作者:艾宝乐
导读
近期阿里云机器学习平台 PAI 团队和达摩院 GraphScope 团队联合推出了面向 PyTorch 的 GPU 加速分布式 GNN 框架 GraphLearn-for-PyTorch(GLT) 。GLT 利用 GPU 的强大并行计算性能来加速图采样,并利用 UVA 来减少顶点和边特征的转换和拷贝。对于大规模图,GLT 使用了生产者-消费者的架构,通过异步并发的分布式采样和特征查找以及热点缓存功能支持在多个 GPU 或多个机器上进行高效的分布式训练。接口上,GLT 保持了 PyTorch的风格,并且和 PyG 兼容,只需少量代码修改就可以加速 PyG 的单机训练程序,或者将 PyG 单机模型改成分布式训练。此外,GLT 还提供了灵活的分布式训练部署以满足不同的需求。
开源地址:https://github.com/alibaba/graphlearn-for-pytorch
文档地址:https://graphlearn-torch.readthedocs.io/en/latest/index.html
背景介绍
图神经网络作为一种图数据上表示学习的方法已经被广泛应用在图相关的各个领域,在电商推荐、安全风控、生物分子等领域取得了实际落地。图神经网络由于其独特的数据处理逻辑和神经网络计算逻辑,需要有专门的学习框架来支持训练。PAI团队之前开源了大规模工业级分布式图学习框架 GraphLearn(https://github.com/alibaba/graph-learn)。GraphLearn 以 TensorFlow 1.x 系列为主,采用 ps 架构的异步训练模式,支持十亿节点,百亿边规模的大规模异构图分布式训练,应用于阿里内外部若干业务场景。随着PyTorch 的流行,其更加灵活的贴近 Python 的接口,简单易调试等特性使得算法开发者更倾向于使用 PyTorch 开发模型。DGL 和 PyG等基于PyTorch的开源GNN框架以单机为主,无法支持大规模图的分布式训练。
