出品人:Towhee 技术团队
作者:张晨
架构
Video-LLaMA 旨在使冻结的 LLM 能够理解视频中的视觉和听觉内容。如图所示,本文设计了两个分支,即视觉语言分支和音频语言分支,分别将视频帧和音频信号转换为与 LLM 的文本输入兼容的查询表示。
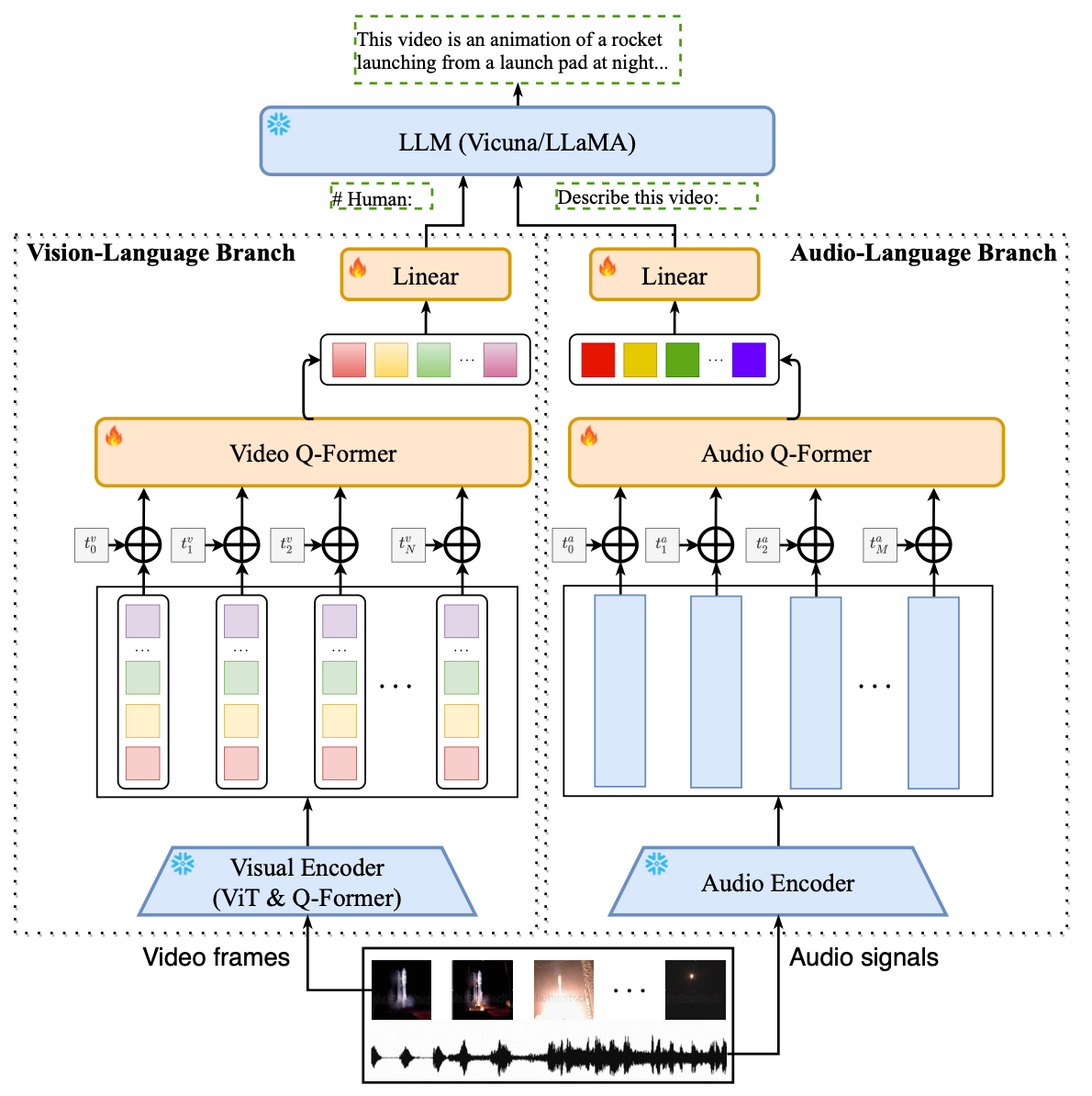
1.1 视觉-语言分支
视觉语言分支旨在使 LLM 能够理解视觉输入。如图左侧所示,它由用于从视频帧中提取特征的冻结预训练图像编码器、用于将时间信息注入视频帧的位置 embedding 层、用于聚合帧的视频 Q-former 组成级表示和线性层,用于将输出视频表示投影到与 LLM 的文本 embeddings 相同的维度。
1.2 音频分支
为了处理给定视频的听觉内容,本文引入了音频语言分支。具体来说,它包括一个预训练的音频编码器,(用的是用预训练的 Imagebind),它用于计算给定一小段原始音频的特征,一个位置 embedding 层,用于将时间信息注入音频片段,一个音频 Q-former,用于融合不同音频片段的特征,和一个线性层,用于将音频表示映射到 LLM 的 embedding 空间。
训练
本文分别训练视觉语言和音频语言分支。第一阶段使用大规模视觉-字幕数据集进行训练,第二阶段使用高质量的指令遵循数据集进行fine-tuning训练。
2.1 视觉-语言分支训练
对于预训练视觉语言分支,本文使用了 Webvid-2M,这是一个大型短视频数据集,带有来自素材网站的文本描述。此外,使用了图像标题数据集 CC595k,该数据集来自 CC3M 。在预训练阶段采用视频到文本生成任务,即给定视频表示,促使冻结的 LLM 生成相应的文本描述。本文发现很大一部分文字描述不足以反映视频的全部内容。因此,视频中的视觉语义与视频描述中的文本语义并不完全一致。然而,这一阶段旨在利用大量数据并使视频特征包含尽可能多的视觉知识。
经过预训练阶段后,模型可以生成视频中的信息内容,但其遵循指令的能力有所下降。因此,在第二阶段,本文 fine-tune 使用高质量的指令数据来构建模型,整合了来自 MiniGPT-4的图像细节描述数据集、来自 LLaVA 的图像指令数据集和来自 Video-Chat 的视频指令数据集。在 fine-tuning 之后,Video-LLaMA 在遵循指令和理解图像和视频方面表现出非凡的能力。
