实验模拟TCP连接的各种异常情况(三次握手丢包,两端异常)
环境搭建
秋招结束,闲来无事,正好把计算机网络一些协议实验过一遍,于是用vmware搭建了一个两机通信的环境,在建立环境的过程中遇到了一些坑点,现记录以作备忘使用。
现环境演示如下:
HostA:
Name:razer
IP:192.168.200.129
MAC:00:0c:29:87:7e:42
OS:Ubuntu20.04 LTS
Interface:ens33
HostB:
name:aaronVM
IP:192.168.200.130
MAC:CentOS7
Interface:ens33
验证TCP三次握手丢包
Ubuntu机(192.168.200.129)作为客户端,CentOS机(192.168.200.130)作为服务端。
第一次握手SYN丢包
模拟第一次丢包可模拟服务端down掉的情况,将服务端的网线断掉,然后客户端终端1开 tcpdump后终端2开curl,设置如下
tcpdump -i ens33 tcp and host 192.168.200.130 and port 80 -w tcp_sys_timeout.pcap
date;curl http://192.168.200.130;date
大约1分钟后客户端超时:
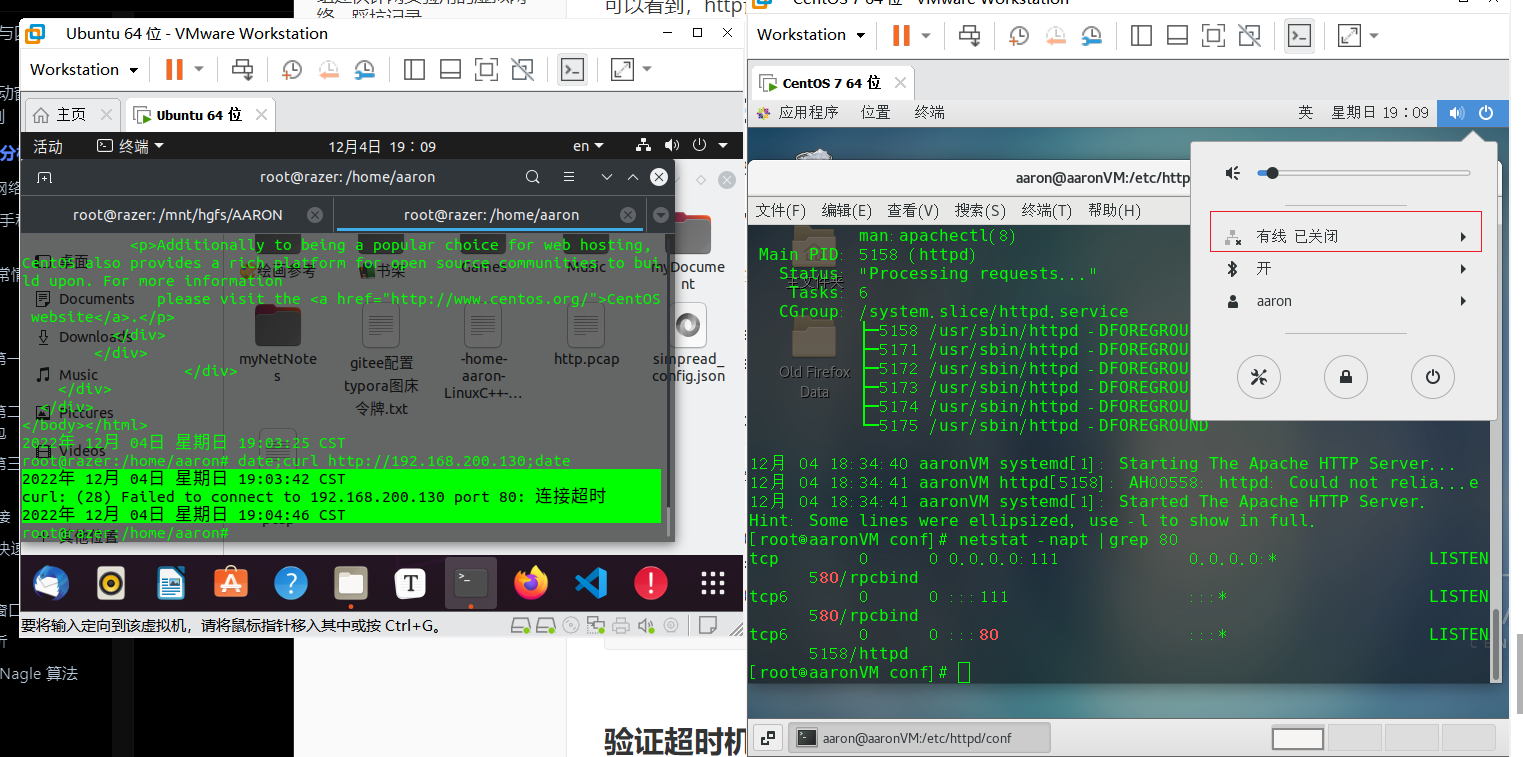
将产生的文件提取出来wireshark抓包:

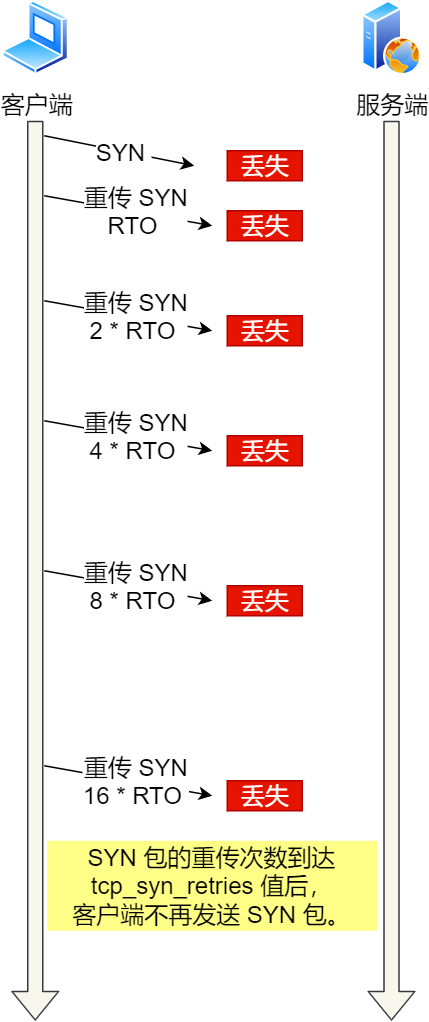
可以看到服务端第一次连接之后重传了5次,每一次重传时间的间隔都是上一次重传间隔的两倍,控制tcp重传次数的内核参数是/proc/sys/net/ipv4/tcp_syn_retries,我查了自己客户端的参数值是5, 也就是 SYN 最大重传次数是 5 次。
cat /proc/sys/net/ipv4/tcp_syn_retries
5
通过实验一的实验结果,我们可以得知,当客户端发起的 TCP 第一次握手 SYN 包,在超时时间内没收到服务端的 ACK,就会在超时重传 SYN 数据包,每次超时重传的 RTO 是翻倍上涨的,直到 SYN 包的重传次数到达 tcp_syn_retries 值后,客户端不再发送 SYN 包。