此外,由于 GPU 并行计算的优势,图神经网络使用 GPU 训练比 CPU 训练有数倍的提升。然而常见的图神经网络框架将图拓扑数据和特征存在内存里,使用CPU进行采样和特征查找并将数据拷贝到GPU进行神经网络训练,这个过程中图采样和特征查找部分很容易成为整体训练的瓶颈。下面我们以大规模图上典型的训练流程为例对训练过程的性能瓶颈进行分析说明。
一个典型的GNN训练流程[1] 包括:
- 子图拓扑采样,采样多跳邻居并组成子图;
- 查询子图里节点或者边的特征;
- 将子图格式转换成神经网络训练需要的格式并且拷贝到GPU显存中;
- 对原始特征进行处理,比如离散特征进行embedding lookup;
- 邻居聚合;
- 节点更新。
其中,3和4为可选步骤。常见的 GNN 模型神经网络参数相对来说比较小,因此计算量也比较小,瓶颈通常在1-4步,具体来说主要是I/O操作,包括通信,数据拷贝和格式转换。这导致即使使用GPU进行训练,GPU的资源利用率也很低,整体吞吐以及扩展性很难提高。
综上所述,我们需要一个高效的基于PyTorch 的分布式 GNN 训练框架,能够充分利用 GPU 等硬件资源,能够基于图的数据分布性质,结合不同算法模型和并行策略做相应优化,减少通信和数据转换耗时,提升整体吞吐。
关键设计
