一、ASCII和GBK字符集
计算机存储一个英文字符需要一个字节。
ASCII字符集,包括128(0000000B~1111111B)个数据,存储英文字母和字符,对于欧美国家够用。
例如,存储字符’a’,查询ASCII得到为97,二进制为1100001B,计算机进行编码,ASCII编码规则为“前面补0,补齐8位”,所以’a’存储位01100001B。
当从硬盘上读取’a’时,读到01100001B,解码时直接将二进制转化为十进制,再通过查询ACII得出结果。

GB2312-80:中华人民共和国国家标准信息交换用汉字编码字符集基本集。GB表示标准,2312是版本号,80表示年份1980年,只有简体汉字。

GBK中的K是扩的首字母。windows系统简体中文版默认使用的就是GBK。

ANSI是上图中字符集的统称。
后来,美国国家标准协会提出了国际标准字符集Unicode(万国码),它将世界各种语言的每个字符定义一个唯一的编码,以满足跨语言、跨平台的文本信息交换。
GBK的存储规则:
(1)英文也是使用一个字节进行存储,完全兼容ASCII。
(2)汉字用两个字节存储。高位字节二进制一定以1开头(为了与英文区分开,英文的字符开头位0 ),转成十进制之后是一个负数。
GBK读取字节流时,遇到以0开头的字节则表示英文的一个字符,遇到以1开头的字节,则表示这个字节与后面的一个字节组合起来表示一个汉字。
二、Unicode
Unicode
UTF-16编码规则:用2-4个字节保存。英文转为16位。其他文字可能更长。
UTF表示Unicode Transfer Format,即Unicode字符集转换模式。16表示转为16个比特位。
UTF-32编码规则,固定使用四个字节保存。
UTF-8编码规则:用1~4个字节保存。不同国家长度不同,只需记住ASCII码用一个字节(第一位为0),简体中文用3个字节(第一个字节前4为固定为1110,第二个字节前两位固定为10,第三个字节前两位固定为10)。
例如:
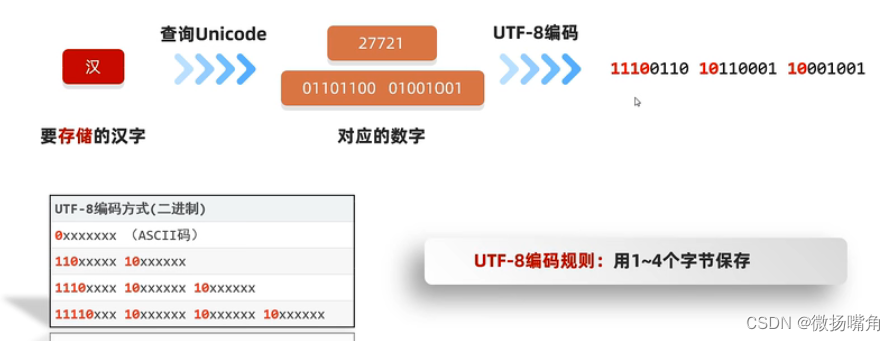
注意:字符集除了对不同字符进行编码,存储之前还有一个编码的过程。查询Unicode找到指定字符的编码,转为二进制数后,使用UTF-8编码规则进行编码,固定位不变,其他位用得到的二进制数进行填充。
三、乱码原因
原因1:读取数据时未读完真个汉字。


注:只读了三分之一的中文,查不到对应字符,有的系统显示?,有的显示方框。
原因2:编码与解码方式不统一。
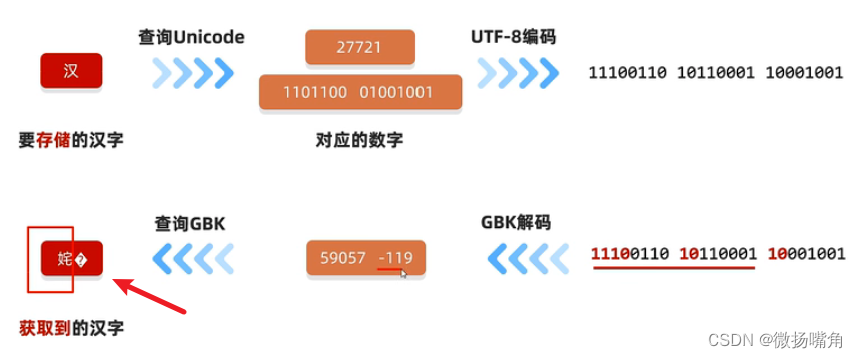
如何不产生乱码:
(1)不要用字节流读取文本文件;
(2)编码解码时使用同一个码表,同一个编码方式。
四、java中的编码与解码

