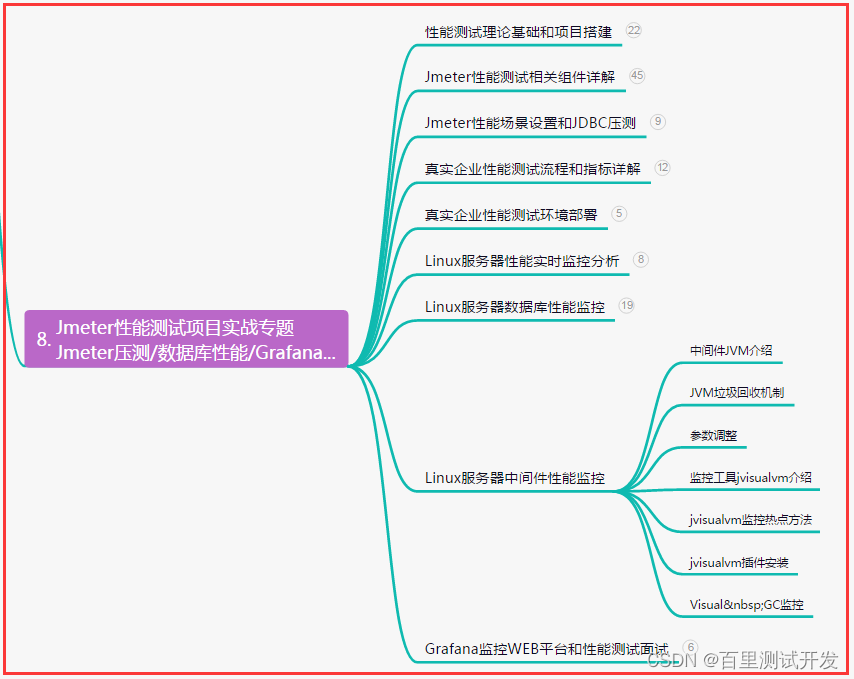
0. 概览
我们在之前三篇博文中已经介绍了如何用多种语言(ruby、swift、c、x64 汇编和 ARM64 汇编)实现一道“超超超难”的剑桥数学面试题:
-
· 有趣的小实验:四种语言搞定“超超超难”剑桥面试数学题
-
· 搞定“超超超难”剑桥面试数学题番外篇:ARM64汇编
-
· 超详细:实现 Swift 与 汇编(Asm)代码混编并在真机或模拟器上运行
在以上这一系列博文中,我们用多种语言生成可执行文件,并分别在多个平台做了性能测试:
- MacBook Pro(Intel i5 2.9GHz)
- MacBook Air (M2)
- iPhone XR
- iPhone 14 Pro Max
现在,我们还想利用 cpu 强大的多核并发执行来进一步提高我们的算法速度。在本篇博文中,我们将使用 swift、c、x64汇编以及 ARM64 汇编语言来完成此“挑战”!
本文用半娱乐的心境写成,不求测试多么精确,但求保持一颗童心,Let‘s go!!!😉
1. 题目回顾

题目很简单:
- 如果 a + b + c + d = 63;
- 求 ab + bc + cd 的最大值;
- 其中 a、b、c、d 都为自然数;
我们假设 0 不属于自然数,即有: a、b、c、d 最小值皆为 1。
2. swift 语言
我们先易后难,先让 swift 打头阵。
swift 语言是并发编程的“绝顶高手”!我们有多种“姿势”可以实现代码并发执行,这里我们使用 async/await 结构化并发来完成它。
使用 Xcode 新建控制台类型项目,并填入如下代码:
import Foundation
typealias GroupNumbers = (a: Int, b: Int, c: Int, d: Int, rlt: Int)
let full_range = 1...63
func calc_max_range(_ r: ClosedRange<Int>) async -> Int {
var max = 0
for a in r {
for b in full_range {
for c in full_range {
for d in full_range {
if a + b + c + d == 63 {
let rlt = a*b + b*c + c*d
if rlt >= max {
max = rlt
}
}
}
}
}
}
return max
}
let group = DispatchGroup()
group.enter()
Task {
async let r0 = calc_max_range(1...15)
async let r1 = calc_max_range(16...30)
async let r2 = calc_max_range(31...45)
async let r3 = calc_max_range(46...63)
let max = await [r0, r1, r2, r3].max()!
