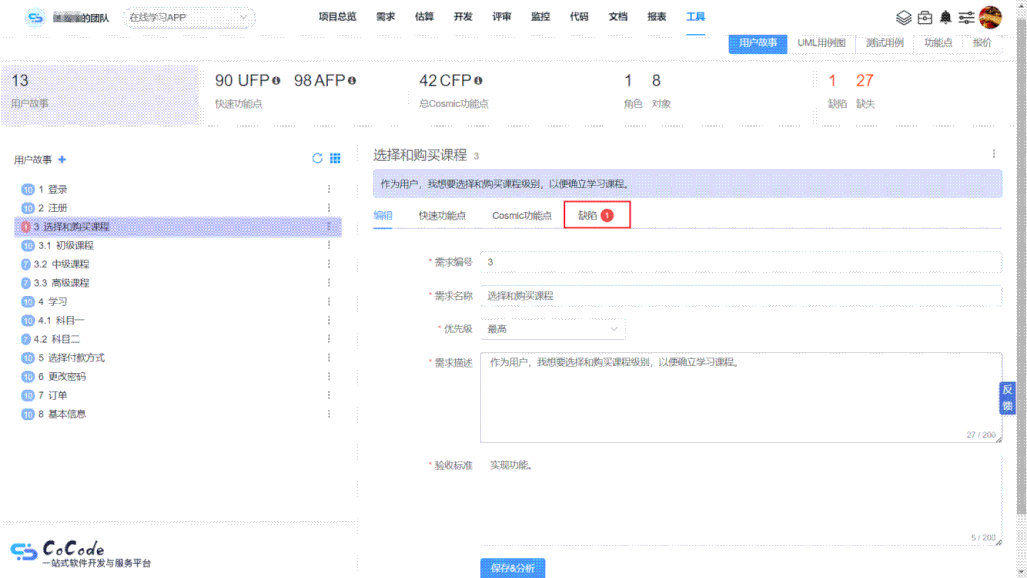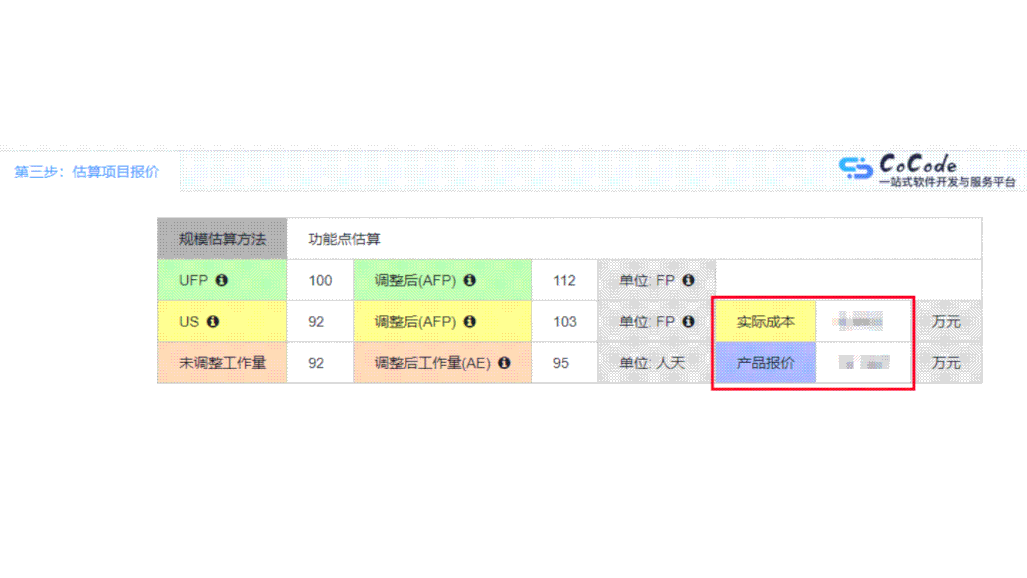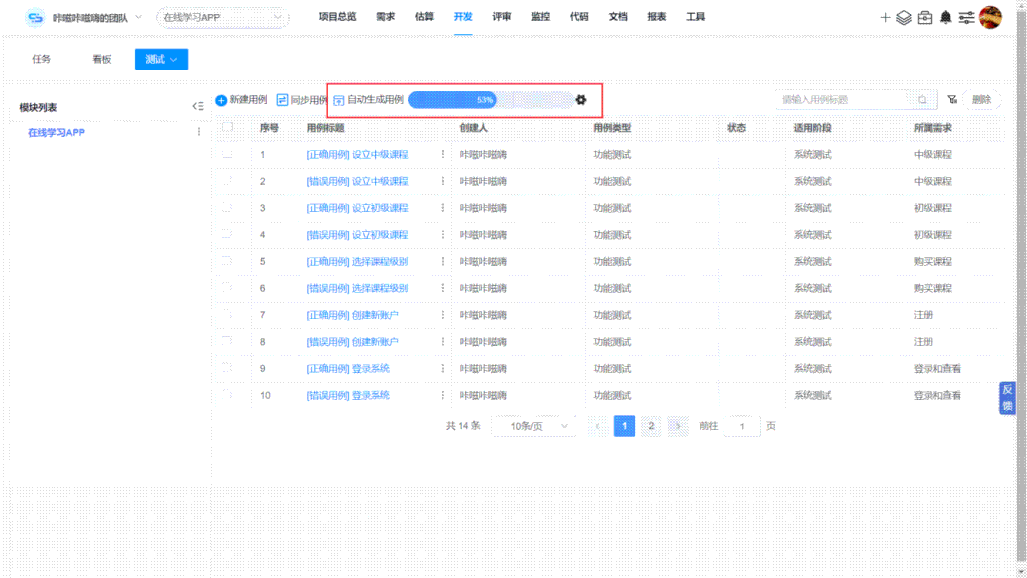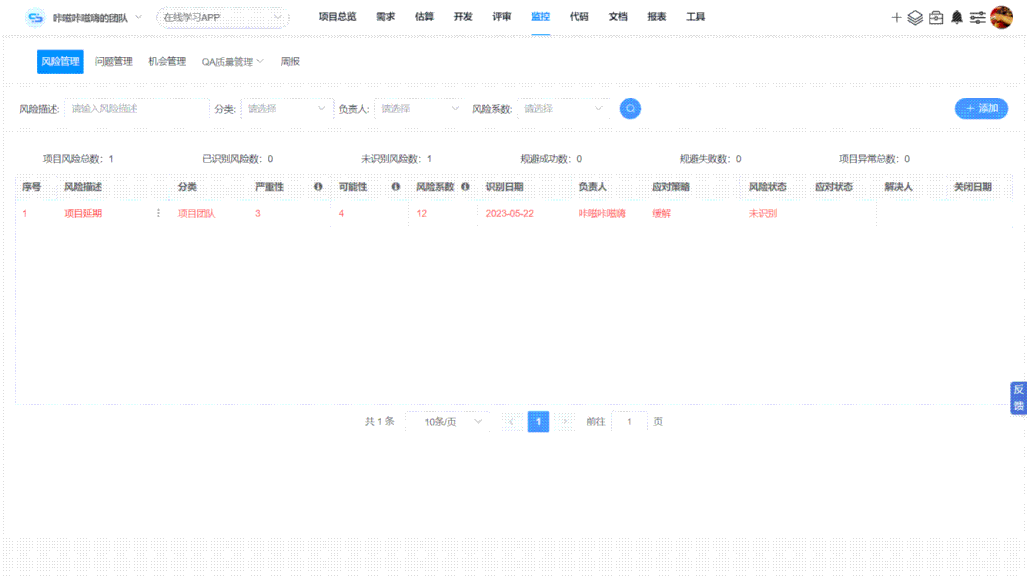
patroni+etcd+antdb高可用架构图
- Patroni组件功能
自动创建并管理主备流复制集群,并且通过api接口往dcs(Distributed Configuration Store,通常指etcd、zookeeper、consul等基于Raft协议的键值存储)读取以及更新键值来维护集群的状态。键值包括集群状态、master/slave的节点信息等。
- Etcd组件功能
Dcs的一种,存储键值信息,基于Raft协议同步信息。
- Raft协议介绍
Raft是一个共识算法(consensus algorithm)。所谓共识,就是多个节点对某个事情达成一致的看法,即使是在部分节点故障、网络延时、网络分割的情况下。这些年最为火热的加密货币(比特币、区块链)就需要共识算法,而在分布式系统中,共识算法用于提高系统的容错性,比如分布式存储中的复制集(replication)。
Patroni针对网络异常脑裂引起集群异常的优化
当antdb集群出现网络异常时(比如延迟、分割等),
此时etcd集群处于僵死等待恢复状态(Raft协议保证,必须大于1/2节点才能存活),
此时patroni不会改变其管理下的antdb集群状态,
