环境准备
首先需要将如下四个必要的文件下载到计算机(已经附上了下载地址,点击即可下载)。
Vmware Workstation 17.x 【官方的下载地址】
CentOS-7-x86_64-Minimal-2009【阿里云镜像站下载地址】
openjdk-8u41-b04-linux-x64-14_jan_2020【开源下载地址】
安装 CentOS 7
在安装了 Vmware Workstation 17 后,接下来就可开始安装由阿里云镜像站提供的CentOS7。步骤如下:
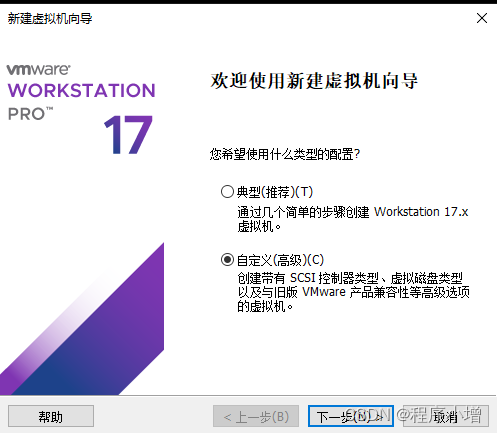
1.文件 → 新建虚拟机,进入到【新建虚拟机向导】界面,选择自定义配置,如下所示:
2.点击下一步,进入选择虚拟机硬件兼容性
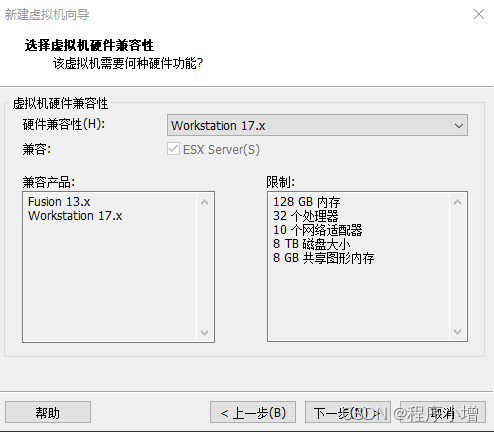
3.点击下一步,进入安装客户端操作系统,选择稍后安装操作系统
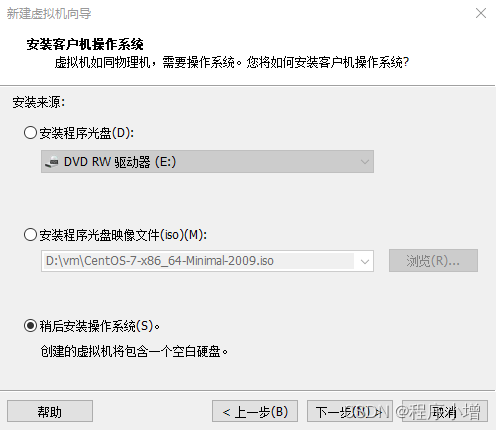
4.点击下一步,进入选择客户端操作系统,选择如下:
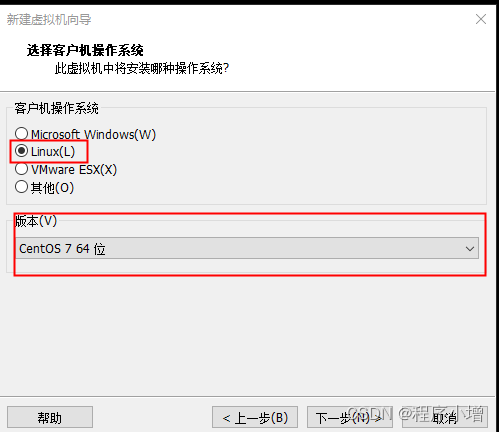
5.点击下一步,命名虚拟机
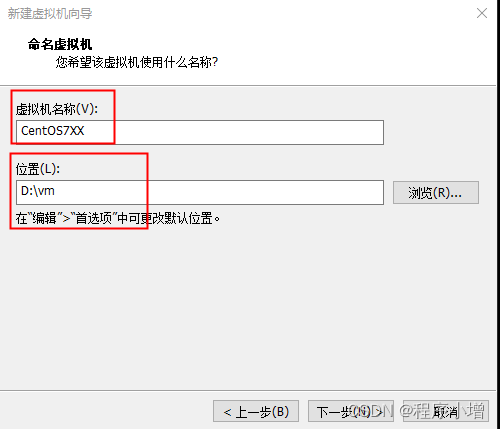
6.点击下一步,处理器配置
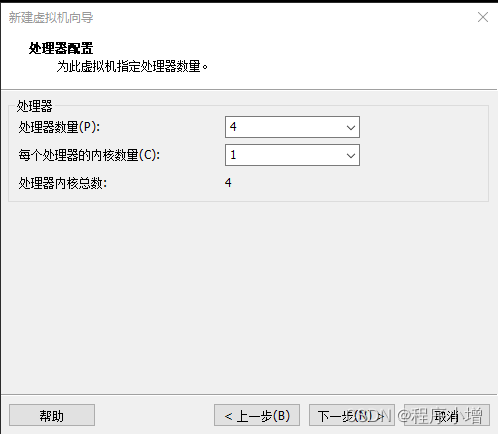
7.点击下一步,此虚拟机的内存选择
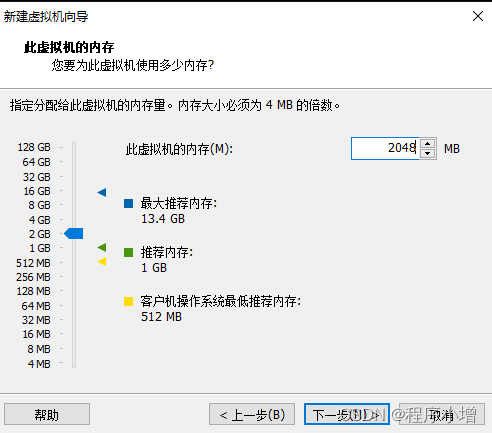
8.点击下一步,选择网络类型
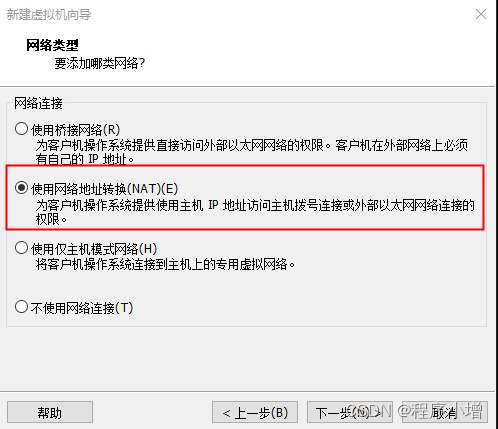
9.点击下一步,选择I/O控制器类型
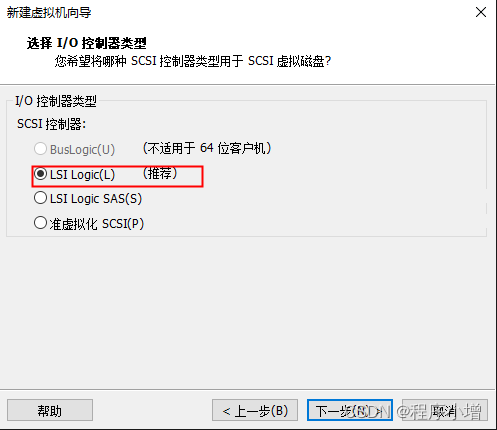
10.点击下一步,选择磁盘类型
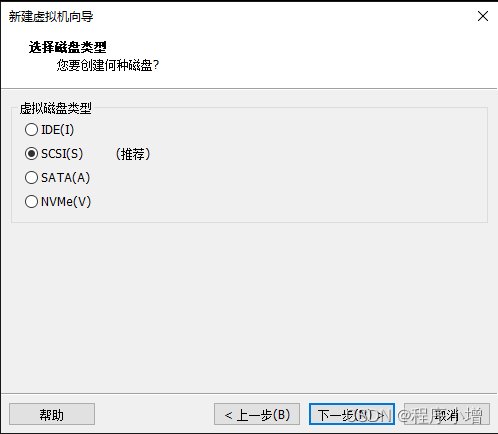
11.点击下一步,选择磁盘
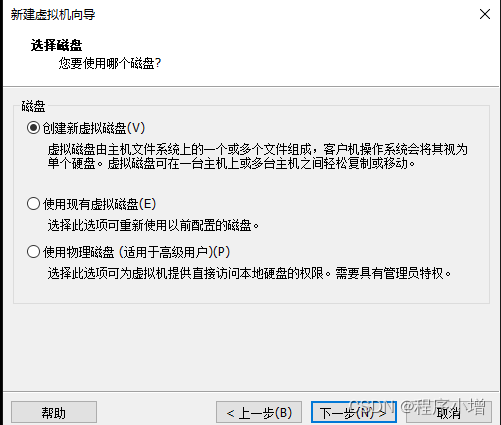
12.点击下一步,指定磁盘容量
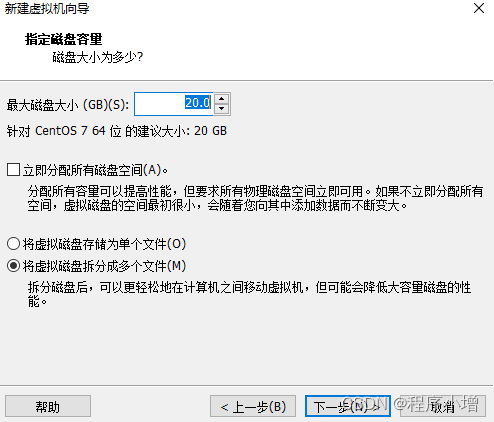
13.点击下一步,指定磁盘文件
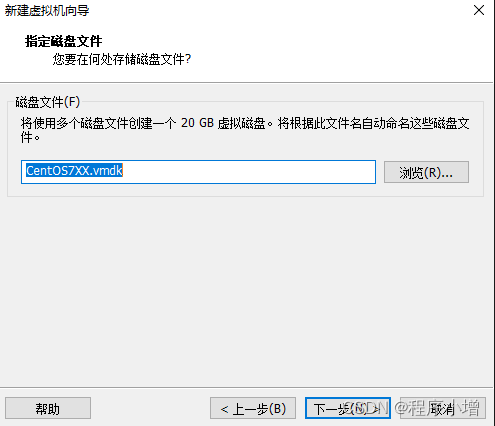
14.点击下一步,已准备好创建虚拟机
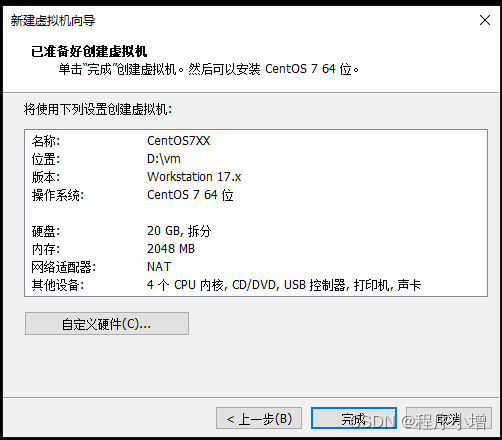
15.点击完成
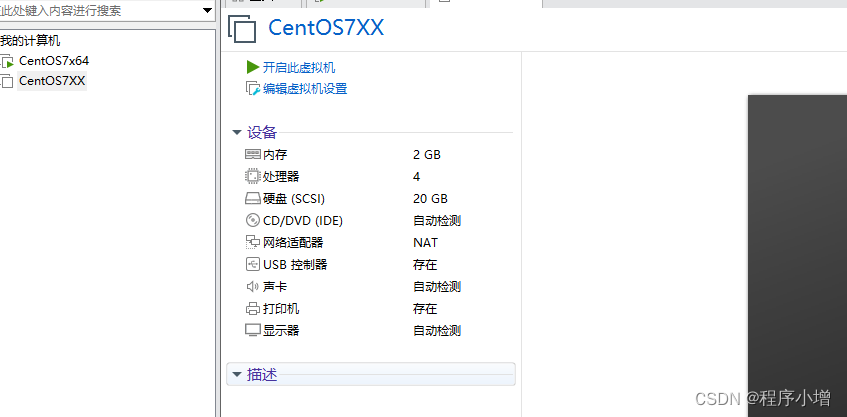
16.点击编辑虚拟机设置
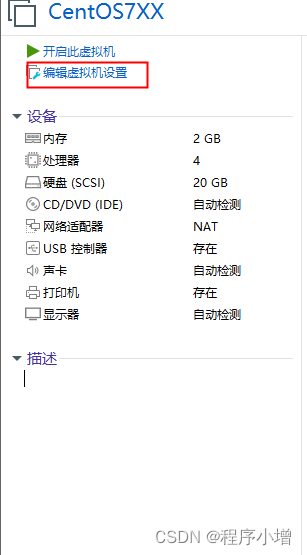
17.选择CD/DVD,选择我们下载的ISO映像文件,点击确定
18.点击开启此虚拟机,快捷键 Ctrl + B。
19.开机之后,通过方向键 ↑ 使得Install CentOS 7 菜单高亮选中,并按下回车键确认。
