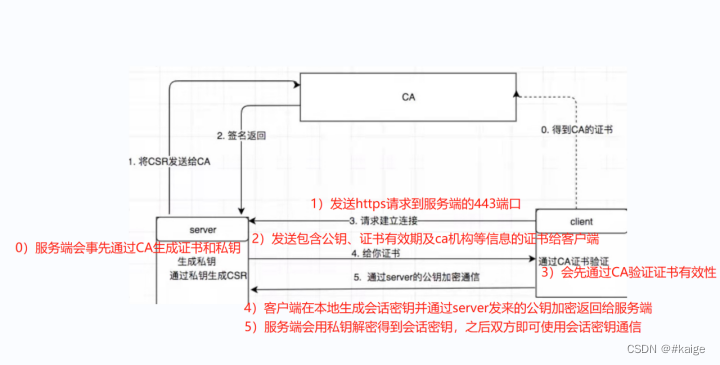
使用代理IP可以帮助爬虫隐藏真实IP地址,防止被网站封禁或限制访问。此外,使用代理IP还可以帮助爬虫绕过一些地区或国家的访问限制,获取更多的数据。因此,对于一些需要频繁爬取数据的爬虫,使用代理IP是一个不错的选择。但是,需要注意的是,使用代理IP也可能会带来一些问题,比如代理IP的稳定性、速度等问题,需要根据具体情况进行选择。

不是所有的爬虫都需要使用代理 IP。但是,对于一些特定的数据采集任务,使用代理 IP 可以带来以下好处:
1、躲避反爬虫机制:网站管理员可能会针对频繁的请求设置反爬虫机制,如 IP 封禁、验证码、限速等,使用代理 IP 可以规避这些限制,提高爬虫的稳定性和可用性。
2、模拟地理位置:有些网站根据访问者的地理位置不同的服务或,通过使用特定地区的代理 IP,可以模拟访问该地区的用户,获取更准确的数据。
3、获得更多数据源:有些网站可能会限制某些地区的访问,通过使用代理 IP,可以访问被限制的网站,从而获得更多的数据来源。
需要指出的是,使用代理 IP 也可能存在一些潜在的问题和风险,如代理服务的质量、稳定性和安全性等方面需谨慎考虑。
如何区分高质量代理ip
区分高质量代理 IP 可以从以下几个方面考虑:
1、稳定性:高质量代理 IP 应该是稳定、可靠的,不容易出现连接中断或者频繁变换 IP 地址等情况。
2、速度:高质量代理 IP 连接速度应该比较快,不要影响爬虫的访问效率和速度。
3、匿名性:高质量代理 IP 应该具备一定的匿名性,可以避免被目标网站识别并封禁 IP 或访问受限页面。
4、私密性:高质量代理 IP 应该有一定的私密性,即只有你自己使用,未被其他人占用和滥用。
5、支持协议类型:代理 IP 还需要支持爬虫所需的协议类型(如HTTP、HTTPS、SOCKS等)。
为了找到高质量代理 IP,可以尝试使用一些第三方服务商提供的代理 IP 池,这些服务商会筛选可用的代理 IP,并提供给客户使用。也可以自己搭建代理池获取 IP,不过需要进行一些技术上的设置和维护。
爬虫使用代理ip通用代码
以下是一个简单的Python爬虫使用代理IP的示例代码。该代码使用requests库来发送HTTP请求,并通过设置proxies参数来指定代理IP。
import requests
# 设置代理IP地址
proxies = {
"http": "http://ip_address:port",
"https": "http://ip_address:port"
}
# 发送HTTP GET请求,设置代理IP
resp = requests.get("http://example.com", proxies=proxies)
# 输出响应内容
print(resp.text)
请将 ip_address 和 port 替换为你所使用的代理IP地址和端口号。另外,请注意如果代理IP需要验证用户名和密码,需要在 proxies 中添加相应的信息,例如:
proxies = {
"http": "http://username:password@ip_address:port",
"https": "http://username:password@ip_address:port"
}
在使用代理IP时,建议先进行一些简单的测试以确保代理IP正常运作,并可用于爬取目标网站。