print("max is \(max)")
group.leave()
}
group.wait()
使用 Release 配置编译运行,在 M2 上大约耗时 0.017 秒左右。
3. c 语言
c 语言并发编程远比想象的要简单的多,我们可以利用 pthread 库非常容易的把指令流调度到多核上:
#include <stdio.h>
#include <pthread.h>
const int START = 1;
const int END = 63;
typedef struct {
pthread_t id;
int start, end;
int max;
} PInfo;
void *calc_range(void *args) {
int max = 0;
PInfo* info = (PInfo *) args;
for (int a = info->start; a <= info->end; a++) {
for (int b = START; b <= END; b++) {
for (int c = START; c <= END; c++) {
for (int d = START; d < END; d++) {
if(a + b + c + d == 63) {
int rlt = a*b + b*c + c*d;
if(rlt >= max) {
max = rlt;
}
}
}
}
}
}
info->max = max;
pthread_exit(NULL);
}
int main() {
PInfo infos[4] = {
{NULL, 1, 15, 0},
{NULL, 16, 30, 0},
{NULL, 31, 45, 0},
{NULL, 46, END, 0}
};
pthread_create(&infos[0].id, NULL, calc_range, &infos[0]);
pthread_create(&infos[1].id, NULL, calc_range, &infos[1]);
pthread_create(&infos[2].id, NULL, calc_range, &infos[2]);
pthread_create(&infos[3].id, NULL, calc_range, &infos[3]);
int max = 0;
for (int i = 0; i < 4; i++) {
pthread_join(infos[i].id, NULL);
if(infos[i].max > max) {
max = infos[i].max;
}
}
printf("max is %d\n", max);
return 0;
}
因为上面 4 个线程写入结果的地址都不相同,所以不会有数据竞争发生。
使用 O2 选项优化编译代码,同样在 M2 mac 上运行平均耗时 0.015 秒,比 swift 有所进步。
4. x64 汇编
x64 汇编相比较 swift 和 c 两种语言,更显“繁琐”一些。
不过核心思路仍然很简单:我们只需调用系统 fork 功能号创建新线程,并发计算即可。
但是,这样要处理的底层事情太多,不如借助 c 库(pthread)更简单!
# as mt_x64.s -o mt_x64.o
# ld mt_x64.o -lSystem -L `xcrun --show-sdk-path -sdk macosx`/usr/lib -o mt_x64
.equ loop_upper_bound, 63
.equ NULL,0
// PINFO 结构的长度
.equ PINFO_SIZE, pinfo_1 - pinfo_0
// 函数构造器
.macro func_constructor
push %rbp
mov %rsp,%rbp
pushq %rbx
pushq %rdx
.endm
// 函数析构器
.macro func_destructor
popq %rdx
popq %rbx
popq %rbp
.endm
.data
pinfo_0:
// pthread_t, start, end, max
.quad NULL,1,15,0
pinfo_1:
.quad NULL,16,30,0
pinfo_2:
.quad NULL,31,45,0
pinfo_3:
.quad NULL,46,loop_upper_bound,0
max:
.quad 0
string: .asciz "max is %ld\n"
.text
.globl _main
.p2align 4, 0x90
_main:
func_constructor
leaq pinfo_0(%rip),%rdi
movq $0,%rsi
leaq calc_max_in_range_func(%rip),%rdx
movq %rdi,%rcx
// pthread_create(rdi,rsi,rdx,rcx)
call _pthread_create
leaq pinfo_1(%rip),%rdi
movq $0,%rsi
leaq calc_max_in_range_func(%rip),%rdx
movq %rdi,%rcx
call _pthread_create
leaq pinfo_2(%rip),%rdi
movq $0,%rsi
leaq calc_max_in_range_func(%rip),%rdx
movq %rdi,%rcx
call _pthread_create
leaq pinfo_3(%rip),%rdi
movq $0,%rsi
leaq calc_max_in_range_func(%rip),%rdx
movq %rdi,%rcx
call _pthread_create
movq pinfo_0(%rip),%rdi
xorq %rsi,%rsi
// pthread_join(rdi,rsi)
call _pthread_join