注:使用默认方式可以通过看软件的指定位置。
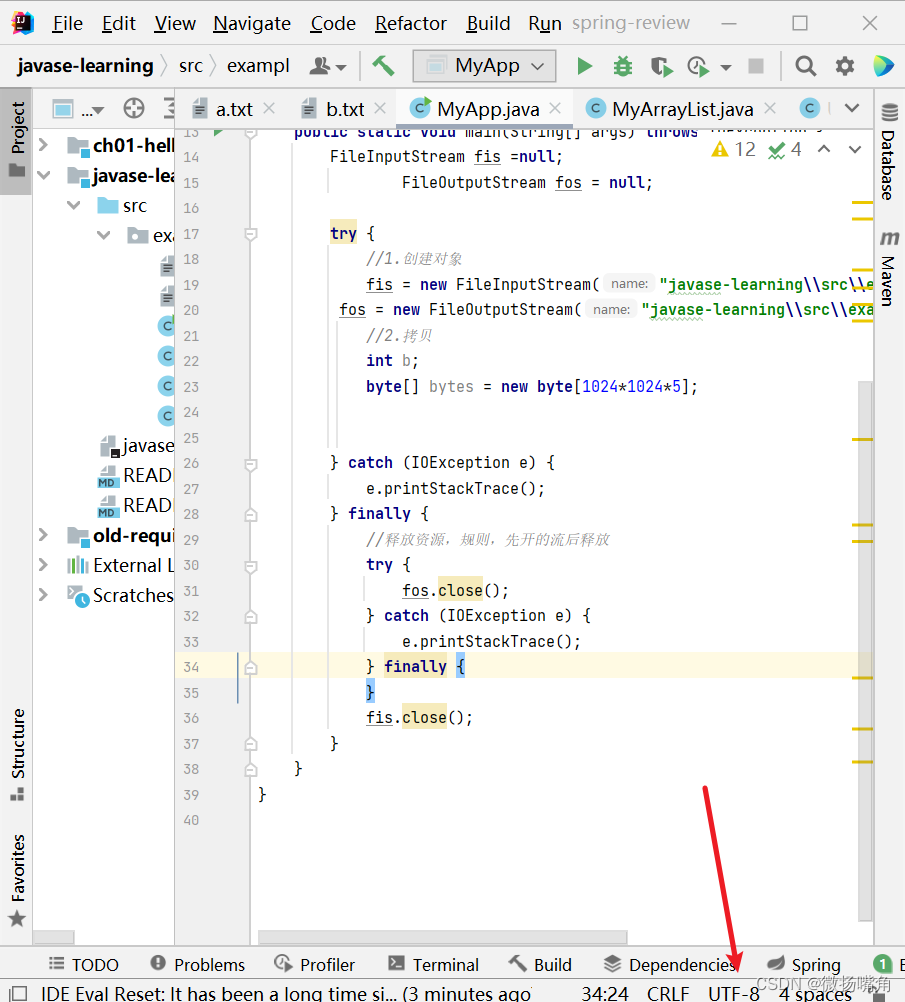
可以看出上图中显示idea默认使用UTF-8编码。
例如:
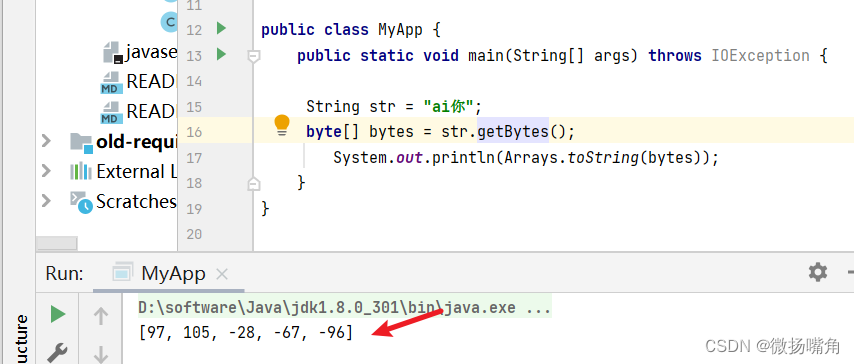
字符串"ai你"通过UTF-8编码,'a’和’i’为一个字节,'你’三个字节。
再例如:
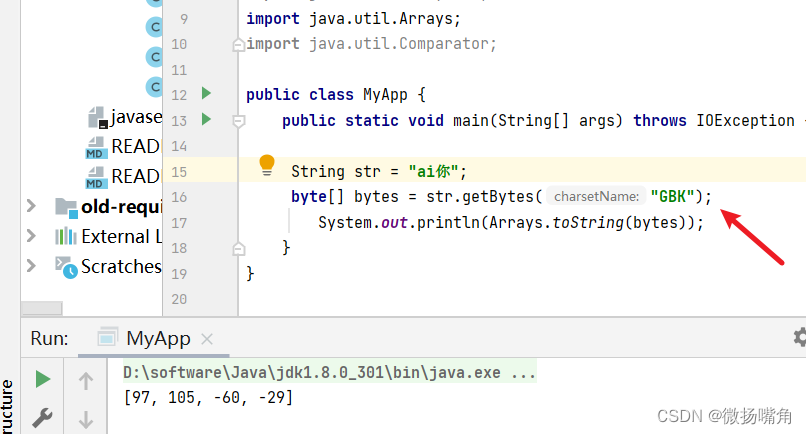
指定使用GBK编码方式,'a’与’i’为一个字节,'你’为两个字节。
解码的例子:
使用默认解码方式UTF-8:
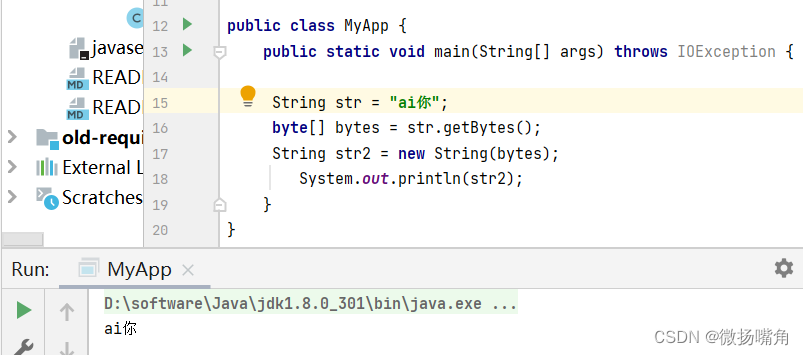
再例如,指定GBK的解码方式:
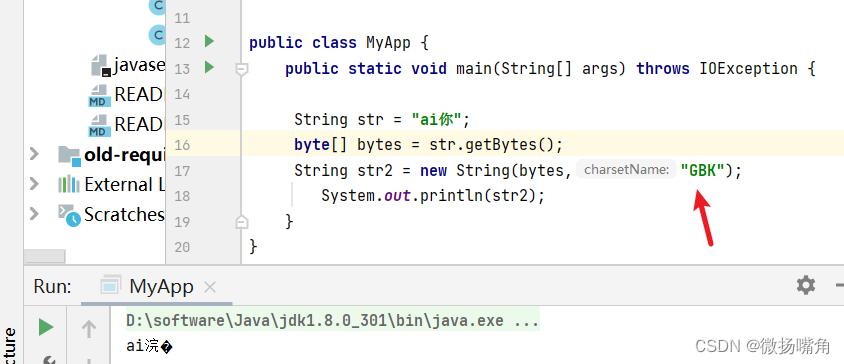
因为编码默认为UTF-8,而解码使用GBK,造成乱码现象。
字符集和java的编码与解码
news2026/2/10 2:17:36
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/642872.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章
Java阶段四Day03
Java阶段四Day03 文章目录 Java阶段四Day03数据处理基本流程代码编写顺序开发DAO层,添加的依赖项配置数据源任务拆解内容管理MySQL中的数据类型和Java属性的类型对照关于MyBatis PlusMyBatis Plus的基本使用关于MyBatis Plus的使用建议汇总如下自动更新时间 关于Pro…
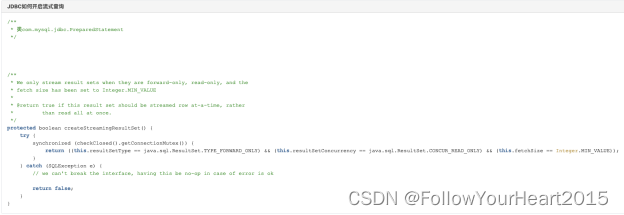
一种不停服的数据迁移方案
一、前言
好的方案是一步步演进出来的。当前最优的系统方案,可能在下一个月、三个月或半年后,就会遇到瓶颈,需要调整自身以便适应新的业务场景。系统的演进就是一个快进版的人类进化史。
我之前负责的一个系统,一开始基本没啥数…

