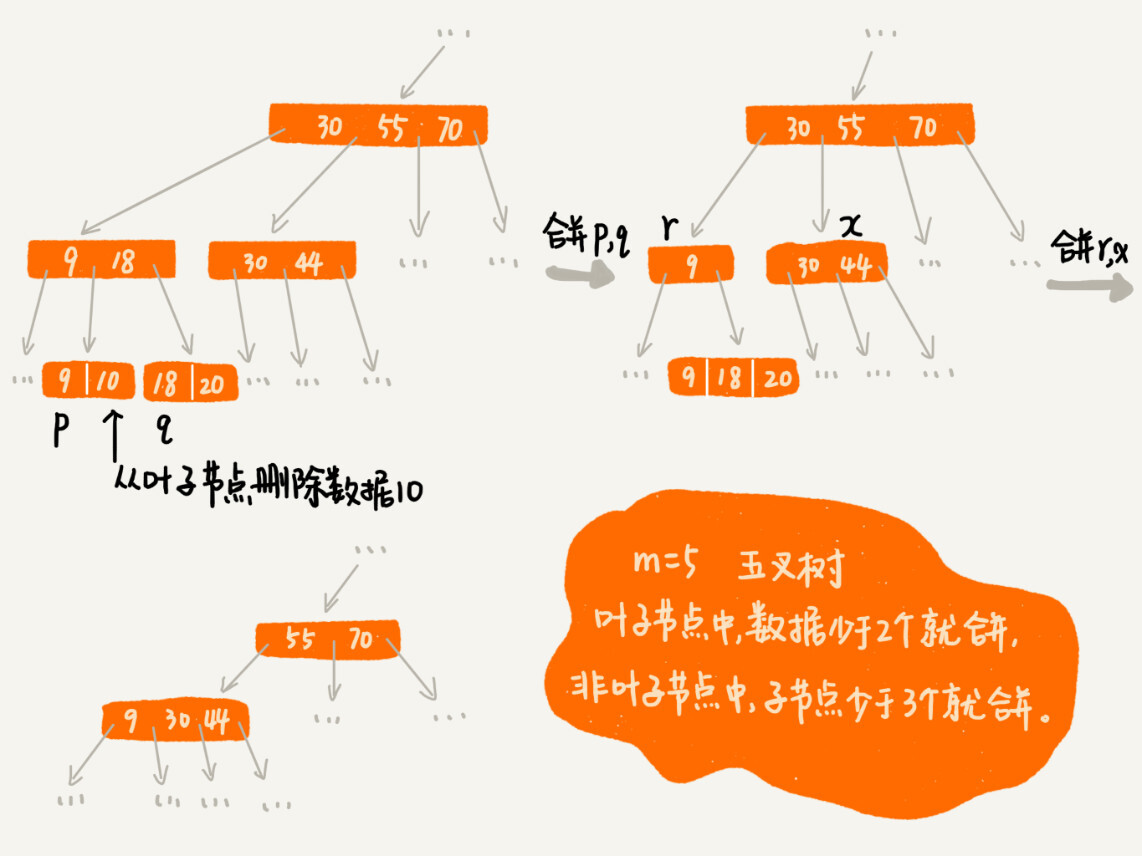
Random Forest Variable importance
- 算法介绍
- 实现
- 算法流程
- 分类
- 回归
- 实验
- 实验1:waveform数据集(分类)
- 实验2:superconductivity数据集(回归)
- 实验3:power-consumption数据集(回归)
- 实验4:mnist数据集(可视化实验)
- 实验5:与sklearn的验证
- 附录
项目主页:randomforest
C++ implementation of random forests classification, regression, proximity and variable importance.
推荐阅读:Random Forests C++实现:细节,使用与实验
算法介绍
特征重要性评估(Variable importance measure, or Feature importance evaluation)用来计算样本特征的重要性,定量地描述特征对分类或者回归的贡献程度。随机森林可以用来对特征重要性进行评估,从另一个角度来说,特征重要新评估是随机森林的一种自带工具,主要分为两种方法:(1)Mean Decrease Impurity(MDI),通过统计节点分裂时不纯度的下降数值来衡量某个节点的重要性;(2)Mean Decrease Accuracy(MDA), 方法是随机交换袋外数据集 (permuted oob data) 中某个特征的值,然后重新进行预测,通过衡量分类/回归的准确度下降的程度来计算该特征的重要性。这两种方法的思想都是Leo Breiman提出的。
MDI使用的是训练集数据,在RF训练完成后就能直接获取MDI特征重要性评估值;MDA使用的是oob数据,需要在RF训练完成后独立运行特征重要性评估的程序。由于MDI完全使用训练数据,它可能对评估的准确性造成影响,而且更加倾向于加大high cardinality features的权重。相比之下,MDA的结果更加准确。MDI与MDA的对比可以查看sklearn给出的实验——Permutation Importance vs Random Forest Feature Importance (MDI)。
Mean Decrease Accuracy:
The MDA of X(j) is obtained by averaging the difference in out-of-bag error estimation before and after the permutation over all trees.
