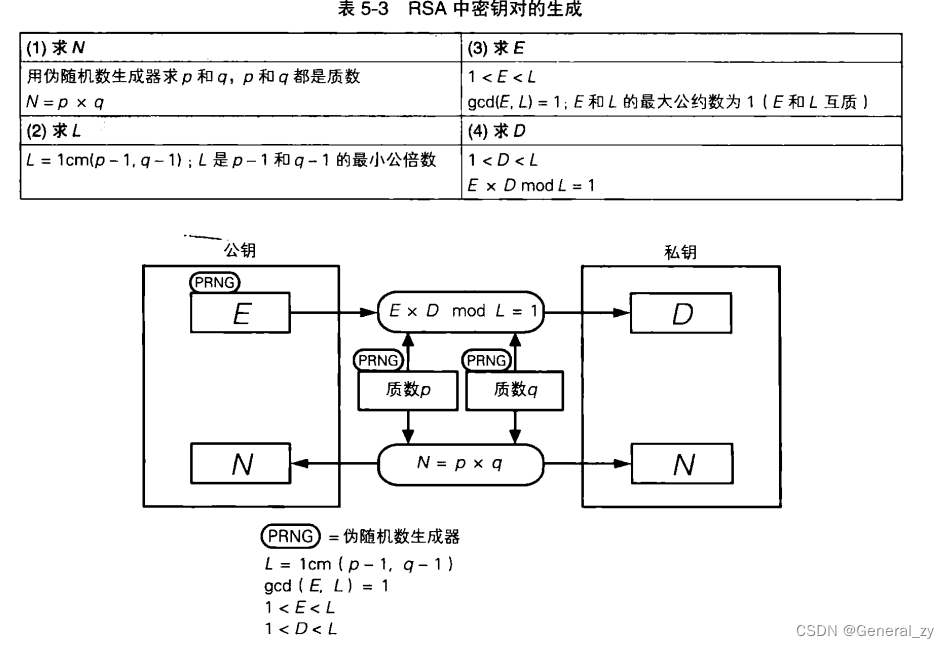
1 特征值分解(EVD)
设 A n × n A_{n \times n} An×n有 n n n个线性无关的特征向量 x 1 , … , x n \boldsymbol{x}_{1}, \ldots, \boldsymbol{x}_{n} x1,…,xn,对应特征值分别为 λ 1 , … , λ n \lambda_{1}, \ldots, \lambda_{n} λ1,…,λn
A [ x 1 ⋯ x n ] = [ λ 1 x 1 ⋯ λ n x n ] A\left[\begin{array}{lll}\boldsymbol{x}_{1} & \cdots & \boldsymbol{x}_{n}\end{array}\right]=\left[\begin{array}{lll}\lambda_{1} \boldsymbol{x}_{1} & \cdots & \lambda_{n} \boldsymbol{x}_{n}\end{array}\right] A[x1⋯xn]=[λ1x1⋯λnxn]
所以:
A
=
[
x
1
⋯
x
n
]
[
λ
1
⋱
λ
n
]
[
x
1
⋯
x
n
]
−
1
A = \left[\begin{array}{lll}\boldsymbol{x}_{1} & \cdots & \boldsymbol{x}_{n}\end{array}\right]\left[\begin{array}{lll}\lambda_{1} & & \\& \ddots & \\& & \lambda_{n}\end{array}\right]\left[\begin{array}{lll}\boldsymbol{x}_{1} & \cdots & \boldsymbol{x}_{n}\end{array}\right]^{-1}
A=[x1⋯xn]⎣⎡λ1⋱λn⎦⎤[x1⋯xn]−1
因此有EVD分解
A
X
=
X
Λ
A
=
X
Λ
X
−
1
A X=X \Lambda \quad \quad \quad A=X \Lambda X^{-1}
AX=XΛA=XΛX−1
其中
X
X
X为
x
1
,
…
,
x
n
(
列
向
量
)
\boldsymbol{x}_{1}, \ldots, \boldsymbol{x}_{n}\left(\right. 列向量)
x1,…,xn(列向量)构成的矩阵,
Λ
=
diag
(
λ
1
,
…
,
λ
n
)
\Lambda=\operatorname{diag}\left(\lambda_{1}, \ldots, \lambda_{n}\right)
Λ=diag(λ1,…,λn)。即使固定
Λ
\Lambda
Λ,
X
X
X也不唯一。
更为特殊的是,当矩阵
A
A
A是一个对称矩阵时,则存在一个对称对角化分解,即
A
=
X
Λ
X
T
A=X \Lambda X^{T}
A=XΛXT
其中,
X
X
X的每一列都是相互正交的特征向量,且是单位向量,
Λ
\Lambda
Λ对角线上的元素是从大到小排列的特征值。
注意到要进行特征分解,矩阵 A A A必须为方阵。那么如果 A A A不是方阵,即行和列不相同时,我们还可以对矩阵进行分解吗?答案是可以,此时我们的SVD登场了。
2 奇异值分解(SVD)
2.1 引言
特征值分解是一个提取矩阵特征很不错的方法,但是它只是对方阵而言的,在现实的世界中,我们看到的大部分矩阵都不是方阵,比如说有
m
m
m个学生,每个学生有
n
n
n科成绩,这样形成的一个
m
×
n
m\times n
m×n的矩阵就不可能是方阵,我们怎样才能描述这样普通的矩阵呢的重要特征呢?奇异值分解可以用来干这个事情,奇异值分解是一个能适用于任意的矩阵的一种分解的方法:
A
=
U
Σ
V
T
A = U\Sigma V^T
A=UΣVT
假设 A A A是一个 m × n m\times n m×n的矩阵,那么得到的 U U U是一个 m × m m\times m m×m的方阵(里面的向量是正交的, U U U里面的向量称为左奇异向量), Σ \Sigma Σ是一个 m × n m\times n m×n的矩阵(除了对角线的元素都是0,对角线上的元素称为奇异值), V T V^T VT(V的转置)是一个 n × m n\times m n×m的矩阵,里面的向量也是正交的, V V V里面的向量称为右奇异向量),从图片来反映几个相乘的矩阵的大小可得下面的图片