设计初期,我们和 Quiver[2] 团队合作针对 GPU 采样的可行性进行了初步探索,发现 GPU 采样相比 CPU 能够带来数量级的提升。此外,为了减少特征在 CPU 内存和 GPU 显存之间的拷贝开销,特征可以直接存储在 GPU 显存里。然而对于规模比较大的数据来说,显存无法存储所有特征数据,因此我们用 UVA 技术来进行特征的存储,相比直接内存存储也有数量级的性能提升。工业界的图规模很容易突破单机的极限,因此我们进一步设计了分布式训练框架。具体来说,我们使用生产者-消费者范式来处理分布式图采样和特征查找以及模型训练的关系,将图采样、特征查找与训练进行解耦,使用多进程并行和协程异步并发来加速采样和特征查找,并使用预取和热点缓存的方式进一步减少训练端的等待,提升端到端吞吐。考虑到用户迁移成本和易用性,在接口上我们保持了和 PyG 的兼容,只需少量改动 PyG 代码就可以加速 PyG 的训练,或者将其迁移到 GLT 的分布式训练上。以下为我们具体阐述几个关键的设计点。
GPU采样
GLT 将图拓扑使用 CSR 格式存储在 GPU 显存或者 pin memory里,实现了 CUDA 采样算子来进行 GPU 并行采样。使用 CSR 存储可以很容易得到每个节点的邻居,并且独立对每个节点进行采样,因此可以方便地利用 GPU 多线程进行并行采样。我们使用了蓄水池算法来进行无放回随机采样。在batch size大的情况下,GPU 比 CPU 采样能有数量级的提升。
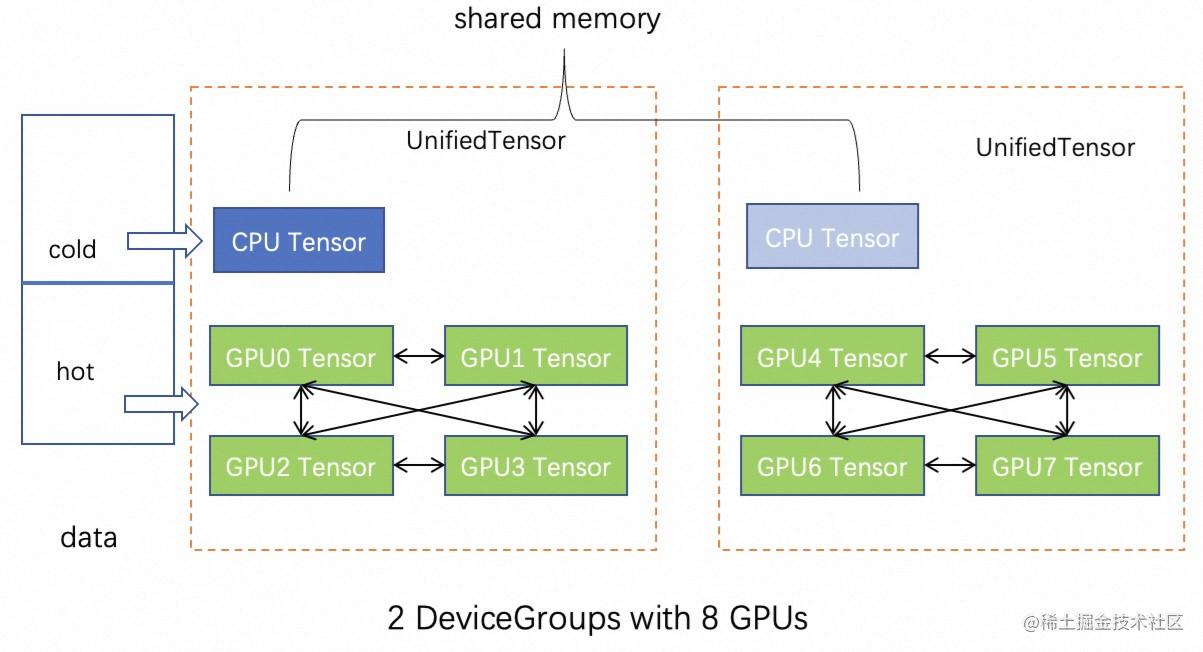
UnifiedTensor
为了消除CPU 内存到 GPU 显存的拷贝开销,一个比较直观的方法是将特征存放在 GPU 显存里,然而由于单卡的显存有限,在特征数据比较大的情况下也很难完全把特征存到显存里。因此,在GLT中我们利用图自身的特性如power law分布和采样访问特性如有些度比较高的节点被访问的概率高,将部分热点特征存放在 GPU 显存里,其他特征存在内存,同时需要利用 UVA 让 GPU 访问内存里的特征。