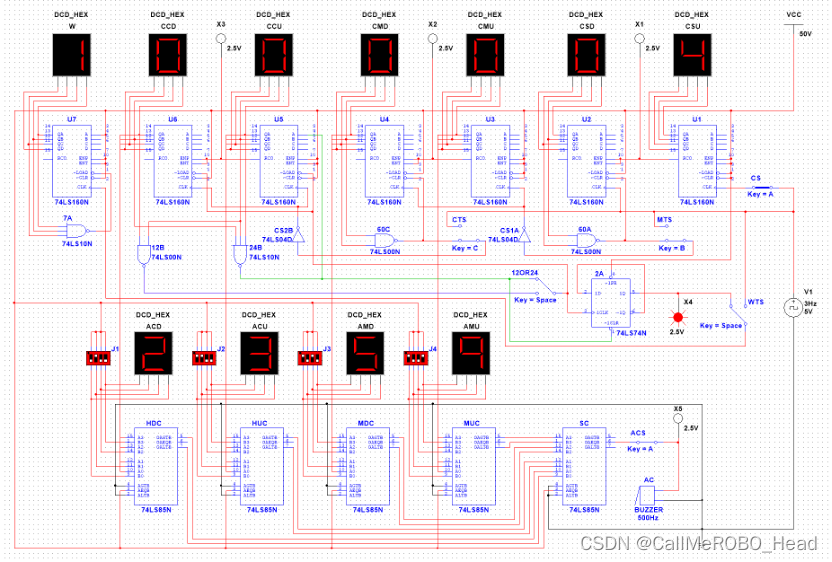
论文笔记--LIMA: Less Is More for Alignment
- 1. 文章简介
- 2. 文章概括
- 3 文章重点技术
- 3.1 表面对齐假设(Superfacial Alignment Hypothesis)
- 3.2 对齐数据
- 3.3 训练
- 4 数值实验
- 5. 文章亮点
- 5. 原文传送门
- 6. References
1. 文章简介
- 标题:LIMA: Less Is More for Alignment
- 作者:Zhou, Chunting, et al.
- 日期:2023
- 期刊:arxiv preprint
2. 文章概括
文章基于表面对齐假设(superfacial alignment hypothesis)展开了一系列的数值实验,证明了大模型的能力是在与训练过程中学习得到,而对齐过程只是为了教会大模型一种符合人类偏好的风格/格式。在此假设基础上,文章训练了一个6B参数的LLaMA模型:LIMA。LIMA只采用了1000条对齐数据,效果已经追平或超过Alpaca,Davinci003,BARD和ClAUDE大模型。
3 文章重点技术
3.1 表面对齐假设(Superfacial Alignment Hypothesis)
文章定义了表明对齐假设:大模型的知识和能力几乎全部在预训练阶段获得的,对齐只是教会模型以何种子分布来和用户进行交互。形象一点来说,pretraining阶段就是知识积累、学习阶段,而预训练阶段则是学习如何演讲、教学等技巧。
3.2 对齐数据
- 社区的问答数据:保证样本的多样性
- stackExchange:stackExchange网站共计179个社区,我们从中选择包括编程、数学、物理等社区在内的75个STEM exchanges(communities)和99个其它的社区,放弃5个社区。我们从每个社区随机抽样几个self-contained问题(即问题包含在标题中),得到不同领域的样本共计200个,并选择每个问题的top 回答。为了保持一致的风格,我们将下述几种情况的答案进行了过滤:1)太短的答案 2)太长的答案 3)第一人称作答的答案 4)参考其它答案的答案(出现关键词as mentioned, stack exchange等)。此外,我们一出了图像、超链接和其它HTML tag,只保留代码和列表。我们随机采用一部分问题的title作为prompt(因为是self-contained,问题包含在title中),另一部分问题用问题描述作为prompt。
- wikiHow:wikiHow包含了24万how-to文章,比如"How to update Microsoft Edge?", "How to tie a tie?"等问题及回答。我们从该网站的19个不同类别下依此采样1篇文章以保证多样性,最终得到200篇how-to文章。这里直接使用标题"How to …"作为prompt,对应的回答作为response即可。
- Pushshift Reddit:Reddit是一个类似贴吧的网站,但相比于前两个网站,Reddit里面受欢迎的回答往往是幽默的、讽刺的等。为此,我们选择两类样本:1)r/AskReddit: 70个self-contained标题作为prompt,用作test set(因为top回答不一定可靠) 2)r/WritingPrompts:150个科幻故事的前提,选择每个前提对应的高质量的补全回答作为response,添加到training set。
- 手动编写的示例
- 我们将作者划分为GroupA和GroupB,每组分别创作250个prompts,从GroupA中选择200个放入training set,50个放入dev set(不参与训练过程);GroupB中过滤后的230个prompts放入test set。
- 我们自己编写了200个高质量回答的训练样本。
- 我们增加了13个有害或恶意的样本到training set,并精心设计了拒绝回答这些样本的答案。增加30个类似样本在test set中
- 我们从SNI数据集中随机采样50个训练样本放入training set,包括文本摘要、风格转换各种NLP任务。
3.3 训练
在LLaMA[1]语言模型的基础上,我们用上述prompts对齐数据进行微调,得到我们的LIMA(Less Is More for Alignment)模型。
4 数值实验
我们采用了两种方法评估LIMA:针对每组prompt,让LIMA与其它语言模型(Alpaca,DaVinci003,Bard,Claude,GPT-4)同时生成回答,人类去评估哪一个更好;针对每组prompt,让LIMA与其它语言模型(Alpaca,DaVinci003)同时生成回答,GPT-4去评估哪一个更好。下图可以看到,无论是人类还是GPT-4,LIMA在50%以上的情况是优于或等于Alpaca和DaVinci003的。值得注意的是,GPT-4有19%的情况下认为LIMA优于GPT-4自己产生的答案。
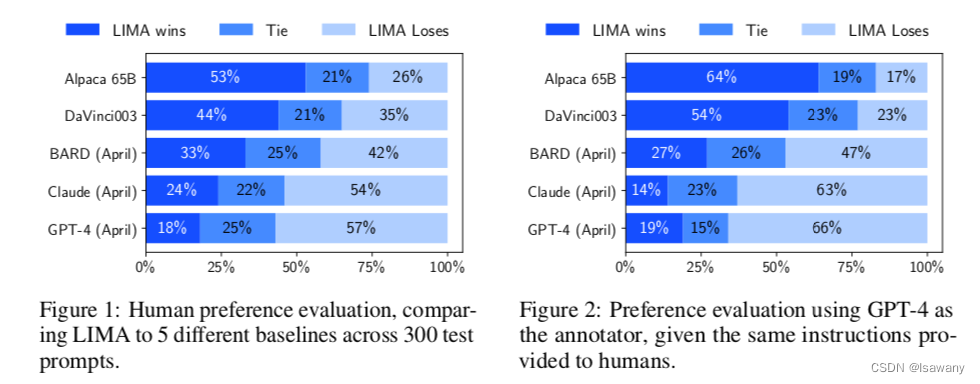
5. 文章亮点
文章基于表面对齐假设,给出了一种仅基于1000个对齐样本微调的大模型LIMA。LIMA在人类偏好度/GPT-4偏好度上的表现优于Alpaca 55B和DaVinci003。文章认为对齐样本并非越多越好,对齐的能力可能还与样本的多样性和质量有关,这可能是下一代语言模型对齐可以重点优化的方向。
5. 原文传送门
LIMA: Less Is More for Alignment
6. References
[1] 论文笔记–LLaMA: Open and Efficient Foundation Language Models