本篇作为Flink系列的第二篇,第一篇是环境准备,需要的同学可以看:https://blog.csdn.net/lly576403061/article/details/130358449?spm=1001.2014.3001.5501。希望可以通过系统的学习巩固该方面的知识,丰富自己的技能树。废话不多说咱们开始吧。
1、传统数据处理架构
在我们的日常生活中数据和数据处理无处不在,随着数据的采集和使用量的不断增加,设计并构建了各种架构来管理数据,传统的数据处理架构分为两类:事务性处理架构和分析型处理架构。
1.1、事务型处理架构
咱们在平时开发的各类应用都属于事务性处理架构。例如:客户管理系统(CRM)、任务系统(ZEUS)、订单系统(SHUTTLE-ORDER)以及所有的基于Web的应用等。
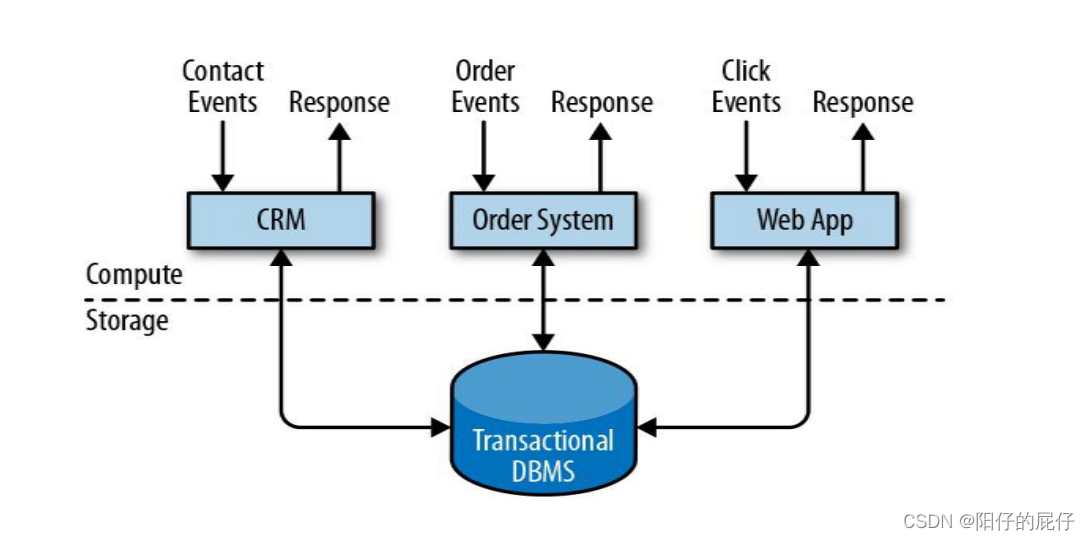 上图就是一个将数据存储在远程关系型数据库内的传统事务型应用的设计。传统的事务型机构有以几个特点。
上图就是一个将数据存储在远程关系型数据库内的传统事务型应用的设计。传统的事务型机构有以几个特点。
- 连接的实际用户或者外部的服务。
- 持续接受来自外部(用户或者系统)的请求并实时处理返回数据,期间处理每个请求的时候基本上都会通过执行远程数据库的事务来进行CRUD。
- 很多时候都是共享同一个DB和同一个table。
以上系统设计有个弊端就是在需要更新或者扩缩容是会导致一些问题,所以就出现微服务,通过将复杂庞大紧耦合的服务进行优化,分化出很多独立、微型、独立的应用,各个服务之间通过标准化接口进行通行。
1.2、分析型处理架构
存储于不同数据库的数据为可以为我们的业务分析做好数据准备,但是由于事务型的数据库都是相互隔离的,我们不会在事务型的数据库上进行数据查询,所以想要将这些数据进行统一分析要做的就是将不同的DB的数据转换为某种通用的形式。这就出现了分析型数据处理架构(数据仓库)。
为了将分散的数据填充到数据仓库我们要将事务型数据库中的数据copy过去,这个过程分为三步:提取-转换-加载(ETL)。整个过程比较复杂和性能挑战,为了保证数据同步需要进行周期型的同步数据。
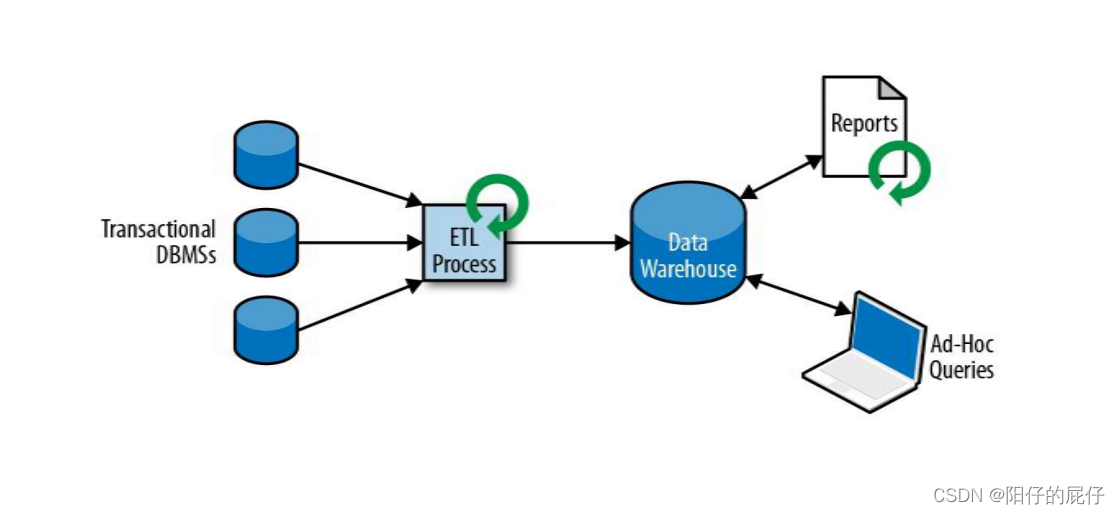