做这个实验注意服务端关连接之前至少要让客户端成功连接服务端一次,不然客户端会有记忆机制,达不到重传次数就会快速返回连接失败。
第二次握手 SYN、ACK 丢包
模拟客户端收不到服务端第二次握手可通过给客户端加上防火墙拦截的方法实现,直接简单粗暴的把从服务端收到的包都丢弃。
在ubuntu机配置防火墙如下
iptables -I INPUT -s 192.168.200.130 -j DROP
随后做法同第一次试验,提出pcap文件,得:
tcpdump -i ens33 tcp and host 192.168.200.130 and port 80 -w tcp_synack_timeout.pcap
date;curl http://192.168.200.130;date

可以发现,客户端发送syn报文,服务端收到syn报文后回发syn-ack报文,由于客户端的防火墙会拦截并丢弃服务端的syn-ack报文,因此客户端一段时间得不到回应便会自动重发syn,且每次发送间隔是上一次间隔的2倍,服务端收到客户端syn报文后其超时定时器并不会重置,在隔到指定时间后仍会重发synack报文,且报文的重发间隔也是上一次间隔的两倍。
最后客户端和服务端在接受不到应有的回答后各自重传均达到5次后断开连接。
客户端重传第一次握手由tcp_syn_retries控制,服务端重传第二次握手由tcp_synack_retries控制,
我查了自己两个虚拟机的这两个内核参数都是5,对应就是图中客户端和服务端在接受不到应有的回答后各自重传均达到5次后断开连接。
将客户端tcp_syn_retries改为1,服务端tcp_synack_retries不变仍为5,再次实验结果:
echo 1 > /proc/sys/net/ipv4/tcp_syn_retries
可以看到不到3秒客户端显示断连,但是不要马上中断tcpdump抓包,等上大概1多分钟,不然服务端达不到重传次数:
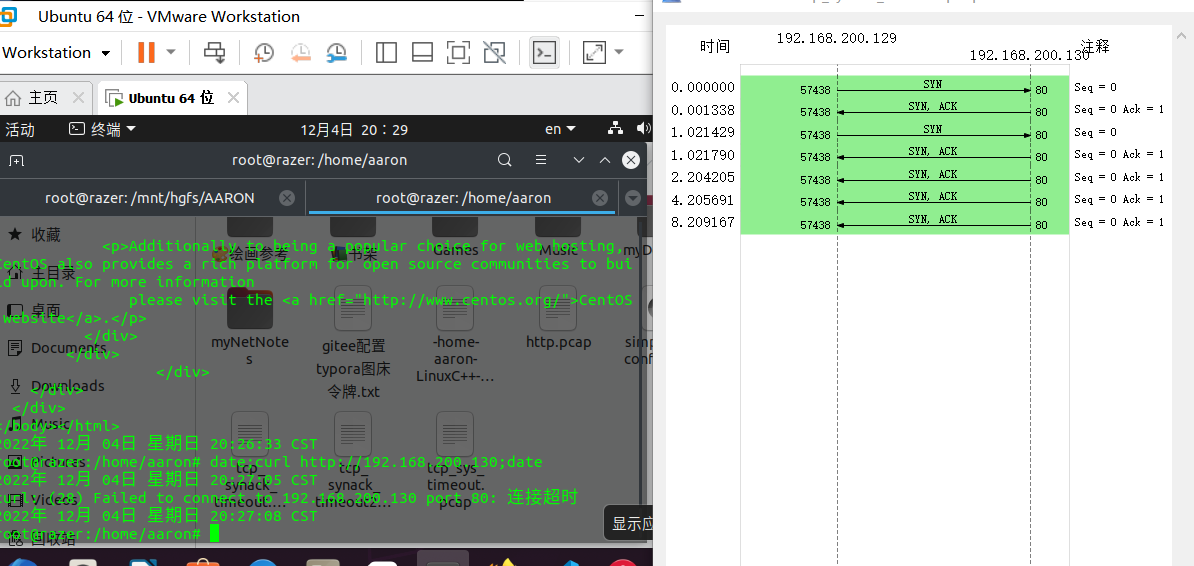
最终的结果如下:
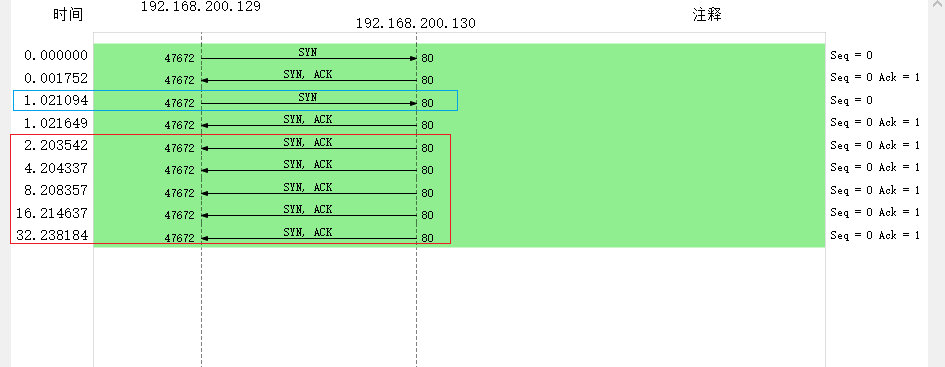
