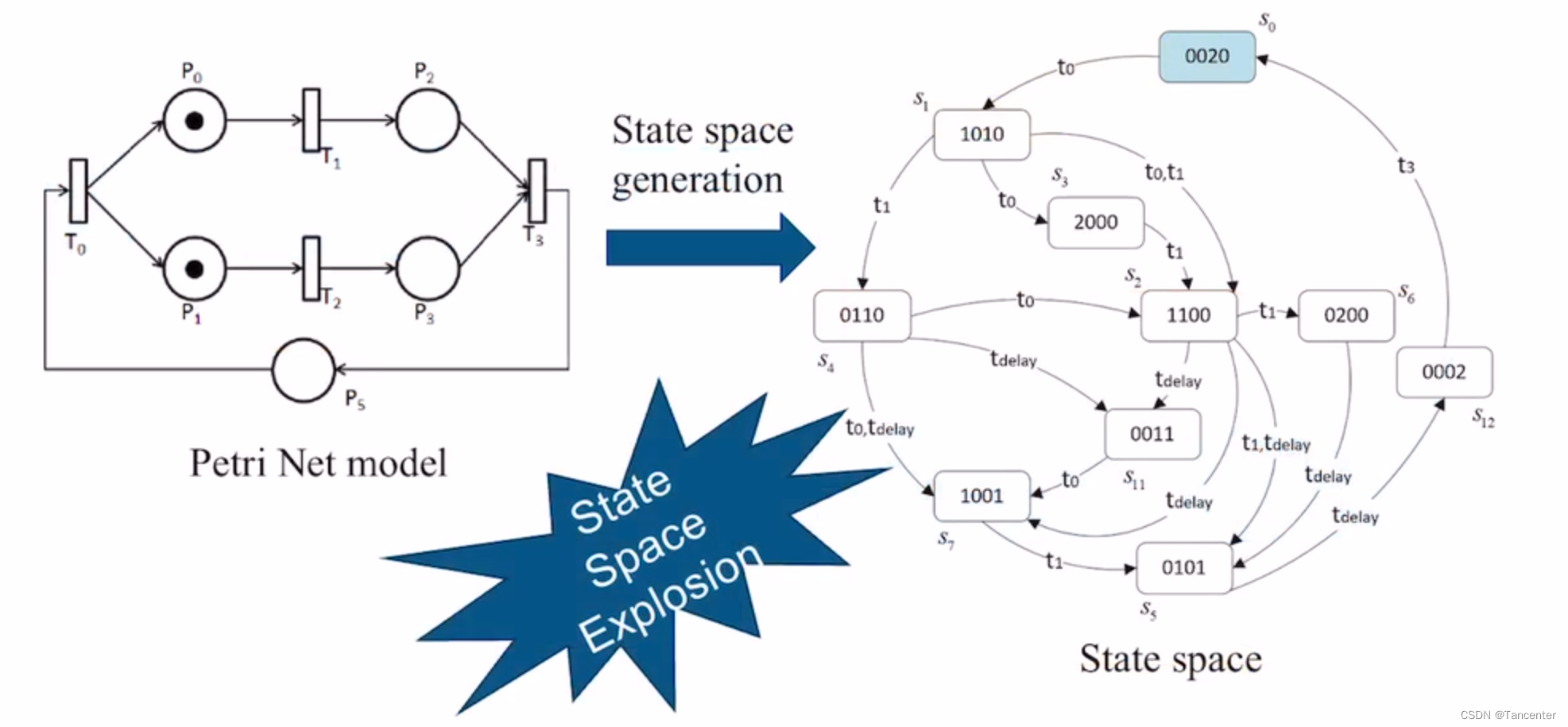
Kafka是一个高吞吐量、基于ZooKeeper(ZooKeeper维护Kafka的broker信息)的分布式发布订阅信息系统,它可以处理消费者在网站中的所有动作(网页浏览,搜索和其他用户的行动)流数据。通常情况下,使用Kafka构建系统或应用程序之间的数据管道,用来转换或响应实时数据,使数据能够及时地进行业务计算,得出相应结果。
一、Kafka集群部署
-
下载Kafka
访问Apache资源网站下载Linux操作系统的Kafka安装包kafka_2.11-2.0.0.tgz。 -
上传Kafka安装包
使用SecureCRT远程连接工具连接虚拟机Spark01,在存放应用安装包的目录/export/software/下执行“rz”命令上传Kafka安装包。 -
安装Kafka
在虚拟机Spark01中,通过解压缩的方式安装Kafka,将Kafka安装到存放应用的目录/export/servers/。
tar -zxvf /export/software/kafka_2.11-2.0.0.tgz -C /export/servers/ -
修改配置文件server.properties
在Kafka安装目录下的config目录,执行“vi server.properties”命令编辑Kafka配置文件server.properties,配置Kafka的相关参数。
broker.id=0
listeners=PLAINTEXT://spark01:9092
log.dirs=/export/data/kafka
zookeeper.connect=spark01:2181,spark02:2181,spark03:2181/kafka
broker.id:broker的全局唯一编号,每个kafka节点的编号值不能重复。
listeners:定义外部连接者通过指定主机名和端口号访问开放的Kafka服务。
log.dirs:存储Kafka日志存储目录。
zookeeper.connect:配置ZooKeeper集群地址。