上图就是一个分析型数据仓库架构,分析型数据仓库可以提供两大类的查询。
- 定期类的报告查询:将业务数据进行周期型的分析计算,统计重要指标,为企业健康状态提供评估依据。(收入、产出、用户增长、订单量等等)
- 即溪查询:提供较为实时的数据基础辅助关键性的商业决策。(广告投入、获客、转换等等)目前ApacheHaDoop生态组建已经为我们提供了强大而且丰富的存储查询引擎,我们的海量的日志文件、社交媒体、点击等等数据不再使用传统的关系型数据库存储而是是用HaDoop分布式文件系统(HDFS)、S3、Apache Hbase等大容量存储系统中,并且他们还提供了丰富的基于HaDoop的SQL引擎(Apache Hive、Apache Dirll)进行查询和处理。
2、状态化流处理架构
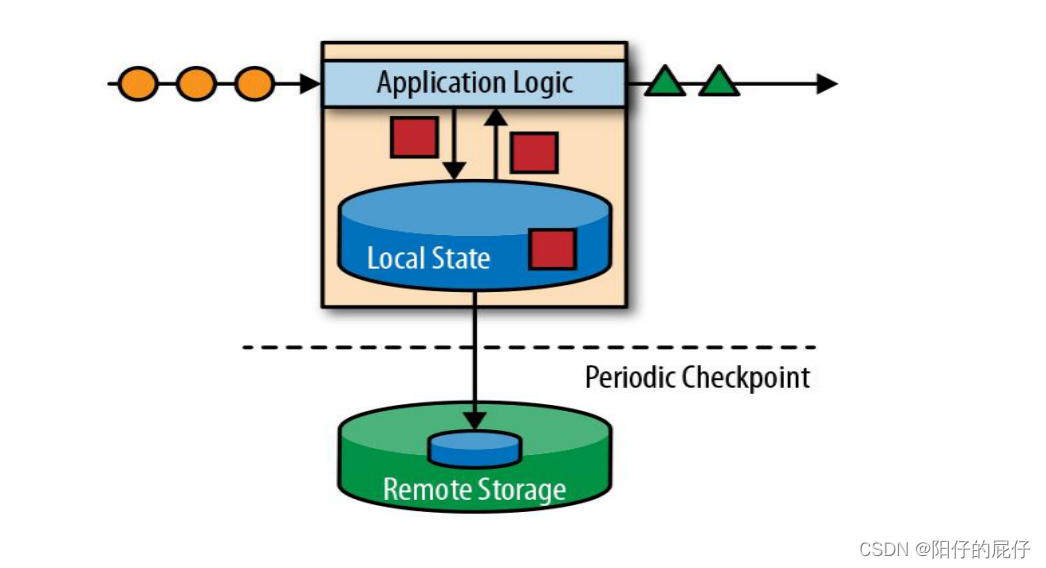
我们都知道现实生活中的数据都是不间断的产生的,在处理事件流的过程中我们要支持多条记录的转换并且能够存储和访问中间结果,并且在进行数据分析的时候有时候业务需要的是比较实事的分析结果,在海量的事件处理中,传统的事物型数据架构和ETL架构就难以支撑。基于以上的各方面就设计出现了有状态的流处理架构。有状态的流处理架构(Flink)可以接收大量的请求并且天生支持并行计算,具有高吞吐,低延迟特性,并且将计算的中间结果存储到本地或者存储到远程存储,Flink还会定期进行检查点(CheckPoint)写入到持久化存储,在进行故障恢复的时候根据检查点进行恢复。
3、Flink的主要特点
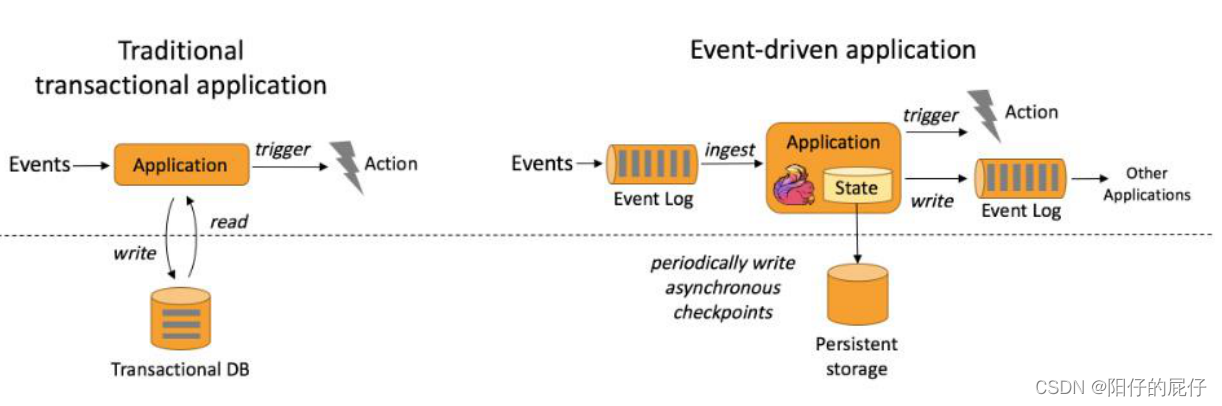
3.1、事件驱动
事件驱动其实是借鉴于传统的事务型架构,接收事件请求(可以是实时触发的操作或者事件日志Kafka、redis等等存储介质),并且存储中间状态到本地或者远程存储,最后将计算结果返回可以出发操作或者写入到相关的存储介质中(Mysql、Redis、Kafka等等)供消费方使用。
3.2、基于流的世界观
在Flink的世界中都是流,分为有界流和无界流。无界流:定义了开始,但是没有定义终点,所以没有办法获得所有的事件,这就要求无界流需要实时进行处理,通常情况下无界流需要根据某种特定的顺序处理以便获得准确的结果(比如事件时间)。无界流就是定义了开始和终点的流,因为能够获得所有的事件所以不需要定义特定的顺序。