可以看到,客户端只重传了1次,服务端之后重传了5次,分别符合各自的内核参数tcp_syn_retries和tcp_synack_retries
总结:
通过实验二的实验结果,我们可以得知,当 TCP 第二次握手 SYN、ACK 包丢了后,客户端 SYN 包会发生超时重传,服务端 SYN、ACK 也会发生超时重传。
客户端 SYN 包超时重传的最大次数,是由 tcp_syn_retries 决定的,默认值是 5 次;服务端 SYN、ACK 包时重传的最大次数,是由 tcp_synack_retries 决定的,默认值是 5 次。
实验完毕,开始下一次实验,不要忘了还原现场:
iptables -F #清除所有规则
iptables -L #列举所有规则 用于检查
#客户端
echo 5 > /proc/sys/net/ipv4/tcp_syn_retries
#服务端
echo 5 > /proc/sys/net/ipv4/tcp_synack_retries
第三次握手ACK丢包
模拟第三次握手丢包,可对服务端设置防火墙规则,拦截来自客户端的ack:
iptables -I INPUT -s 192.168.200.129 -p tcp --tcp-flag ACK ACK -j DROP
随后客户端架tcpdump,用telnet连接客户端80端口,就会出现如下情景:
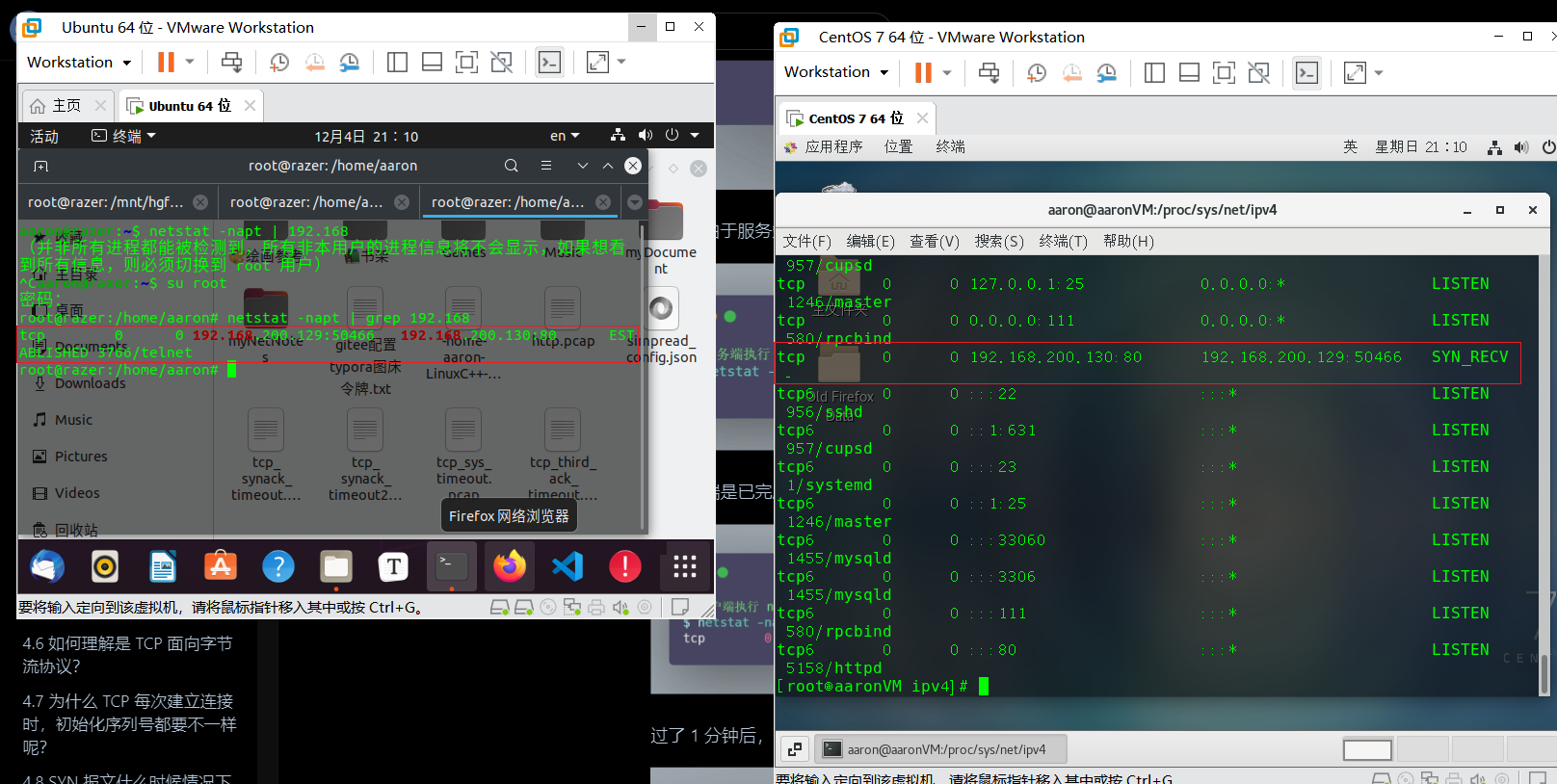
可见服务端由于一直收不到客户端的ACK报文停留在SYN_RECV状态,而客户端由于收到服务端的第二次握手SYN-ACK,已处于ESTABLISH状态。
服务端得不到ACK将会重传SYN_ACK报文,过了一分钟,服务端达到最大重传次数,便中断连接,客户端仍保持ESTABLISH状态。
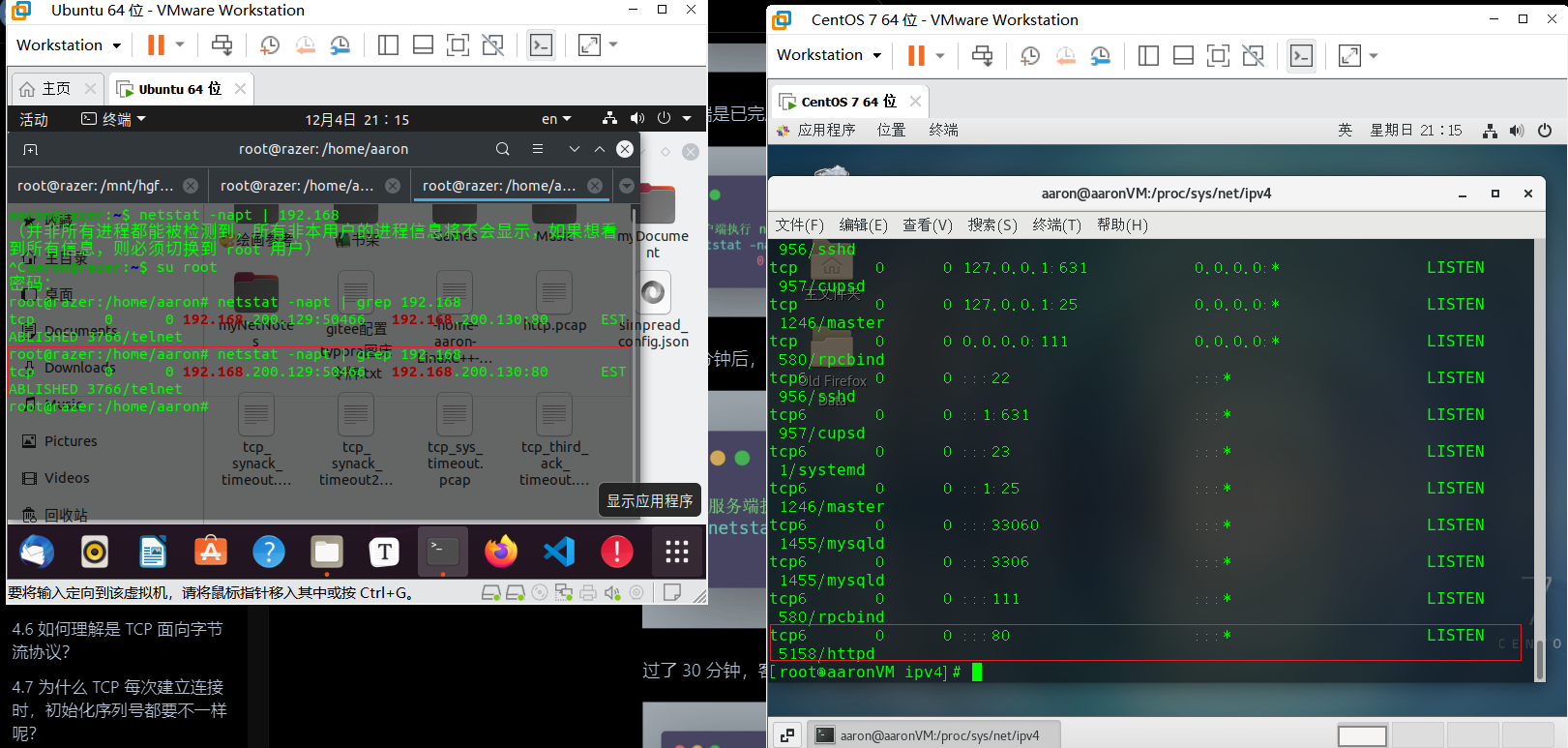
客户端用telnet向服务端发送数据,由于服务端已下线,客户端将一直处于阻塞状态。
root@razer:/home/aaron# telnet 192.168.200.130 80
Trying 192.168.200.130...