—— Biau, G., Scornet, E. A random forest guided tour. TEST 25, 197–227 (2016).
本文讨论和实现MDA方法,特征
j
j
j(样本第
j
j
j维)的重要性计算方法如下:
(1)分类:
M
D
A
c
(
j
)
=
1
T
∑
t
T
[
1
∣
D
t
∣
(
∑
X
i
∈
D
t
I
(
P
(
X
i
)
=
=
y
i
)
−
∑
X
i
j
∈
D
t
j
I
(
P
(
X
i
j
)
=
=
y
i
)
)
]
MDA_c(j)=\frac {1}{T} \sum_t^T\left [ \frac{1}{|D_t|} \left( \sum_{X_i\in D_t} I(P(X_i)==y_i)- \sum_{X_i^j\in D_t^j} I(P(X_i^j)==y_i) \right) \right]
MDAc(j)=T1t∑T
∣Dt∣1
Xi∈Dt∑I(P(Xi)==yi)−Xij∈Dtj∑I(P(Xij)==yi)
(2)回归:
M
D
A
r
(
j
)
=
1
T
∑
t
T
[
1
∣
D
t
∣
(
∑
X
i
j
∈
D
t
j
∑
k
(
R
k
(
X
i
j
)
−
y
i
k
)
2
−
∑
X
i
∈
D
t
∑
k
(
R
k
(
X
i
)
−
y
i
k
)
2
)
]
MDA_r(j)=\frac {1}{T} \sum_t^T\left [ \frac{1}{|D_t|} \left( \sum_{X_i^j\in D_t^j} \sum _k \left(R_k(X_i^j)-y_i^k\right)^2- \sum_{X_i\in D_t} \sum_k \left(R_k(X_i)-y_i^k\right)^2 \right) \right]
MDAr(j)=T1t∑T
∣Dt∣1
Xij∈Dtj∑k∑(Rk(Xij)−yik)2−Xi∈Dt∑k∑(Rk(Xi)−yik)2
以上公式参考自Gérard Biau的经典论文"A Random Forest Guided Tour",解释下公式中的符号:
- T T T: RF中随机树的数量
- ( X i , y i ) (X_i,y_i) (Xi,yi): 样本,对于分类 y y y为类别,对于回归为输出(可以是多维)
- X i j X_i^j Xij: X i X_i Xi的第 j j j维(特征)随机交换后的样本
- D t D_t Dt: 随机树 t t t的袋外(oob)样本集, D t j D_t^j Dtj: 第 j j j维交换后形成的样本集
- P ( X i ) P(X_i) P(Xi): 样本 X i X_i Xi的预测结果(类别); R ( X i ) R(X_i) R(Xi):样本 X i X_i Xi的预测输出(回归)
- I ( P X i = = y i ) I(P_{X_i}==y_i) I(PXi==yi): 指示函数,如果预测结果与真实类别相同,则返回1,否则返回0。
- y i k y_i^k yik: 考虑到多目标回归,表示第 k k k维输出
这个公式反映了,对样本第
j
j
j维(特征)上的数据进行随机交换后,模型预测(分类)准确度或者(回归)精度下降的程度,使用的是每棵树的袋外数据。如果在随机交换后,准确度下降较多,则认为这个特征比较重要。
上面公式中
M
D
A
c
(
j
)
、
M
D
A
r
(
j
)
MDA_c(j)、MDA_r(j)
MDAc(j)、MDAr(j)被称为raw score。对于
M
D
A
c
(
j
)
MDA_c(j)
MDAc(j),在数值上它反映的是当特征
j
j
j 被随机交换后,袋外样本的平均分类正确率的下降值;对于
M
D
A
r
(
j
)
MDA_r(j)
MDAr(j),在数值上它反映的是当特征
j
j
j 被随机交换后,袋外样本均方误差(MSE)的上升数值。
In every tree grown in the forest, put down the oob cases and count the number of votes cast for the correct class. Now randomly permute the values of variable m in the oob cases and put these cases down the tree. Subtract the number of votes for the correct class in the variable-m-permuted oob data from the number of votes for the correct class in the untouched oob data. The average of this number over all trees in the forest is the raw importance score for variable m. by Leo Breiman
实现
算法流程
随机森林MDA算法的流程如下(以分类为例):
训练随机森林模型(树数量
T
T
T),训练过程记录每棵树的袋外数据集
D
t
D_t
Dt
对于每棵树
t
=
1......
