AI实战营第二期 第八节 《MMSegmentation代码课》
【课程链接】https://www.bilibili.com/video/BV1uh411T73q/
【讲师介绍】张子豪 OpenMMLab算法工程师
【学习形式】录播+社群答疑
【作业布置】本次课程为实战课,需提交笔记+作业。

课程大纲:
- 环境配置
- 预训练模型预测图片、视频
- 航拍图像语义分割案例
- 肾小球病理切片语义分割案例
作业:
- 西瓜瓤、西瓜皮、西瓜籽像素级语义分割
安装配置MMSegmentation
安装pytorch
pip install install torch==1.10.1+cu113 torchvision==0.11.2+cu113 torchaudio==0.10.1+cu113 -f https://download.pytorch.org/whl/cu113/torch_stable.html
用MIM安装MMCV
pip install -U openmim
mim install mmengine
mim install 'mmcv==2.0.0rc4'
安装其它工具包
pip install opencv-python pillow matplotlib seaborn tqdm pytorch-lightning 'mmdet>=3.0.0rc1' -i https://pypi.tuna.tsinghua.edu.cn/simple
下载 与安装MMSegmentation
# 删掉原有的 mmsegmentation 文件夹(如有)
rm -rf mmsegmentation
# 从 github 上下载最新的 mmsegmentation 源代码
git clone https://github.com/open-mmlab/mmsegmentation.git -b dev-1.x
pip install -v -e .
下载预训练模型权重文件和视频素材
import os
# 创建 checkpoint 文件夹,用于存放预训练模型权重文件
os.mkdir('checkpoint')
# 创建 outputs 文件夹,用于存放预测结果
os.mkdir('outputs')
# 创建 data 文件夹,用于存放图片和视频素材
os.mkdir('data')
下载预训练模型权重至checkpoint目录
Model Zoo:https://github.com/open-mmlab/mmsegmentation/blob/master/docs/en/model_zoo.md
从 Model Zoo 获取 PSPNet 预训练模型,下载并保存在 checkpoint 文件夹中
!wget https://download.openmmlab.com/mmsegmentation/v0.5/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth -P checkpoint
下载素材至data目录
如果报错Unable to establish SSL connection.,重新运行代码块即可。
# 伦敦街景图片
!wget https://zihao-openmmlab.obs.cn-east-3.myhuaweicloud.com/20220713-mmdetection/images/street_uk.jpeg -P data
# 上海驾车街景视频,视频来源:https://www.youtube.com/watch?v=ll8TgCZ0plk
!wget https://zihao-download.obs.cn-east-3.myhuaweicloud.com/detectron2/traffic.mp4 -P data
# 街拍视频,2022年3月30日
!wget https://zihao-openmmlab.obs.cn-east-3.myhuaweicloud.com/20220713-mmdetection/images/street_20220330_174028.mp4 -P data
检查安装成功
# 检查 Pytorch
import torch, torchvision
print('Pytorch 版本', torch.__version__)
print('CUDA 是否可用',torch.cuda.is_available())
# 检查 mmcv
import mmcv
from mmcv.ops import get_compiling_cuda_version, get_compiler_version
print('MMCV版本', mmcv.__version__)
print('CUDA版本', get_compiling_cuda_version())
print('编译器版本', get_compiler_version())
# 检查 mmsegmentation
import mmseg
from mmseg.utils import register_all_modules
from mmseg.apis import inference_model, init_model
print('mmsegmentation版本', mmseg.__version__)
设置Matplotlib中文字体
# # windows操作系统
# plt.rcParams['font.sans-serif']=['SimHei'] # 用来正常显示中文标签
# plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号
# Mac操作系统,参考 https://www.ngui.cc/51cto/show-727683.html
# 下载 simhei.ttf 字体文件
# !wget https://zihao-openmmlab.obs.cn-east-3.myhuaweicloud.com/20220716-mmclassification/dataset/SimHei.ttf
# Linux操作系统,例如 云GPU平台:https://featurize.cn/?s=d7ce99f842414bfcaea5662a97581bd1
# 如果遇到 SSL 相关报错,重新运行本代码块即可
!wget https://zihao-openmmlab.obs.cn-east-3.myhuaweicloud.com/20220716-mmclassification/dataset/SimHei.ttf -O /environment/miniconda3/lib/python3.7/site-packages/matplotlib/mpl-data/fonts/ttf/SimHei.ttf