Connected to 192.168.200.130.
Escape character is '^]'.
123456
中断tcpdump查看抓包结果:
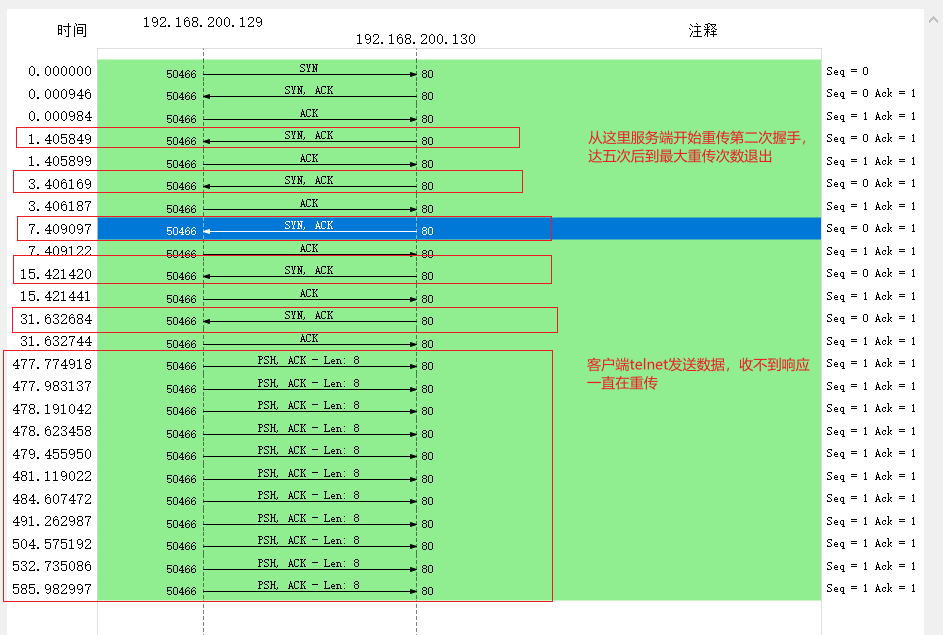
可以发现客户端的ACK到达服务端后被拦截丢弃,致使服务端无法收到客户端响应,启动超时重传机制重发SYNACK,达到内核tcp_synack_retries的5次重传上限后断连退出,而客户端仍保持在ESTABLISH状态,使客户端发送数据,由于服务端已CLOSE无法响应,客户端便会一直试图重传,且重传的时间间隔越来越大,但并不是超时重传的每次乘2倍的算法。
客户端重传数据的内核参数由tcp_retries2控制,默认为15,据此上述客户端并不会一直重传下去,而且在重传次数达到15次后退出,这个过程大概花费半小时的时间,碍于时间关系就不验证了。
root@razer:/mnt/hgfs/AARON# cat /proc/sys/net/ipv4/tcp_retries2
15
如果客户端一直不发送数据,TCP也有机制断开其连接,负责这个任务的是tcp的保活机制,这个机制的原理是这样的:
定义一个时间段,在这个时间段内,如果没有任何连接相关的活动,TCP 保活机制会开始作用,每隔一个时间间隔,发送一个「探测报文」,该探测报文包含的数据非常少,如果连续几个探测报文都没有得到响应,则认为当前的 TCP 连接已经死亡,系统内核将错误信息通知给上层应用程序。
在 Linux 内核可以有对应的参数可以设置保活时间、保活探测的次数、保活探测的时间间隔,以下都为默认值:
net.ipv4.tcp_keepalive_time=7200
net.ipv4.tcp_keepalive_intvl=75
net.ipv4.tcp_keepalive_probes=9
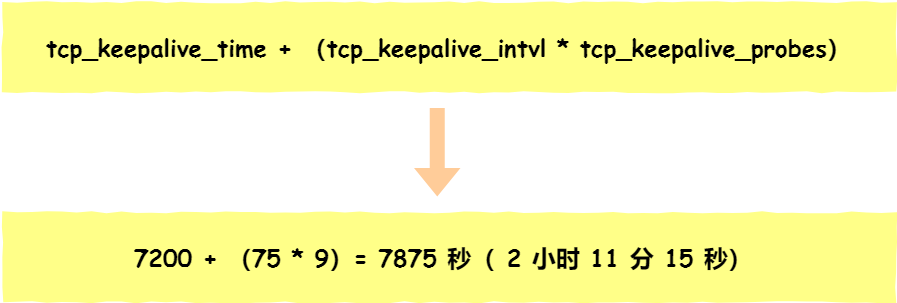
- tcp_keepalive_time=7200:表示保活时间是 7200 秒(2小时),也就 2 小时内如果没有任何连接相关的活动,则会启动保活机制
- tcp_keepalive_intvl=75:表示每次检测间隔 75 秒;
- tcp_keepalive_probes=9:表示检测 9 次无响应,认为对方是不可达的,从而中断本次的连接。
也就是说在 Linux 系统中,最少需要经过 2 小时 11 分 15 秒才可以发现一个「死亡」连接。
这个时间是有点长的,所以如果我抓包足够久,或许能抓到探测报文。
实验三的小结如下:
在建立 TCP 连接时,如果第三次握手的 ACK,服务端无法收到,则服务端就会短暂处于 SYN_RECV 状态,而客户端会处于 ESTABLISHED 状态。