movq pinfo_1(%rip),%rdi
xorq %rsi,%rsi
call _pthread_join
movq pinfo_2(%rip),%rdi
xorq %rsi,%rsi
call _pthread_join
movq pinfo_3(%rip),%rdi
xorq %rsi,%rsi
call _pthread_join
// i in rax, pinfo addr in rbx, max in r11
movq $3,%rax
leaq pinfo_0(%rip),%rbx
mov 24(%rbx),%r11
1:
addq $PINFO_SIZE,%rbx
mov 24(%rbx),%r12
cmpq %r12,%r11
jg 2f
mov %r12,%r11
2:
dec %rax
jz 3f
jmp 1b
3:
movq %r11,%rsi
lea string(%rip),%rdi
callq _printf
func_destructor
xor %rax,%rax
ret
.pushsection "__TEXT", "__text"
// void *calc_max_in_range(void *arg);
calc_max_in_range_func:
func_constructor
// void *arg in %rdi
// rax: start, r12: a loop end
movq 8(%rdi),%rax
movq 16(%rdi),%r12
mov $1,%rbx
mov %rbx,%rcx
mov %rbx,%rdx
// max in r11
xor %r11,%r11
start_a_loop:
cmpq %r12,%rax
jg end_a_loop
start_b_loop:
cmpq $loop_upper_bound,%rbx
jg end_b_loop
start_c_loop:
cmpq $loop_upper_bound,%rcx
jg end_c_loop
start_d_loop:
cmpq $loop_upper_bound,%rdx
jg end_d_loop
# if a + b + c + d == 63
xorq %r8,%r8
add %rax,%r8
add %rbx,%r8
add %rcx,%r8
add %rdx,%r8
cmpq $loop_upper_bound,%r8
jne not_equ_63
# == 63, 计算 a*b + b*c + c*d 放到 r8 中
mov %rax,%r8
imul %rbx,%r8
mov %r8,%r9
mov %rbx,%r8
imul %rcx,%r8
mov %r8,%r10
mov %rcx,%r8
imul %rdx,%r8
addq %r9,%r8
addq %r10,%r8
cmpq %r11,%r8
jl not_equ_63
# 更新 max 值
mov %r8,%r11
not_equ_63:
incq %rdx
jmp start_d_loop
end_d_loop:
mov $1,%rdx
incq %rcx
jmp start_c_loop
end_c_loop:
mov $1,%rcx
incq %rbx
jmp start_b_loop
end_b_loop:
mov $1,%rbx
incq %rax
jmp start_a_loop
end_a_loop:
mov %r11,24(%rdi)
func_destructor
xorq %rax,%rax
ret
.popsection
咋一看上面代码很长,但其本质很简单,我们在关键处做了注释,方便大家阅览。
使用调试器加载运行 x64 汇编代码生成的可执行文件,在第一个 pthread_join 函数下断点,中断后可以发现我们的计算确是在多个线程上并发进行的:

汇编代码在 MBP(intel i5)上大约耗时 0.025 秒。
我们可以在 Silicon 芯片的 mac 上使用交叉编译来处理上述 x64 汇编代码,然后利用 Rosetta 2 来运行它:
// 使用 x86_64 架构编译代码
as x64.s -arch x86_64 -o x64.o
ld x64.o -lSystem -L `xcrun --show-sdk-path -sdk macosx`/usr/lib -o x64
运行发现耗时仅 0.023 秒左右,在 M2 上翻译执行的速度反而要比在 intel cpu 上原生执行还要快,只能说那台 intel MBP “廉颇老矣”…
为了证明上面 x64 汇编产生的可执行文件的确是 intel x64 指令集,我们可以用 otool 工具来验证一下:
hopy@Love2 asm % otool -tvV x64
x64:
(__TEXT,__text) section
_main:
0000000100003de0 pushq %rbp
0000000100003de1 movq %rsp, %rbp
0000000100003de4 pushq %rbx
0000000100003de5 pushq %rdx
0000000100003de6 leaq pinfo_0(%rip), %rdi
0000000100003ded movq $NULL, %rsi
0000000100003df4 leaq calc_max_in_range_func(%rip), %rdx
0000000100003dfb movq %rdi, %rcx
0000000100003dfe callq 0x100003edc ## symbol stub for: _pthread_create
0000000100003e03 leaq pinfo_1(%rip), %rdi
0000000100003e0a movq $NULL, %rsi
