作者:Felix Barnsteiner,Nicolas Ruflin

在 Elasticsearch 8.8 中,我们在技术预览中引入了重新路由处理器(reroute processor),它可以根据灵活的路由规则将文档(例如日志)发送到不同的数据流。 使用 Elastic 可观察性时,你可以更精细地控制数据的保留、权限和处理,并享受数据流命名方案的所有潜在优势。 在针对数据流进行优化的同时,重新路由处理器也适用于经典索引。 这篇博文包含有关如何使用重新路由处理器的示例,你可以通过在 Kibana 开发工具中执行代码片段来自行尝试。
Elastic Observability 提供广泛的集成,可帮助你监控应用程序和基础设施。 这些集成作为策略添加到 Elastic 代理,这有助于将遥测数据引入 Elastic 可观察性。 这些集成的几个示例包括从系统中提取日志的能力,这些系统发送来自不同应用程序的日志流,例如 Amazon Kinesis Data Firehose、Kubernetes 容器日志和系统日志。 一个挑战是这些多路复用日志流正在将数据发送到相同的 Elasticsearch 数据流,例如 logs-syslog-default。 这使得很难在摄取管道和仪表板中为特定技术创建解析规则,例如来自 Nginx 和 Apache 集成的技术。 这是因为在 Elasticsearch 中,结合数据流命名方案,处理和模式都被封装在一个数据流中。
重新路由处理器可帮助你从通用数据流中梳理出数据并将其发送到更具体的数据流。 例如,你可以使用该机制将日志发送到由 Nginx 集成设置的数据流,以便使用该集成解析日志,你可以使用集成的预建仪表板或使用字段创建自定义仪表板,例如 作为 url、状态代码和 Nginx 管道从 Nginx 日志消息中解析出来的响应时间。 你还可以使用重新路由处理器拆分/分离常规 Nginx 日志和错误,从而提供进一步的日志分离能力和分类。
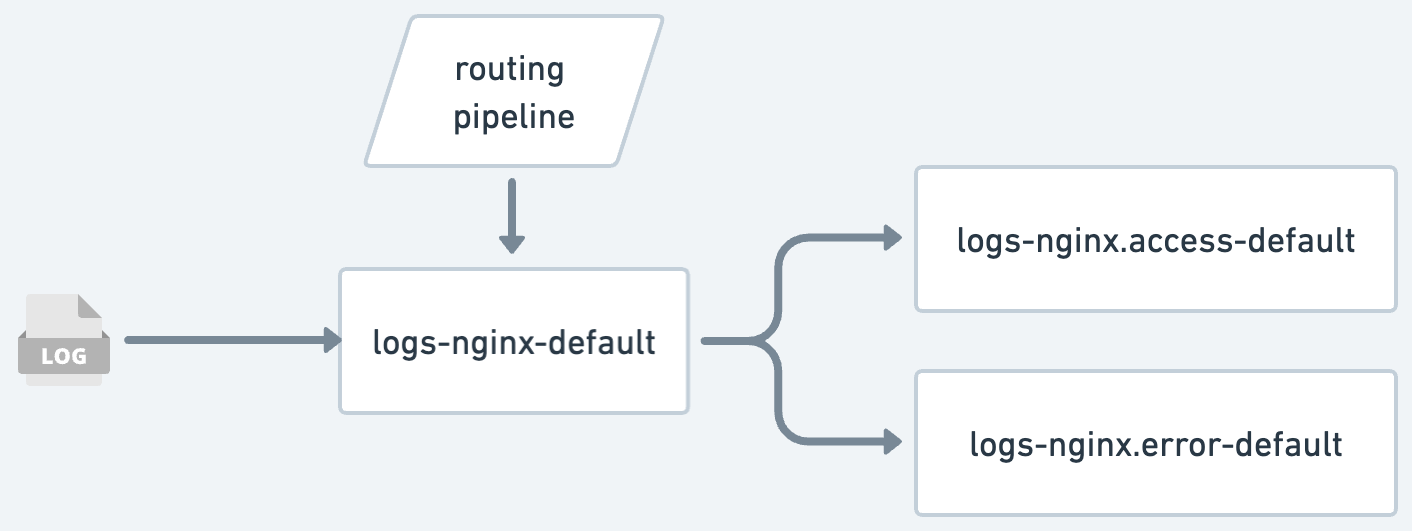
示例用例
要使用重新路由处理器,首先:
- 确保你使用的是 Elasticsearch 8.8
- 确保你有权管理索引和数据流
- 如果你在 Elastic Cloud 上还没有账户,请注册一个
接下来,你需要设置一个数据流并创建一个自定义的 Elasticsearch 摄取管道,该管道被称为默认管道。 下面我们将逐步介绍我们将模拟摄取容器日志的“mydata” 数据集。 我们从一个基本示例开始,然后从那里扩展它。
应在 Elastic 控制台中使用以下步骤,该控制台位于 Management -> Dev Tools -> Console。 首先,我们需要一个摄取管道和一个数据流模板:
PUT _ingest/pipeline/logs-mydata
{
"description": "Routing for mydata",
"processors": [
{
"reroute": {
}
}
]
}这将创建一个带有空重新路由处理器的摄取管道。 要使用它,我们需要一个索引模板:
PUT _index_template/logs-mydata
{
"index_patterns": [
"logs-mydata-*"
],
"data_stream": {},
"priority": 200,
"template": {
"settings": {
"index.default_pipeline": "logs-mydata"
},
"mappings": {
"properties": {
"container.name": {
"type": "keyword"
}
}
}
}
}上述模板适用于传送到 logs-mydata-* 的所有数据。 我们已将 container.name 映射为 keyword 字段,因为这是我们稍后将用于路由的字段。 现在,我们将文档发送到数据流,它将被摄取到 logs-mydata-default 中:
POST logs-mydata-default/_doc
{
"@timestamp": "2023-05-25T12:26:23+00:00",
"container": {
"name": "foo"
}
}我们可以使用下面的命令检查它是否被提取,这将显示 1 个结果。
GET logs-mydata-default/_search上面的命令显示的结果为:
{
"took": 0,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": ".ds-logs-mydata-default-2023.06.15-000001",
"_id": "o1k9vogBbFMkj6EdYagJ",
"_score": 1,
"_source": {
"container": {
"name": "foo"
},
"data_stream": {
"namespace": "default",
"type": "logs",
"dataset": "mydata"
},
"@timestamp": "2023-05-25T12:26:23+00:00"
}
}
]
}
}在不修改路由处理器的情况下,这已经允许我们路由文档。 一旦指定了重路由处理器,它将默认查找 data_stream.dataset 和 data_stream.namespace 字段,并根据数据流命名方案 logs-<dataset>-<namespace> 将文档发送到相应的数据流。 让我们试试这个:
POST logs-mydata-default/_doc
{
"@timestamp": "2023-03-30T12:27:23+00:00",
"container": {
"name": "foo"
},
"data_stream": {
"dataset": "myotherdata"
}
}上面命令返回的结果为:
{
"_index": ".ds-logs-myotherdata-default-2023.06.15-000001",
"_id": "pFlAvogBbFMkj6EdDqgy",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}从上面的返回结果中,_index 的值为 .ds-logs-myotherdata-default-2023.06.15-000001,也就是它被写入到 logs-myotherdata-default 数据流中了。
从 GET logs-mydata-default/_search 命令可以看出,该文档最终出现在 logs-myotherdata-default 数据流中。 但是我们不想使用默认规则,而是想为字段 container.name 创建我们自己的规则。 如果该字段是 container.name = foo,我们想将它发送到 logs-foo-default。 为此,我们修改路由管道:
PUT _ingest/pipeline/logs-mydata
{
"description": "Routing for mydata",
"processors": [
{
"reroute": {
"tag": "foo",
"if" : "ctx.container?.name == 'foo'",
"dataset": "foo"
}
}
]
}让我们用一个文档来测试一下:
POST logs-mydata-default/_doc
{
"@timestamp": "2023-05-25T12:26:23+00:00",
"container": {
"name": "foo"
}
}虽然可以为每个容器名称指定一个路由规则,但你也可以通过文档中字段的值进行路由:
PUT _ingest/pipeline/logs-mydata
{
"description": "Routing for mydata",
"processors": [
{
"reroute": {
"tag": "mydata",
"dataset": [
"{{container.name}}",
"mydata"
]
}
}
]
}在此示例中,我们使用字段引用作为路由规则。 如果文档中存在 container.name 字段,它将被路由 —— 否则它会回退到 mydata。 这可以通过以下方式进行测试:
POST logs-mydata-default/_doc
{
"@timestamp": "2023-05-25T12:26:23+00:00",
"container": {
"name": "foo1"
}
}
POST logs-mydata-default/_doc
{
"@timestamp": "2023-05-25T12:26:23+00:00",
"container": {
"name": "foo2"
}
}这将创建数据流 logs-foo1-default 和 logs-foo2-default。
注意:当前处理器中存在一个限制,要求在 {{field.reference}} 中指定的字段采用嵌套对象表示法。 带点的字段名称当前不起作用。 此外,当文档包含任何 data_stream.* 字段的带点字段名称时,你将收到错误消息。 此限制将在 8.8.2 和 8.9.0 中修复。
API密钥
使用重新路由处理器时,指定的 API 密钥必须具有对源索引和目标索引的权限,这一点很重要。 例如,如果模式用于从 logs-mydata-default 进行路由,则 API 密钥必须具有对 logs-*-* 的写入权限,因为数据可能最终出现在这些索引中的任何一个中(参见下面的示例)。
我们目前正在努力扩展我们集成的 API 密钥权限,以便在你运行 Fleet 管理的 Elastic Agent 时允许默认路由。
如果你使用独立的 Elastic Agent 或任何其他的摄入数据途径,你可以使用它作为模板来创建你的 API 密钥:
POST /_security/api_key
{
"name": "ingest_logs",
"role_descriptors": {
"ingest_logs": {
"cluster": [
"monitor"
],
"indices": [
{
"names": [
"logs-*-*"
],
"privileges": [
"auto_configure",
"create_doc"
]
}
]
}
}
}未来的计划
在 Elasticsearch 8.8 中,重新路由处理器以技术预览版的形式发布。 计划是在我们的数据接收器集成中采用它,例如 syslog、k8s 和其他。 Elastic 将提供开箱即用的默认路由规则,但用户也可以添加自己的规则。 如果你正在使用我们的集成,请按照本指南了解如何添加自定义摄取管道。
试试看!
这篇博文展示了一些基于文档的路由的示例用例。 通过调整索引模板的命令并为你自己的数据摄取管道,在你的数据上试用它,并通过 7 天的免费试用开始使用 Elastic Cloud。 通过此反馈表让我们知道你打算如何使用重新路由处理器以及你是否有改进建议。