GLT 设计了 UnifiedTensor 将 CUDA Tensor 和 CPU Tensor 统一管理起来,以提供简洁高效的数据访问。进一步,如果 GPU 之间可以直接进行 peer2peer 访问(具有NVLink),这些 GPU 的显存也可以被统一管理,从而扩大特征在显存的存储。GLT 使用UnifiedTensor 将这些不同硬件设备上的存储统一管理起来,提供直接访问 CUDA Tensor,通过 NVLink 访问其他 GPU 上的 CUDA Tensor,并通过 UVA 进行 ZERO-COPY 访问 CPU Tensor的能力,上层查找元素接口就像普通 Tensor 一样,底层会自动去对应的设备上进行访存操作。
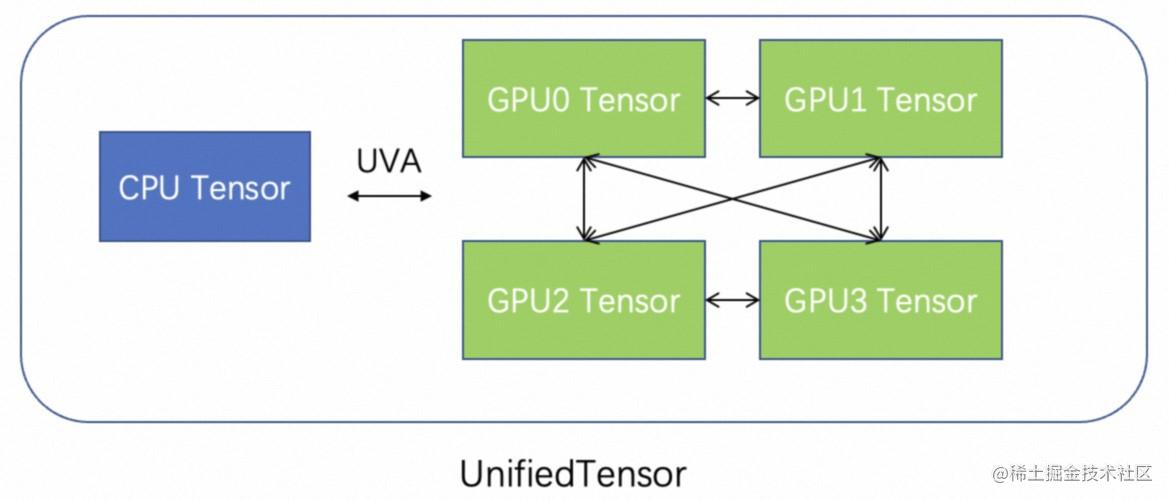
Feature
Feature 由 UnifiedTensor 构成,具有硬件拓扑感知功能。具体来说,首先,按照用户指定 CPU/GPU 内存大小,对特征进行划分,分为 GPU(hot) 部分和 CPU(cold) 部分。其次,对 GPU 部分,根据用户指定的 replica 策略,进行 replica,包括每个卡 replica 和每个 NVLink 连接的 GPU group 之间的 replica。GPU group replica 的方式,相比卡间 replica, 可以有更多的 hot data 存在 GPU 上,因为 GPU group 里 GPU 之间都是可以 p2p 访问的。实现上GLT抽象出 DeviceGroup 来统一表示卡间 replica 和组间 replica。一个 DeviceGroup 表示一组 NVLink 连接的 GPUs。