!rm -rf /home/featurize/.cache/matplotlib
import matplotlib
import matplotlib.pyplot as plt
matplotlib.rc("font",family='SimHei') # 中文字体
plt.plot([1,2,3], [100,500,300])
plt.title('matplotlib中文字体测试', fontsize=25)
plt.xlabel('X轴', fontsize=15)
plt.ylabel('Y轴', fontsize=15)
plt.show()
预训练语义分割模型预测
进入 mmsegmentation 主目录
import os
os.chdir('mmsegmentation')
载入测试图像
from PIL import Image
MMSegmentation模型库
Model Zoo:https://github.com/open-mmlab/mmsegmentation/blob/master/docs/en/model_zoo.md
常用config和checkpoint文件
configs/pspnet/pspnet_r50-d8_4xb2-40k_cityscapes-512x1024.py
https://download.openmmlab.com/mmsegmentation/v0.5/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth
configs/segformer/segformer_mit-b5_8xb1-160k_cityscapes-1024x1024.py
https://download.openmmlab.com/mmsegmentation/v0.5/segformer/segformer_mit-b5_8x1_1024x1024_160k_cityscapes/segformer_mit-b5_8x1_1024x1024_160k_cityscapes_20211206_072934-87a052ec.pth
configs/mask2former/mask2former_swin-l-in22k-384x384-pre_8xb2-90k_cityscapes-512x1024.py
https://download.openmmlab.com/mmsegmentation/v0.5/mask2former/mask2former_swin-l-in22k-384x384-pre_8xb2-90k_cityscapes-512x1024/mask2former_swin-l-in22k-384x384-pre_8xb2-90k_cityscapes-512x1024_20221202_141901-28ad20f1.pth
PSPNet
PSPNet语义分割算法
!python demo/image_demo.py \
data/street_uk.jpeg \
configs/pspnet/pspnet_r50-d8_4xb2-40k_cityscapes-512x1024.py \
https://download.openmmlab.com/mmsegmentation/v0.5/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth \
--out-file outputs/B1_uk_pspnet.jpg \
--device cuda:0 \
--opacity 0.5

SegFormer
!python demo/image_demo.py \
data/street_uk.jpeg \
configs/segformer/segformer_mit-b5_8xb1-160k_cityscapes-1024x1024.py \
https://download.openmmlab.com/mmsegmentation/v0.5/segformer/segformer_mit-b5_8x1_1024x1024_160k_cityscapes/segformer_mit-b5_8x1_1024x1024_160k_cityscapes_20211206_072934-87a052ec.pth \
--out-file outputs/B1_uk_segformer.jpg \
--device cuda:0 \
--opacity 0.5

Mask2Former
!python demo/image_demo.py \
data/street_uk.jpeg \
configs/mask2former/mask2former_swin-l-in22k-384x384-pre_8xb2-90k_cityscapes-512x1024.py \
https://download.openmmlab.com/mmsegmentation/v0.5/mask2former/mask2former_swin-l-in22k-384x384-pre_8xb2-90k_cityscapes-512x1024/mask2former_swin-l-in22k-384x384-pre_8xb2-90k_cityscapes-512x1024_20221202_141901-28ad20f1.pth \
--out-file outputs/B1_uk_Mask2Former.jpg \
--device cuda:0 \
--opacity 0.5
ADE20K语义分割数据集
mmsegmentation/mmseg/datasets/ade.py
关于ADE20K的故事:https://www.zhihu.com/question/390783647/answer/1226097849
!python demo/image_demo.py \
data/street_uk.jpeg \
configs/segformer/segformer_mit-b5_8xb2-160k_ade20k-640x640.py \
https://download.openmmlab.com/mmsegmentation/v0.5/segformer/segformer_mit-b5_640x640_160k_ade20k/segformer_mit-b5_640x640_160k_ade20k_20220617_203542-940a6bd8.pth \