0000000100003e11 leaq calc_max_in_range_func(%rip), %rdx
0000000100003e18 movq %rdi, %rcx
0000000100003e1b callq 0x100003edc ## symbol stub for: _pthread_create
0000000100003e20 leaq pinfo_2(%rip), %rdi
0000000100003e27 movq $NULL, %rsi
0000000100003e2e leaq calc_max_in_range_func(%rip), %rdx
0000000100003e35 movq %rdi, %rcx
0000000100003e38 callq 0x100003edc ## symbol stub for: _pthread_create
0000000100003e3d leaq pinfo_3(%rip), %rdi
0000000100003e44 movq $NULL, %rsi
0000000100003e4b leaq calc_max_in_range_func(%rip), %rdx
0000000100003e52 movq %rdi, %rcx
0000000100003e55 callq 0x100003edc ## symbol stub for: _pthread_create
0000000100003e5a movq pinfo_0(%rip), %rdi
0000000100003e61 xorq %rsi, %rsi
0000000100003e64 callq 0x100003ee2 ## symbol stub for: _pthread_join
0000000100003e69 movq pinfo_1(%rip), %rdi
0000000100003e70 xorq %rsi, %rsi
0000000100003e73 callq 0x100003ee2 ## symbol stub for: _pthread_join
0000000100003e78 movq pinfo_2(%rip), %rdi
0000000100003e7f xorq %rsi, %rsi
0000000100003e82 callq 0x100003ee2 ## symbol stub for: _pthread_join
0000000100003e87 movq pinfo_3(%rip), %rdi
0000000100003e8e xorq %rsi, %rsi
0000000100003e91 callq 0x100003ee2 ## symbol stub for: _pthread_join
0000000100003e96 movq $0x3, %rax
0000000100003e9d leaq pinfo_0(%rip), %rbx
0000000100003ea4 movq 0x18(%rbx), %r11
0000000100003ea8 addq $0x20, %rbx
0000000100003eac movq 0x18(%rbx), %r12
0000000100003eb0 cmpq %r12, %r11
0000000100003eb3 jg 0x100003eb8
0000000100003eb5 movq %r12, %r11
0000000100003eb8 decq %rax
0000000100003ebb je 0x100003ebf
0000000100003ebd jmp 0x100003ea8
0000000100003ebf movq %r11, %rsi
0000000100003ec2 leaq string(%rip), %rdi
0000000100003ec9 callq 0x100003ed6 ## symbol stub for: _printf
0000000100003ece popq %rdx
0000000100003ecf popq %rbx
0000000100003ed0 popq %rbp
0000000100003ed1 xorq %rax, %rax
0000000100003ed4 retq
看到了吗?百分之百纯正 intel x64 指令!😉
5. ARM64 汇编
现在,让最后一位选手 ARM64 登场吧。
ARM64 和 x64 汇编都可以用 as 汇编器(Mac OS X Mach-O GNU-based assemblers)编译成目标文件。我们还可以利用 as 的 arch 选项实现跨平台交叉编译。
比如,我们在 intel Mac 上可以利用如下命令编译 ARM64 格式的汇编代码:
as test_arm64.s -arch arm64 -o arm64.o
类似的,前面我们也讨论过如何在 M2 Mac 上编译执行 x64 汇编代码。
下面,我们就用 ARM64 汇编代码实现多线程并发计算:
# as mt_arm64.s -o mt_arm64.o
# ld mt_arm64.o -lSystem -L `xcrun --show-sdk-path -sdk macosx`/usr/lib -o mt_arm64
# mt_arm64.s
.equ loop_upper_bound, 63
.equ NULL,0
// 函数构造器
.macro func_constructor
sub sp,sp,#32
stp x29,x30,[sp,#16]
add x29,sp,#16
.endm
// 函数析构器
.macro func_destructor
ldp x29,x30,[sp,#16]
add sp,sp,#32
.endm
.data
pinfo_0:
// pthread_t, start, end, max
.quad NULL,1,15,0
pinfo_1:
.quad NULL,16,30,0
