目录
- 一、为什么要有协程?
- 二、协程的原语操作
- 1、基本操作
- 2、让出(yield)和恢复(resume)
- 三、协程的切换(switch)
- 1、汇编
- 2、ucontext
- 3、longjmp / setjmp
- 四、协程结构的定义
- 五、协程调度器结构的定义
- 六、调度策略
- 七、如何与posix api 兼容
- 八、协程多核模式
一、为什么要有协程?
以DNS请求为例子,客户端向服务器发送域名,服务器回复该域名对应得IP地址。
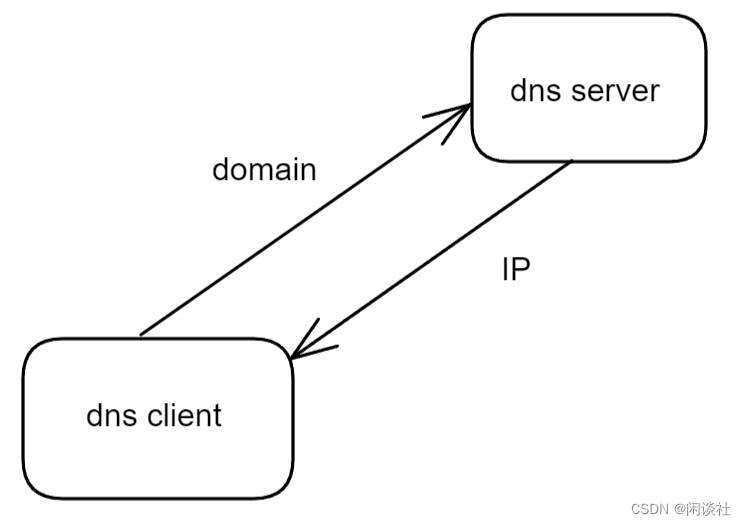
在Linux下,常使用IO多路复用器epoll来管理客户端连接,其主循环框架如下
while (1){
int nready = epoll_wait(epfd, events, EVENT_SIZE, -1);
int i=0;
for (i=0; i<nready; i++){
int sockfd = events[i].data.fd;
if (sockfd == listenfd){
int connfd = accept(listenfd, addr, &addr_len);
setnonblock(connfd); //置为非阻塞
ev.events = EPOLLIN | EPOLLET;
ev.data.fd = connfd;
epoll_ctl(epfd, EPOLL_CTL_ADD,connfd,&ev);
}else{
handel(sockfd); //进行读写操作
}
}
}
对于handel(sockfd)有两种处理方式:同步以及异步。
同步
handle(sockfd)函数内部对 sockfd 进行读写动作,并且handle 的 io 操作(send,recv)与 epoll_wait 是在同一个处理流程里面的,即IO 同步操作。
int handle(int sockfd) {
recv(sockfd, rbuffer, length, 0);
parser_proto(rbuffer, length);
send(sockfd, sbuffer, length, 0);
}
异步
handle(sockfd)函数内部将 sockfd 的操作,push 到线程池中。handle函数是将 sockfd 处理方式放到另一个已经其他的线程中运行,如此做法,将 io 操作(recv,send)与 epoll_wait 不在一个处理流程里面,使得 io操作(recv,send)与 epoll_wait 实现解耦,即 IO 异步操作。
int thread_cb(int sockfd) {
// 此函数是在线程池创建的线程中运行。
// 与 handle 不在一个线程上下文中运行
recv(sockfd, rbuffer, length, 0);
parser_proto(rbuffer, length);
send(sockfd, sbuffer, length, 0);
}
int handle(int sockfd) {
//此函数在主线程 main_thread 中运行
push_thread(sockfd, thread_cb); //将 sockfd 放到其他线程中运行。
}
对比

这样子,自然希望有一种方法,能有同步的代码逻辑,异步的性能,来方便编程人员对 IO 操作的。这就是一种轻量级的协程,在每次 send 或者 recv 之前进行切换,再由调度器来处理 epoll_wait 的流程。
二、协程的原语操作
协程的实现原理是在单个线程中创建多个协程,并通过“切换”的方式来实现协程之间的调度。协程之间的切换是由程序自己控制的,比线程切换更加快速和高效。协程通常不会阻塞整个线程,而只会阻塞当前的协程,因此可以大幅度降低线程的切换开销,提高程序的执行效率。
1、基本操作
协程包括三大部分:协程的创建、协程的调度器、协程的切换。
创建协程之后,将协程加入调度器,由调度器统一管理,决定执行顺序。
在遇到IO操作之前,协程让出(yield)执行权,交由调度器决定下一个恢复(resume)加载执行的协程。执行完成(或者未就绪)之后,协程再次让出(yield)执行权交给调度器。
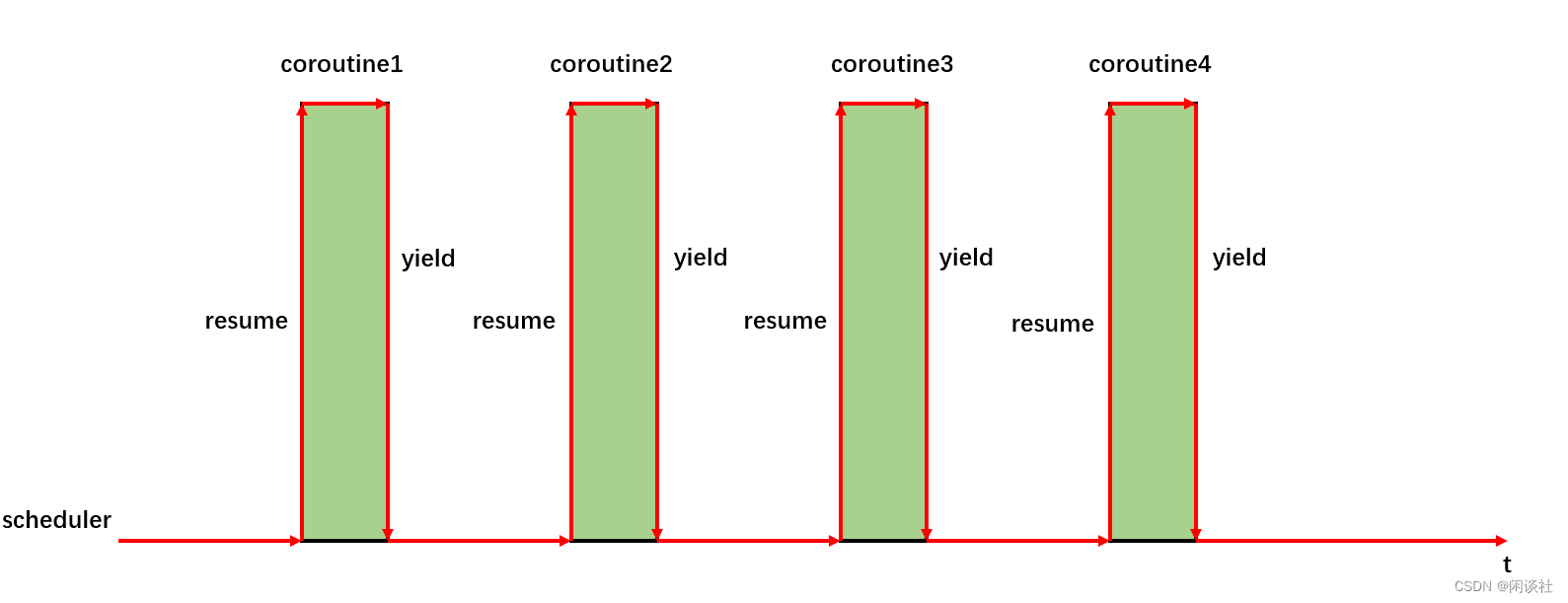
整体感觉便是调度器将时间划分成不同的时间片,每个时间片交由不同协程完成具体操作。当操作完成或没有操作时,运行权移交给调度器控制。