--out-file outputs/B1_Segformer_ade20k.jpg \
--device cuda:0 \
--opacity 0.5

预训练语义分割模型预测-视频
视频预测-命令行(不推荐,慢)
!python demo/video_demo.py \
data/street_20220330_174028.mp4 \
configs/mask2former/mask2former_swin-l-in22k-384x384-pre_8xb2-90k_cityscapes-512x1024.py \
https://download.openmmlab.com/mmsegmentation/v0.5/mask2former/mask2former_swin-l-in22k-384x384-pre_8xb2-90k_cityscapes-512x1024/mask2former_swin-l-in22k-384x384-pre_8xb2-90k_cityscapes-512x1024_20221202_141901-28ad20f1.pth \
--device cuda:0 \
--output-file outputs/B3_video.mp4 \
--opacity 0.5
视频预测-Python API(推荐,快)
import numpy as np
import time
import shutil
import torch
from PIL import Image
import cv2
import mmcv
import mmengine
from mmseg.apis import inference_model
from mmseg.utils import register_all_modules
register_all_modules()
from mmseg.datasets import CityscapesDataset
# 模型 config 配置文件
config_file = 'configs/mask2former/mask2former_swin-l-in22k-384x384-pre_8xb2-90k_cityscapes-512x1024.py'
# 模型 checkpoint 权重文件
checkpoint_file = 'https://download.openmmlab.com/mmsegmentation/v0.5/mask2former/mask2former_swin-l-in22k-384x384-pre_8xb2-90k_cityscapes-512x1024/mask2former_swin-l-in22k-384x384-pre_8xb2-90k_cityscapes-512x1024_20221202_141901-28ad20f1.pth'
from mmseg.apis import init_model
model = init_model(config_file, checkpoint_file, device='cuda:0')
from mmengine.model.utils import revert_sync_batchnorm
if not torch.cuda.is_available():
model = revert_sync_batchnorm(model)
# input_video = 'data/traffic.mp4'
input_video = 'data/street_20220330_174028.mp4'
temp_out_dir = time.strftime('%Y%m%d%H%M%S')
os.mkdir(temp_out_dir)
print('创建临时文件夹 {} 用于存放每帧预测结果'.format(temp_out_dir))
# 获取 Cityscapes 街景数据集 类别名和调色板
from mmseg.datasets import cityscapes
classes = cityscapes.CityscapesDataset.METAINFO['classes']
palette = cityscapes.CityscapesDataset.METAINFO['palette']
def pridict_single_frame(img, opacity=0.2):
result = inference_model(model, img)
# 将分割图按调色板染色
seg_map = np.array(result.pred_sem_seg.data[0].detach().cpu().numpy()).astype('uint8')
seg_img = Image.fromarray(seg_map).convert('P')
seg_img.putpalette(np.array(palette, dtype=np.uint8))
show_img = (np.array(seg_img.convert('RGB')))*(1-opacity) + img*opacity
return show_img
# 读入待预测视频
imgs = mmcv.VideoReader(input_video)
prog_bar = mmengine.ProgressBar(len(imgs))
# 对视频逐帧处理
for frame_id, img in enumerate(imgs):
## 处理单帧画面
show_img = pridict_single_frame(img, opacity=0.15)
temp_path = f'{temp_out_dir}/{frame_id:06d}.jpg' # 保存语义分割预测结果图像至临时文件夹
cv2.imwrite(temp_path, show_img)
prog_bar.update() # 更新进度条
# 把每一帧串成视频文件
mmcv.frames2video(temp_out_dir, 'outputs/B3_video.mp4', fps=imgs.fps, fourcc='mp4v')
shutil.rmtree(temp_out_dir) # 删除存放每帧画面的临时文件夹
print('删除临时文件夹', temp_out_dir)
Kaggle实战-迪拜卫星航拍多类别语义分割
下载整理好的数据集
Kaggle原版数据集:https://www.kaggle.com/datasets/humansintheloop/semantic-segmentation-of-aerial-imagery