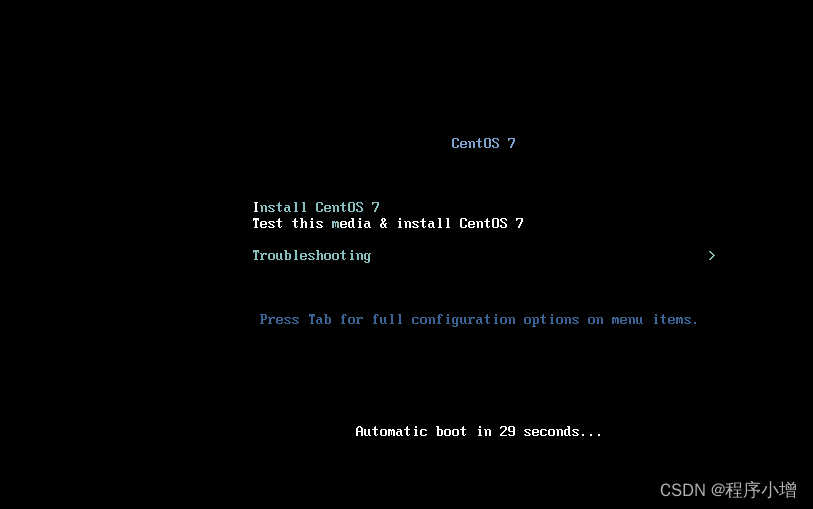
20.安装 CentOS 出现的第一个界面是欢迎页面,我们需要在整个安装期间选择一个语言。默认的语言是美式英文。(如果想要换成中文可以搜索)
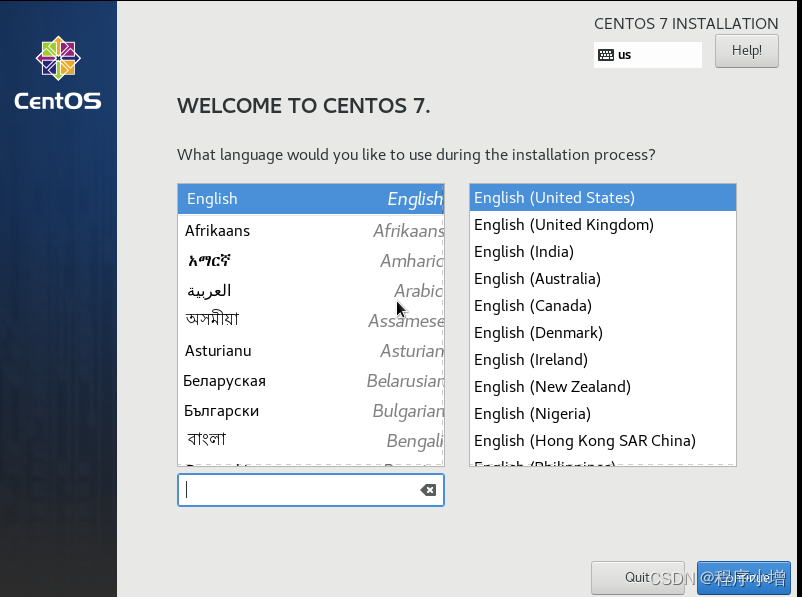
21.点击Continue进入,进入设置页面,先设置时间
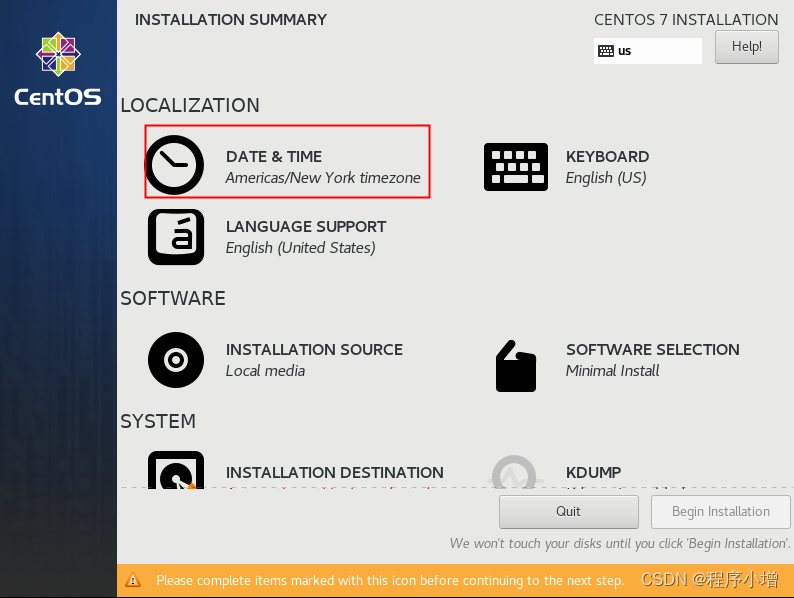
选择上海时间,点击Done返回总设置页面
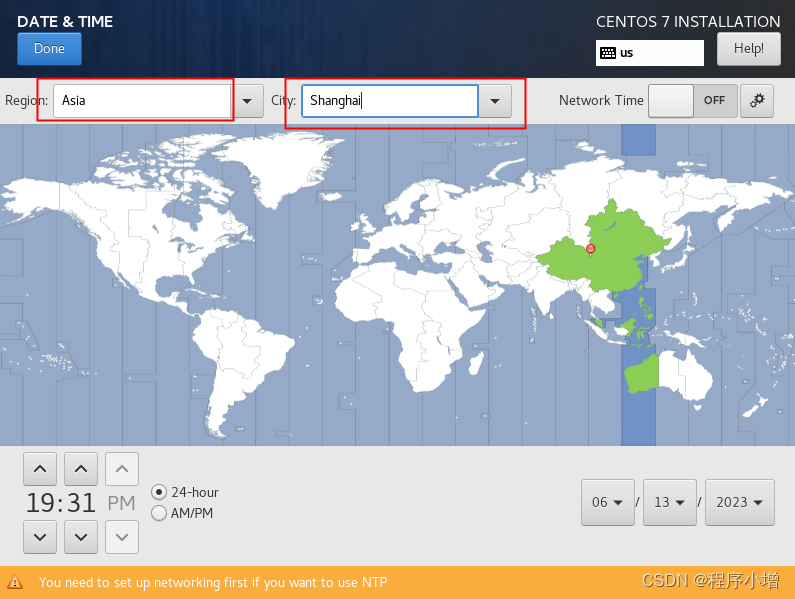
选择SYSTEM中带有感叹号的INSTALLATION DESTINATION配置的是系统的安装位置和网络主机名
根据需要来配置磁盘或者分区。我这里不做任何的修改,直接点击【Done】按钮。回到配置页面
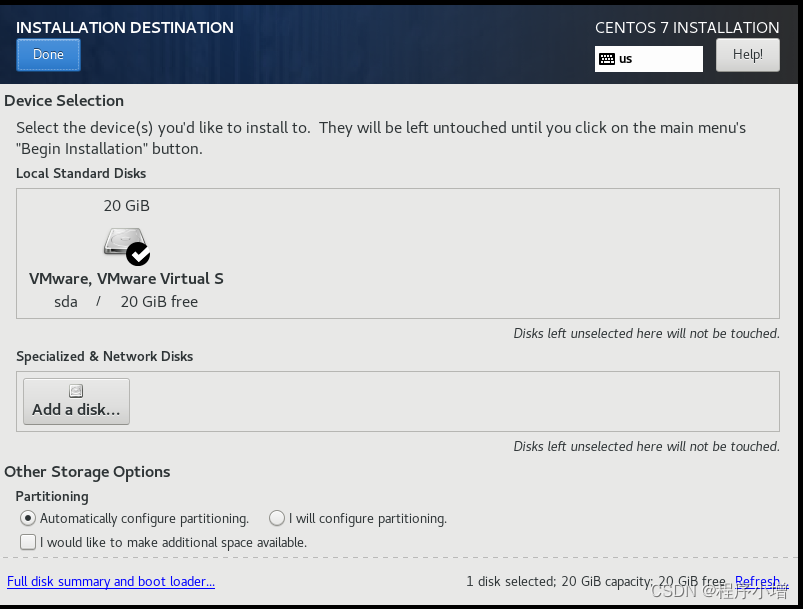
回到安装信息摘要界面,点击NETWORK & HOST NAME。在安装之初,就设置好这些,避免开机之后还要设置网络信息。
接下来进度网络配置,我们需要在这里配置网卡信息和主机名信息,首先,点击以太网右侧的开关,以启动网卡.
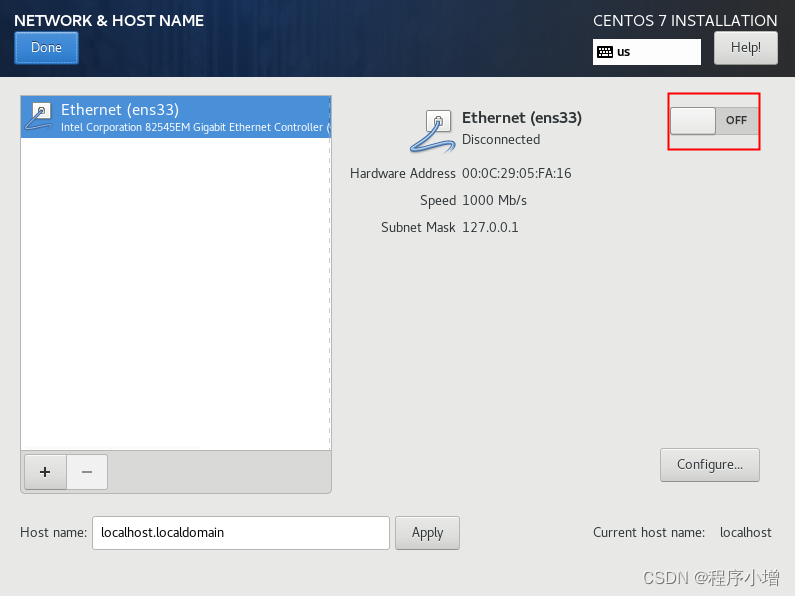
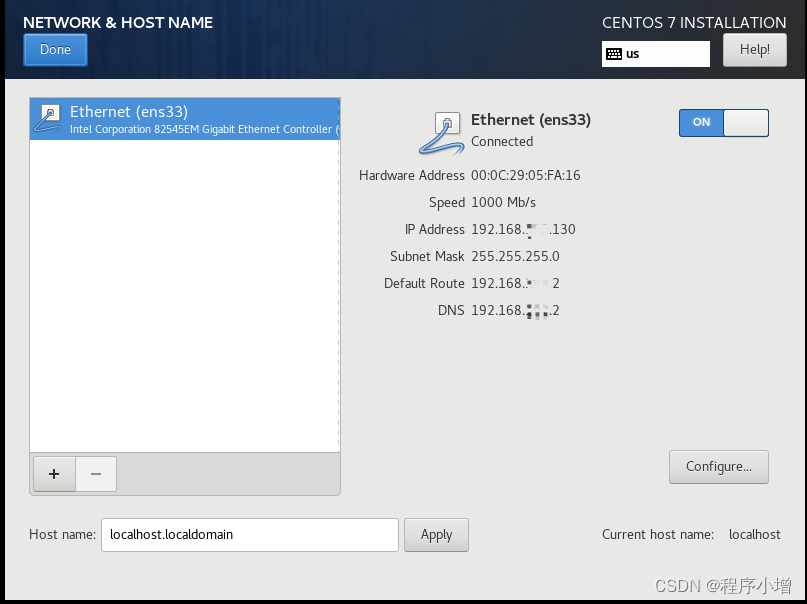
这里的IP地址是通过DHCP自动获取的,不能保证每次开机它的IP是固定的,为了方便后面做集群的配置,这里可以对该网卡手动设置IP 。在配置网卡信息之前,记录下此时的网卡的子网掩码、默认路由和DNS信息。点击右下方的Configure按钮,开始编辑网卡信息,在弹出的对话框中选择 【IPv4设置】选项卡。
在配置 IP 地址的时候,需要注意的是,需要考虑到网段要和真实机保持一致,因为前面创建虚拟机时,采用了网络地址转换的连接方式,默认情况下,真实机使用的网卡是 VMware Network Adapter VMnet8 网卡
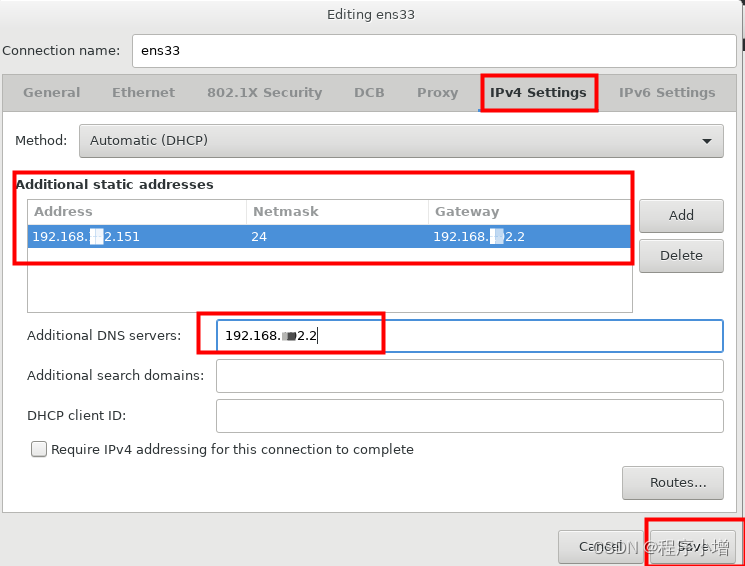
点击保存后可以看到这个ip已经变成我们修改的ip
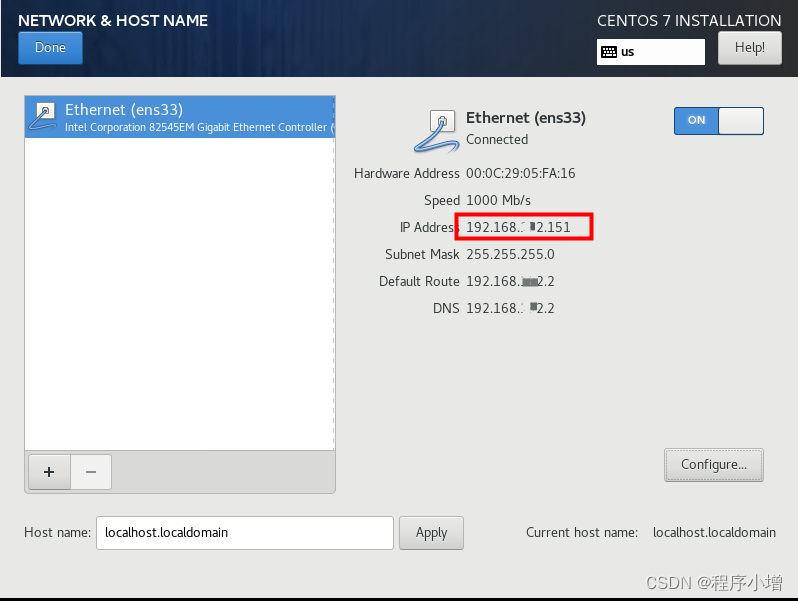
接下来修改最底下的主机名处,将输入框中的主机名修改为方便好记的主机名,以便于后面通过 ssh 进行登录。因为我使用的 CentOS 7。而且是为了搭建 Hadoop 环境,结合我自定义的IP地址,我将其命名为 h151.c7。然后点击应用,就可以发现右下角的 localhost就会发生变化。最后,点击左上角的Done按钮,以完成配置。
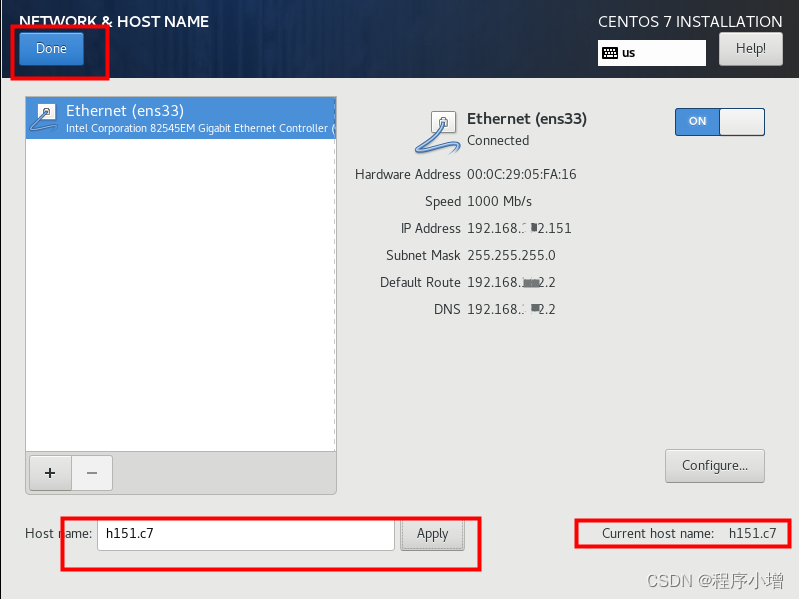
点击Done后返回配置页面,然后点击BeginInstallation按钮开始安装
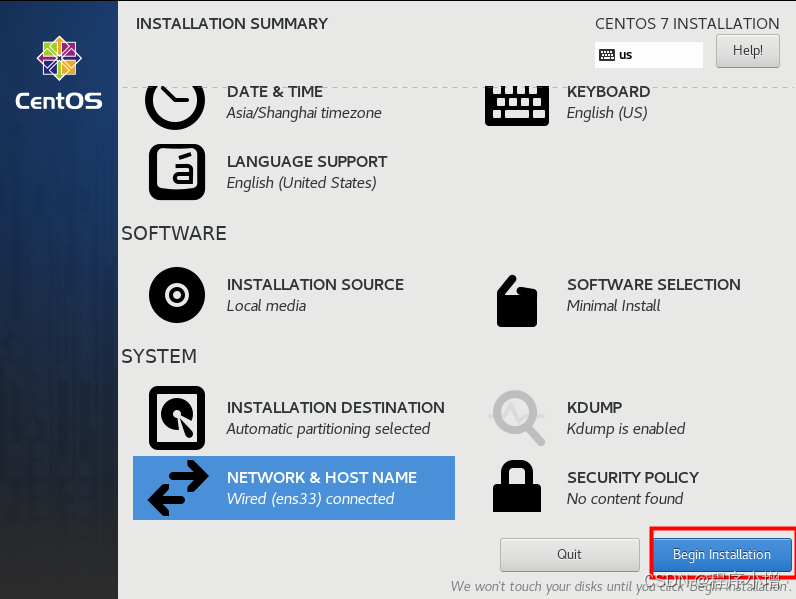