因此,协程的核心原语操作有:创建(create)、让出(yield)、恢复(resume)
create:创建协程。
yield:由当前协程的上下文切换到调度器的上下文。
resume:由调度器获取下一个将要执行的协程的上下文,恢复协程的运行权。
2、让出(yield)和恢复(resume)
async_Recv(fd, buffer, length) {
ret = poll(fd); //判断fd是否就绪
//若未就绪,重新加入到epoll,并切换到下一个协程
if (ret == notReady) {
epoll_ctl(add);
yield (next_fd); //resume
}
else {
recv;
}
}
async_Send(fd, buffer, length) {
ret = poll(fd); //判断fd是否就绪
//若未就绪,重新加入到epoll,并切换到下一个协程
if (ret == notReady) {
epoll_ctl(add);
yield(next_fd); //resume
}
else {
send;
}
}
while (1) {
epool_wait();
for () {
async_Recv(fd, buffer, length);
parse(buffer); //解析
async_Send(fd, buffer, length);
}
}
三、协程的切换(switch)
协程的切换有三种方式:
1、汇编
2、ucontext
3、longjmp / setjmp
1、汇编
x86_64 的寄存器有 16 个 64 位寄存器,分别是:%rax, %rbx, %rcx, %esi, %edi, %rbp, %rsp, %r8, %r9, %r10, %r11, %r12,%r13, %r14, %r15。
%rax:存储函数的返回值;
%rdi,%rsi,%rdx,%rcx,%r8,%r9:函数的六个参数,依次对应第 1 参数,第 2 参数。如果函数的参数超过六个,那么六个以后的参数会入栈。
%rbp:栈指针寄存器,指向栈底;
%rsp:栈指针寄存器,指向栈顶。
其余的用作数据存储。
上下文切换,就是将CPU的寄存器暂存,再将即将运行的协程的上下文寄存器分别mov到相应的寄存器上。
切换_switch 函数定义:
int _switch(nty_cpu_ctx *new_ctx, nty_cpu_ctx *cur_ctx);
参数 1:即将运行协程的上下文
参数 2:正在运行协程的上下文
按照 x86_64 的寄存器定义,%rdi 保存第一个参数的值,即 new_ctx 的值,%rsi 保存第二
个参数的值,即保存 cur_ctx 的值。
__asm__ (
" .text \n"
" .p2align 4,,15 \n"
".globl _switch \n"
".globl __switch \n"
"_switch: \n"
"__switch: \n"
" movq %rsp, 0(%rsi) # save stack_pointer \n"
" movq %rbp, 8(%rsi) # save frame_pointer \n"
" movq (%rsp), %rax # save insn_pointer \n"
" movq %rax, 16(%rsi) \n"
" movq %rbx, 24(%rsi) # save rbx,r12-r15 \n"
" movq %r12, 32(%rsi) \n"
" movq %r13, 40(%rsi) \n"
" movq %r14, 48(%rsi) \n"
" movq %r15, 56(%rsi) \n"
" movq 56(%rdi), %r15 \n"
" movq 48(%rdi), %r14 \n"
" movq 40(%rdi), %r13 # restore rbx,r12-r15 \n"
" movq 32(%rdi), %r12 \n"
" movq 24(%rdi), %rbx \n"
" movq 8(%rdi), %rbp # restore frame_pointer \n"
" movq 0(%rdi), %rsp # restore stack_pointer \n"