由于服务端一直收不到 TCP 第三次握手的 ACK,则会一直重传 SYN、ACK 包,直到重传次数超过 tcp_synack_retries 值(默认值 5 次)后,服务端就会断开 TCP 连接。
而客户端则会有两种情况:
- 如果客户端没发送数据包,一直处于
ESTABLISHED状态,然后经过 2 小时 11 分 15 秒才可以发现一个「死亡」连接,于是客户端连接就会断开连接。(前提是客户端要打开keepalive选项,否则就会一直持续下去) - 如果客户端发送了数据包,一直没有收到服务端对该数据包的确认报文,则会一直重传该数据包,直到重传次数超过
tcp_retries2值(默认值 15 次)后,客户端就会断开 TCP 连接。
两端异常
服务端有数据传输,客户端主机拔线
这个场景下找不到能用于模拟的服务端和指令,我自己写了一个回声服务端,为了刚好使得能在服务端传输数据之前使客户端异常,我在回声服务端的write函数前加入了sleep语句,这个新的服务端称为echo_server_slow,这个实验我让服务端监听8080端口:
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<errno.h>
#include<unistd.h>
#include<arpa/inet.h>
#include<fcntl.h>
#include<sys/socket.h>
#include<sys/epoll.h>
#define MAX_CONNECTION 100
#define EPOLL_SIZE 1024
int tcp4Bind(int port){
int servfd = socket(PF_INET,SOCK_STREAM,0);
struct sockaddr_in serv_addr;
serv_addr.sin_family = AF_INET;
serv_addr.sin_addr.s_addr = INADDR_ANY;
serv_addr.sin_port = htons(port);
int optval = 1;
if(setsockopt(servfd,SOL_SOCKET,SO_REUSEADDR,&optval,sizeof(optval)) == -1){
perror("setsockopt() error");
return -1;
}
if(bind(servfd, (struct sockaddr *)&serv_addr, sizeof(serv_addr)) == -1){
perror("bind() error");
return -1;
}
if(listen(servfd,MAX_CONNECTION) == -1){
perror("listen() error");