46 最佳实践-性能最佳实践-内存大页
文章目录 46 最佳实践-性能最佳实践-内存大页46.1 概述46.2 操作指导 46 最佳实践-性能最佳实践-内存大页
46.1 概述
相比传统的4K内存分页,openEuler也支持2MB/1GB的大内存分页。内存大页可以有效减少TLB miss,显著提升内存访问密集型业务的性能。ope…

证券行业异构系统众多,微服务和网格如何全都要
在携手网易数帆取得中间件云原生化的创新成果之后,安信证券已在谋划大规模微服务化的布局,以确保信息系统架构走在现代金融科技的前列,支撑业务在未来数智金融竞争中把握主动权。
架构未动,思想先行。安信证券近日在内部组织了一…

安全左移DevSecOps开源工具链建设
开发安全相关技术和产品受到越来越多的关注。行业共识认为,应用系统上线之后进行软件漏洞修复,其修复成本是需求设计阶段修复成本的几十倍。因此,在开发环节,引入相应的安全工具,能够有效的降低漏洞的修复成本…
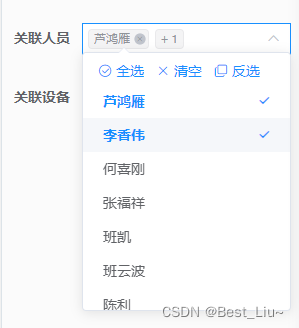
vue+el-select下拉实现:全选、反选、清空功能
问题描述:
el-select下拉框要求实现全选功能。具体功能包括:
当选择【全选】时,所有选项全部被勾选;当选择【反选】时,已选择选项变为未选择选项,未选项变为已选项当选择【清空】时,所有选项变…

SpringBoot进阶学习?看这篇就够了
相信从事Java开发的朋友都听说过SSM框架,老点的甚至经历过SSH,说起来有点恐怖,比如我就是经历过SSH那个时代未流。当然无论是SSM还是SSH都不是今天的重点,今天要说的是Spring Boot,一个令人眼前一亮的框架,…

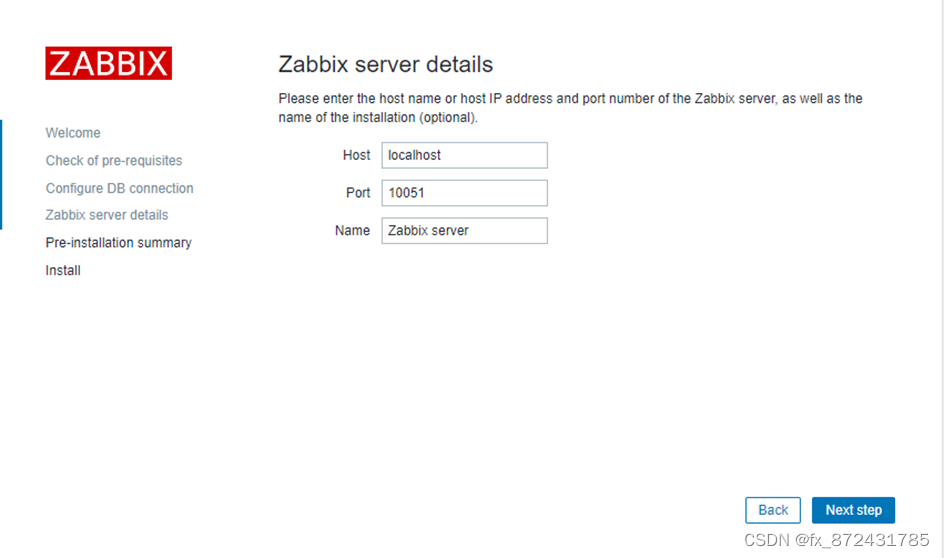
ansible自动部署zabbix监控平台
目录
ansible端部署
使用ansible配置zabbix-mysql端
使用ansible配置zabbix-server端 使用ansible配置zabbix-agent端
一键部署zabbix Ansible是一款开源的自动化运维工具,可以通过SSH协议远程自动化地执行一些复杂的IT工作,例如程序部署、配置管理、…
Python自动化测试——postman,jmeter接口测试
关于众所postman,jmeter,做自动化测试的我想对这两个词并不陌生。大家都知道postman用来做接口测试很方便,下面我们就用一些例子来演示一下它该如何进行接口测试:
首先我们来介绍一下接口测试的概念:
1、什么是接口测试…
【裸机开发】内核时钟 PLL1 配置实验(一)—— 寄存器分析篇
本章主要会回答以下问题 ?
imx6u 的时钟源来自于哪 ?为什么一个起始时钟源,最终分成了多路?不同的时钟源是如何与外设对应起来的?(时钟树)要配置内核时钟频率 有哪些步骤 ?涉及到哪…
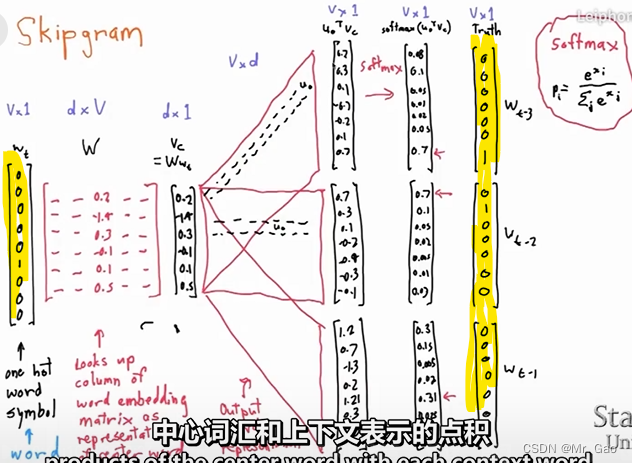
NLP学习笔记十一-word2vec模型
NLP学习笔记十一-word2vec模型
再介绍word2vec模型之前,我们需要先介绍一些背景知识。
我们只知道,NLP这一领域在ward2vec出现之前肯定也是有很大程度发展的,那么想要用将自然语言用计算机进行处理,进行计算,我们必须…
JQuery全部详细笔记-下
JQuery全部详细笔记-下 jQuery 的 DOM 操作
查找节点, 修改属性
查找属性节点: 查找到所需要的元素之后, 可以调用 jQuery 对象的 attr() 方法来获取它的各种属性值
应用实例
<!DOCTYPE html>
<html lang"en">
<head><meta charset"UT…

