论文简要总结
刚读了下speed is all you need这个论文, https://arxiv.org/pdf/2304.11267.pdf
只是用的SD1.4没有对网络进行改造。
只做了4个改动
1 是对norm采用了groupnorm (GPU shader加速)
2 采用了GELU (GPU shader加速)
3 采用了两种attention优化,是partitially fused softmax或者Flash attention(2种方法视情况选1)
4 采用了winograd 卷积
实验效果 SD1.4 出512x512的图,迭代12次,12s以下(手机端)
under 12 seconds for Stable Diffusion 1.4 without INT8 quantization for a 512 × 512 image with 20 iterations
1 摘要
Large diffusion models have gained signifificant attention for their ability to generate photorealistic images and support various tasks.
On-device deployment of these models provides benefits such as lower server costs, offline functionality, and improved user privacy.
However, com mon large diffusion models have over 1 billion parameters and pose challenges due to restricted computational and memory resources on devices.
We present a series of implementation optimizations for large diffusion models that achieve the fastest reported inference latency to-date(under 12 seconds for Stable Diffusion 1.4 without INT 8 quantization for a 512 × 512 image with 20 iterations) on GPU
These enhancements broaden the applicability of generative AI and improve the overall user experience across a wide range of devices.
大型扩散模型因其生成逼真图像和支持各种任务的能力而在上获得了显著的关注。
这些模型的设备上部署提供了诸如降低服务器成本、脱机功能和改进用户隐私等好处。
然而,com许多大型扩散模型具有超过10亿个参数,并且由于设备上有限的计算和内存资源而带来挑战。
我们提出了一系列针对大型扩散模型的实现优化,这些模型在GPU上实现了迄今为止最快的推断延迟(对于512 × 512图像,在没有INT8量化的情况下,SD1.4在12秒内实现了20次迭代)配备移动设备。
这些增强扩大了生成式人工智能的适用性,并在各种设备上改善了整体用户体验。
实验
We chose the following target devices (and their GPU chip):
Samsung S23 Ultra (Adreno 740), and iPhone 14 Pro Max (A16).
As the denoising neural network, UNet, is the most computationally demanding component, we provide the latency fifigures for executing UNet for a single iteration with 512 × 512 image resolution, measured in milliseconds.
Additionally, we document the memory usage generated during runtime for the intermediate tensors in the “Tensor” column and the memory allocated for holding the model weights in the “Weight” column, both quantifified in megabytes.
Note that the memory manager [17] optimizes the memory footprint by reusing the buffers for intermediate tensors.
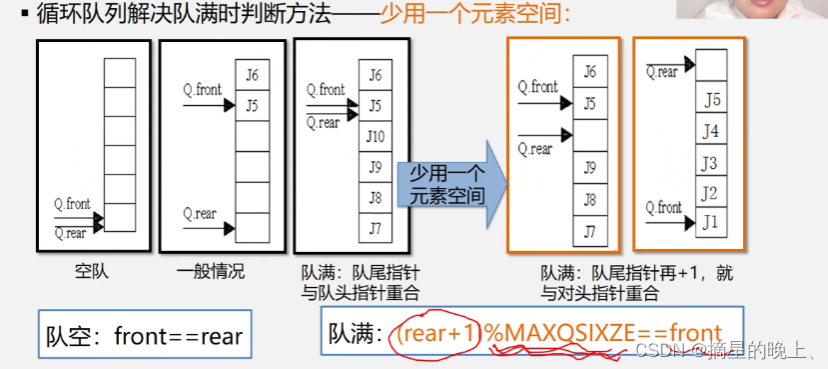
为了评估改进,我们在各种设备上进行了一组基准测试,如表1所示。
我们选择了以下目标设备(及其GPU芯片):
三星S23 Ultra (Adreno 740)和iPhone 14 Pro Max (A16)。
由于去噪神经网络UNet是计算要求最高的组件,我们提供了在512 × 512图像分辨率下执行UNet的单次迭代的延迟数字,以毫秒秒为单位测量。
此外,我们记录了运行时为“Tensor”列中的中间张量生成的内存使用情况,以及为保存“Weight”列中的模型权重而分配的内存,两者都以兆字节为单位进行量化。
请注意,内存管理器[17]通过重用中间张量的缓冲区来优化内存占用。
The table’s first row displays the result that follows the implementation in the public Github repository [19] using our internal OpenCL kernels without any optimizations.
Rows 2 through 5 sequentially enable each optimiza tion individually:
“Opt. Softmax” refers to the partially fused softmax and optimized softmax reduction step (subsection 3.2;
“S-GN/GELU” relates to the specialized kernels for Group Normalization and GELU (subsection 3.1;
“FlashAttn.” pertains the FlashAttention implementation (subsection 3.2);
“Winograd(All)” employs the Winograd convolution (subsection 3.3).