22.点击完上面的安装后进入修改密码页面然后点击ROOT PASSWORD进行密码设置
输入设置的新密码 点击Done完成密码设置
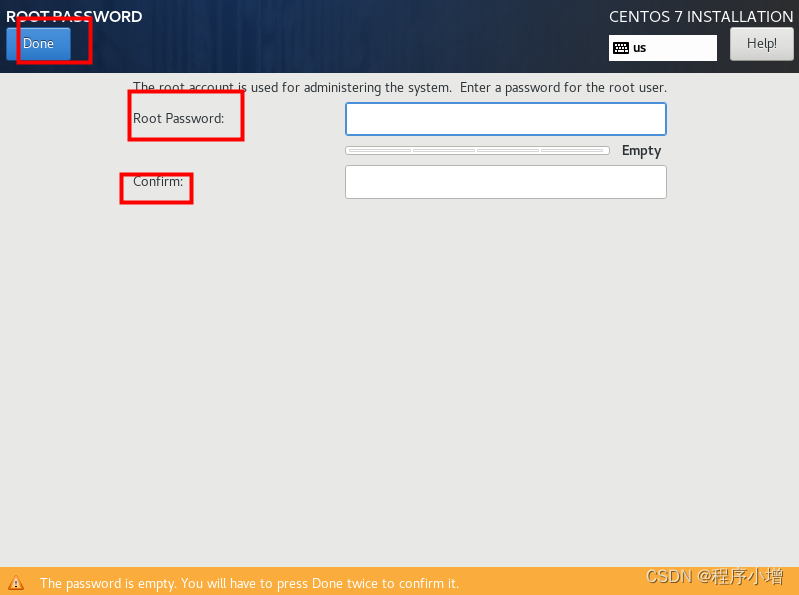
23.回到安装界面,如果出现如下提示,点击【Reboot】按钮即可,出现这个界面可能是因为配置密码的时候,花的时间较长导致。
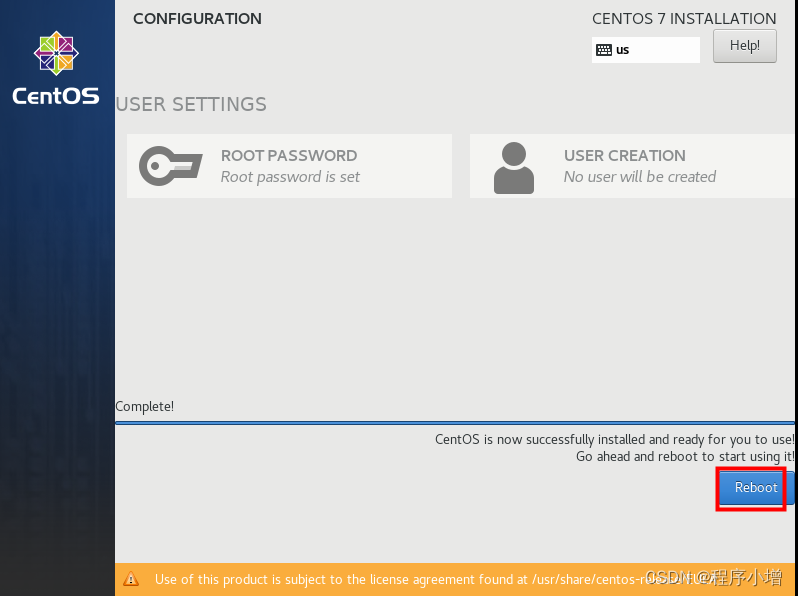
24.安装 CentOS的最后一个界面如下,点击重启以完成系统的安装。
25.重启之后,可以使用 Xshell 或者 MobaXterm等远程工具进行登录了。
26.配置 yum 源
刚安装的 CentOS 要做的第一件事就是将 yum 源配置为阿里云的镜像,以方便后面安装软件的时候提升响应速度。通过 curl 下载阿里云的 yum 源配置文件:
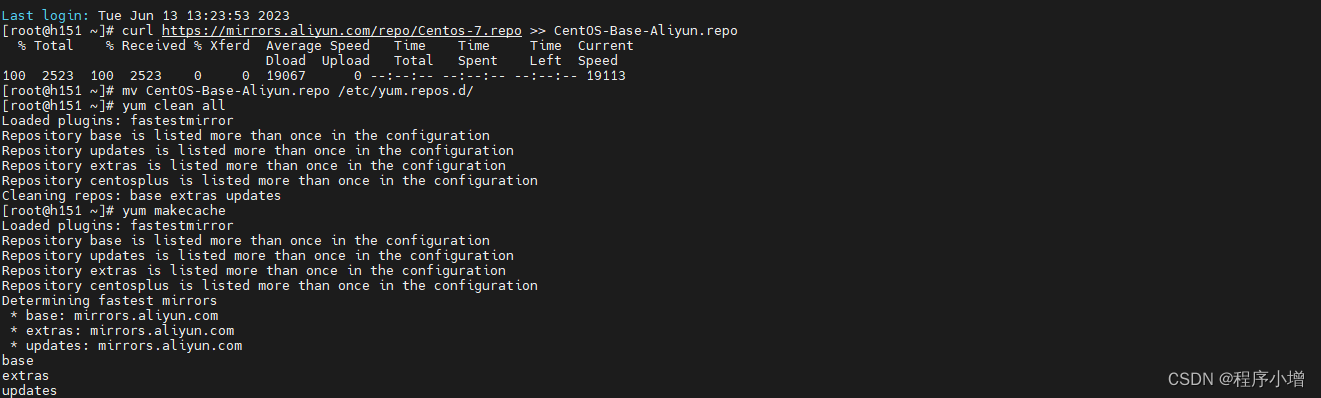
[root@h151 ~]# curl https://mirrors.aliyun.com/repo/Centos-7.repo >> CentOS-Base-Aliyun.repo
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 2523 100 2523 0 0 19067 0 --:--:-- --:--:-- --:--:-- 19113
[root@h151 ~]# mv CentOS-Base-Aliyun.repo /etc/yum.repos.d/
[root@h151 ~]# yum clean all
Loaded plugins: fastestmirror
Repository base is listed more than once in the configuration
Repository updates is listed more than once in the configuration
Repository extras is listed more than once in the configuration
Repository centosplus is listed more than once in the configuration
Cleaning repos: base extras updates
[root@h151 ~]# yum makecache
Loaded plugins: fastestmirror
Repository base is listed more than once in the configuration
Repository updates is listed more than once in the configuration
Repository extras is listed more than once in the configuration