T
t=1......T
t=1......T
| 计算
D
t
D_t
Dt上的分类正确的样本数
c
0
c_0
c0:
|
∑
D
t
I
(
P
(
X
i
)
=
=
y
i
)
\sum_{D_t} I(P(X_i)==y_i)
∑DtI(P(Xi)==yi)
| 对于每个特征
j
=
1......
M
j=1......M
j=1......M
| | 对
D
t
D_t
Dt样本的特征
j
j
j进行随机交换得到
D
t
j
D_t^j
Dtj
| | 计算
D
t
j
D_t^j
Dtj上的分类正确的样本数
c
1
c_1
c1:
| |
∑
D
t
j
I
(
P
(
X
i
j
)
=
=
y
i
)
\sum_{D_t^j} I(P(X_i^j)==y_i)
∑DtjI(P(Xij)==yi)
| | 计算:
m
d
a
(
t
,
j
)
=
1
∣
D
t
∣
(
c
0
−
c
1
)
mda(t,j)=\frac{1}{|D_t|}(c_0-c_1)
mda(t,j)=∣Dt∣1(c0−c1)
| end of
j
j
j
end of
t
t
t
对于每个特征
j
=
1......
M
j=1......M
j=1......M
| 计算特征
j
j
j的重要性raw socre:
|
M
D
A
c
(
j
)
=
1
∣
T
∣
∑
t
m
d
a
(
t
,
j
)
MDA_c(j)=\frac{1}{|T|}\sum_t mda(t,j)
MDAc(j)=∣T∣1∑tmda(t,j)
end of
j
j
j
算法的时间复杂度为 O ( M ∗ N ∗ T ) O(M*N*T) O(M∗N∗T), M , N , T M,N,T M,N,T分别是特征数、样本数、随机树数量。运行MDA特征重要性评估的耗时要远远大于随机森林训练的耗时。MDA特征重要性评估的C++实现如下:
分类
int RawVariableImportanceScore(float** data, int* label, LoquatCForest* loquatForest, int nType, float* varImportance, bool bNormalize, char* filename)
{
int var, tr, i, j, oobnum, index;
const int variables_num = loquatForest->RFinfo.datainfo.variables_num;
const int Ntrees = loquatForest->RFinfo.ntrees;
struct LoquatCTreeStruct* pTree = NULL;
int* pIndex = NULL, predicted_class_index;
float confidence;
int correct_num = 0, correct_num_premute = 0;
float* tmp_data = new float[variables_num];
int** DeltMatrix = new int* [Ntrees];
for (i = 0; i < Ntrees; i++)
{
DeltMatrix[i] = new int[variables_num];
memset(DeltMatrix[i], 0, sizeof(int) * variables_num);
}
float* mean_var = new float[variables_num];
memset(mean_var, 0, sizeof(float) * variables_num);
float* std2_var = new float[variables_num];
memset(std2_var, 0, sizeof(float) * variables_num);
int *oobOfTrees = new int[Ntrees];
for (tr = 0; tr < Ntrees; tr++)
{
pTree = loquatForest->loquatTrees[tr];
pIndex = pTree->outofbag_samples_index;
oobnum = pTree->outofbag_samples_num;
oobOfTrees[tr] = oobnum;
int* permuted_order = new int[oobnum];
for (correct_num = 0, i = 0; i < oobnum; i++)
{
index = pIndex[i];
PredictAnTestSampleOnOneTree(data[index], variables_num, pTree, predicted_class_index, confidence);
if (predicted_class_index == label[index])
correct_num++;
}
for (var = 0; var < variables_num; var++)
{
// permuting (var)th variables
// permute [0, oobnum-1]
permute(oobnum, permuted_order);
for (correct_num_premute = 0, i = 0; i < oobnum; i++)
{
index = pIndex[permuted_order[i]];
memcpy(tmp_data, data[pIndex[i]], variables_num * sizeof(float));
tmp_data[var] = data[index][var];
PredictAnTestSampleOnOneTree(tmp_data, variables_num, pTree, predicted_class_index, confidence);
if (predicted_class_index == label[pIndex[i]])
correct_num_premute++;
}
DeltMatrix[tr][var] = correct_num - correct_num_premute;
mean_var[var] += (correct_num - correct_num_premute)/(float)oobOfTrees[tr];
}
delete[]permuted_order;
}
for (i = 0; i < variables_num; i++)
mean_var[i] = mean_var[i] / Ntrees;
for (i = 0; i < variables_num; i++)
{