return -1;
}
return servfd;
}
int main(){
int servfd = tcp4Bind(8080);
if(servfd == -1){
printf("tcp4bind() error\n");
return -1;
}
struct sockaddr_in clnt_addr;
socklen_t clnt_addr_len;
char rebuf[BUFSIZ];
//创建红黑树,根节点为epfd
//内核2.6.0之后 不用再实际指明监视数组的数量 参数不强制 仅给内核建议
int epfd = epoll_create(1);
//ev描述事件 events用于返回变化的fd集合
struct epoll_event ev, events[EPOLL_SIZE];
ev.data.fd = servfd;
ev.events = EPOLLIN;
epoll_ctl(epfd, EPOLL_CTL_ADD, servfd, &ev);
while(1){
printf("\nlistening......\n");
//epoll_wait会注册变化的fd集合到events并返回变化的事件数
int event_cnt = epoll_wait(epfd, events, EPOLL_SIZE, -1);
if(event_cnt == -1){
perror("error");
break;
}
else{
//和select和poll不同的是 epoll是由内核管理fd, 监测会返回一个只有变化fd的数组, 这是其优势
for(int i = 0; i < event_cnt; i++){
int sockfd = events[i].data.fd;
if(events[i].data.fd == servfd){
int sockfd = accept(servfd,(struct sockaddr *)&clnt_addr, &clnt_addr_len);
printf("new sockfd %d connected from %s:%d",sockfd, inet_ntoa(clnt_addr.sin_addr), ntohs(clnt_addr.sin_port));
//更新监控fd的数据结构
ev.data.fd = sockfd;
ev.events = EPOLLIN;
epoll_ctl(epfd,EPOLL_CTL_ADD,sockfd,&ev);
}
else{
int rlen = recv(sockfd, rebuf, sizeof(rebuf),0);
if(!strncmp(rebuf,"quit",4)){