" movq 16(%rdi), %rax # restore insn_pointer \n"
" movq %rax, (%rsp) \n"
" ret \n"
);
2、ucontext
getcontext、makecontext、swapcontext是一组操作上下文(context)的函数,一般用于在用户层级(user space)线程中实现协程(coroutine)。
(1)getcontext(ucontext_t *ucp):该函数会获取当前线程的上下文,并将其保存到ucontext_t类型的结构体指针ucp中,以便后续使用。
(2)makecontext(ucontext_t *ucp, void (*func)(), int argc, ...):创建一个新的执行上下文,并将其与func函数关联,argc表示func函数的参数个数,后面的省略号表示具体的函数参数。通常情况下,我们需要先调用getcontext获取当前线程的上下文,然后再通过makecontext创建一个新的上下文,该上下文可以通过swapcontext函数来激活,并开始执行func函数。
(3)swapcontext(ucontext_t *oucp, const ucontext_t *ucp):用于切换两个不同上下文之间的控制流。oucp和ucp分别表示当前和目标上下文。当调用该函数时,程序会保存当前上下文并开始执行ucp所指定的上下文。
// getcontext(&context);
// makecontext(&context, func, arg);
// swapcontext(&curent_context, &next_context);
#include <stdio.h>
#include <ucontext.h>
ucontext_t ctx[2];
ucontext_t main_ctx;
int count = 0;
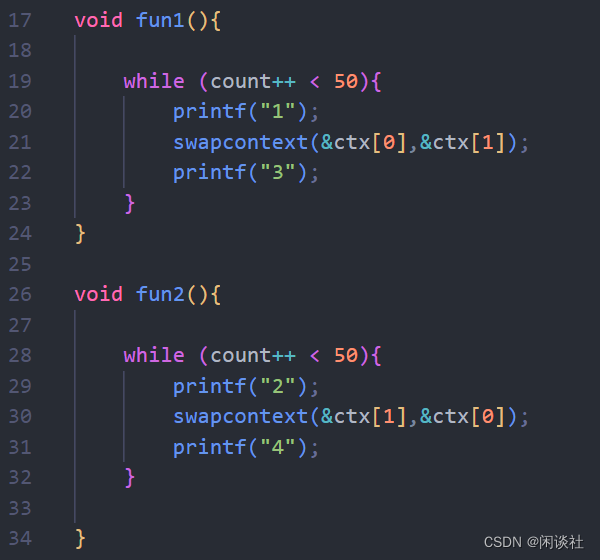
void fun1(){
while (count++ < 50){
printf("1");
swapcontext(&ctx[0],&ctx[1]);
printf("3");
}
}
void fun2(){
while (count++ < 50){
printf("2");
swapcontext(&ctx[1],&ctx[0]);
printf("4");
}
}
int main(){
char stack1[2048] = {0};
char stack2[2048] = {0};
getcontext(&ctx[0]);
//将用户上下文ctx[1]的栈空间(stack)指针指向了一个已预先分配的内存块stack1
ctx[0].uc_stack.ss_sp = stack1;
//将栈空间的大小设置为stack1的大小,也就是在此处分配的内存块大小。
ctx[0].uc_stack.ss_size = sizeof(stack1);
//将链接指针(link pointer)设置为main_ctx,也就是当执行完当前上下文时,
//程序将会切换回main_ctx所指定的上下文。链接指针用于实现协程(coroutine)之间的切换。
ctx[0].uc_link = &main_ctx;
makecontext(&ctx[0], fun1 ,0);
getcontext(&ctx[1]);
ctx[1].uc_stack.ss_sp = stack1;
ctx[1].uc_stack.ss_size = sizeof(stack1);
ctx[1].uc_link = &main_ctx;
makecontext(&ctx[1], fun2 ,0);
printf("swapcontext\n");
swapcontext(&main_ctx, &ctx[0]);
printf("\n");
}
结果是
123142314231423142314231423142314231423142314231423142314231423142314231423142314231423142314231423
执行顺序是:
p19 -> p20 -> p21 -> p28 -> p29 -> p30 -> p21 -> p22 -> p19 -> p20 -> p21 -> p30 -> p31 -> p28 -> p29 -> p30 -> p21 -> p22 -> p19 -> p20 -> p21 -> p30 -> p31 -> ……