for (j = 0; j < Ntrees; j++)
std2_var[i] += (DeltMatrix[j][i]/(float)oobOfTrees[j] - mean_var[i]) * (DeltMatrix[j][i]/(float)oobOfTrees[j] - mean_var[i]);
std2_var[i] /= Ntrees;
}
float* raw_score = new float[variables_num];
float* z_score = new float[variables_num];
memset(raw_score, 0, sizeof(float) * variables_num);
memset(z_score, 0, sizeof(float) * variables_num);
float fsum = 0.f;
// raw score
for (i = 0; i < variables_num; i++)
{
raw_score[i] = mean_var[i];
fsum += raw_score[i];
}
// Normalization
if (bNormalize) {
for (i = 0; i < variables_num; i++)
raw_score[i] /= fsum;
}
// z-score
fsum = 0.f;
for (i = 0; i < variables_num; i++)
{
z_score[i] = mean_var[i] / (sqrtf(std2_var[i]) + FLT_EPSILON); //0530
fsum += z_score[i];
}
// Normalization
if (bNormalize) {
for (i = 0; i < variables_num; i++)
z_score[i] /= fsum;
}
if (nType == 0) // raw_score
memcpy(varImportance, raw_score, sizeof(float) * variables_num);
else // z-score
memcpy(varImportance, z_score, sizeof(float) * variables_num);
if (filename != NULL)
{
fstream vieFile;
vieFile.open(filename, ios_base::out);
if (vieFile.is_open())
{
vieFile << "variable index" << "\t" << "raw score" << "\t\t" << "z-score" << endl;
for (i = 0; i < variables_num; i++)
vieFile << i << "\t\t" << raw_score[i] << "\t\t" << z_score[i] << endl;
vieFile.close();
}
}
delete[] tmp_data;
for (i = 0; i < Ntrees; i++)
delete[] DeltMatrix[i];
delete[] DeltMatrix;
delete[] mean_var;
delete[] std2_var;
delete[] oobOfTrees;
delete[] raw_score;
delete[] z_score;
return 0;
}
回归
回归森林中的实现比分类森林中复杂一些,主要是要兼顾多目标回归的情况。
int RawVariableImportanceScore(float** data, float* target, LoquatRForest* loquatForest, int nType, float* varImportance, bool bNormalize, char* filename)
{
int var, tr, i, j, oobnum, index;
const int variables_num = loquatForest->RFinfo.datainfo.variables_num_x;
const int target_num = loquatForest->RFinfo.datainfo.variables_num_y;
const int Ntrees = loquatForest->RFinfo.ntrees;
int* pIndex = NULL;
float confidence, predicted=0.f;
float *mse = new float[target_num];
float *mse_premute = new float[target_num];
float *target_predicted = NULL;
float* tmp_data = new float[variables_num];
float** DeltMatrix = new float * [Ntrees];
for (i = 0; i < Ntrees; i++)
{
DeltMatrix[i] = new float[variables_num];
memset(DeltMatrix[i], 0, sizeof(float) * variables_num);
}
float* mean_var = new float[variables_num];
memset(mean_var, 0, sizeof(float) * variables_num);
float* std2_var = new float[variables_num];
memset(std2_var, 0, sizeof(float) * variables_num);
int *oobOfTrees = new int[Ntrees];
for (tr = 0; tr < Ntrees; tr++)
{
pIndex = loquatForest->loquatTrees[tr]->outofbag_samples_index;
oobnum = loquatForest->loquatTrees[tr]->outofbag_samples_num;
oobOfTrees[tr] = oobnum;
int* permuted_order = new int[oobnum];
memset(mse, 0, sizeof(float)*target_num);
for (i = 0; i < oobnum; i++)
{
index = pIndex[i];
target_predicted = GetArrivedLeafNode(loquatForest, tr, data[index])->pLeafNodeInfo->MeanOfArrived;