那么奇异值和特征值是怎么对应起来的呢?首先,我们将将A的转置和A做矩阵乘法,将会得到一个方阵,我们用这个方阵求特征值可以得到:
(
A
T
A
)
v
i
=
λ
i
v
i
(A^TA)v_i = \lambda_i v_i
(ATA)vi=λivi
这样我们就可以得到矩阵 A T A A^TA ATA的 n n n个特征值和对应的 n n n个特征向量 v v v了。将 A T A A^TA ATA的所有特征向量张成一个 n × n n\times n n×n的矩阵 V V V,就是我们SVD公式里面的 V V V矩阵了。
如果我们将
A
A
A和
A
A
A的转置做矩阵乘法,那么会得到
m
×
m
m\times m
m×m的一个方阵
A
A
T
AA^T
AAT。既然
A
A
T
AA^T
AAT是方阵,那么我们就可以进行特征分解,得到的特征值和特征向量满足下式:
(
A
A
T
)
u
i
=
λ
i
u
i
(AA^T)u_i = \lambda_i u_i
(AAT)ui=λiui
这样我们就可以得到矩阵 A A T AA^T AAT的 m m m个特征值和对应的 m m m个特征向量 u u u了。将 A A T AA^T AAT的所有特征向量张成一个 m × m m\times m m×m的矩阵 U U U,就是我们SVD公式里面的 U U U矩阵了。
U U U和 V V V我们都求出来了,现在就剩下奇异值矩阵 Σ \Sigma Σ没有求出了。由于 Σ \Sigma Σ除了对角线上是奇异值其他位置都是0,那我们只需要求出每个奇异值 σ \sigma σ就可以了。
我们注意到:
A
=
U
Σ
V
T
⇒
A
V
=
U
Σ
V
T
V
⇒
A
V
=
U
Σ
⇒
A
v
i
=
σ
i
u
i
⇒
σ
i
=
A
v
i
/
u
i
A=U\Sigma V^T \Rightarrow AV=U\Sigma V^TV \Rightarrow AV=U\Sigma \Rightarrow Av_i = \sigma_i u_i \Rightarrow \sigma_i = Av_i / u_i
A=UΣVT⇒AV=UΣVTV⇒AV=UΣ⇒Avi=σiui⇒σi=Avi/ui
进一步我们还可以看出我们的特征值矩阵等于奇异值矩阵的平方,也就是说特征值和奇异值满足如下关系:
σ
i
=
λ
i
\sigma_i = \sqrt{\lambda_i}
σi=λi
这里的
σ
\sigma
σ就是上面说的奇异值,u就是上面说的左奇异向量。奇异值
σ
\sigma
σ跟特征值类似,在矩阵
Σ
\Sigma
Σ中也是从大到小排列,而且
σ
\sigma
σ的减少特别的快,在很多情况下,前10%甚至1%的奇异值的和就占了全部的奇异值之和的99%以上了。也就是说,我们也可以用前
r
r
r大的奇异值来近似描述矩阵,这里定义一下部分奇异值分解:
A
m
×
n
≈
U
m
×
r
Σ
r
×
r
V
r
×
n
T
A_{m\times n} \approx U_{m\times r}\Sigma_{r\times r}V_{r\times n}^T
Am×n≈Um×rΣr×rVr×nT
r r r是一个远小于 m 、 n m、n m、n的数,这样矩阵的乘法看起来像是下面的样子:

右边的三个矩阵相乘的结果将会是一个接近于 A A A的矩阵,在这儿, r r r越接近于 n n n,则相乘的结果越接近于 A A A。而这三个矩阵的面积之和(在存储观点来说,矩阵面积越小,存储量就越小)要远远小于原始的矩阵 A A A,我们如果想要压缩空间来表示原矩阵 A A A,我们存下这里的三个矩阵: U 、 Σ 、 V U、\Sigma、V U、Σ、V就好了。
2.2 定义
将一个非零的 m × n m\times n m×n实矩阵 A , A ∈ R m × n A,A\in R^{m\times n} A,A∈Rm×n,表示为如下三个实矩阵的乘积形式的运算,即进行矩阵的因子分解:
A = U Σ V T A=U\Sigma V^T A=UΣVT
其中, U U U是 m m m阶正交矩阵, V V V是 n n n阶正交矩阵, Σ \Sigma Σ是由降序排列的非负对角元素组成的 m × n m\times n m×n矩形对角矩阵,用符号描述如下:
U U T = I , V V T = I Σ = d i a g ( σ 1 , σ 2 , . . . , σ p ) , σ 1 ≥ σ 2 ≥ ⋯ ≥ σ p ≥ 0 , p = m i n ( m , n ) UU^T=I,VV^T=I\\ \Sigma=diag(\sigma_1,\sigma_2,...,\sigma_p),\sigma_1\geq\sigma_2\geq\cdots\geq\sigma_p\geq 0,p=min(m,n) UUT=I,VVT=IΣ=diag(σ1,σ2,...,σp),σ1≥σ2≥⋯≥σp≥0,p=min(m,n)
2.3 构造性的证明
1. 求
Σ
,
V
\Sigma,V
Σ,V
由于
A
A
A是
m
×
n
m\times n
m×n阶的矩阵,所以
A
T
A
A^TA
ATA是一个
n
×
n
n\times n
n×n实对称矩阵,故可以对其做正交分解使得:
V T ( A T A ) V = Λ V^T(A^TA)V=\Lambda VT(ATA)V=Λ
其中, V V V为n阶正交实矩阵, Λ \Lambda Λ为 n n n阶对角阵,其对角线元素由 A T A A^TA ATA的特征值构成,且这些特征值非负,下面简单说明,假设 λ \lambda λ是 A T A A^TA ATA的一个特征值, x x x是对应的特征向量,那么
∣ ∣ A x ∣ ∣ 2 = x T A T A x = λ x T x = λ ∣ ∣ x ∣ ∣ 2 ||Ax||^2=x^TA^TAx=\lambda x^Tx=\lambda ||x||^2 ∣∣Ax∣∣2=xTATAx=λxTx=λ∣∣x∣∣2
所以:
λ = ∣ ∣ A x ∣ ∣ 2 ∣ ∣ x ∣ ∣ 2 > 0 \lambda=\frac{||Ax||^2}{||x||^2}>0 λ=∣∣x∣∣2∣∣Ax∣∣2>0
我们可以通过调整正交矩阵 V V V的排列损失使得对应的特征值形成降序排列:
λ 1 ≥ λ 2 ≥ ⋯ ≥ λ p ≥ 0 \lambda_1\geq\lambda_2\geq \cdots \geq\lambda_p\geq 0 λ1≥λ2≥⋯≥λp≥0
接着计算奇异值:
σ j = λ j , j = 1 , 2 , . . . , p \sigma_j=\sqrt{\lambda_j},j=1,2,...,p σj=λj,j=1,2,...,p
假设 A A A的秩为 r r r,则 A T A A^TA ATA的秩也为r,所以有:
λ 1 ≥ λ 2 ≥ ⋯ ≥ λ r > 0 , λ r + 1 = λ r + 2 = ⋯ = λ p = 0 \lambda_1\geq\lambda_2\geq \cdots \geq\lambda_r> 0,\lambda_{r+1}=\lambda_{r+2}=\cdots=\lambda_p=0 λ1≥λ2≥⋯≥λr>0,λr+1=λr+2=⋯=λp=0
相应的,我们令:
V 1 = [ v 1 , . . . , v r ] , V 2 = [ v r + 1 , . . . , v p ] V_1=[v_1,...,v_r],V_2=[v_{r+1},...,v_p] V1=[v1,...,vr],V2=[vr+1,...,vp]
则:
V = [ V 1 V 2 ] V=[V_1\ V_2] V=[V1 V2]
同样地,我们令:
Σ 1 = d i a g ( σ 1 , . . . , σ r ) \Sigma_1=diag(\sigma_1,...,\sigma_r) Σ1=diag(σ1,...,σr)
对其余部分填充0,使得:
Σ = [ Σ 1 0 0 0 ] \Sigma=\begin{bmatrix} \Sigma_1 & 0\\ 0 & 0 \end{bmatrix} Σ=[Σ1000]
2. 求 U U U
接下来构造 m m m阶正交实对称矩阵 U U U,我们令:
u j = 1 σ j A v j , j = 1 , 2 , . . . , r u_j=\frac{1}{\sigma_j}Av_j,j=1,2,...,r uj=σj1Avj,j=1,2,...,r
令:
U 1 = [ u 1 , . . . , u r ] U_1=[u_1,...,u_r] U1=[u1,...,ur]
那么,如下关系就可以成立了:
A V 1 = U 1 Σ 1 AV_1=U_1\Sigma_1 AV1=U1Σ1
接下来,再为 U 1 U_1 U1扩充 m − r m-r m−r个标准正交向量,令 [ u r + 1 , . . . , u m ] [u_{r+1},...,u_m] [ur+1,...,um]为 N ( A T ) N(A^T) N(AT)的一组正交基,并令:
U 2 = [ u r + 1 , . . . , u m ] U = [ U 1 U 2 ] U_2=[u_{r+1},...,u_m]\\ U=[U_1\ U_2] U2=[ur+1,...,um]U=[U1 U2]
所以:
U Σ V T = [ U 1 U 2 ] [ Σ 1 0 0 0 ] [ V 1 T V 2 T ] = U 1 Σ 1 V 1 T = A V 1 V 1 T = A U\Sigma V^T=\begin{bmatrix} U_1 & U_2 \end{bmatrix} \begin{bmatrix} \Sigma_1 & 0\\ 0 & 0 \end{bmatrix} \begin{bmatrix} V_1^T\\ V_2^T \end{bmatrix}=U_1\Sigma_1V_1^T=AV_1V_1^T=A UΣVT=[U1U2][Σ1000][V1TV2T]=U1Σ1V1T=AV1V1T=A
2.4 奇异值分解(SVD)的求法
第一步:求出 A m × n T A m × n \pmb{A}^T_{m \times n}\pmb{A}_{m \times n} AAAm×nTAAAm×n的 n n n个特征值 λ 1 , λ 2 , ⋯ , λ r , λ r + 1 = 0 , ⋯ , λ n = 0 \lambda_1,\lambda_2, \cdots,\lambda_r , \lambda_{r+1}=0, \cdots, \lambda_{n} = 0 λ1,λ2,⋯,λr,λr+1=0,⋯,λn=0(并按照从大到小排列)和对应的标准正交的特征向量 v 1 , v 2 , ⋯ , v r , v r + 1 , ⋯ , v n \pmb{v}_1, \pmb{v}_2, \cdots,\pmb{v}_r,\pmb{v}_{r+1}, \cdots, \pmb{v}_{n} vvv1,vvv2,⋯,vvvr,vvvr+1,⋯,vvvn。
第二步:取标准正交的特征向量构成正交矩阵
V
n
×
n
=
(
v
1
,
v
2
,
⋯
,
v
r
,
v
r
+
1
,
⋯
,
v
n
)
n
×
n
\pmb{V}_{n \times n}=(\pmb{v}_1, \pmb{v}_2, \cdots,\pmb{v}_r,\pmb{v}_{r+1}, \cdots, \pmb{v}_{n})_{n \times n}
VVVn×n=(vvv1,vvv2,⋯,vvvr,vvvr+1,⋯,vvvn)n×n
取正奇异值,即前
r
r
r个奇异值,即非零特征值开根号
λ
1
,
λ
2
,
⋯
,
λ
r
\sqrt{\lambda_1}, \sqrt{\lambda_2}, \cdots,\sqrt{\lambda_r}
λ1,λ2,⋯,λr,构成对角矩阵
D
r
×
r
=
(
λ
1
λ
2
⋱
λ
r
)
r
×
r
\pmb{D}_{r \times r} = \begin{pmatrix} \sqrt{\lambda_1} \\ & \sqrt{\lambda_2} \\ & & \ddots \\ & & & \sqrt{\lambda_r} \end{pmatrix}_{r \times r}
DDDr×r=⎝⎜⎜⎛λ1λ2⋱λr⎠⎟⎟⎞r×r
添加额外的0组成
m
×
n
m\times n
m×n的矩阵
Σ
m
×
n
=
(
D
r
×
r
0
0
0
)