每个antdb节点会维持当前集群的状态信息(而不是从dcs模块实时读取集群信息),
此时patroni将自己置为暂停状态,并允许antdb提供只读服务。
Patroni针对单节点异常引起集群异常的优化
当数据库hangup或者出现out-of-memory异常等原因,
导致antdb单节点的实例处于僵死状态时,
此时patroni支持watchdog 看门狗软件,
定时探测与数据库实例的心跳监测,
当在指定时间内未返回心跳信息后,
watchdog 看门狗重置该节点整个数据库实例的状态,
并从etcd同步集群的状态信息,
保证整个集群处于一致的运行状态。
Patroni流程说明
Patroni流程图
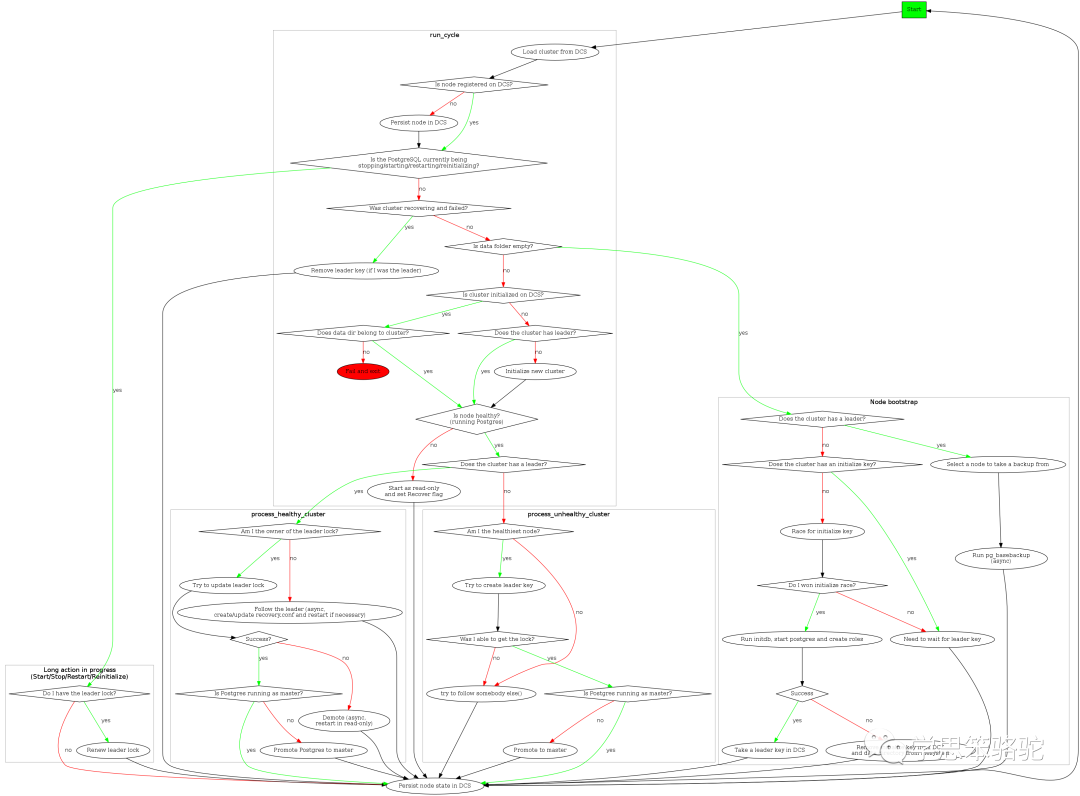
按照Patroni官方给的流程图,可以将整个流程划分为:
1.节点启动流程
2.节点拉起流程
3.处理健康集群流程
4.处理不健康集群流程
4.1节点启动
1.1:从DCS中加载集群信息
- 判断条件2.1:如果在DCS中已经注册了节点,那么执行判断条件2.2,如果没有注册,则执行步骤1.2
1.2:在DCS中持久化节点信息
- 判读条件2.2:判读当前节点Postgresql的状态,如果是开始中、停止中、重新启动中以及重新初始化中,那么进入判断条件2.3,否则就进入判断条件2.4
- 判断条件2.3:判断该节点是否拥有领导者锁,如果拥有领导者锁,则执行步骤1.3,否则执行步骤1.4
1.3:更新领导者锁
1.4:持久化节点状态到DCS中