2.2 音频分支训练
由于此类数据的稀有性,直接使用音频文本数据训练音频语言分支非常具有挑战性。音频语言分支中可学习参数的目标是将冻结音频编码器的输出 embedding 与 LLM 的 embedding 空间对齐。鉴于音频文本数据的稀缺性,本文采用变通策略来实现这一目标。用作音频编码器的 ImageBind 具有将不同模态的 embeddings 对齐到一个公共空间的非凡能力,在跨模态检索和生成任务上展示了令人印象深刻的性能。由于音频文本数据的稀缺性和视觉文本数据的丰富性,本文使用视觉文本数据训练音频语言分支,遵循与视觉分支相同的数据和过程。由于 ImageBind 提供的共享 embedding 空间,Video-LLaMA 展示了在推理过程中理解音频的能力,即使音频接口从未在音频数据上进行过训练。
限制
尽管 Video-LLaMA 在理解视频中的视觉和听觉内容方面表现出了令人印象深刻的能力,但它仍处于早期原型阶段并且存在一些局限性,包括:(1) 有限的感知能力:Video-LLaMA 的性能受到质量和当前训练数据集的规模。本文正在积极构建高质量的音频-视频-文本对齐数据集,以增强模型的感知能力(2) handle 长视频的能力有限。长视频(如电影和电视节目)包含大量信息,对计算资源提出更高要求。这一挑战仍然是研究界正在积极努力解决的一个关键问题(3)幻觉。 Video-LLaMA 继承了冻结 LLM 的幻觉问题。未来更强大的 LLM 的进步有望缓解这个问题。
参考链接:
代码地址:https://github.com/DAMO-NLP-SG/Video-LLaMA 论文地址:https://arxiv.org/abs/2306.02858 在线测试:https://huggingface.co/spaces/DAMO-NLP-SG/Video-LLaMA
🌟全托管 Milvus SaaS/PaaS 即将上线,由 Zilliz 原厂打造!覆盖阿里云、百度智能云、腾讯云、金山云。目前已支持申请试用,企业用户 PoC 申请或其他商务合作请联系 business@zilliz.com。
-
如果在使用 Milvus 或 Zilliz 产品有任何问题,可添加小助手微信 “zilliz-tech” 加入交流群。 -
欢迎关注微信公众号“Zilliz”,了解最新资讯。 
本文由 mdnice 多平台发布