假设8卡没有 NVLink,那么会对应8个 DeviceGroup,如果 GPU 0-3 两两 NVLink 连接,GPU 4-7 两两 NVLink 连接,那么 GPU 0-3 为一组 DeviceGroup, GPU 4-7 为一组 DeviceGroup。实际测试中,使用UnifiedTensor 的Feature性能比 CPU Tensor的查找(包括拷贝到GPU) 快1个数量级,而且可以通过控制 GPU 存储部分的比例来灵活达到速度和显存占用的平衡。
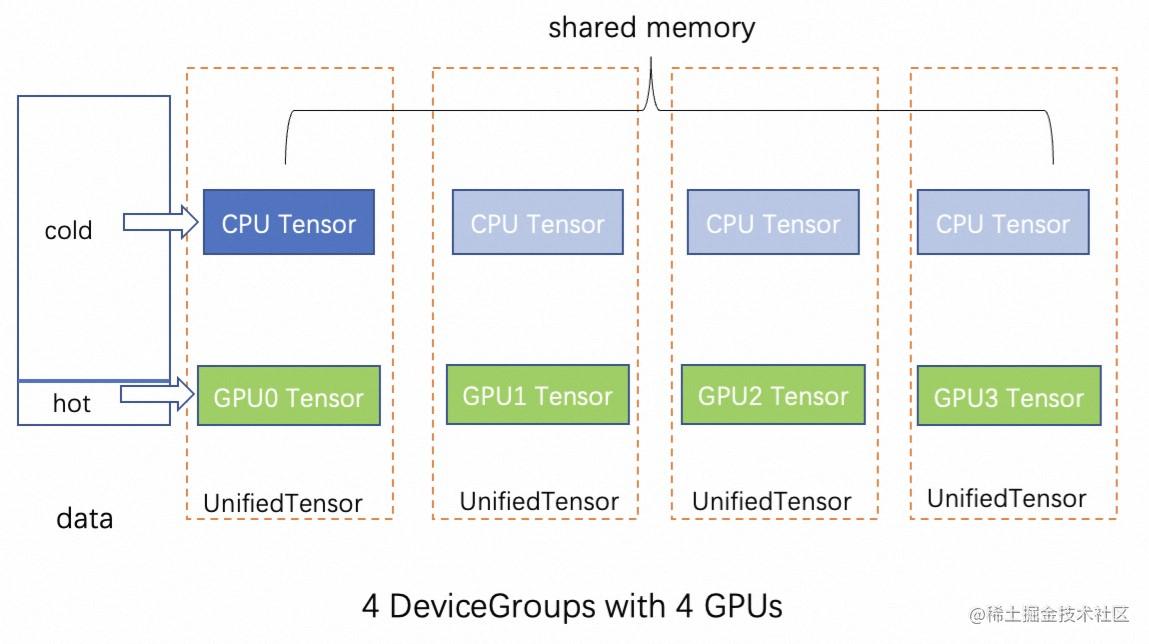
分布式设计
GLT分布式GNN训练主要分成:分布式采样,特征查找, 模型训练3部分。一次采样的结果一般比较小(最大为十几MB),特征查找的结果比较大(百MB),训练时使用特征查找的结果进行神经网络计算。对特征查找来说需要考虑减少和训练任务之间的数据转换和拷贝。采样和训练之间是典型的生产者和消费者关系,因此可以分成不同任务,通过缓冲区连接,平衡生产者和消费者的处理能力,起到一个数据缓存的作用,同时也达到了一个解耦的作用。基于生产者-消费者方式,GLT的分布式训练有两种基本类型的进程:采样进程和训练进程。
采样进程:负责分布式邻居采样和特征收集。采样结果将被发送到采样消息通道,该通道将进一步用于训练任务。
训练进程:对应于PyTorch DDP的分布式训练进程,通常,每个训练进程将占用一个GPU进行训练。
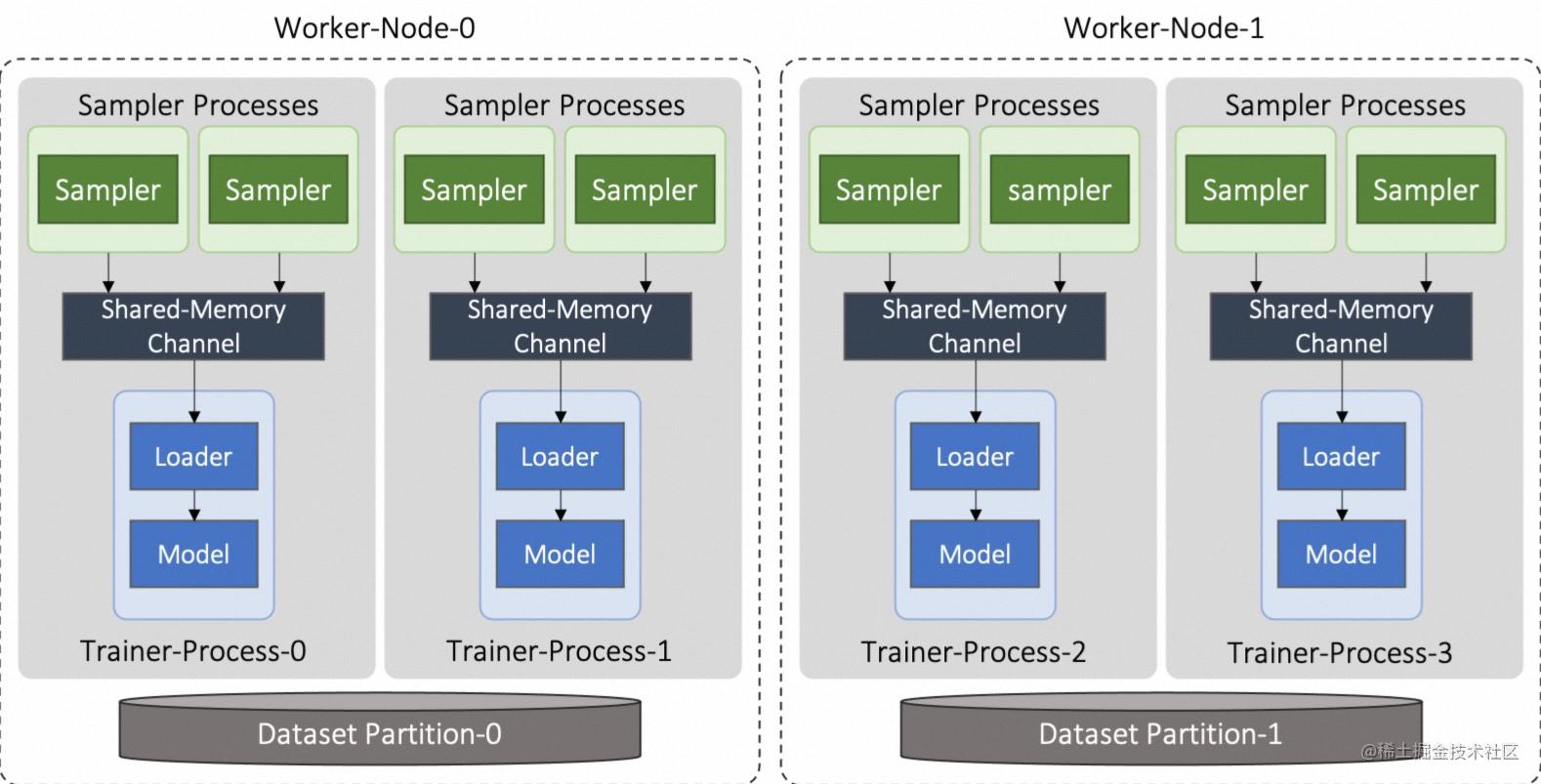
这些进程可以灵活地分布在不同的机器上,为了更好地管理分布式进程部署,GLT的分布式训练提供了两种参考部署模式:Worker 模式和 Server-Client 模式。