Repository centosplus is listed more than once in the configuration
Determining fastest mirrors
* base: mirrors.aliyun.com
* extras: mirrors.aliyun.com
* updates: mirrors.aliyun.com
添加一个可以使用table补齐的插件重启后可生效
yum -y install bash-completion
27.安装jdk,这里为了方便安装hadoop时使用所有安装的是jdk1.8,可以通过命令进行安装
下载后可解压至对应的目录中
[root@h151 ~]# curl -# https://download.java.net/openjdk/jdk8u41/ri/openjdk-8u41-b04-linux-x64-14_jan_2020.tar.gz >> java-se-8u41-ri.tar.gz
######################################################################## 100.0%
[root@h151 ~]# tar -zxf java-se-8u41-ri.tar.gz -C /opt/
[root@h151 ~]# vi /etc/profile
添加jdk的环境变量 vi /etc/profile此命令是打开环境变量配置文件
export JAVA_HOME=/opt/java-se-8u41-ri/
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
配置完成后执行一下命令,使配置生效并查看jdk是否成功
[root@h151 ~]# source /etc/profile
[root@h151 ~]# java -version
openjdk version "1.8.0_41"
OpenJDK Runtime Environment (build 1.8.0_41-b04)
OpenJDK 64-Bit Server VM (build 25.40-b25, mixed mode)
安装 Hadoop (伪分布模式)
【伪分布式模 式】:
用多个线程模拟多台真实机器,即用一台主机模拟真实的分布式环境。
【完全分布式模式】:
用多台机器(或启动多个虚拟机)来完成部署集群。
1.下载安装包,并解压到指定位置。
[root@h151 ~]# curl -# https://archive.apache.org/dist/hadoop/common/hadoop-3.3.5/hadoop-3.3.5.tar.gz >> hadoop-3.3.5.tar.gz
######################################################################## 100.0%