- 分发Kafka安装包
为了便于快速配置集群中其它服务器,将虚拟机Spark01中的Kafka安装目录分发到虚拟机Spark02和Spark03。
scp -r /export/servers/kafka_2.11-2.0.0/ root@spark02:/export/servers/
scp -r /export/servers/kafka_2.11-2.0.0/ root@spark03:/export/servers/
Kafka安装包分发完成后,需要分别在虚拟机Spark02和虚拟机Spark03中修改配置文件内容,将参数broker.id的值分别修改为“1”和“2”,参数listeners的值分别修改为“PLAINTEXT://spark02:9092”和“PLAINTEXT://spark03:9092”。
二、启动Kafka集群
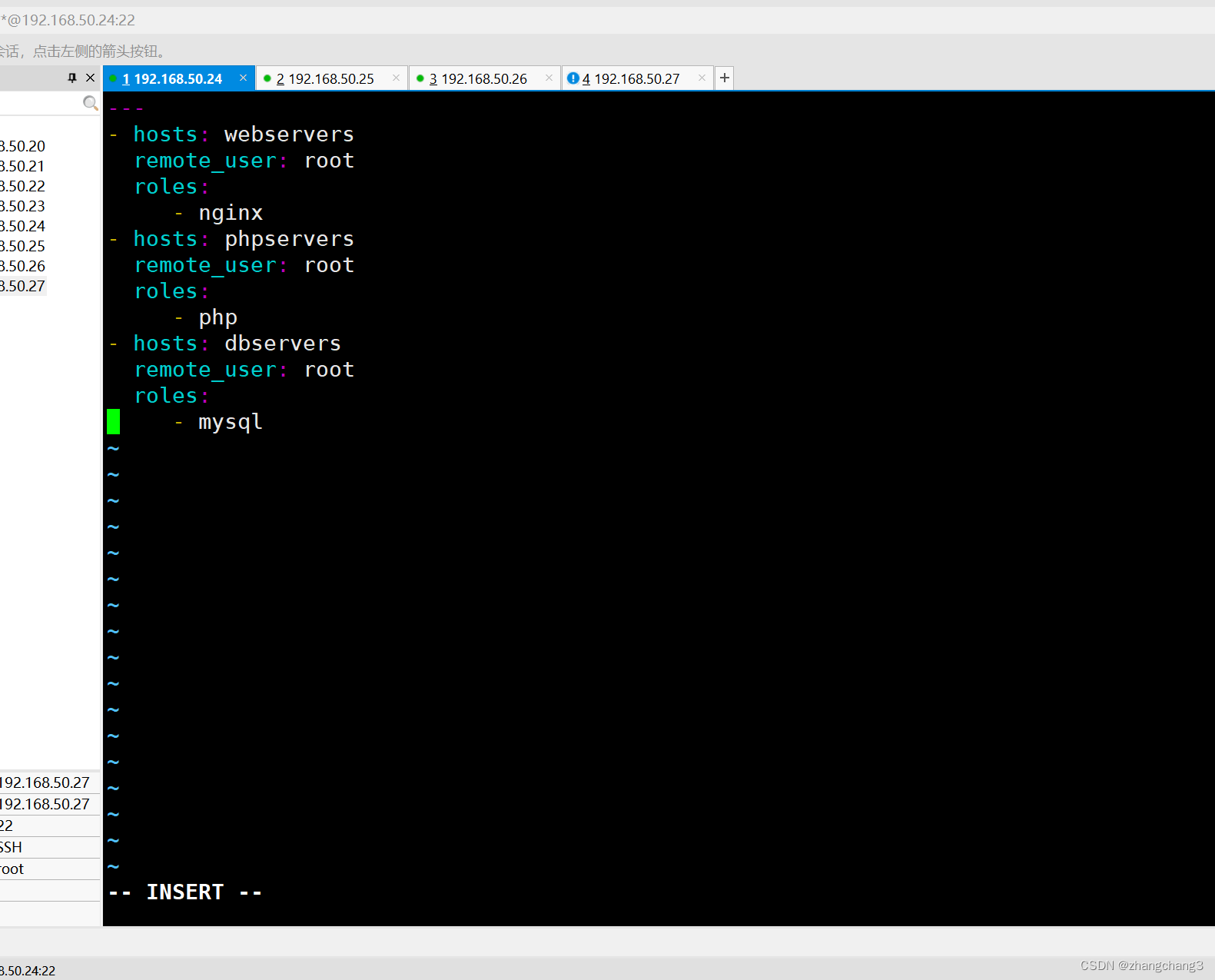
启动Kafka集群时,需要确保ZooKeeper集群是正常启动的。下面分别在虚拟机Spark01、Spark02和Spark03的Kafka安装目录下,执行启动Kafka命令。如下图所示:



好了,Kafka的集群部署我们就讲到这里了,这几篇主要针对大数据集群环境的搭建进行了讲解,包括创建虚拟机、Linux操作系统的安装与配置、安装JDK、ZooKeeper集群部署、Hadoop集群部署、Spark集群部署、HBase集群部署以及Kafka集群部署。通过这几篇的学习,希望读者熟悉大数据集群环境的搭建流程,并掌握ZooKeeper、Hadoop、Spark、HBase和Kafka集群的部署,为后续项目的开展奠定基础。
转载自:https://blog.csdn.net/u014727709/article/details/130918183
欢迎start,欢迎评论,欢迎指







![React学习[一]](https://img-blog.csdnimg.cn/fcc4c6119248446292444821628c1d96.png#pic_center)