Worker模式里,数据切分后,每个机器持有一个分片,采样进程和训练进程一起部署在这些机器上。每个训练进程可以spawn出多个采样子进程,采样进程通过一个共享内存的消息通道将采样结果传递给训练进程。对于采样进程来说,可以使用多进程进行采样,并且每个分布式采样算子都使用Python协程来并发执行,将结果放到消息通道里。为了减少消息通道到训练进程 GPU 的拷贝耗时,消息通道也可以放到pin memory上。
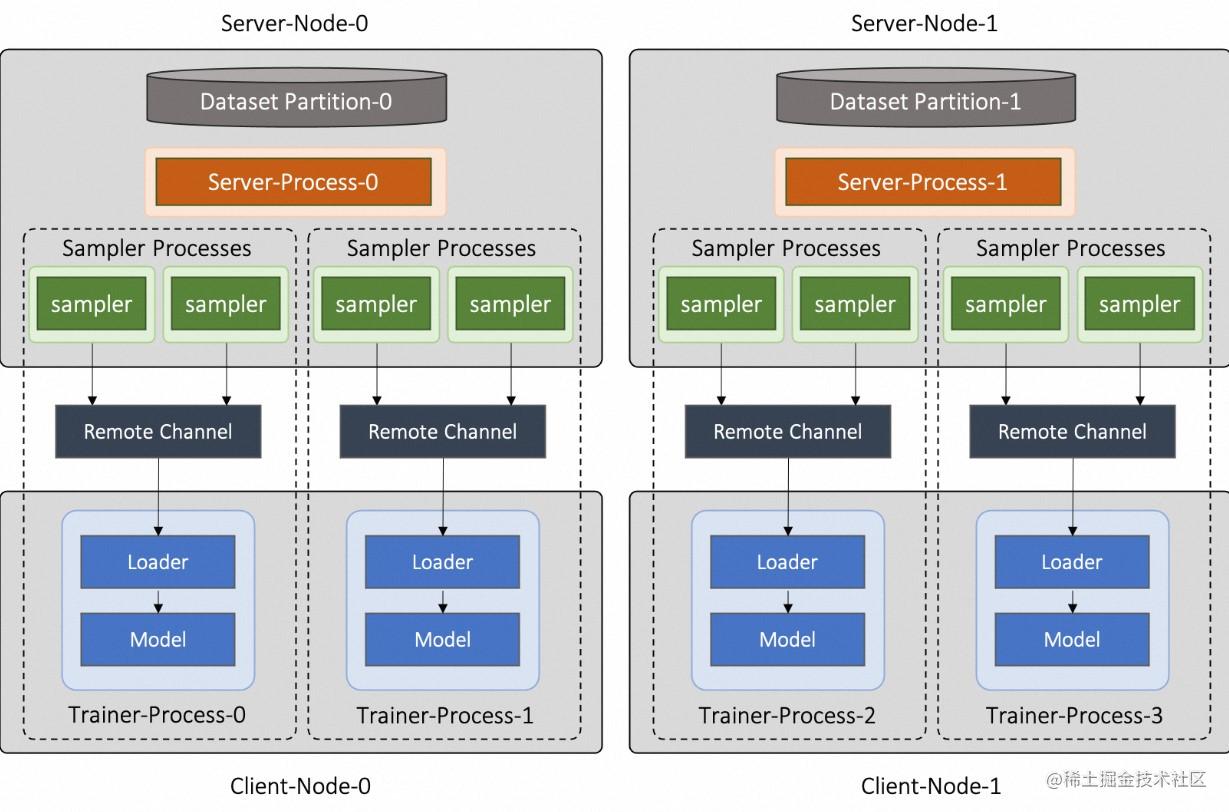
Server-Client模式下,集群中存在两种类型的机器节点,即 Server 节点和 Client 节点。采样进程部署在 Server 节点,训练进程分布在所有 Client 节点上。采样进程生成的样本结果将通过一个RPC实现的远程消息通道发送到当前训练进程进行训练。Server-Client 模式可以将采样和训练不同 workload 的任务放到不同机器,进行资源上的解耦。
总体架构
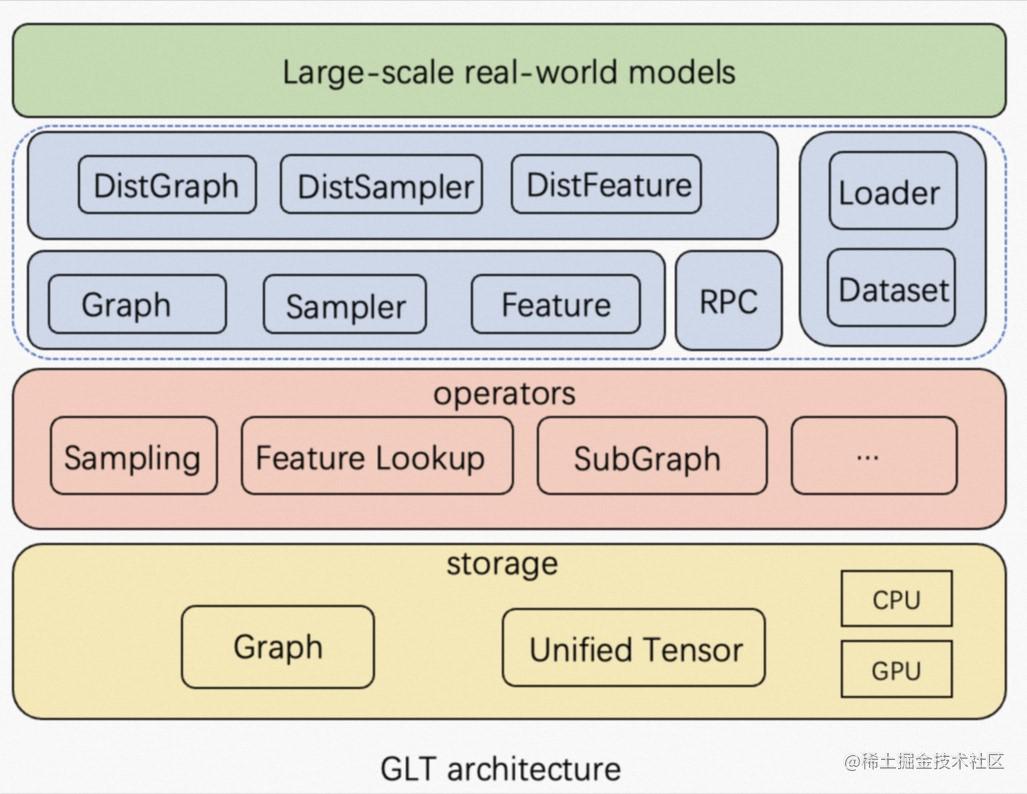
GLT 的主要目标是充分利用 GPU/NVLink/RDMA 等硬件资源和 GNN 模型的特性,加速单机和分布式环境下的端到端 GNN 训练。
存储:在 GPU 训练场景,图采样和 CPU-GPU 数据传输很容易成为主要性能瓶颈。为了加速图采样和特征查找,GLT 实现了 UnifiedTensor 统一 CPU 和 GPU 的内存管理。为了减少特征收集引起的 CPU-GPU 数据传输开销,GLT 支持将热点特征缓存在 GPU 显存中,并通过 UVA 访问其余特征数据。我们还利用高速 NVLink 在GPU 之间扩展 GPU 缓存的容量。