m
×
n
=
(
λ
1
λ
2
0
⋱
λ
r
0
0
)
m
×
n
\pmb{\Sigma}_{m \times n} = \begin{pmatrix} \pmb{D}_{r \times r} & \pmb{0} \\ \pmb{0} & \pmb{0} \end{pmatrix}_{m \times n} = \begin{pmatrix} \sqrt{\lambda_1} \\ & \sqrt{\lambda_2} & & & {\pmb{0}} \\ & & \ddots \\ & & & \sqrt{\lambda_r} \\ & {\pmb{0}} & & &{\pmb{0}} \end{pmatrix}_{m \times n}
ΣΣΣm×n=(DDDr×r000000000)m×n=⎝⎜⎜⎜⎜⎛λ1λ2000⋱λr000000⎠⎟⎟⎟⎟⎞m×n
第三步:构成前 r r r个标准正交向量 u 1 , u 2 , ⋯ , u r \pmb{u}_1, \pmb{u}_2, \cdots,\pmb{u}_r uuu1,uuu2,⋯,uuur,其中 u i = 1 λ i A v i , i = 1 , 2 , ⋯ , r \pmb{u}_{i} = \frac{1}{\sqrt{\lambda_i}}\pmb{A}\pmb{v}_i\quad, i = 1, 2, \cdots,r uuui=λi1AAAvvvi,i=1,2,⋯,r
第四步:将
u
1
,
u
2
,
⋯
,
u
r
\pmb{u}_1, \pmb{u}_2, \cdots,\pmb{u}_r
uuu1,uuu2,⋯,uuur扩充为
m
m
m维向量空间
R
m
\mathbb{R}^m
Rm的标准正交基
u
1
,
u
2
,
⋯
,
u
r
,
b
1
,
⋯
,
b
m
−
r
\pmb{u}_1, \pmb{u}_2, \cdots,\pmb{u}_r, \pmb{b}_{1}, \cdots,\pmb{b}_{m-r}
uuu1,uuu2,⋯,uuur,bbb1,⋯,bbbm−r,组成正交矩阵
U
m
×
m
=
(
u
1
,
u
2
,
⋯
,
u
r
,
b
1
,
⋯
,
b
m
−
r
)
m
×
m
\pmb{U}_{m \times m} = (\pmb{u}_1, \pmb{u}_2, \cdots,\pmb{u}_r, \pmb{b}_{1}, \cdots,\pmb{b}_{m-r})_{ m \times m}
UUUm×m=(uuu1,uuu2,⋯,uuur,bbb1,⋯,bbbm−r)m×m
第五步:写出即可:
A
m
×
n
=
U
m
×
m
Σ
m
×
n
V
n
×
n
T
=
U
m
×
m
(
λ
1
λ
2
0
⋱
λ
r
0
0
)
m
×
n
V
n
×
n
T
\pmb{A}_{m \times n} =\pmb{U}_{m \times m} \pmb{\Sigma}_{ m \times n} \pmb{V}^T_{n \times n} = \pmb{U}_{m \times m} \begin{pmatrix} \sqrt{\lambda_1} \\ & \sqrt{\lambda_2} & & & {\pmb{0}} \\ & & \ddots \\ & & & \sqrt{\lambda_r} \\ & {\pmb{0}} & & &{\pmb{0}} \end{pmatrix}_{m \times n} \pmb{V}^T_{n \times n}
AAAm×n=UUUm×mΣΣΣm×nVVVn×nT=UUUm×m⎝⎜⎜⎜⎜⎛λ1λ2000⋱λr000000⎠⎟⎟⎟⎟⎞m×nVVVn×nT
2.5 紧奇异值分解
上面第二节的分解方式称为完全奇异分解,大家可以发现,如果 r < p r<p r<p,我们完全没有必要对 U 1 U_1 U1以及 V 1 V_1 V1进行扩充,因为通过 U 1 , Σ 1 , V 1 U_1,\Sigma_1,V_1 U1,Σ1,V1就可以无损还原 A A A,即:
A = U 1 Σ 1 V 1 T A=U_1\Sigma_1V_1^T A=U1Σ1V1T
这便是紧奇异分解。
2.6 截断奇异值分解
