编码为什么是一个重要的话题,因为我们和计算机交互的主要方式目前还是文字字符。作为一个程序员,相信大部分都都被字符和编码的问题折磨过,从键盘输入文字字符到编辑器 中,编辑器存储字符到硬盘,再到具体一个编程语言如何表示和处理字符等,可以说字符集和 字符集的编码在计算机中无处不在,因此有必要进行一次全面的梳理。本次通过这篇文章聊聊我对于字符和字符编码的认识与理解,希望能够给你带来收获。
字符集和字符编码
字符集:一系列字符的集合,最著名的莫过于Unicode字符集,网罗了世界上绝大多数的字符,并且为每一个字符分配了一个数字进行编号,这个编号在计算机中就可以表示该字符。
字符集编码:通常简称编码,由于字符需要在计算机中存储和传输,因此需要规定一个字符使用几个字节以及怎样的值存储在硬盘上或者内存中。Unicode 字符集对应的编码方式包括 UTF-8、UTF-16、UTF-32 等多种。
除了 Unicode,我们经常接触到的字符集还包括 ASCII、GB2312 等字符集。像 GB2312 只包含常见的中文,数字等字符的集合,因此在一些采用GB2312 字符集可能无法显示一些生僻的汉字,在后续 GBK收录了这些生僻字。当然像日韩、欧洲等其他国家也有自己特定的字符集。但是它们都有一个共同的特点,就是均在 ASCII 字符集上扩展而来,对于 ASCII 字符集是兼容的,下图1说明他们之间的关系:
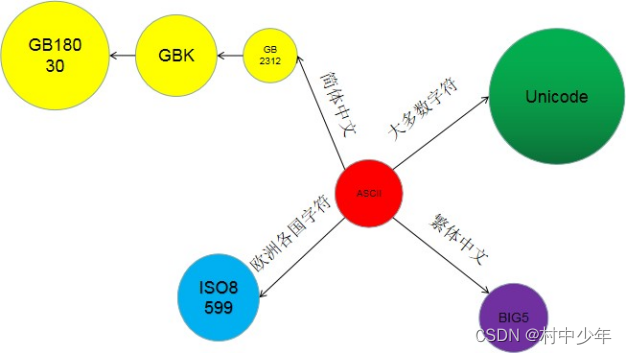
图1
看到这里有人可能会提出疑问ASCII明明是一种编码⽅式,为什么这⾥有说成是字符集呢。原因在于在计算机发展早期,字符集和字符集编码并没有严格的区分,ASCII兼具了字符集编号和字符编码的功能,因此ASCII既可以说成是字符集,也可以认为是字符集编码。最初 ASCII 字符集的范围是 0-127,本身字符编号可以直接使用一个字节来进行存储,字符编号和其字符编码可以一一对应上。同样的道理 GB2312 的字符集范围是 0~65535,使用两个字节进行存储,也有一一对应的关系。没有必要单独将字符集和字符集编码进⾏区分,其编码形式唯一。正因为历史上存在诸如 ASCII、GB2312等没有将字符集和字符编码有效的区分的编码模型, 以至于 Unicode 出现后,很多人称 Unicode 为编码,这其实并不是特别准确,准确的说法是unicode字符集。
Unicode定义了世界上绝大多数的字符,并给每个字符进行编号,我们通过这个编号就可以定位到具体的字符。由于 Unicode 字符集的庞大,目前拥有数十万的字符,编号从 0-10W+,导致使用多少字节对于字符存储不在像 ASCII 以及 GB2312 那样可以简单设计。英文字符编号在0~127 之内的可以使用一个字节存储;汉字的编号,比如一开始的村中少年,分别是 6751(26449)、4E2D(20013)、5C11(23569)、5E74(24180), 需要至少 2 个字节才能容纳的下。 出于存储效率的考量,设计者设计了 UTF-8 变长编码方式;出于设计简单的考量,有 UTF-32 等编码⽅式。可以看到 Unicode 字符集本身对应的编码方式众多,字符编号和不同编码方式得到的值是不同的。因此在 Unicode 中字符集和字符编码的概念是要加以区分的。通常称 Unicode 为字符集或者 Unicode 编号,UTF-8 等是该字符集对应的编码方式。
UTF-8 编码
对于不是特别了解 UTF-8 编码的同学,我这里简单的说一下 UTF-8 编码规则,即 UTF-8 和 Unicode 之间的转换关系,不然总有些又抱琵琶半遮面的感觉。同时 UTF-8 作为目前应用最为广泛的编码方式,是值得学习一下的。使用一张图2说明如下:

图2
左侧对应的是 Unicode 编号的取值,右侧对应的是 UTF-8 编码之后的值。黑色部分固定不变,红色部分是需要填充的具体 Unicode 的编号对应的值。总的原则就是根据 Unicode 编号的范围,确定对应的 UTF-8 编码长度以及对应的格式。将 Unicode 编号转换成为二进制之后,依次的将该二进制从右向左的值对应填入上述编码格式中红色部分的从右向左的位置上, 剩余的位置补齐 0 即可。
举两个例子来说明上表:
字符 a 对应的 Unicode 值为 0x0061,其二进制为 1100001,对应上表中的第一行的存储方式,需要一个字节存储,因此从右向左的依次放入对应的位置得到存储内容为01100001,即 0x61。
汉字 中 对应的 Unicode 值为 0x4E2D,其二进制为 100111000101101,其范围对应上表中的第三行的存储方式,需要三个字节存储,因此从后向前的依次放入对应的位置得 到存储内容为 111001001011100010101101,即 0xE4B8AD。
当然对于 村中少年 这几个字符,可以拿来练练手,看看和上图中的 Nodepad++ 存储的结果是否一致。另外我还发现站长之家给出工具,将中文转换成为UTF-8的结果并不是真正意义上的 UTF-8 编码后的值。
关于显示和存储
显而易见的是,如果你的脑袋中能够装下整个 GBK 和 Unicode 的字符编号,其实输入法是完全可以被取代的,按照前面的操作即可。遗憾的是,可能只有极少数的人能够做到这一点。可以看到输入法是针对字符编号不容易记忆,而拼音较为容易记忆的情况。输入法作为一个中间层做了一次转换,将拼音转换成为具体的编号。当然如果直接显示编号是不够友好的,需要显示字符编号对应的图形,往往是字符的点阵图或者矢量图,也就是像Word 软件中的字体。当需要显示某个字符的时候,依据编号查找对应的点阵图进行绘制即可。当我们向英文 Linux终端中请求输入Unicode 字符 26449 的时候,系统就去查找 26449 对应的字符是村,于是就按照村这个字符点阵信息在终端中进行绘制。值得一提的是,在计算机的发展中,很多的工作都是为了人机交互服务的。因此产生了很多类似的中间层,例如DNS,由于IP 地址难以记忆,域名很容易记忆,使用 DNS作为中间层转换,这一点相信在日常的工作和学习过程中,大家深有体会。
例如英文 Linux 的 terminal 中输入村这个字符,按下回车的时候,可能会出现了如下的提示:
-bash: $’\346\235\221’:command not found
原因解释如下:
1,\346\235\221 是 8 进制的表示⽅式,转换为 16 进制为 E69D91,该值就是村这个字符的UTF-8 编码对应的值,注意村在 Unicode 中的编号是 0x6751,这里就体现了编码和字符编号的不同。
2,当通过输入法或者 Alt 加上对应的 Unicode 编号的时候,一开始在终端上显示的是对应的字符(也就是对应的编号的点阵信息),如村等。但是当按下 Enter的时候,其实是在像系统发送命令(村这个命令)。当涉及到传输以及存储的时候,就需要对字符进行编码。这个时候终端就会将该字符转换为编码后的值进行存储和传输。由于我的终端默认的是 UTF-8 编码⽅式,因此就会将村(0x6751)编码成为 E69D91,也就是 \346\235\221。由于系统中没有村这个指令,因此就会有上述的错误提示。