3.3、分层API
Flink提供了三层API。每个API在简洁性和表达性之间提供不同的权衡。越顶层越抽象,表达的含义越简洁,使用越方便。越底层越具体,表达能力越丰富,使用越灵活。
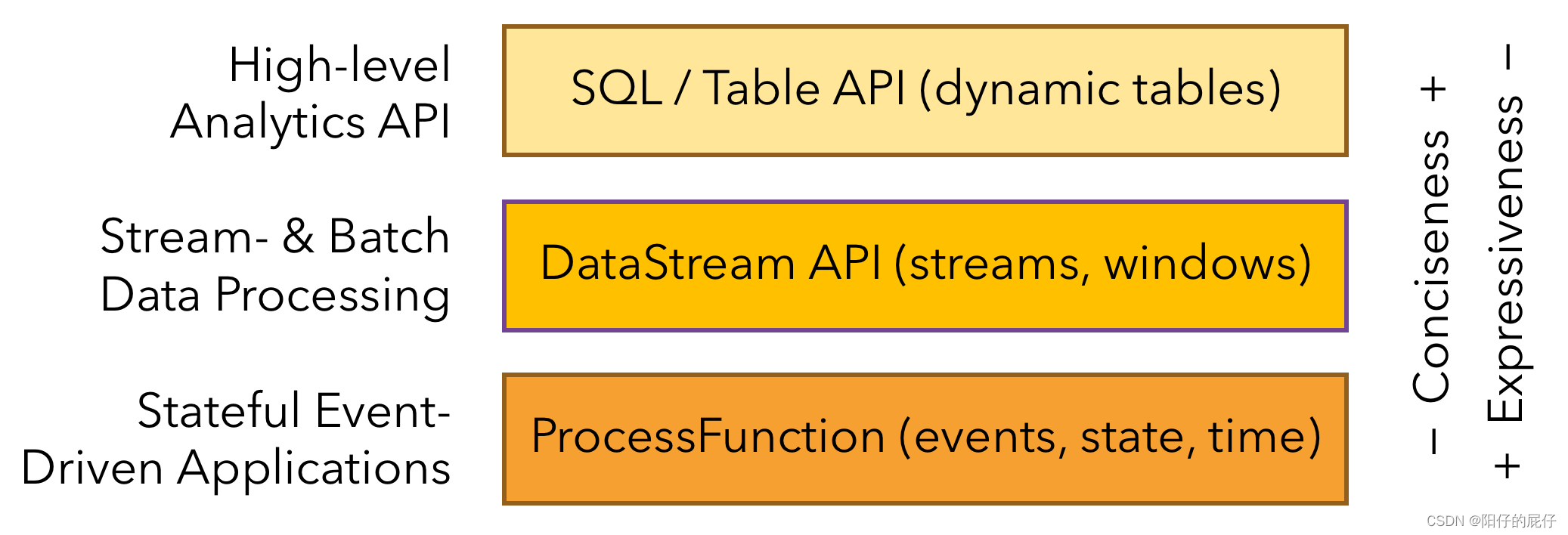
这里我们采用的是DataStream API进行系统的学习,下面是一个简介的Flink的执行框架
1、定义了Flink的执行环境。
2、从数据源获取数据。
3、进行转换计算。
4、输出到控制台。
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class SocketTextStreamWordCount {
public static void main(String[] args) throws Exception {
//参数检查
if (args.length != 2) {
System.err.println("USAGE:\nSocketTextStreamWordCount <hostname> <port>");
return;
}
String hostname = args[0];
Integer port = Integer.parseInt(args[1]);
// set up the streaming execution environment
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//获取数据
DataStreamSource<String> stream = env.socketTextStream(hostname, port);
//计数
SingleOutputStreamOperator<Tuple2<String, Integer>> sum = stream.flatMap(new LineSplitter())
.keyBy(0)
.sum(1);
sum.print();
env.execute("Java WordCount from SocketTextStream Example");
}