3、longjmp / setjmp
setjmp 和 longjmp 是两个用于非局部跳转(non-local jump)的 C 语言库函数。
(1)int setjmp(jmp_buf env);:保存当前程序上下文信息到env,并返回0;
(2)void longjmp(jmp_buf env, int val);:直接跳转到该跳转点env的位置,并且恢复该跳转点env的状态。还可以传递一个整数值val,用于作为 setjmp 函数的返回值。
#include <stdio.h>
#include <setjmp.h>
jmp_buf env;
void func(int arg){
printf("func\n");
longjmp(env, ++arg);
printf("longjmp complete\n"); //由于longjmp是非局部跳转操作,所以之前在func函数中的printf语句不会被执行。
}
int main(){
int ret = setjmp(env);
if (ret == 0){
printf("ret == 0\n");
func(ret);
}else if (ret == 1){
printf("ret == 1\n");
func(ret);
}
printf("ret:%d\n",ret);
}
执行结果是
ret == 0
func
ret == 1
func
ret:2
执行顺序
1、在main函数中使用setjmp函数保存当前程序状态。
2、在main函数中判断setjmp返回值ret,如果为0,则说明是第一次调用,执行func函数并将ret作为参数传递;否则,说明是通过longjmp跳转回来的,继续执行func函数。
3、在func函数中,先输出"func",然后通过longjmp跳转回到setjmp处,并将arg+1作为返回值。由于longjmp是非局部跳转操作,所以之前在func函数中的printf语句不会被执行。
4、最终,在main函数结束时输出ret的值
四、协程结构的定义
//协程的状态
typedef enum _co_status {
CO_NEW, //新建
CO_READY, // 就绪
CO_WAIT, //等待
CO_SLEEP, //睡眠
CO_EXIT, //退出
} co_status_t;
struct coroutine {
int birth; //协程创建的时间
int coid; //协程的id
struct context ctx; //上下文信息
struct scheduler* sched; //调度器
void* (*entry)(void*); //回调函数入口
void *arg; //回调函数的参数
void* stack; //独立栈(每个协程有自己的虚拟内存空间) 或 共享栈
size_t size; //栈的大小
co_status_t status; //协程的状态
queue_node(coroutine) readyq;
rbtree_node(coroutine) sleept;
rbtree_node(coroutine) waitt;
queue__node(coroutine) exitq;
};
五、协程调度器结构的定义
struct scheduler {
struct coroutine* cur_co; //当前运行的协程
queue_head(coroutine) readyh;
rbtree_root(coroutine) sleepr;
rbtree_root(coroutine) waitr;
queue_head(coroutine) exith;
};
六、调度策略
调度策略:
1、IO密集型(更多强调IO等待)-- > 把wait放在最前面,把sleep放在最后面
2、计算密集型(更多强调计算结果) --> 把ready放在最前面
schedule(struct schedule* sched) {
coroutine* co = NULL;
while ((co = get_expired_node(sched->sleepr)) != NULL) {
resume(co);
}