下载整理好之后的数据集
!rm -rf Dubai-dataset.zip Dubai-dataset
!wget https://zihao-openmmlab.obs.cn-east-3.myhuaweicloud.com/20230130-mmseg/dataset/Dubai-dataset.zip
!unzip Dubai-dataset.zip >> /dev/null # 解压
!rm -rf Dubai-dataset.zip # 删除压缩包
删除系统自动生成的多余文件
查看待删除的多余文件
!find . -iname '__MACOSX'
!find . -iname '__MACOSX'
!find . -iname '.DS_Store'
!find . -iname '.ipynb_checkpoints'
./.ipynb_checkpoints
删除多余文件
!for i in `find . -iname '__MACOSX'`; do rm -rf $i;done
!for i in `find . -iname '.DS_Store'`; do rm -rf $i;done
!for i in `find . -iname '.ipynb_checkpoints'`; do rm -rf $i;done
验证多余文件已删除
!find . -iname '__MACOSX'
!find . -iname '.DS_Store'
!find . -iname '.ipynb_checkpoints'
可视化探索数据集
import os
import cv2
import numpy as np
from PIL import Image
from tqdm import tqdm
import matplotlib.pyplot as plt
%matplotlib inline
# 指定单张图像路径
img_path = 'Dubai-dataset/img_dir/train/14.jpg'
mask_path = 'Dubai-dataset/ann_dir/train/14.png'
img = cv2.imread(img_path)
mask = cv2.imread(mask_path)
# 可视化语义分割标注
plt.imshow(mask[:,:,0])
plt.show()

plt.imshow(img[:,:,::-1])
plt.imshow(mask[:,:,0], alpha=0.4) # alpha 高亮区域透明度,越小越接近原图
plt.axis('off')
plt.show()

批量可视化图像和标注
# 指定图像和标注路径
PATH_IMAGE = 'Dubai-dataset/img_dir/train'
PATH_MASKS = 'Dubai-dataset/ann_dir/train'
# n行n列可视化
n = 5
# 标注区域透明度
opacity = 0.5
fig, axes = plt.subplots(nrows=n, ncols=n, sharex=True, figsize=(12,12))
for i, file_name in enumerate(os.listdir(PATH_IMAGE)[:n**2]):
# 载入图像和标注
img_path = os.path.join(PATH_IMAGE, file_name)
mask_path = os.path.join(PATH_MASKS, file_name.split('.')[0]+'.png')
img = cv2.imread(img_path)
mask = cv2.imread(mask_path)
# 可视化
axes[i//n, i%n].imshow(img)
axes[i//n, i%n].imshow(mask[:,:,0], alpha=opacity)
axes[i//n, i%n].axis('off') # 关闭坐标轴显示
fig.suptitle('Image and Semantic Label', fontsize=30)
plt.tight_layout()
plt.show()
准备config配置文件
import numpy as np
from PIL import Image
import os.path as osp
from tqdm import tqdm
import mmcv
import mmengine
import matplotlib.pyplot as plt
%matplotlib inline
定义数据集类(各类别名称及配色)
!rm -rf mmseg/datasets/DubaiDataset.py # 删除原有文件
!wget https://zihao-openmmlab.obs.cn-east-3.myhuaweicloud.com/20230130-mmseg/Dubai/DubaiDataset.py -P mmseg/datasets
注册数据集类
!rm -rf mmseg/datasets/__init__.py # 删除原有文件
!wget https://zihao-openmmlab.obs.cn-east-3.myhuaweicloud.com/20230130-mmseg/Dubai/__init__.py -P mmseg/datasets
定义训练及测试pipeline
!rm -rf configs/_base_/datasets/DubaiDataset_pipeline.py
!wget https://zihao-openmmlab.obs.cn-east-3.myhuaweicloud.com/20230130-mmseg/Dubai/DubaiDataset_pipeline.py -P configs/_base_/datasets
下载模型config配置文件
!rm -rf configs/pspnet/pspnet_r50-d8_4xb2-40k_DubaiDataset.py # 删除原有文件
!wget https://zihao-openmmlab.obs.cn-east-3.myhuaweicloud.com/20230130-mmseg/Dubai/pspnet_r50-d8_4xb2-40k_DubaiDataset.py -P configs/pspnet
载入config配置文件
from mmengine import Config