[root@h151 ~]# tar -zxf hadoop-3.3.5.tar.gz -C /opt/
2.cd 到Hadoop下通过 vi 修改 Hadoop 下 etc/hadoop/hadoop-env.sh 文件,找到 JAVA_HOME 和 HADOOP_CONF_DIR。此处的 JAVA_HOME 的值需要和 /etc/profile 中配置的 JAVA_HOME 的值保持一致。修改后结果如下:
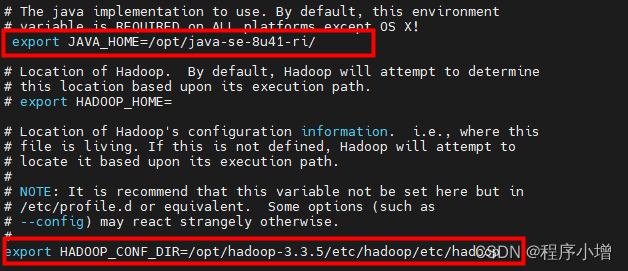
export JAVA_HOME=/opt/java-se-8u41-ri/
export HADOOP_CONF_DIR=/opt/hadoop-3.3.5/etc/hadoop/etc/hadoop
配置完成之后,使用 source 命令使其生效:
[root@h151 hadoop-3.3.5]# source /opt/hadoop-3.3.5/etc/hadoop/hadoop-env.sh
3.通过 vi 修改 Hadoop 下 etc/hadoop/core-site.xml 文件,内容如下:
<configuration>
<!-- 指定 NameNode 的主机名和端口号 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://h151.c7:9000</value>
</property>
<!--
指定 Hadoop 的临时目录
在默认情况下,该目录会存储 NameNode,DataNode 或其他模块的数据
-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-3.3.5/tmp</value>
</property>
<!-- 缓冲区大小,实际工作中根据服务器性能动态调整 -->
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<!--
开启hdfs的垃圾桶机制,删除掉的数据可以从垃圾桶中回收,单位分钟
-->
<!--
<property>
<name>fs.trash.interval</name>
<value>10080</value>
</property>
-->
</configuration>
4.通过 vi 修改 Hadoop 下 etc/hadoop/hdfs-site.xml 文件,内容如下:
<configuration>
<!--
指定 hdfs 保存数据副本的数量(包括自己),默认值是 3。
如果是伪分布模式,此值应该是 1
-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- 设置HDFS的文件权限-->
<property>
<name>dfs.permissions</name>
<value>true</value>
</property>
<!-- 设置一个文件切片的大小:128M -->
<!--