pinfo_2:
.quad NULL,31,45,0
pinfo_3:
.quad NULL,46,loop_upper_bound,0
.text
.globl _main
.p2align 2
// *******************************************************************
_main:
func_constructor
adrp x0,pinfo_0@PAGE
add x0,x0,pinfo_0@PAGEOFF
mov x19,x0
mov x1,#0
adr x2,_calc_max_thread_func
mov x3,x19
bl _pthread_create
add x5,x19,#32
mov x0,x5
mov x1,#0
adr x2,_calc_max_thread_func
mov x3,x5
bl _pthread_create
add x5,x19,#64
mov x0,x5
mov x1,#0
adr x2,_calc_max_thread_func
mov x3,x5
bl _pthread_create
add x5,x19,#96
mov x0,x5
mov x1,#0
adr x2,_calc_max_thread_func
mov x3,x5
bl _pthread_create
ldr x0,[x19]
mov x1,xzr
bl _pthread_join
add x5,x19,#32
ldr x0,[x5]
mov x1,xzr
bl _pthread_join
add x5,x19,#64
ldr x0,[x5]
mov x1,xzr
bl _pthread_join
add x5,x19,#96
ldr x0,[x5]
mov x1,xzr
bl _pthread_join
mov x11,xzr
mov x0,4
0:
ldr x1,[x19,24]
cmp x11,x1
b.ge 1f
mov x11,x1
1:
subs x0,x0,1
b.eq 2f
add x19,x19,#32
b 0b
2:
adr x0,string
str x11,[sp]
bl _printf
func_destructor
mov x0,xzr
ret
// *******************************************************************
// void *calc_max_thread_func(void *arg)
_calc_max_thread_func:
func_constructor
str x0,[x29,#-8]
mov x12,x0
ldr x0,[x12,#8]
ldr x1,[x12,#16]
bl _calc_max_in_range
ldr x12,[x29,#-8]
str x0,[x12,#24]
func_destructor
mov x0,NULL
ret
// *******************************************************************
.pushsection "__TEXT", "__text"
// long calc_max_in_range(long start, long end);
_calc_max_in_range:
func_constructor
// start in x0, end in x1
mov x12,x1 // a loop end in x12
mov x1,#1 // b in x1
mov x2,x1 // c in x2
mov x3,x1 // d in x3
mov x11,xzr // max in x11
1:
cmp x0,x12
b.hi 9f
2:
cmp x1,loop_upper_bound
b.hi 8f
3:
cmp x2,loop_upper_bound
b.hi 7f
4:
cmp x3,loop_upper_bound
b.hi 6f
// 计算 a + b + c + d 的值
add x4,x0,x1
add x4,x4,x2
add x4,x4,x3
cmp x4,loop_upper_bound
b.ne 5f
// 若等于 a + b + c + d = 63,则计算 ab + bc + cd 的值 x
mul x4,x0,x1
mul x5,x1,x2
mul x6,x2,x3
add x5,x5,x6
add x4,x4,x5
// 若 x > max ,则需要更新 max 为 x 值
cmp x4,x11
b.ls 5f
mov x11,x4
5:
add x3,x3,#1
b 4b
6:
mov x3,#1
add x2,x2,#1
b 3b
7:
mov x2,#1
add x1,x1,#1
b 2b
8:
mov x1,#1
add x0,x0,#1
b 1b
9:
func_destructor
mov x0,x11
ret
.popsection
string: .asciz "max is %ld\n"
如上所示:ARM64 汇编语言的数据格式和 x64 汇编没有什么差别,不过指令语法、函数构造器和析构器等还是有很大不同的。
将上述代码编译链接为可执行文件,在 M2 MBA 上运行耗时大约在 0.015 秒左右,和 c 旗鼓相当。
之前在 M2 上单线程执行算法耗时将近 0.03 秒之多,现在快了 1 倍!可见 Silicon 芯片上多核并发执行就是“香”啊!
值得一提的是,因为 的A系列处理器(比如 iPhone14 Pro Max 的 A16)同样兼容 ARM64 指令集,所以上述代码同样可以运行在 iPhone 真机上。
6. 总结
在本篇博文中,我们使用并行算法(swift、c、x64汇编和 ARM64 汇编)充分“榨干” 了 cpu ,进一步提高了原算法的速度,棒棒哒!
感谢观赏,再会!😎