cfg = Config.fromfile('./configs/pspnet/pspnet_r50-d8_4xb2-40k_DubaiDataset.py')
修改config配置文件
cfg.norm_cfg = dict(type='BN', requires_grad=True) # 只使用GPU时,BN取代SyncBN
cfg.crop_size = (256, 256)
cfg.model.data_preprocessor.size = cfg.crop_size
cfg.model.backbone.norm_cfg = cfg.norm_cfg
cfg.model.decode_head.norm_cfg = cfg.norm_cfg
cfg.model.auxiliary_head.norm_cfg = cfg.norm_cfg
# modify num classes of the model in decode/auxiliary head
# 模型 decode/auxiliary 输出头,指定为类别个数
cfg.model.decode_head.num_classes = 6
cfg.model.auxiliary_head.num_classes = 6
cfg.train_dataloader.batch_size = 8
cfg.test_dataloader = cfg.val_dataloader
# 结果保存目录
cfg.work_dir = './work_dirs/DubaiDataset'
# 训练迭代次数
cfg.train_cfg.max_iters = 3000
# 评估模型间隔
cfg.train_cfg.val_interval = 400
# 日志记录间隔
cfg.default_hooks.logger.interval = 100
# 模型权重保存间隔
cfg.default_hooks.checkpoint.interval = 1500
# 随机数种子
cfg['randomness'] = dict(seed=0)
查看完整config配置文件
print(cfg.pretty_text)
保存config配置文件
cfg.dump('pspnet-DubaiDataset_20230612.py')
MMSegmentation训练语义分割模型
import numpy as np
import os.path as osp
from tqdm import tqdm
import mmcv
import mmengine
from mmengine import Config
cfg = Config.fromfile('pspnet-DubaiDataset_20230612.py')
from mmengine.runner import Runner
from mmseg.utils import register_all_modules
# register all modules in mmseg into the registries
# do not init the default scope here because it will be init in the runner
register_all_modules(init_default_scope=False)
runner = Runner.from_cfg(cfg)
runner.train()
开始训练
如果遇到报错CUDA out of memeory,可尝试以下步骤:
-
调小 batch size
-
左上角内核-关闭所有内核
-
重启实例,或者使用显存更高的实例即可。
可视化训练日志
设置Matplotlib中文字体
# # windows操作系统
# plt.rcParams['font.sans-serif']=['SimHei'] # 用来正常显示中文标签
# plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号
# Mac操作系统,参考 https://www.ngui.cc/51cto/show-727683.html
# 下载 simhei.ttf 字体文件
# !wget https://zihao-openmmlab.obs.cn-east-3.myhuaweicloud.com/20220716-mmclassification/dataset/SimHei.ttf
# Linux操作系统,例如 云GPU平台:https://featurize.cn/?s=d7ce99f842414bfcaea5662a97581bd1
# 如果遇到 SSL 相关报错,重新运行本代码块即可
!wget https://zihao-openmmlab.obs.cn-east-3.myhuaweicloud.com/20220716-mmclassification/dataset/SimHei.ttf -O /environment/miniconda3/lib/python3.7/site-packages/matplotlib/mpl-data/fonts/ttf/SimHei.ttf
!rm -rf /home/featurize/.cache/matplotlib
import matplotlib
import matplotlib.pyplot as plt
matplotlib.rc("font",family='SimHei') # 中文字体
plt.plot([1,2,3], [100,500,300])
plt.title('matplotlib中文字体测试', fontsize=25)
plt.xlabel('X轴', fontsize=15)
plt.ylabel('Y轴', fontsize=15)
plt.show()
导入工具包
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
载入训练日志
日志文件路径
log_path = 'work_dirs/DubaiDataset/20230612_100725/vis_data/scalars.json'
with open(log_path, "r") as f:
json_list = f.readlines()
len(json_list)
eval(json_list[4])
df_train = pd.DataFrame()
df_test = pd.DataFrame()
for each in json_list[:-1]:
if 'aAcc' in each:
df_test = df_test.append(eval(each), ignore_index=True)
else:
df_train = df_train.append(eval(each), ignore_index=True)
导出训练日志表格
df_train.to_csv('训练日志-训练集.csv', index=False)
df_test.to_csv('训练日志-测试集.csv', index=False)
可视化辅助函数
from matplotlib import colors as mcolors
import random
random.seed(124)
colors = ['b', 'g', 'r', 'c', 'm', 'y', 'k', 'tab:blue', 'tab:orange', 'tab:green', 'tab:red', 'tab:purple', 'tab:brown', 'tab:pink', 'tab:gray', 'tab:olive', 'tab:cyan', 'black', 'indianred', 'brown', 'firebrick', 'maroon', 'darkred', 'red', 'sienna', 'chocolate', 'yellow', 'olivedrab', 'yellowgreen', 'darkolivegreen', 'forestgreen', 'limegreen', 'darkgreen', 'green', 'lime', 'seagreen', 'mediumseagreen', 'darkslategray', 'darkslategrey', 'teal', 'darkcyan', 'dodgerblue', 'navy', 'darkblue', 'mediumblue', 'blue', 'slateblue', 'darkslateblue', 'mediumslateblue', 'mediumpurple', 'rebeccapurple', 'blueviolet', 'indigo', 'darkorchid', 'darkviolet', 'mediumorchid', 'purple', 'darkmagenta', 'fuchsia', 'magenta', 'orchid', 'mediumvioletred', 'deeppink', 'hotpink']
markers = [".",",","o","v","^","<",">","1","2","3","4","8","s","p","P","*","h","H","+","x","X","D","d","|","_",0,1,2,3,4,5,6,7,8,9,10,11]
linestyle = ['--', '-.', '-']
def get_line_arg():
'''
随机产生一种绘图线型
'''
line_arg = {}
line_arg['color'] = random.choice(colors)
# line_arg['marker'] = random.choice(markers)
line_arg['linestyle'] = random.choice(linestyle)
line_arg['linewidth'] = random.randint(1, 4)
# line_arg['markersize'] = random.randint(3, 5)
return line_arg
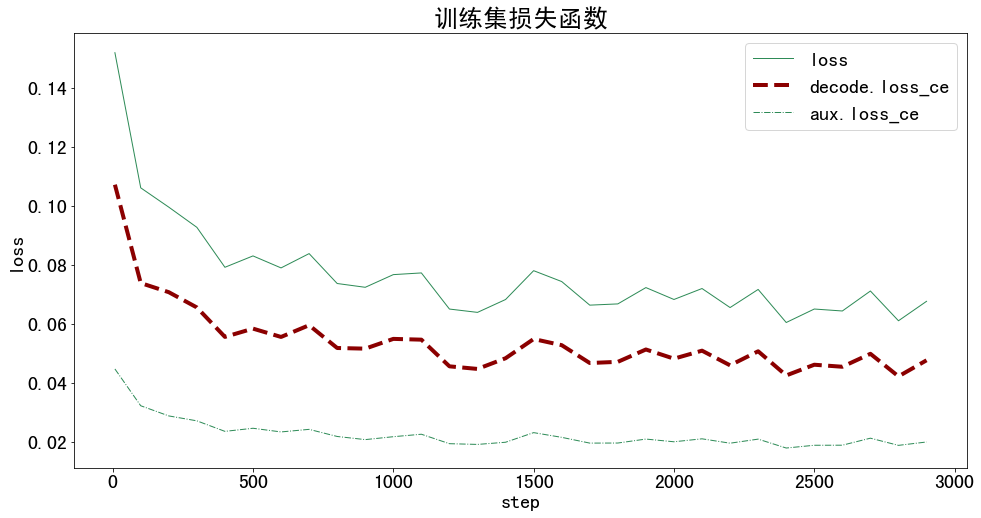
训练集损失函数
metrics = ['loss', 'decode.loss_ce', 'aux.loss_ce']
plt.figure(figsize=(16, 8))
x = df_train['step']
for y in metrics:
plt.plot(x, df_train[y], label=y, **get_line_arg())
plt.tick_params(labelsize=20)
plt.xlabel('step', fontsize=20)
plt.ylabel('loss', fontsize=20)
plt.title('训练集损失函数', fontsize=25)
plt.savefig('训练集损失函数.pdf', dpi=120, bbox_inches='tight')
plt.legend(fontsize=20)
plt.show()
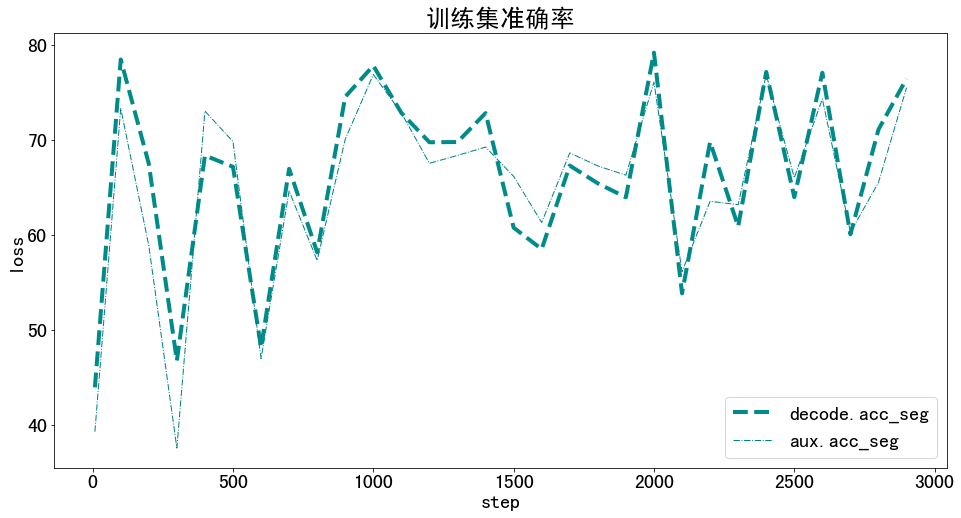
训练集准确率
plt.figure(figsize=(16, 8))
x = df_train['step']
for y in metrics:
plt.plot(x, df_train[y], label=y, **get_line_arg())
plt.tick_params(labelsize=20)
plt.xlabel('step', fontsize=20)
plt.ylabel('loss', fontsize=20)
plt.title('训练集准确率', fontsize=25)
plt.savefig('训练集准确率.pdf', dpi=120, bbox_inches='tight')
plt.legend(fontsize=20)
plt.show()
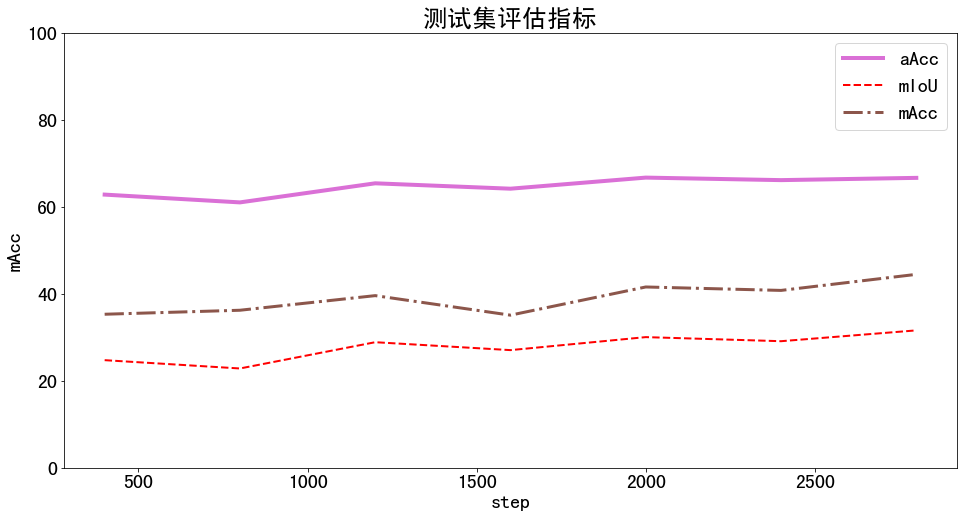
测试集评估指标
plt.figure(figsize=(16, 8))
x = df_test['step']
for y in metrics:
plt.plot(x, df_test[y], label=y, **get_line_arg())
plt.tick_params(labelsize=20)
plt.ylim([0, 100])
plt.xlabel('step', fontsize=20)
plt.ylabel(y, fontsize=20)
plt.title('测试集评估指标', fontsize=25)
plt.savefig('测试集分类评估指标.pdf', dpi=120, bbox_inches='tight')
plt.legend(fontsize=20)
plt.show()
模型预测
导入工具包
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