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
-->
</configuration>
5.通过 vi 修改 Hadoop 下 etc/hadoop/mapred-site.xml 文件:
[root@h151 ~]# vi /opt/hadoop-3.3.5/etc/hadoop/mapred-site.xml
修改内容:
<configuration>
<!-- 指定 MapReduce 在 Yarn 上运行 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>/opt/hadoop-3.3.5/share/hadoop/mapreduce/*, /opt/hadoop-3.3.5/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
6.通过 vi 修改 Hadoop 下 etc/hadoop/yarn-site.xml 文件。
<configuration>
<!-- 指定 Yarn 的 ResourceManager 的主机名 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>h151.c7</value>
</property>
<!-- 指定 Yarn 的 NodeManager 的获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
7.通过 vi 修改 Hadoop 下 etc/hadoop/slaves 文件。直接在该文件中输入集群中所有节点的主机名,每个主机名独占一行,因为采用的是伪 分布式模式,所以,只需要在当前文件中写入当前主机的名称即可。
[root@h151 /]# vi /opt/hadoop-3.3.5/etc/hadoop/slaves
修改后的 slaves 文件的内容如下:
h151.c7
8.在 /etc/profile 文件的最后配置 Hadoop 的环境变量,追加如下内容:
export HADOOP_HOME=/opt/hadoop-3.3.5
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
9.保存退出后使用 source 命令使 /etc/profile 文件生效。
source /etc/profile
10.通过 vi 修改 Hadoop 下 /etc/hosts 文件,追加当前主机的IP地址映射主机名。如下所示:
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.xx.151 h151.c7
11.执行如下命令对 NameNode 进行格式化。
hdfs namenode -format

12.关闭防火墙
关闭防火墙:
systemctl stop firewalld.service
关闭开机启动:
systemctl disable firewalld.service
13.:输入start-all.sh
报错问题1:
[root@h151 hadoop]# start-all.sh
Starting namenodes on [h151.c7]
ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
Starting datanodes
ERROR: Attempting to operate on hdfs datanode as root
ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation.
Starting secondary namenodes [h151.c7]
ERROR: Attempting to operate on hdfs secondarynamenode as root
ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation.
Starting resourcemanager
ERROR: Attempting to operate on yarn resourcemanager as root
ERROR: but there is no YARN_RESOURCEMANAGER_USER defined. Aborting operation.
Starting nodemanagers
ERROR: Attempting to operate on yarn nodemanager as root
ERROR: but there is no YARN_NODEMANAGER_USER defined. Aborting operation.
解决方法:
是因为缺少用户定义造成的,所以分别编辑开始和关闭脚本
cd /opt/hadoop-3.3.5目录下
$ vi sbin/start-dfs.sh
$ vi sbin/stop-dfs.sh
在顶部空白处添加内容:
HDFS_NAMENODE_USER=root
HDFS_DATANODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
YARN_RESOURCEMANAGER_USER=root
YARN_NODEMANAGER_USER=root
是因为缺少用户定义造成的,所以分别编辑开始和关闭脚本
$ vi sbin/start-yarn.sh
$ vi sbin/stop-yarn.sh
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
报错2:
WARNING: HADOOP_SECURE_DN_USER has been replaced by HDFS_DATANODE_SECURE_USER. Using value of HADOOP_SECURE_DN_USER.