epoll_ctl(epfd, EPOLL_CTL_DEL, sockfd, NULL);
close(sockfd);
}
else{
//设置睡眠,使得服务端发数据前有时间对客户端动手脚
sleep(5);
send(sockfd,rebuf,rlen,0);
memset(rebuf,0,sizeof(rebuf));
}
}
}
}
}
close(servfd);
close(epfd);
return 0;
}
理论上服务端在得不到回应时会重发数据包,CentOS机负责控制重发次数的内核参数tcp_retries2默认值是15,大概要半小时才会重发完15次退出连接,这个时间实在是太久了,故此我将CentOS机的这个参数改为3, 这样大概1分钟就能跑完连接:
echo 5 > /proc/sys/net/ipv4/tcp_retries2
在CentOS机部署echo_server_slow, 然后部署tcpdump(注意这次是在服务端部署了,因为之前握手丢包模拟用的是iptables收到后丢弃,tcpdump是能抓到重传的包的)
tcpdump -nn -i ens33 tcp and host 192.168.200.129 and 192.168.200.130 -w tcp_client_disconnect.pcap
用Ubuntu机telnet向服务端发数据,趁机在5秒内将Ubuntu机的连接断开,然后netstat查看指令,可看到双方当前连接仍然存在:
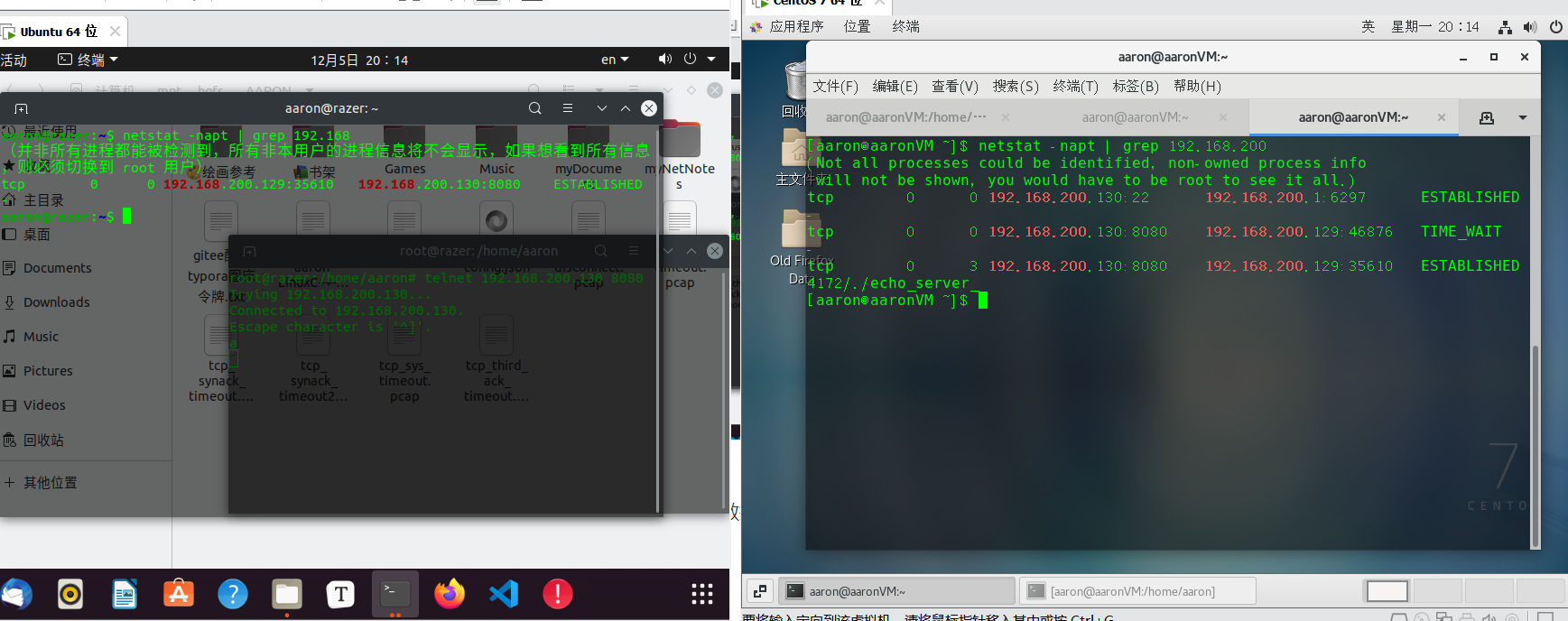
约1分钟,服务端显示连接已消失,而客户端仍保持连接, 这里也可见到重连断开的机制是由内核设定的,并不是由应用程序主动设置的:
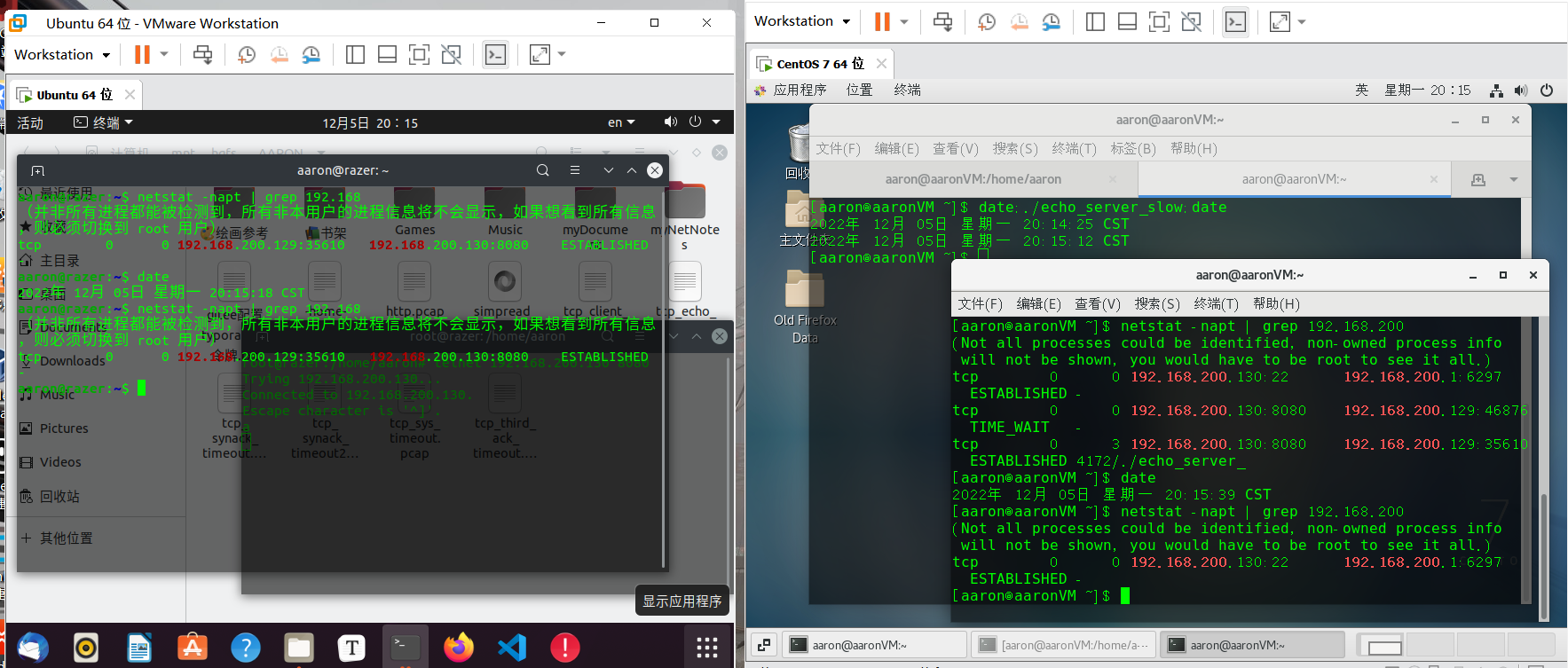
这时候恢复客户端的连接,往telnet再输入数据,就会发现telnet连接被断开了,同时客户端的连接也消失了。
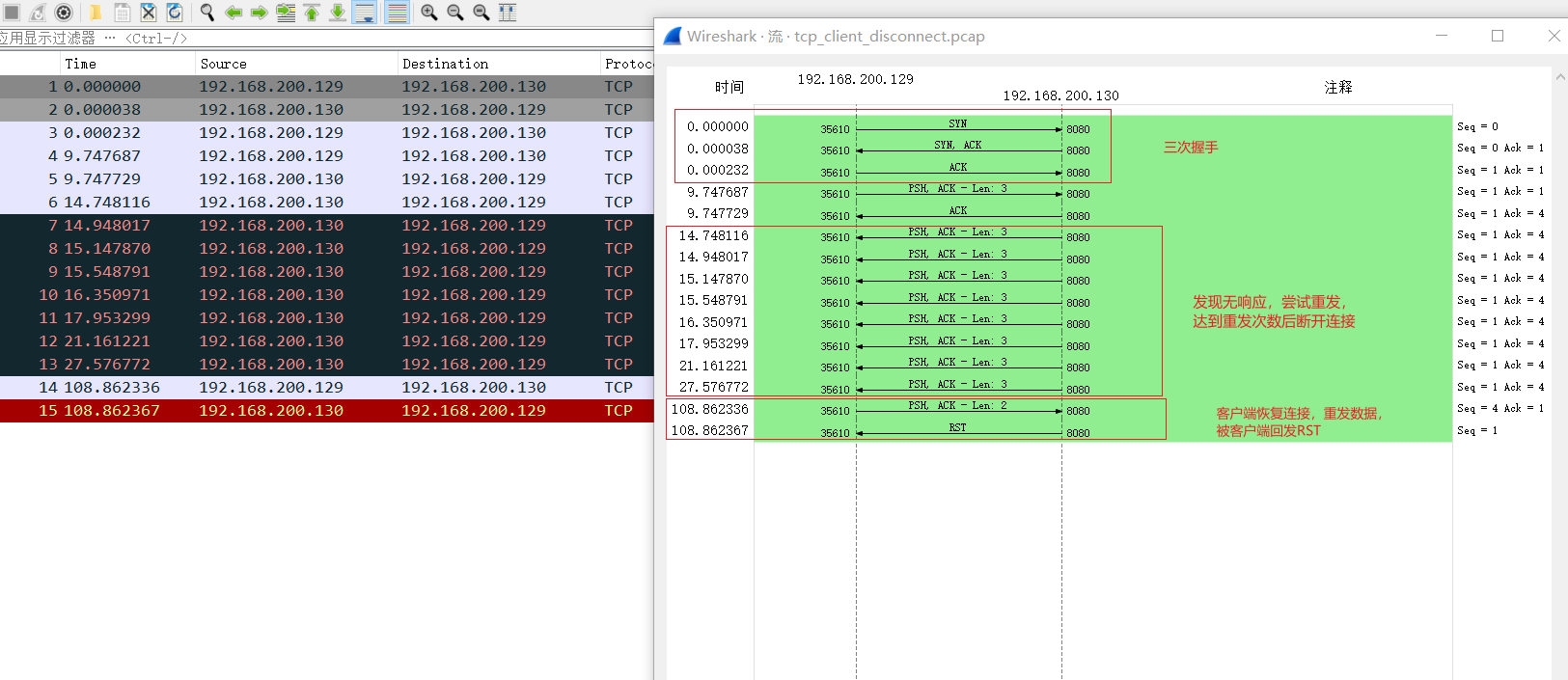
分析tcpdump的抓包结果,由抓包结果可知,如果客户端断连后服务端有数据传输,那客户端不会给服务端响应,这样服务端就会一直重发数据,直到达到最大重传次数后退出,而如果客户端在服务端退出后再进行数据传输,由于之前的连接已经CLOSE,那么服务端收到后就会回发RST报文关闭客户端连接。
服务端有数据传输,客户端主机崩溃
模拟服务端在传输数据时客户端崩溃的做法是,在服务端数据送到之前立刻将客户端挂起。
由于挂机的切换时间较长,容易出现客户端还没有恢复服务端就到达最大重发次数的情况,故这里将重发次数调长了些:
echo 7 > /proc/sys/net/ipv4/tcp_retries2