from mmseg.apis import init_model, inference_model, show_result_pyplot
import mmcv
import cv2
载入配置文件
# 载入 config 配置文件
from mmengine import Config
cfg = Config.fromfile('pspnet-DubaiDataset_20230612.py')
from mmengine.runner import Runner
from mmseg.utils import register_all_modules
# register all modules in mmseg into the registries
# do not init the default scope here because it will be init in the runner
register_all_modules(init_default_scope=False)
runner = Runner.from_cfg(cfg)
载入模型
checkpoint_path = './work_dirs/DubaiDataset/iter_3000.pth'
model = init_model(cfg, checkpoint_path, 'cuda:0')
载入测试集图像,或新图像
img = mmcv.imread('Dubai-dataset/img_dir/val/71.jpg')
语义分割预测
result = inference_model(model, img)
pred_mask = result.pred_sem_seg.data[0].cpu().numpy()
np.unique(pred_mask)
array([0, 1, 2, 3, 4])
plt.imshow(pred_mask)
plt.show()

可视化预测结果
visualization = show_result_pyplot(model, img, result, opacity=0.7, out_file='pred.jpg')
plt.imshow(mmcv.bgr2rgb(visualization))
plt.show()

获取测试集标注
获取测试集标注
label = mmcv.imread('Dubai-dataset/ann_dir/val/71.png')
label_mask = label[:,:,0]
np.unique(label_mask)
plt.imshow(label_mask)
plt.show()

对比测试集标注和语义分割预测结果
# 测试集标注
# 真实为前景,预测为前景
TP = (label_mask == 1) & (pred_mask==1)
# 真实为背景,预测为背景
TN = (label_mask == 0) & (pred_mask==0)
# 真实为前景,预测为背景
FN = (label_mask == 1) & (pred_mask==0)
# 真实为背景,预测为前景
FP = (label_mask == 0) & (pred_mask==1)
plt.imshow(TP)
plt.show()

confusion_map = TP * 255 + FP * 150 + FN * 80 + TN * 30
plt.imshow(confusion_map)
plt.show()

混淆矩阵
from sklearn.metrics import confusion_matrix
confusion_matrix_model = confusion_matrix(label_mask.flatten(), pred_mask.flatten())
confusion_matrix_model
import itertools
def cnf_matrix_plotter(cm, classes, cmap=plt.cm.Blues):
"""
传入混淆矩阵和标签名称列表,绘制混淆矩阵
"""
plt.figure(figsize=(10, 10))
plt.imshow(cm, interpolation='nearest', cmap=cmap)
# plt.colorbar() # 色条
tick_marks = np.arange(len(classes))
plt.title('Confusion Matrix', fontsize=30)
plt.xlabel('Pred', fontsize=25, c='r')
plt.ylabel('True', fontsize=25, c='r')
plt.tick_params(labelsize=16) # 设置类别文字大小
plt.xticks(tick_marks, classes, rotation=90) # 横轴文字旋转
plt.yticks(tick_marks, classes)
# 写数字
threshold = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, cm[i, j],
horizontalalignment="center",
color="white" if cm[i, j] > threshold else "black",
fontsize=12)
plt.tight_layout()
plt.savefig('混淆矩阵.pdf', dpi=300) # 保存图像
plt.show()
classes = ['Land', 'Road', 'Building', 'Vegetation', 'Water', 'Unlabeled']
cnf_matrix_plotter(confusion_matrix_model, classes, cmap='Blues')

测试集性能评估
测试集精度指标
python tools/test.py pspnet-DubaiDataset_20230612.py work_dirs/DubaiDataset/iter_3000.pth
速度指标-FPS
!python tools/analysis_tools/benchmark.py pspnet-DubaiDataset_20230612.py work_dirs/DubaiDataset/iter_3000.pth
Kaggle实战-小鼠肾小球组织病理切片语义分割
下载整理好的数据集
下载数据集
!rm -rf Glomeruli-dataset.zip Glomeruli-dataset