图操作算子:存储之上,GLT 实现了包括邻居采样、负采样、特征查找、子图采样等同时支持 CPU 和 GPU 图操作算子。
分布式算子:对于分布式训练,为防止远程数据访问阻塞模型训练进程,GLT 在 PyTorch RPC 之上封装了一个高效的 RPC 框架,并采用多进程并行和异步并发的图采样和特征查找操作来隐藏网络延迟并提高端到端训练吞吐量。
接口:为了降低 PyG 用户的学习成本,GLT 的上层 API,如Sampler, Dataset和Loader,接口上都与PyG兼容。因此,PyG 用户只需修改很少的代码即可充分利用 GLT 的加速能力。
模型:由于 GLT 与 PyG 兼容,你可以使用几乎任何 PyG 的模型作为基础模型,此外我们也提供了丰富的分布式训练示例。
系统性能
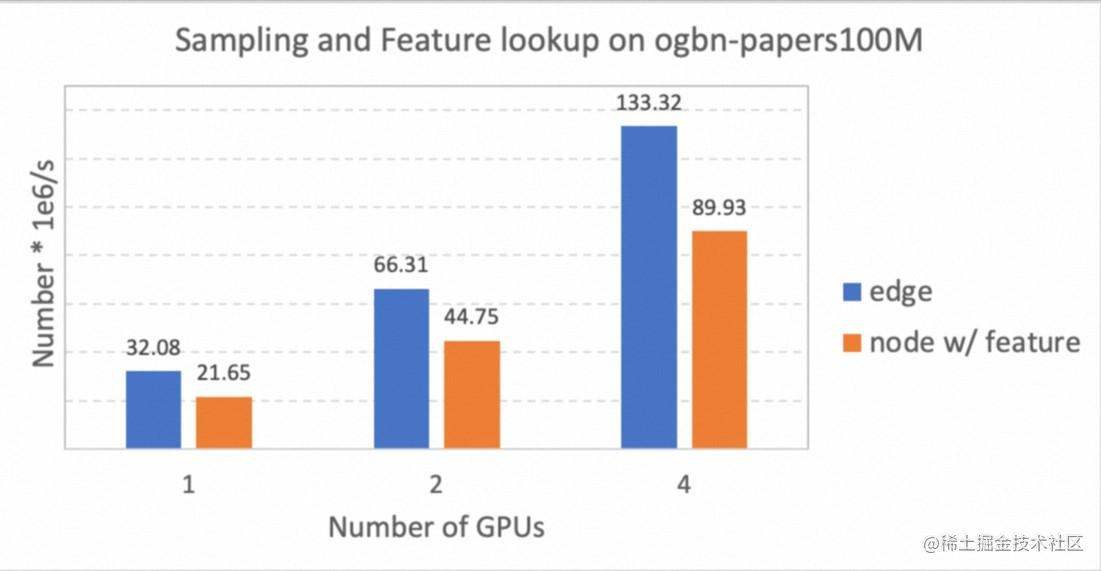
我们在一台配备A100 GPU的机器进行单机扩展性测试,测试环境为 CUDA 11.4、PyTorch 1.12 和 GLT 0.2.0rc2,下图展示了邻居采样和特征查找的总吞吐量。可以看出 GLT 有线性的扩展性(由于有NVLink,多卡的缓存容量更多,因此会存在超线性加速)。
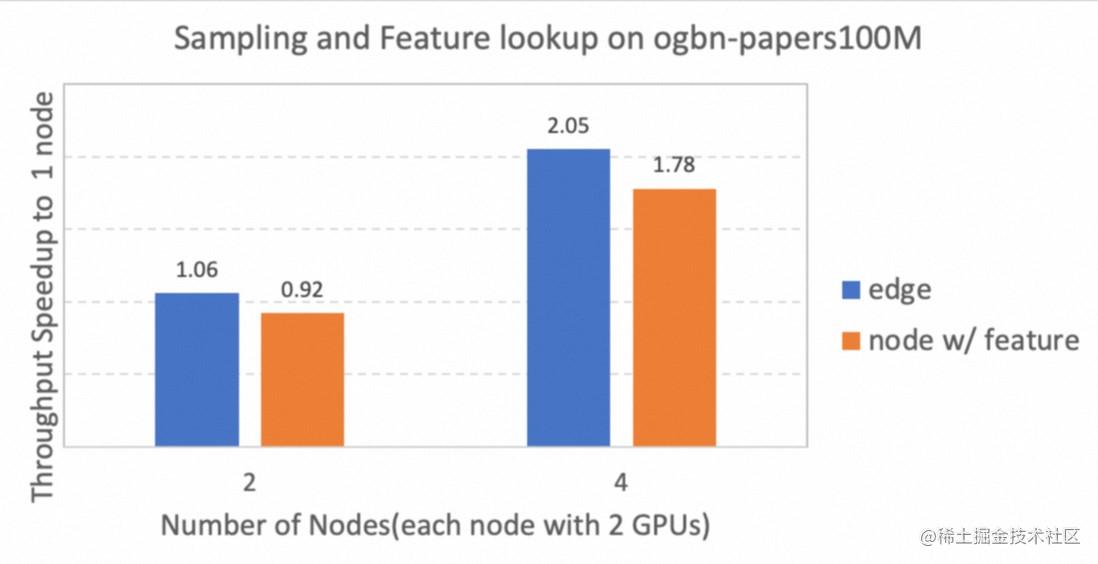
此外,我们还测试了多机的分布式采样和特征查找的扩展性。下图展示了每个机器配备2个A100 GPU的环境下,2个机器和4个机器相比单个机器的吞吐量加速比。测试使用 CUDA11.4、PyTorch 1.12和 GLT 0.2.0rc2 进行。可以看出,2机到4机也有近线性的扩展性。
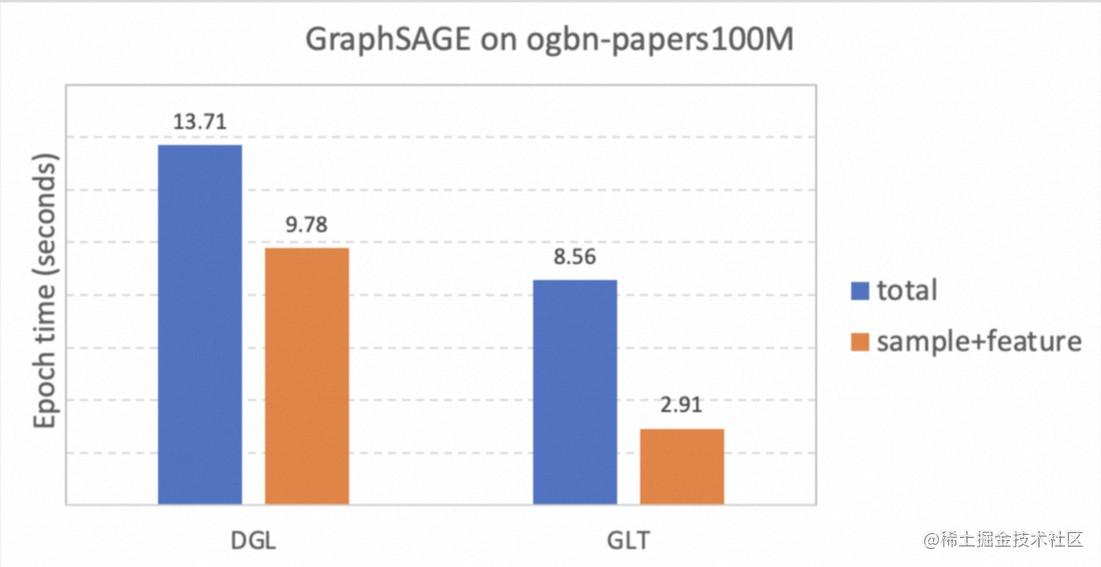