- 判断条件2.4:集群是否还原状态,并且失败了,如果是执行步骤1.5,否则执行判断条件2.5
1.5: 如果当前节点是leader节点,则移除leader key。
- 判断条件2.5:判断数据目录是否为空,如果是执行步骤1.6,否则执行判断条件2.6
1.6:执行②节点拉起流程
- 判断条件2.6:集群信息在DCS中初始化,如果是则执行判断条件2.7,否则执行判断条件2.8
- 判断条件2.7:数据目录是否属于集群,如果是执行判断条件2.9,否则执行步骤1.7
- 判断条件2.8:集群是否有领导者,如果是执行判断条件2.9,否则执行步骤1.8
1.7:节点启动失败并退出
- 判断条件2.9:节点是否健康状态(Postgresql运行中),如果是执行判断条件2.10,否则执行步骤1.9
1.8:初始化一个新集群
1.9:设置成只读节点及还原标志
- 判断条件2.10:集群是否有一个领导者,如果是执行③处理健康集群流程,否则执行④处理不健康集群流程
4.2节点拉起
- 判断条件2.1:集群是否有一个领导者,如果是执行步骤1.1,否则执行判断条件2.2
1.1:选择一个节点,并且获得备份,执行步骤1.2
1.2:执行pg_basebackup还原备份
- 判断条件2.2:集群是否有一个初始键,如果是执行步骤1.3,否则执行步骤1.4
1.3:等待一个leader key
1.4:竞争初始键
- 判断条件2.3:判断是否赢得了竞争初始键,如果是执行步骤1.5,否则执行步骤1.6
1.5:初始化数据库、运行Postgresql并且创建对应角色,执行判断条件2.4