public static final class LineSplitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) {
String[] tokens = s.toLowerCase().split("\\W+");
for (String token : tokens) {
if (token.length() > 0) {
collector.collect(new Tuple2<String, Integer>(token, 1));
}
}
}
}
}
3.4、时间语义
Flink的支持以下三种时间语义,默认情况下使用的处理时间。
@PublicEvolving
public enum TimeCharacteristic {
ProcessingTime,
IngestionTime,
EventTime
}
- 事件时间:根据事件的时间戳处理流数据,事件时间配合水位线能够针对无序的事件提供一致、精确的计算结果。
- 处理时间:处理时间是具体的算子接收到事件的时间,使用处理时间的应用程序一定是要求延迟比较低的数据流。
- 摄取时间:摄入时间是时间进入到Flink 的时间,一般情况下不会使用该时间进行计算。
3.5、精确一次处理
exactly-once精确一次的状态保障:Flink的检查点和恢复算法可确保发生故障时应用程序状态的一致性。
因此,可以透明地处理故障,并且不会影响应用程序的正确性。
3.6、众多存储系统连接
Flink可以连接众多的存储介质。常见的Source和Sink包括:Apache Kafka 、Mysql、Redis、ES 、S3、HDFS等等。
3.7、其他特点
1、支持高可用配置:K8s、Yarn等等集群部署。
2、低延迟,每秒可处理百万级别的事件,毫秒级的延迟。
3、同事也支持批处理,具有成熟的API( DataSet API)。
4、支持窗口操作,为无限的数据流处理提供了成熟的计算机制。
总结
Apache Flink 是一个分布式流处理引擎,它提供了直观且极富表达力的 API 来实现有状态的流处理应用,并且支持在容错的前提下高效、大规模地运行此类应用。本篇通过Flink状态化流处理的各种概念的介绍,大家从整体上了解了相关概念和特点,下一篇咱们进行实践,从实际操作来看看Flink的运行机制,敬请期待!