开始实验,centOS同上一个实验部署tcpdump和回声客户端,Ubuntu机用telnet客户端连接,发送数据后立刻挂起,然后恢复,会发现之前的连接并未消失,客户端能够得到重发的数据,连接保持正常。
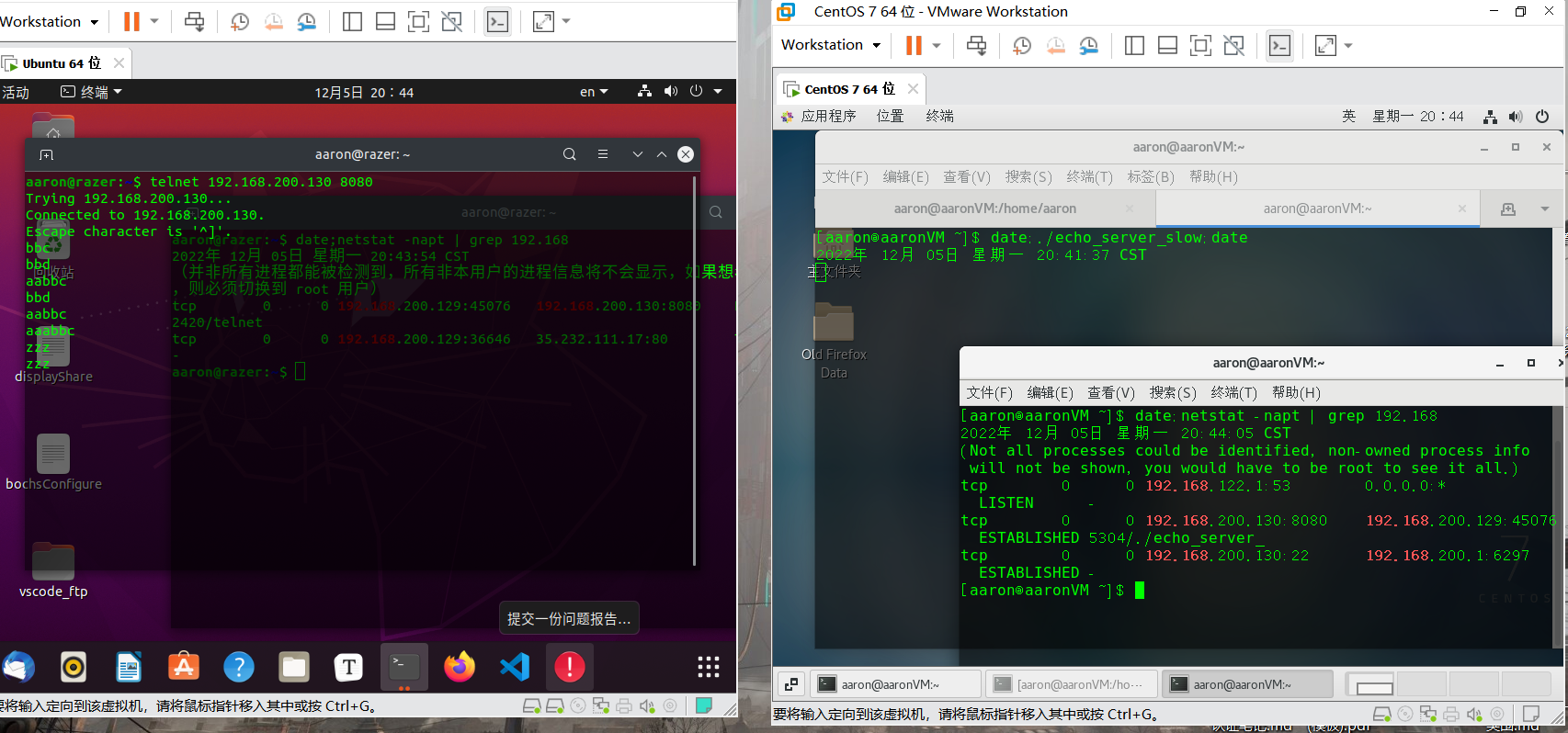
但这并不能说明主机崩溃的情况下一定就能保存连接,现在直接让ubuntu机重启,再次telnet连接服务端,查看情况,可发现之前的连接已经消失了,重启后再telnet的连接是新连接:
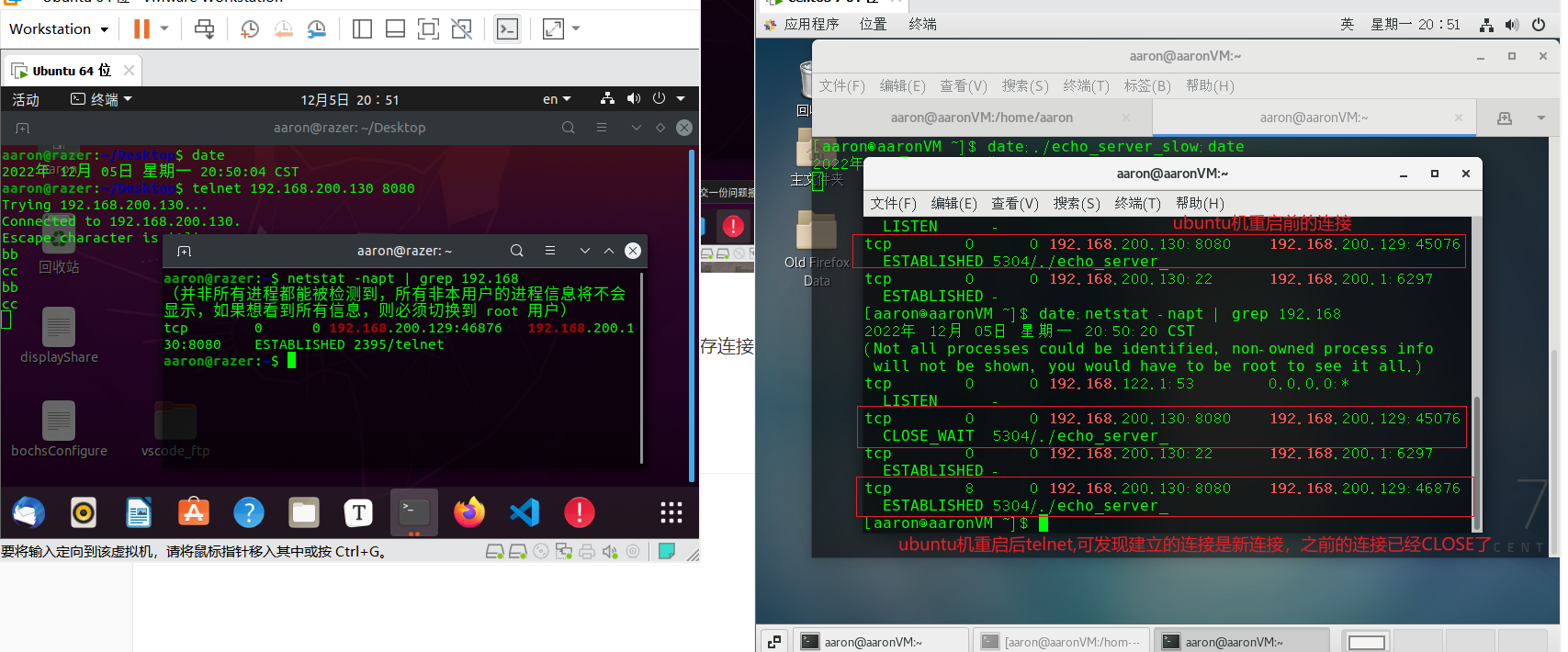
tcpdump抓包全过程如下:
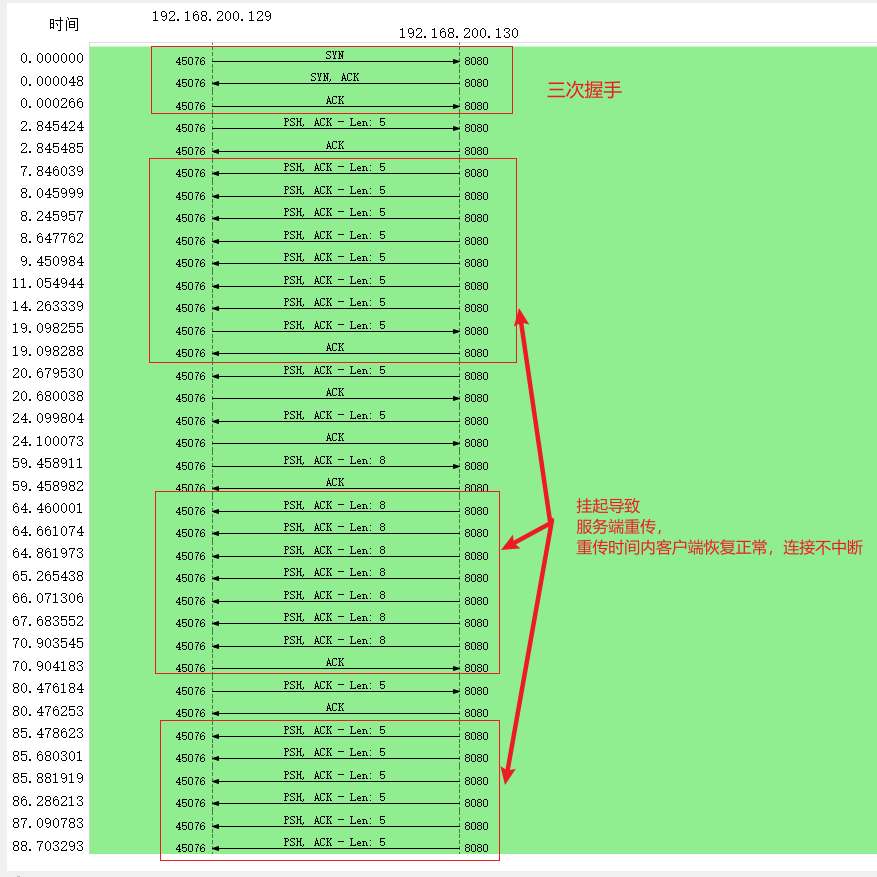

由抓包过程可见,如果连接过程中客户端发生了断电等情况导致进程崩溃,那么客户端就会向服务端发送FIN断连,这样之前的连接就不存在了,下次客户端重新连接就会采用新的四元组连接。图中可见发送FIN的四次挥手不是完整的,不知道为什么,可能是客户端发完FIN之后就重启了,收不到了。
综上,对于挂起,拔线等没有导致进程崩溃的情况,只要客户端能在服务端的重传时间内重新连上服务端,就能够保持之前的连接,否则服务端一旦达到最大重传次数就会自动断开连接,之后客户端再次若尝试连上服务端,服务端便会无情地回复RST中断连接;
对于重启(包括关机再重启),SIGINT中断,kill等导致客户端进程崩溃的情况,客户端会向服务端发送FIN报文断开连接,将先前的连接清除,下次客户端再度重新连接服务端时,将采用新的四元组连接。
至于服务端没传数据的情况则更加简单,若客户端进程拔线,则原有连接不影响,服务端将在一定时间后启动tcp保活机制检测连接是否“活着”,若此时客户端仍不活跃,服务端将会清除该连接。而客户端主机宕机,进程崩溃的情况就是直接断连了,大家可以自己去验证。
参考
小林Coding
tcpdump抓包教程:https://www.cnblogs.com/XDU-Lakers/p/13149926.htmls.com/XDU-Lakers/p/13149926.html




![[附源码]计算机毕业设计JAVA音乐交流平台](https://img-blog.csdnimg.cn/72d18f6515364fe2a6a2c2c363a4a066.png)




![[附源码]Python计算机毕业设计Django社区疫情防控信息管理系统](https://img-blog.csdnimg.cn/d706fd3de82c4b07a0c4072cc28ecf96.png)


![[附源码]计算机毕业设计软考刷题小程序Springboot程序](https://img-blog.csdnimg.cn/b4bbd936e37b48959a90cad31ceaea8e.png)