for(int k=0; k<target_num; k++)
{
predicted = loquatForest->bTargetNormalize == false ? target_predicted[k] : (target_predicted[k] - loquatForest->offset[k])/ loquatForest->scale[k];
mse[k] += (target[index*target_num+k]-predicted) * (target[index*target_num+k]-predicted);
}
}
for (var = 0; var < variables_num; var++)
{
// permuting (var)th variables
// permute [0, oobnum-1]
permute(oobnum, permuted_order);
memset(mse_premute, 0, sizeof(float)*target_num);
for (i = 0; i < oobnum; i++)
{
index = pIndex[permuted_order[i]];
memcpy(tmp_data, data[pIndex[i]], variables_num * sizeof(float));
tmp_data[var] = data[index][var];
target_predicted = GetArrivedLeafNode(loquatForest, tr, tmp_data)->pLeafNodeInfo->MeanOfArrived;
for(int k=0; k<target_num; k++)
{
predicted = loquatForest->bTargetNormalize == false ? target_predicted[k] : (target_predicted[k] -loquatForest->offset[k])/loquatForest->scale[k];
mse_premute[k] +=(target[pIndex[i]*target_num+k] - predicted)*(target[pIndex[i]*target_num+k] - predicted);
}
}
for (int k=0; k<target_num; k++)
DeltMatrix[tr][var] += (mse_premute[k] - mse[k]);
mean_var[var] += DeltMatrix[tr][var]/(float)oobOfTrees[tr];
}
delete[]permuted_order;
}
for (i = 0; i < variables_num; i++)
mean_var[i] = mean_var[i] / Ntrees;
for (i = 0; i < variables_num; i++)
{
for (j = 0; j < Ntrees; j++)
std2_var[i] += (DeltMatrix[j][i]/(float)oobOfTrees[j] - mean_var[i]) * (DeltMatrix[j][i]/(float)oobOfTrees[j] - mean_var[i]);
std2_var[i] /= Ntrees;
}
float* raw_score = new float[variables_num];
float* z_score = new float[variables_num];
memset(raw_score, 0, sizeof(float) * variables_num);
memset(z_score, 0, sizeof(float) * variables_num);
float fsum = 0.f;
// raw score
for (i = 0; i < variables_num; i++)
{
raw_score[i] = mean_var[i];
fsum += raw_score[i];
}
// Normalization
if (bNormalize) {
for (i = 0; i < variables_num; i++)
raw_score[i] /= fsum;
}
// z-score
fsum = 0.f;
for (i = 0; i < variables_num; i++)
{
z_score[i] = mean_var[i] / (sqrtf(std2_var[i]) + FLT_EPSILON); //0530
fsum += z_score[i];
}
// Normalization
if (bNormalize) {
for (i = 0; i < variables_num; i++)
z_score[i] /= fsum;
}
if (nType == 0) // raw_score
memcpy(varImportance, raw_score, sizeof(float) * variables_num);
else // z-score
memcpy(varImportance, z_score, sizeof(float) * variables_num);
if (filename != NULL)
{
fstream vieFile;
vieFile.open(filename, ios_base::out);
if (vieFile.is_open())
{
vieFile << "variable index" << "\t" << "raw score" << "\t\t" << "z-score" << endl;
for (i = 0; i < variables_num; i++)
vieFile << i << "\t\t" << raw_score[i] << "\t\t" << z_score[i] << endl;
vieFile.close();
}
}
delete[] tmp_data;
delete[] mse;
delete[] mse_premute;
for (i = 0; i < Ntrees; i++)
{
delete[] DeltMatrix[i];
DeltMatrix[i] = NULL;
}
delete[] DeltMatrix;
delete[] mean_var;
delete[] std2_var;
delete[] oobOfTrees;
delete[] raw_score;
delete[] z_score;