另外,我们也可以只取最大的 k k k个奇异值( k < r k<r k<r)对应的部分去近似 A A A,这便是截断奇异值分解,即:
A ≈ U k Σ k V k T A \approx U_k\Sigma_kV_k^T A≈UkΣkVkT
这里, U k U_k Uk是一个 m × k m\times k m×k的矩阵,由 U U U的前 k k k列得到, V k V_k Vk是 n × k n\times k n×k矩阵,由 V V V的前 k k k列得到, Σ k \Sigma_k Σk是 k k k阶对角矩阵,由 Σ \Sigma Σ的前 k k k行 k k k列得到。
矩阵
A
=
[
a
i
j
]
m
×
n
A = [ a _ { i j } ] _ { m \times n }
A=[aij]m×n的弗罗贝尼乌斯范数定义为
∥
A
∥
F
=
(
∑
i
=
1
m
∑
j
=
1
n
(
a
i
j
)
2
)
1
2
\| A \| _ { F } = ( \sum _ { i = 1 } ^ { m } \sum _ { j = 1 } ^ { n } ( a _ { i j } ) ^ { 2 } ) ^ { \frac { 1 } { 2 } }
∥A∥F=(i=1∑mj=1∑n(aij)2)21
在秩不超过 k k k的 m × n m \times n m×n矩阵的集合中,存在矩阵 A A A的弗罗贝尼乌斯范数意义下的最优近似矩阵 X X X。秩为 k k k的截断奇异值分解得到的矩阵 A k A_k Ak能够达到这个最优值。奇异值分解是弗罗贝尼乌斯范数意义下,也就是平方损失意义下的矩阵最优近似。详细了解,请阅读:奇异值分解的低秩逼近
2.7 案例分析
SVD的Python实现:
# 实现奇异值分解, 输入一个numpy矩阵,输出 U, sigma, V
# https://zhuanlan.zhihu.com/p/54693391
import numpy as np
#基于矩阵分解的结果,复原矩阵
def rebuildMatrix(U, sigma, V):
a = np.dot(U, sigma)
a = np.dot(a, np.transpose(V))
return a
#基于特征值的大小,对特征值以及特征向量进行排序。倒序排列
def sortByEigenValue(Eigenvalues, EigenVectors):
index = np.argsort(-1 * Eigenvalues)
Eigenvalues = Eigenvalues[index]
EigenVectors = EigenVectors[:, index]
return Eigenvalues, EigenVectors
#对一个矩阵进行奇异值分解
def SVD(matrixA, NumOfLeft=None):
#NumOfLeft是要保留的奇异值的个数,也就是中间那个方阵的宽度
#首先求transpose(A)*A
matrixAT_matrixA = np.dot(np.transpose(matrixA), matrixA)
#然后求右奇异向量
lambda_V, X_V = np.linalg.eig(matrixAT_matrixA)
lambda_V, X_V = sortByEigenValue(lambda_V, X_V)
#求奇异值
sigmas = lambda_V
sigmas = list(map(lambda x: np.sqrt(x)
if x > 0 else 0, sigmas)) #python里很小的数有时候是负数
sigmas = np.array(sigmas)
sigmasMatrix = np.diag(sigmas)
if NumOfLeft == None:
rankOfSigmasMatrix = len(list(filter(lambda x: x > 0,
sigmas))) #大于0的特征值的个数
else:
rankOfSigmasMatrix = NumOfLeft
sigmasMatrix = sigmasMatrix[0:rankOfSigmasMatrix, :] #特征值为0的奇异值就不要了
#计算右奇异向量
X_U = np.zeros(
