数据结构之队列
- 队列的概念
- 顺序队列
- 循环队列
- 顺序循环队列的ADT定义
- 1、简单结构体定义
- 2、初始化
- 3、队列的清空
- 4、计算队列的长度
- 5、判断队列是否为空
- 6、插入新的元素
- 7、元素的删除
- 8、遍历输出队列内的所有元素
- 链队列的ADT定义
- 1、链队列简单结构体定义
- 2、初始化链队列
- 3、判断链队列是否为空
- 4、清空链队列
- 5、销毁链队列
- 6、获取链队列的长度
- 7、获取链队列的头元素
- 8、在链队列尾插入新元素
- 9、删除链队列的头元素
- 10、遍历链队列中的元素
- 顺序队列和链式队列的比较
队列的概念
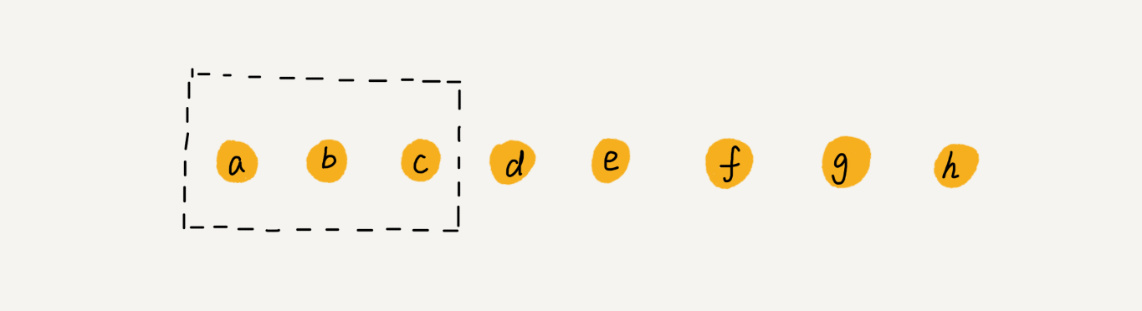
队列(queue)和栈类似,队列中的数据也呈线性排列,但是队列中添加和删除数据的操作分别是在两端进行。就和“ 队列” 这个名字一样,把它想象成排成一队的人更容易理解。在队列中,处理总是从第一个位置开始往后进行,而新来的人只能排在最后的位置。
队列是只允许在一端进行插入操作,在另一端进行删除操作,是一种先进先出的线性表, First In First Out,简称FIFO。允许插入的一 端称为队尾,允许删除的一端称为队头。
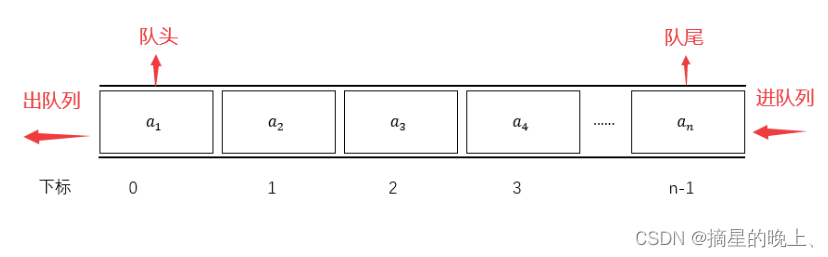
线性表有顺序存储和链式存储两种形式,队列作为一种特殊的线性表,也存在着这两种存储方式。
顺序队列
顺序存储形式的队列,是利用一组地址连续的存储单元,每个存储单元依次存放队列中的元素。为了避免当只有一个元素时,队头和队尾重合使得处理变得麻烦,所以引入两个指针(头指针和尾指针):头指针front指针指向队头元素,尾指针rear指针指向队尾元素的下一个位置。初始化时的头尾指针,初始值均为0。
入队时尾指针rear加1,出队时头指针front加1,头尾指针相等时队列即为空。
当尾指针已经指向了队列的最后一个位置的下一位置时,若再有元素入队,就会发生“溢出”。
为了解决溢出问题,可以采用循环队列。
循环队列
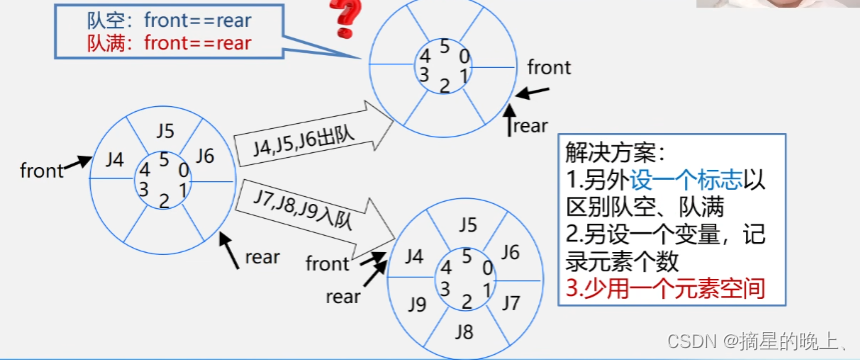
使用循坏队列,将新元素再插入到第一个位置上,入队和出队仍按先进先出的原则进行,操作效率高,空间利用率高,同时解决了顺序队列的假溢出问题。

但是,同时仅凭 front = rear 不能判定循环队列是空还是满
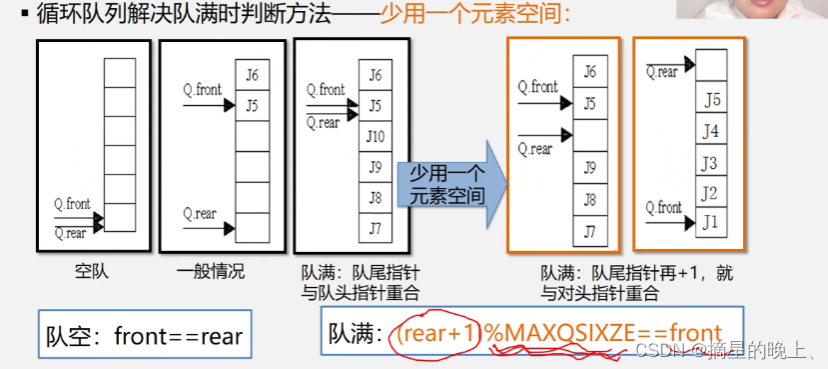
判断队空或者队满,有三种方式:
顺序循环队列的ADT定义
1、简单结构体定义
typedef int Status;
typedef int QElemType; // QElemType类型根据实际情况而定,这里假设为int
// 循环队列的顺序存储结构
typedef struct
{
QElemType data[MAXSIZE];
int front; // 头指针
int rear; // 尾指针,若队列不空,指向队列尾元素的下一个位置
}SqQueue;
2、初始化
Status InitQueue(SqQueue *Q)
{
Q->front = 0;
Q->rear = 0;
return TRUE;
}
3、队列的清空
Status ClearQueue(SqQueue *Q)
{
Q->front = Q->rear = 0;
return TRUE;
}
4、计算队列的长度
int QueueLength(SqQueue Q)
{
return (Q.rear - Q.front + MAXSIZE) % MAXSIZE;
}
5、判断队列是否为空
若队列不空,则用e返回Q的队头元素,并返回TRUE,否则返回FALSE
Status GetHead(SqQueue Q, QElemType *e)
{
if (Q.front == Q.rear) /* 队列空 */
return FALSE;
*e = Q.data[Q.front];
return TRUE;
}
6、插入新的元素
若队列未满,则插入元素e为Q新的队尾元素