return 1;
}
上述代码随机随机森林实现的一部分,建议到项目主页randomforest上查看。
实验
本节通过实验展示了随机森林特征重要性评估的效果,选取了分类和回归中典型的数据集,特征数量为11、40、81、780、4096。并根据数据集的特点给出可视化结果,以此验证本项目实现的准确性。
实验1:waveform数据集(分类)
使用waveform数据集,训练样本数5000,特征40维,类别数3。RF参数为随机树200棵,分类候选特征数
40
\sqrt{40}
40。运行5次得到以下特征重要性的柱状图,显示每个特征重要性的平均值及标准差。这个数据是经典的用于特征重要性评估验证的数据集,它的后19维特征是随机噪声,计算结果符合上述情况。

实验2:superconductivity数据集(回归)
数据集superconductivity的特征81维,训练样本数21263,采集和加工自超导体临界温度的实验。随机回归森林的参数为:随机树 T = 200 T=200 T=200,分类候选特征数 81 3 \frac{81}{3} 381,节点最小样本数5,最大树深度40,都是默认参数。运行5次得到以下特征重要性的柱状图,显示每个特征重要性的平均值及标准差。

实验3:power-consumption数据集(回归)
使用Tetuan-City-power-consumption数据集来进行试验,原始数据集是通过时间、温度、湿度、风速等6个变量来预测城市3个配电网的能源消耗,即输入6维,输出3维。由于“时间”变量难以使用,所以分解为[minute,hour,day,month,weekday,weekofyear] 6个变量,加上原始的5个气象变量 (temperature, light, sound, CO2 and digital passive infrared (PIR)),形成新的11维输入。随机回归森林的参数为:随机树
T
=
200
T=200
T=200,分类候选特征数
4
=
11
3
4=\frac{11}{3}
4=311,节点最小样本数5,最大树深度40,都是默认参数。可以看到hour,month,weekofyear,气温这四个特征(变量)的重要性排名前列,符合常理。

实验4:mnist数据集(可视化实验)
使用mnist手写字符识别数据集训练随机森林分类器,样本数60000,特征数780。RF参数为:随机树 T = 200 T=200 T=200,分类候选特征数 780 \sqrt{780} 780,节点最小样本数5,最大树深度40。将特征重要性的输出值转换为相同分辨率的图像(28x28,780+4,在最后增补了4个0),如下图。可以看到重要特征集中在图像中部,周边的特征重要性非常低,这也符合手写字符训练图像周边像素大多为0的情况。

实验5:与sklearn的验证
Scikit-learn中实现了随机森林MDI方法,在训练结束后可以获取特征重要性的权重值。官网文章“Pixel importances with a parallel forest of trees”通过olivetti_faces人脸识别数据集对像素级特征的重要性进行了可视化。
将本项目输出的olivetti_faces人脸像素特征重要性与sklearn结果进行对比,以验证本项目实现的随机森林在特征重要性评估中的有效性。使用olivetti_faces人脸识别数据集进行验证,选取样本数50(选取了前5类样本,与sklearn官网的实验保持一致),特征数4096(64x64图像),每个样本是一张人脸图像。RF参数为:随机树
T
=
750
T=750
T=750,分类候选特征数
4096
\sqrt{4096}
4096,节点最小样本数1,最大树深度40。这个实验是为了与sklearn的的结果进行比较,实验样本完全相同,参数尽量接近。从可视化结果看,本项目的输出(上图)与sklearn的MDI类似,这验证了本项目实现的特征重要性算法的正确性。


附录
使用我实现的randomforest算法进行RF训练+特征重要性评估的代码如下(以分类森林为例):
int main()
{
// read training samples if necessary
char filename[500] = "/to/direction/dataset/train-data.txt"
float** data = NULL;
int* label = NULL;
Dataset_info_C datainfo;
int rv = InitalClassificationDataMatrixFormFile2(filename, data/*OUT*/, label/*OUT*/, datainfo/*OUT*/);
// check the return value
// ... ...
// setting random forests parameters
RandomCForests_info rfinfo;
rfinfo.datainfo = datainfo;
rfinfo.maxdepth = 40;
rfinfo.ntrees = 200;
rfinfo.mvariables = (int)sqrtf(datainfo.variables_num);
rfinfo.minsamplessplit = 5;
rfinfo.randomness = 1;
// train forest
LoquatCForest* loquatCForest = NULL;
rv = TrainRandomForestClassifier(data, label, rfinfo, loquatCForest /*OUT*/, 20);
// check the return value
// ... ...
// variable importance measure
float *vim = new float [datainfo.variables_num];
RawVariableImportanceScore2(data, label, loquatCForest, 0/*raw score*/, vim, true, "file_to_store.txt");
delete [] vim;
// clear the memory allocated for the entire forest
ReleaseClassificationForest(&loquatCForest);
// release money: data, label
for (int i = 0; i < datainfo.samples_num; i++)
delete[] data[i];
delete[] data;
delete[] label;
return 0;
}