!wget https://zihao-openmmlab.obs.cn-east-3.myhuaweicloud.com/20230130-mmseg/dataset/Glomeruli-dataset.zip
!unzip Glomeruli-dataset.zip >> /dev/null # 解压
!rm -rf Glomeruli-dataset.zip # 删除压缩包
删除系统自动生成的多余文件
查看待删除的多余文件
!find . -iname '__MACOSX'
!find . -iname '.DS_Store'
!find . -iname '.ipynb_checkpoints'
./.ipynb_checkpoints
./Glomeruli-dataset/.ipynb_checkpoints
./Glomeruli-dataset/splits/.ipynb_checkpoints
删除多余文件
!for i in `find . -iname '__MACOSX'`; do rm -rf $i;done
!for i in `find . -iname '.DS_Store'`; do rm -rf $i;done
!for i in `find . -iname '.ipynb_checkpoints'`; do rm -rf $i;done
验证多余文件已删除
!find . -iname '__MACOSX'
!find . -iname '.DS_Store'
!find . -iname '.ipynb_checkpoints'
探索数据集
导入工具包
import os
import cv2
import numpy as np
from PIL import Image
from tqdm import tqdm
import matplotlib.pyplot as plt
%matplotlib inline
指定图像和标注文件夹路径
PATH_IMAGE = 'Glomeruli-dataset/images'
PATH_MASKS = 'Glomeruli-dataset/masks'
print('图像个数', len(os.listdir(PATH_IMAGE)))
print('标注个数', len(os.listdir(PATH_MASKS)))
查看单张图像及其语义分割标注
指定图像文件名
file_name = 'SAS_21883_001_10.png'
img_path = os.path.join(PATH_IMAGE, file_name)
mask_path = os.path.join(PATH_MASKS, file_name)
print('图像路径', img_path)
print('标注路径', mask_path)
img = cv2.imread(img_path)
mask = cv2.imread(mask_path)
# 可视化图像
plt.imshow(img)
plt.show()
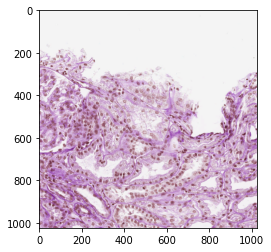
# mask 语义分割标注,与原图大小相同,0 为 背景, 1 为 肾小球
np.unique(mask)
array([0, 1], dtype=uint8)
在本数据集中,只有一部分图像有肾小球语义分割标注(即mask中值为1的像素),其余图像mask的值均为0
可视化语义分割标注
plt.imshow(mask[:,:,0])
plt.show()
# 可视化语义分割标注
plt.imshow(mask*255)
plt.show()

可视化单张图像及其语义分割标注-代码模板
plt.imshow(img)
plt.imshow(mask*255, alpha=0.5) # alpha 高亮区域透明度,越小越接近原图
plt.title(file_name)
plt.axis('off')
plt.show()
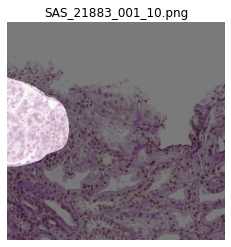
可视化模板-有前景标注
# n行n列可视化
n = 7
# 标注区域透明度
opacity = 0.5
fig, axes = plt.subplots(nrows=n, ncols=n, sharex=True, figsize=(12,12))
i = 0
for file_name in os.listdir(PATH_IMAGE):
# 载入图像和标注
img_path = os.path.join(PATH_IMAGE, file_name)
mask_path = os.path.join(PATH_MASKS, file_name)
img = cv2.imread(img_path)
mask = cv2.imread(mask_path)
if 1 in mask:
axes[i//n, i%n].imshow(img)
axes[i//n, i%n].imshow(mask*255, alpha=opacity)
axes[i//n, i%n].axis('off') # 关闭坐标轴显示
i += 1
if i > n**2-1:
break
fig.suptitle('Image and Semantic Label', fontsize=30)
plt.tight_layout()
plt.show()

可视化模板-无论前景是否有标注
# n行n列可视化
n = 10
# 标注区域透明度
opacity = 0.5
fig, axes = plt.subplots(nrows=n, ncols=n, sharex=True, figsize=(12,12))
for i, file_name in enumerate(os.listdir(PATH_IMAGE)[:n**2]):
# 载入图像和标注
img_path = os.path.join(PATH_IMAGE, file_name)
mask_path = os.path.join(PATH_MASKS, file_name)
img = cv2.imread(img_path)
mask = cv2.imread(mask_path)
# 可视化
axes[i//n, i%n].imshow(img)
axes[i//n, i%n].imshow(mask*255, alpha=opacity)
axes[i//n, i%n].axis('off') # 关闭坐标轴显示
fig.suptitle('Image and Semantic Label', fontsize=30)
plt.tight_layout()
plt.show()