最后,我们测试了分布式e2e的性能。我们在2机每机2卡A100的设置下和DGL做了初步对比(DGL版本0.9.1,GLT版本0.2.0).
结语
本文介绍了基于PyTorch的GPU加速分布式GNN框架GraphLearn-for-PyTorch(GLT),GLT提供了分布式 GPU 训练的优化加速能力,能够充分利用 GPU 等硬件资源进行图采样和特征查找等操作,具有线性扩展性。上层接口上和 PyG 兼容,可以很容易地加速 PyG 已有模型或者将已有模型改成分布式版本。GLT 已经开源并且在PyG, GraphScope中都有示例,后面我们会持续开发优化,欢迎使用和贡献!
[1] P3: Distributed Deep Graph Learning at Scale
[2] Quiver: Supporting GPUs for Low-Latency, High-Throughput GNN Serving with Workload Awareness
免费领取 交互式建模PAI-DSW、模型训练PAI-DLC 5000CU*H计算资源包,以及价值500元模型在线服务 PAI-EAS 抵扣包。
![深度学习应用篇-元学习[14]:基于优化的元学习-MAML模型、LEO模型、Reptile模型](https://img-blog.csdnimg.cn/img_convert/d227e3465fa19ff1bc8bdd5b73afc2ed.png)




![[PostgreSQL-16新特性之EXPLAIN的GENERIC_PLAN选项]](https://img-blog.csdnimg.cn/img_convert/411da8850ca399e994c3839eb1f6ae1d.png)