(matrixA.shape[0], rankOfSigmasMatrix)) #初始化一个右奇异向量矩阵,这里直接进行裁剪
for i in range(rankOfSigmasMatrix):
X_U[:, i] = np.transpose(np.dot(matrixA, X_V[:, i]) / sigmas[i])
#对右奇异向量和奇异值矩阵进行裁剪
X_V = X_V[:, 0:NumOfLeft]
sigmasMatrix = sigmasMatrix[0:rankOfSigmasMatrix, 0:rankOfSigmasMatrix]
#print(rebuildMatrix(X_U, sigmasMatrix, X_V))
return X_U, sigmasMatrix, X_V
下面是SVD进图像进行压缩的实践:
import numpy as np
import matplotlib.pyplot as plt
plt.figure(figsize=(18, 4))
im = plt.imread("./demo.jpg")
ks = [800, 500, 200, 100, 50, 10, 5] # 分别截取不同的 k
for idx, k in enumerate(ks):
svd_image = []
for ch in range(3): # 注意,有RGB三个维度,每个维度对应一个矩阵做SVD分解
im_ch = im[:, :, ch]
U, D, VT = np.linalg.svd(im_ch)
imx = np.matmul(np.matmul(U[:, :k], np.diag(D[:k])), VT[:k, :])
# 将像素值约束到合理范围
imx = np.where(imx<0, 0, imx)
imx = np.where(imx>255, 255, imx)
svd_image.append(imx.astype('uint8'))
img = np.stack((svd_image[0], svd_image[1], svd_image[2]), 2)
plt.subplot(1, len(ks), idx+1)
plt.imshow(img)
plt.axis('off')
plt.title("k="+str(k))

小结
- 任意一个 m × n m \times n m×n 矩阵,都可以表示为三个矩阵的乘积(因子分解)形式,分别是 m m m阶正交矩阵,由降序排列的非负的对角线元素组成的 m m m x n n n 矩形对角矩阵,和 n n n阶正交矩阵,称为该矩阵的奇异值分解。矩阵的奇异值分解一定存在,但不唯一。
- 奇异值分解可以看作是矩阵数据压缩的一种方法,即用因子分解的方式近似地表示原始矩阵,这种近似是在平方损失意义下的最优近似。
- 奇异值分解有明确的几何解释。奇异值分解对应三个连续的线性变换:一个旋转变换,一个缩放变换和另一个旋转变换第一个和第三个旋转变换分别基于空间的标准正交基进行。
- 奇异值分解包括紧奇异值分解和截断奇异值分解。紧奇异值分解是与原始矩阵等秩的奇异值分解,截断奇异值分解是比原始矩阵低秩的奇异值分解。
参考
- 机器学习中的数学(5)-强大的矩阵奇异值分解(SVD)及其应用:https://www.cnblogs.com/LeftNotEasy/archive/2011/01/19/svd-and-applications.html
- 奇异值分解(SVD)的定义、证明、求法(矩阵分解——3. 奇异值分解(SVD)):https://zhuanlan.zhihu.com/p/399547902
- 奇异值分解的揭秘(一):矩阵的奇异值分解过程:https://zhuanlan.zhihu.com/p/26306568
- 奇异值分解(SVD)原理与在降维中的应用:https://www.cnblogs.com/pinard/p/6251584.html







![[Database] 脏读、幻读这些都是什么?事务隔离级别又是什么?MySQL数据库的事务隔离级别都有哪些?](https://img-blog.csdnimg.cn/0b42b3bc46874658a5c93fe5e8c41c09.png)