while ((co = get_wait_node(sched->waitq)) != NULL) {
push_ready_queue(co);
}
whike((co = get_next_node(sched->readyq)) != NULL) {
resume(co);
}
whike((co = get_next_node(sched->exitq)) != NULL) {
destroy(co);
}
}
七、如何与posix api 兼容
利用hook技术,可以在实现协程的时候与本系统的API实现兼容。
主要函数是dlsym函数
dlsym函数是一个动态链接库函数,它的作用是在动态链接库中查找指定的符号,并返回符号对应的地址。
void *dlsym(void *handle, const char *symbol);
举个例子,连接mysql的时候,我们通过使用hook技术,使得实际执行的connect、recv、send是经过我们重定义后的。
zxm@ubuntu:~/share/opp$ gcc -o mysql mysql.c -lmysqlclient -ldl
zxm@ubuntu:~/share/opp$ ./mysql
connect
recv
send
mysql_real_connect success
#define _GNU_SOURCE
#include <dlfcn.h>
#include <stdio.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <mysql/mysql.h>
#define __INIT_HOOK__ init_hook();
#define MING_DB_IP "192.168.42.128"
#define MING_DB_PORT 3306
#define MING_DB_USENAME "admin"
#define MING_DB_PASSWORD "123456"
#define MING_DB_DEFAULTDB "MING_DB"
typedef int (*connect_t)(int sockfd, const struct sockaddr *addr,socklen_t addrlen);
connect_t connect_f = NULL;
typedef ssize_t (*recv_t)(int sockfd, void *buf, size_t len, int flags);
recv_t recv_f = NULL;
typedef ssize_t (*send_t)(int sockfd, const void *buf, size_t len, int flags);
send_t send_f = NULL;
int connect(int sockfd, const struct sockaddr *addr,socklen_t addrlen){
printf("connect\n");
return connect_f(sockfd, addr, addrlen);
}
ssize_t recv(int sockfd, void *buf, size_t len, int flags){
printf("recv\n");
return recv_f(sockfd,buf, len, flags );
}
ssize_t send(int sockfd,const void *buf, size_t len, int flags){
printf("send\n");
return send_f(sockfd ,buf, len, flags );
}
void init_hook(void){
if (!connect_f){
connect_f = dlsym(RTLD_NEXT,"connect");
}
if (!recv_f){
recv_f = dlsym(RTLD_NEXT,"recv");
}
if (!send_f){
send_f = dlsym(RTLD_NEXT,"send");
}
}
int main () {
__INIT_HOOK__;
MYSQL *mysql = mysql_init(NULL); // 初始化MYSQL结构体,返回一个指向MYSQL结构体的指针
if (!mysql){
printf("musql_init failed\n");