1.6:需要等待leader key
- 判断条件2.4:操作成功,执行步骤1.7,否则执行步骤1.8
1.7:将leader key存储到DCS中,执行步骤1.9
1.8:从DCS中移除初始化键,并且删除数据目录,执行步骤1.9
1.9:持久化节点状态到DCS中
4.3处理健康集群
- 判断条件2.1:判断当前节点是否拥有领导者锁,如果是执行步骤1.1,否则执行步骤1.2
步骤1.1:尝试更新领导者锁,执行判断条件2.2
步骤1.2:跟随领导者
- 判断条件2.2:如果执行成功,则执行判断条件2.3,否则执行步骤1.3
- 判断条件2.3:当前节点是否作为主节点在运行,如果是执行步骤1.5,否则步骤1.4
1.3:执行节点降级操作
1.4:提升当前节点为主节点
1.5:持久化节点状态到DCS中
4.4处理不健康集群
- 判断条件2.1:判断当前节点是否为健康状态,如果是执行步骤1.1,否则执行步骤1.2
1.1:创建leader key
1.2:尝试跟随其他节点
- 判断条件2.2:是否可以获得锁,如果可以执行判断条件2.3,否则执行步骤1.2
- 判断条件2.3:当前节点是否作为Postgresql主节点在运行,如果是执行步骤1.3,否则执行步骤1.4
1.3:持久化节点状态到DCS中
1.4:提升当前节点为主节点
Watchdog说明
watchdog 是一款内核自带的系统监控工具。普通情况下,它看似无关紧要,但却能在危机关头力挽狂澜。因为它能够在系统资源即将耗尽或即将崩溃时主动重启系统,避免由于硬件罢工而导致的被动重启或宕机造成的数据损失和业务损失。