Stopping namenodes on [h151.c7]
Last login: Tue Jun 13 16:07:57 CST 2023 on pts/0
h151.c7: Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password).
Stopping datanodes
Last login: Tue Jun 13 16:08:15 CST 2023 on pts/0
localhost: Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password).
Stopping secondary namenodes [h151.c7]
Last login: Tue Jun 13 16:08:16 CST 2023 on pts/0
h151.c7: Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password).
Stopping nodemanagers
ERROR: Attempting to operate on yarn nodemanager as root
ERROR: but there is no YARN_NODEMANAGER_USER defined. Aborting operation.
Stopping resourcemanager
ERROR: Attempting to operate on yarn resourcemanager as root
ERROR: but there is no YARN_RESOURCEMANAGER_USER defined. Aborting operation.
解决方法:
[root@h151 ~]# ssh-keygen -t rsa
一直回车直到显示
//输入一下命令获取秘钥
[root@h151 ~]# cat /root/.ssh/id_rsa.pub
输入一下命令将秘钥复制进去
[root@h151 ~]# vi /root/.ssh/authorized_keys
然后输入start-all.sh就可以启动成功
输入jps查看是否启动
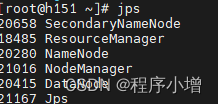
在浏览器输入ip+9870就可以访问hadoop网页端

至此伪集群搭建完成
上传文件出现
Permission denied: user=dr.who, access=WRITE, inode="/":root:supergroup:drwxr-xr-x
解决方案:
<!-- 当前用户全设置成root -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- 不开启权限检查 -->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>