Status EnQueue(SqQueue *Q, QElemType e)
{
if ((Q->rear + 1) % MAXSIZE == Q->front) // 队列满的判断
return FALSE;
Q->data[Q->rear] = e; // 将元素e赋值给队尾
Q->rear = (Q->rear + 1) % MAXSIZE;// rear指针向后移一位置,若到最后则转到数组头部
return TRUE;
}
7、元素的删除
若队列不空,则删除Q中队头元素,用e返回其值
Status DeQueue(SqQueue *Q, QElemType *e)
{
if (Q->front == Q->rear) //*队列空的判断
return FALSE;
*e = Q->data[Q->front]; // 将队头元素赋值给e
Q->front = (Q->front + 1) % MAXSIZE; //front指针向后移一位置,到了最后则转到数组头部
return TRUE;
}
8、遍历输出队列内的所有元素
队头到队尾依次对队列Q中每个元素输出
Status QueueTraverse(SqQueue Q)
{
int i;
i = Q.front;
while ((i + Q.front) != Q.rear)
{
visit(Q.data[i]);
i = (i + 1) % MAXSIZE;
}
printf("\n");
return TRUE;
}
链队列的ADT定义
队列的链式存储结构,就是一个单向链表。链式队列和单向链表比就多了两个指针,头指针和尾指针。
优点:
相比普通的队列,元素出队时无需移动大量元素,只需移动头指针。
可动态分配空间,不需要预先分配大量存储空间。
适合处理用户排队等待的情况。
缺点:
需要为表中的逻辑关系增加额外的存储空间。
读取时的时间复杂度为O(1)。
插入、删除时的时间复杂度为O(1)。
1、链队列简单结构体定义
typedef int Status; // 函数返回结果类型
typedef int ElemType; // 元素类型
// 队列节点
typedef struct QNode {
ElemType data; // 元素值
struct QNode *next; // 指向下一个节点的指针
} QNode, *QueuePtr;
// 链队列结构
typedef struct {
QueuePtr front, rear; // 队头指针、队尾指针
} LinkQueue;
2、初始化链队列
Status InitQueue(LinkQueue *Q) {
// 为队头和队尾指针分配内存
Q->front = Q->rear = (QueuePtr) malloc(sizeof(QNode));
// 内存分配失败,结束程序
if (!Q->front || !Q->rear) {
return FALSE;
}
Q->front->next = NULL; // 队头节点指向NULL
return TRUE;
}
3、判断链队列是否为空
Status QueueEmpty(LinkQueue Q) {
// 头指针和尾指针位置相等,队列为空
if (Q.front == Q.rear) {
return TRUE;
} else {
return FALSE;
}
}
4、清空链队列
Status ClearQueue(LinkQueue *Q) {
QueuePtr p, q; // p用来遍历队列节点,q用来指向被删除的节点
Q->rear = Q->front; // 队尾指针指向队头指针
p = Q->front->next; // p指向队头指针的下一个节点
Q->front->next = NULL; // 队头指针的下一个节点指向NULL(表示删除之后的所有元素)
// 当队列中还有元素,释放头节点之后的所有节点
while (p) {
q = p; // q节点指向被删除节点
p = p->next; // p指向队列的下一个节点
delete q; // 释放q节点
}
return TRUE;