Note that each row includes all optimizations of its preceding rows, making the last row our final optimization numbers.
表的第一行显示了在公共Github存储库[19]中实现的结果,我们在没有任何优化的情况下使用内部OpenCL内核。
第2行到第5行依次单独启用每个优化:
“Opt. Softmax”是指部分融合的Softmax和优化的Softmax缩减步骤(参见章节3.2;
“S-GN/GELU”涉及群归一化和GELU的专门ker(第3.1节;
“FlashAttn。涉及FlashAttention实现(第3.2节);
“Winograd(All)”使用Winograd卷积(第3.3节)。
请注意,每一行都包含其前一行的所有优化,使最后一行成为我们的最终优化数。
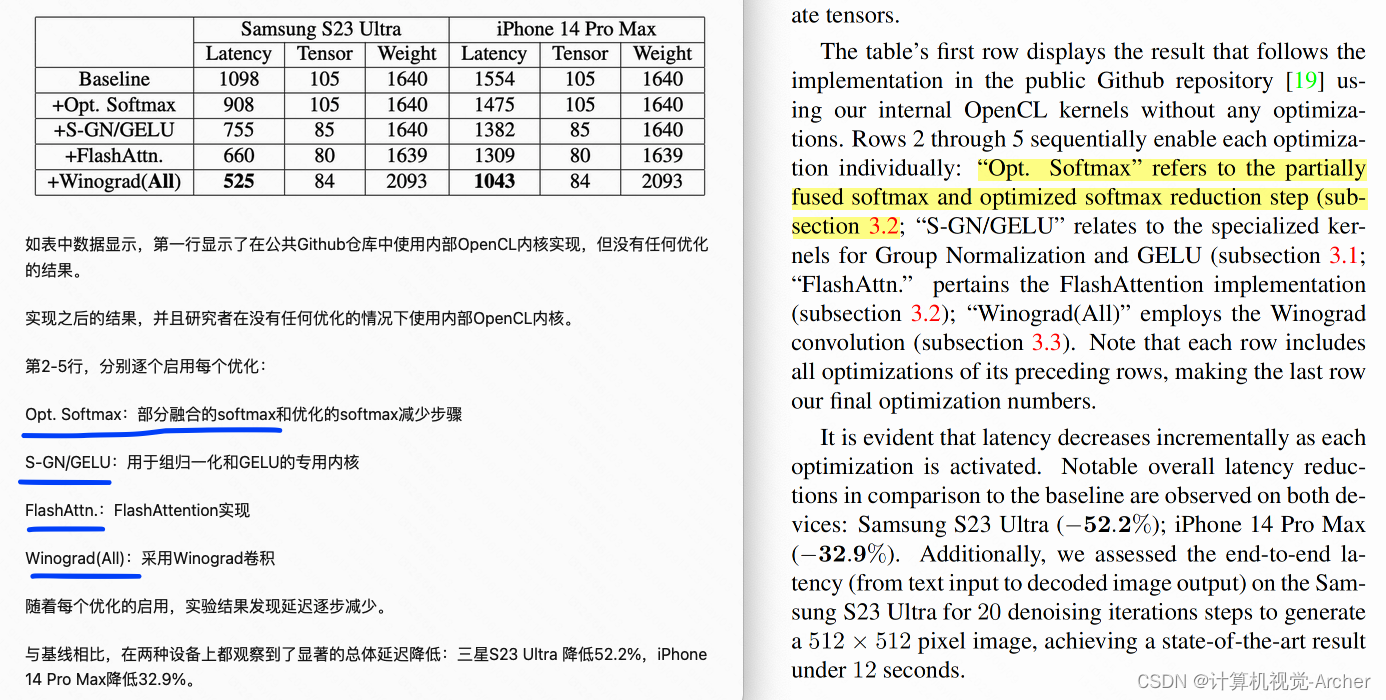
Notable overall latency reductions in comparison to the baseline are observed on both devices: Samsung S23 Ultra ( − 52 . 2 % ); iPhone 14 Pro Max ( − 32 . 9 % ).
Additionally, we assessed the end-to-end latency (from text input to decoded image output) on the Samsung S23 Ultra for 20 denoising iterations steps to generate a 512 × 512 seconds. pixel image, achieving a state-of-the-art result under 12 seconds
与基线相比,在两种设备上都观察到显着的总体延迟降低:
三星S23 Ultra (- 52.2%);iPhone 14 Pro Max(−32.9%);
此外,我们在Samsung S23 Ultra上评估了20个去噪迭代步骤的端到端la趋势(从文本输入到解码图像输出),以在× 12 512秒内生成512。像素图像,在12秒内达到最先进的效果