上述例子说明了一个问题,就是计算机的存储和显示是分离的。在计算机显示的时候显示的是一个具体的字符,也可以理解为显示的是字符的编号。但是存储的时候我可以更改编码方式, 按照需要进行存储。
上例中终端采用了 UTF-8 编码方式,同样的在 Nodepad++ 等软件中 我可以按照 UTF-8 方式存储村中少年几个字,也可以按照 GBK 方式存储,如下是使用 HxD 查看两种⽅式存储的 16 进制结果,如下:
GBK
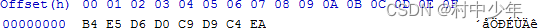
UTF-8

可以看到尽管存储的值不同,但是在显示的时候看到的都是 村中少年 这几个字符。因为当Nodepad++ 在打开文件显示,其实是从编码值到字符编号的逆过程(解码)。无论该字符是以何种形式编码,在显示的时候其表示的含义是字符本身,不会因为编码值的改变改变。因此 在显示阶段要表现的是字符本身的内容,因此需要几个固定的值来表示,即所在字符集的编号。但是当一个字符存储到硬盘上或者存储在内存中或者用于传输的时候,必须要考虑使用 个字节对该字符进行存储,这个时候字符需要考虑占用空间,有长度的限制,即编码的范畴。 不同的编码对于同以个字符存储长度可能不同,例如在 UTF-8 中文通常使用三个字符存储,而GB2312 往往是两个字节。
因此可以得出如下的结论:
算机操作系统显示阶段,使用了字符所在字符集编号唯一的表示这个字符。在存储和显示阶段,根据不同的编码设置,将字符编号转换成为编码后的值进行传输和存储。
一个小游戏
曾经有这样一个小游戏:不使输入法法,在 Word 中打出自己的中文名字。
如果你不知道如何实现,恭喜你,看完本文之后又 get 到一个新技能;如果你曾经实现过,那么背后的原理也许你会很感兴趣。
以我 CSDN 博客的名 村中少年 为例进行说明。
1,村中少年 四个字符对应的 GBK、 GB2312 字符集中的编号为 B4E5(46309)、 D6D0
(54992)、C9D9(51673)、C4EA(50410),括号内的是十进制,括号外的是十六进制。对于常见的中文字符来说 GBK 和 GB2312 的编号是一致的,可以理解 GB2312 是 GBK 的一个子集。
2,这四个字符对应 Unicode 字符集中的编号分别为 6751(26449)、 4E2D(20013)、5C11(23569)、5E74(24180)。
3,在中文Windows 操作系统中,在 DOS 窗口中输入 chcp,如下图3:
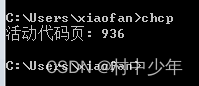
图3
其中代码页就是字符集的别名, 而936 指的就是 GBK 字符集编码, 可以看到我的中文Windows 操作系统中采用了 GBK 字符集,当然也可以说是 GBK 编码,后面我们会简单聊聊区别
4,在 Windows 中文操作系统中,按住 Alt 键不放,分别在数字小键盘上输入步骤 1 中字符集对应的十进制,依次为 46309、54992、51673、50410。就可以在 DOS 窗口,Word 文档, Nodpad++ 等终端或者编辑器中打印出村中少年几个汉字。当然这里面有个限制需要注意,必须使用数字小键盘进行数字的输入,因此对于笔记本来说就无法使用这种方式来操作了。
5,如果你的系统使用的并不是 GBK 字符集,例如 Unicode 字符集。比如英文的 Linux 系统中通常采用的是 Unicode 字符集,这个时候的组合就是 Alt 键加上步骤 2 对应 Unicode 字符集中的编号了,依次为 26449、20013、23569、24180。同样可以打印出村中少年。感兴趣的童鞋可以自己试一试。
本文为CSDN村中少年原创文章,未经允许不得转载,博主链接这里。