}
5、销毁链队列
Status DestroyQueue(LinkQueue *Q) {
// 当队列中还有元素
while (Q->front) {
Q->rear = Q->front->next;// 队尾指针指向队头指针的下一个元素
delete Q->front; // 释放队头指针所在节点
Q->front = Q->rear; // 队头指针指向队尾指针(即原来的下一个元素)
}
return TRUE;
}
6、获取链队列的长度
int QueueLength(LinkQueue Q) {
int i = 0; // 用于统计队列长度的计数器
QueuePtr p; // 用于遍历队列的元素
p = Q.front; // p指向队头节点
// 当p没有移动到队尾指针位置
while (p != Q.rear) {
i++; // 计数器加1
p = p->next; // p移动到队列的下一个节点
}
return i; // 返回队列长度
}
7、获取链队列的头元素
Status GetHead(LinkQueue Q, ElemType *e) {
QueuePtr p;
// 队列为空,获取失败
if (Q.front == Q.rear) {
return FALSE;
}
p = Q.front->next; // p指向队列的第一个元素
*e = p->data; // 将队列头元素的值赋值给e元素
return TRUE;
}
8、在链队列尾插入新元素
Status EnQueue(LinkQueue *Q, ElemType e) {
// 给新节点分配空间
QueuePtr s = (QueuePtr) malloc(sizeof(QNode));
// 分配空间失败,结束程序
if (!s) {
return FALSE;
}
s->data = e; // 将值赋值给新节点
s->next = NULL; // 新节点指向NULL
Q->rear->next = s; // 队尾指针的下一个元素指向新节点
Q->rear = s; // 队尾指针指向新节点(新节点成为队尾指针的指向的节点)
return TRUE;
}
9、删除链队列的头元素
Status DeQueue(LinkQueue *Q, ElemType *e) {
QueuePtr p; // 用于指向被删除节点
// 队列为空,出队失败
if (Q->front == Q->rear) {
return FALSE;
}
p = Q->front->next; // p指向队列的第一个元素
*e = p->data; // 将队列头节点的值赋值给元素e
Q->front->next = p->next; // 头指针的下一个节点指向下下个节点(跳过头节点)
// 如果被删除节点是队尾指针指向的节点(删除后队列为空)
if (Q->rear == p) {
Q->rear = Q->front; // 队尾指针指向队头指针
}
delete p; // 释放队头节点
return TRUE;
}
10、遍历链队列中的元素
Status QueueTravel(LinkQueue Q) {
QueuePtr p; // 用于遍历队列中的节点
p = Q.front->next; // p指向头节点
printf("[ ");
// 当队列中还有元素
while (p) {
printf("%d ", p->data); // 打印当前节点的值
p = p->next; // p移动到队列下一个位置
}
printf("]\n");
return TRUE;
}
顺序队列和链式队列的比较
顺序队列是以数组的形式实现的,首指针在出队的时候向后移动,尾指针在入队的时候向后移动,需要考虑队列为空、队列为满的两种情况。
链式队列是以链表的形式实现的,首指针不移动始终指向头节点,尾指针在入队的时候移动指向插入的元素,只考虑队列为空的情况
(只要存储空间够,就能申请内存空间来存放节点,所以不用考虑满,因为链表长度在程序运行过程中可以不断增加)
参考资料:数据结构与算法基础-王卓老师