RK3288 Android8.1添加lvds以及gt9触摸屏(二)
现在先说gt9触摸屏如何配置
首先拿到硬件厂商提供的cfg以及gt9xx文件夹 驱动源码路径:kernel/drivers/input/touchscreen/gtxx
注:可以自己定义最后把gt9xx.h以及gt9xx.c文件放在哪,放在哪就在makefile里指定对应位置
1.touchscreen文件夹…

耗时108天,阿里P8总结了 1000 道 Java 工程师面试题
半年前还在迷茫该学什么,怎样才能走出现在的困境,半年后已经成功上岸阿里,感谢在这期间帮助我的每一个人。
面试中总结了 1000 道经典的 Java 面试题,里面包含面试要回答的知识重点,并且我根据知识类型进行了分类&…

写一个自定义View你都需要注意什么
本文主要是记录一下继承子View,所需要实现的方法,以及对自己的知识做一下梳理和记录,其中不少内容觉得自己应该是会的,但是实际写起来,还是遇到不少阻碍
构造方法
首先构造先了解一下构造方法,一般来说&a…

和悦未来社区:助力共同富裕,三思打造智慧社区新样板
“共同富裕是社会主义的本质要求,是中国式现代化的重要特征,是人民群众的共同期盼。”
2021年5月20日,《中共中央 国务院关于支持浙江高质量发展建设共同富裕示范区的意见》正式发布。
浙江省作为共同富裕先行示范省份,行而不辍…
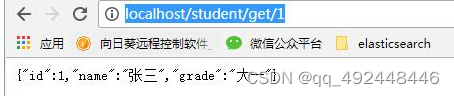
SpringCloud microservice-student-consumer-80服务消费者项目建立(四)
新建一个服务器提供者module子模块,类似前面建的common公共模块,名称是 microservice-student-consumer-1001
pom.xml修改:
<project xmlns"http://maven.apache.org/POM/4.0.0" xmlns:xsi"http://www.w3.org/2001/XMLSc…

重生之我测阿里云U1实例(通用算力型实例)
官方福利!!!!大厂羊毛你确定不薅???
参与ECSU实例评测,申请免费体验机会:https://developer.aliyun.com/mission/review/ecsu 参与ECSU实例评测,申请免费体验…