return 0;
}
if (!mysql_real_connect(mysql,MING_DB_IP,MING_DB_USENAME,MING_DB_PASSWORD,MING_DB_DEFAULTDB,
MING_DB_PORT,NULL,CLIENT_FOUND_ROWS)){
printf("mysql_real_connect failed\n");
return 0;
}
printf("mysql_real_connect success\n");
}
八、协程多核模式
可将某个计算与某个cpu绑定黏合在一起,有利于计算密集型。
比如对于多进程/多线程与多核的黏合,可以为每个进程或者线程,分配一个调度器。
//线程绑定
Thread 3 is running on cpu
Thread 2 is running on cpu
Thread 1 is running on cpu
Thread 0 is running on cpu
//进程绑定
Process 31690 is running on cpu
Process 31691 is running on cpu
Process 31692 is running on cpu
Process 31693 is running on cpu
#define _GNU_SOURCE
#include <stdio.h>
#include <pthread.h>
#include <sched.h>
#include <unistd.h>
#include <sys/syscall.h>
#define THREAD_COUNT 2
void *thread_func(void *arg){
int threadid = *(int *)arg;
printf("Thread %d is running on cpu \n",threadid);
while (1);
}
int process_bind(void) {
int num = sysconf(_SC_NPROCESSORS_CONF); // //返回当前系统中可用的CPU核心数量
pid_t self_id = syscall(__NR_gettid);
cpu_set_t mask;
CPU_ZERO(&mask);
CPU_SET(self_id % num, &mask);
sched_setaffinity(0, sizeof(mask), &mask);
printf("Process %d is running on cpu\n", self_id);
while (1) ;
}
int main(){
#if 0 // 线程绑定
pthread_t threads[THREAD_COUNT];
int threadid[THREAD_COUNT];
//定义了一个 cpu_set_t 类型的变量 cpus,它是一个位图,每一位代表一个 CPU 核心
cpu_set_t cpus;
//通过调用 CPU_ZERO(&cpus) 函数将其清零。
CPU_ZERO(&cpus);
int i=0;
for (i=0; i< THREAD_COUNT; i++){
//将下标 i 对应的 CPU 核心编号添加到 cpus 变量中
CPU_SET(i,&cpus);
}
for (i=0;i< THREAD_COUNT; i++){
threadid[i] = i;
pthread_create(&threads[i], NULL , thread_func, &threadid[i]);
// 将第 i 个线程绑定到第 i 个 CPU 上
pthread_setaffinity_np (threads[i], sizeof(cpu_set_t), &cpus);
}
for (i=0; i< THREAD_COUNT; i++){
pthread_join (threads[i],NULL);
}
#else //进程绑定
fork();
fork();
process_bind();
#endif
return 0;
}
·······················································································································