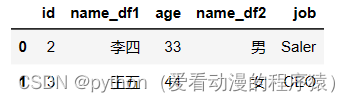
老规矩,先来看看大致结构:
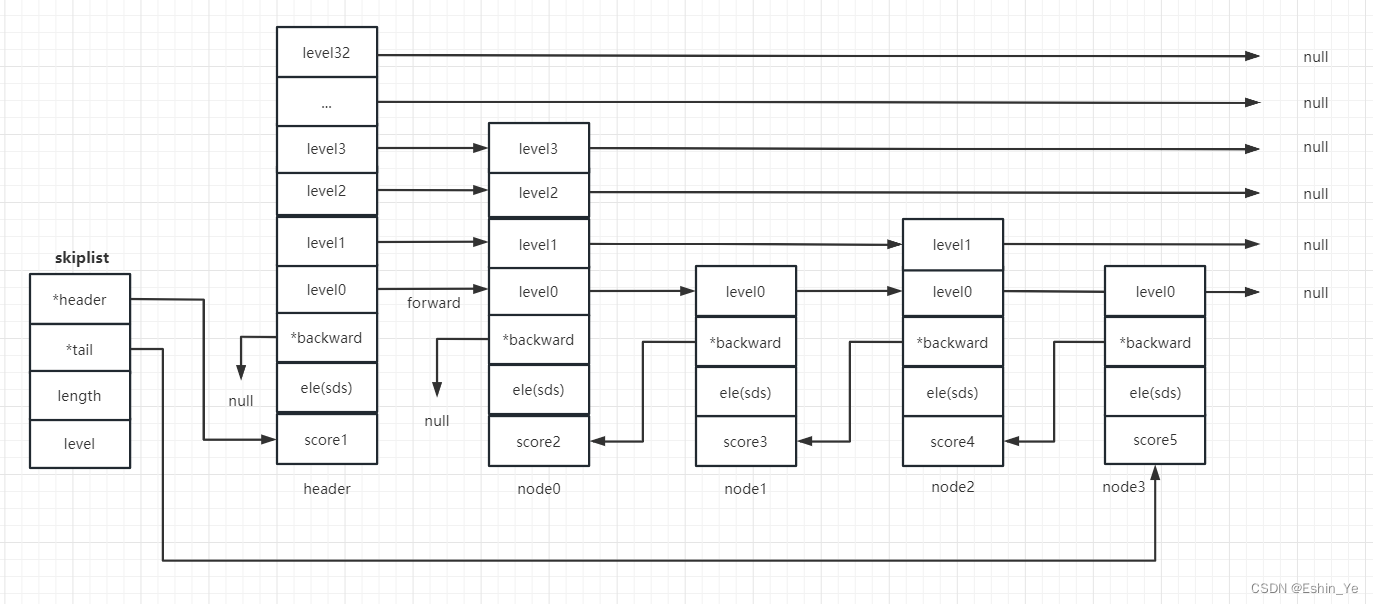
debug所用demo如下:
#include "src/server.h"
void testSDS();
void testAlign();
void testZipList();
void testSkipList();
void testQuickList();
int main(int argc, char **argv) {
// testAlign();
// testSDS();
// testZipList();
// testQuickList();
testSkipList();
}
void testSkipList(){
zskiplist *my_list = zslCreate();
sds sds01 = sdsnew("0001a");
sds sds02 = sdsnew("0002a");
sds sds03 = sdsnew("0003a");
sds sds04 = sdsnew("0004a");
sds sds05 = sdsnew("0005a");
zslInsert(my_list,1,sds01);
zslInsert(my_list,2,sds02);
zslInsert(my_list,3,sds03);
zslInsert(my_list,4,sds04);
zslInsert(my_list,5,sds05);
}
skiplist本质是有序的链表,每个节点可能会属于多层,至少属于一层,是个典型的以空间换时间的结果,大致的数据结构如下:
typedef struct zskiplistNode {//skiplist节点
sds ele; //节点字符串内容
double score; //节点分值,主要用于插入排序比对
struct zskiplistNode *backward; //除了header节点和header后的一个节点,其余节点的backward都指向前面节点
struct zskiplistLevel {
struct zskiplistNode *forward;//当前节点在当前层,指向的下一个节点
unsigned long span; //到下一个节点间隔多少个元素,即步长。
} level[]; //每个节点都可能属于多层
} zskiplistNode;
typedef struct zskiplist {
struct zskiplistNode *header, *tail;//定义头结点和尾节点
unsigned long length; //node节点数量
int level; //当前list用了多少层
} zskiplist;
从上图可以看出:
level0:header-》node0-》node1-》node2->node3
level1和level2都是:header-》node0->node2
一、创建skiplist并初始化
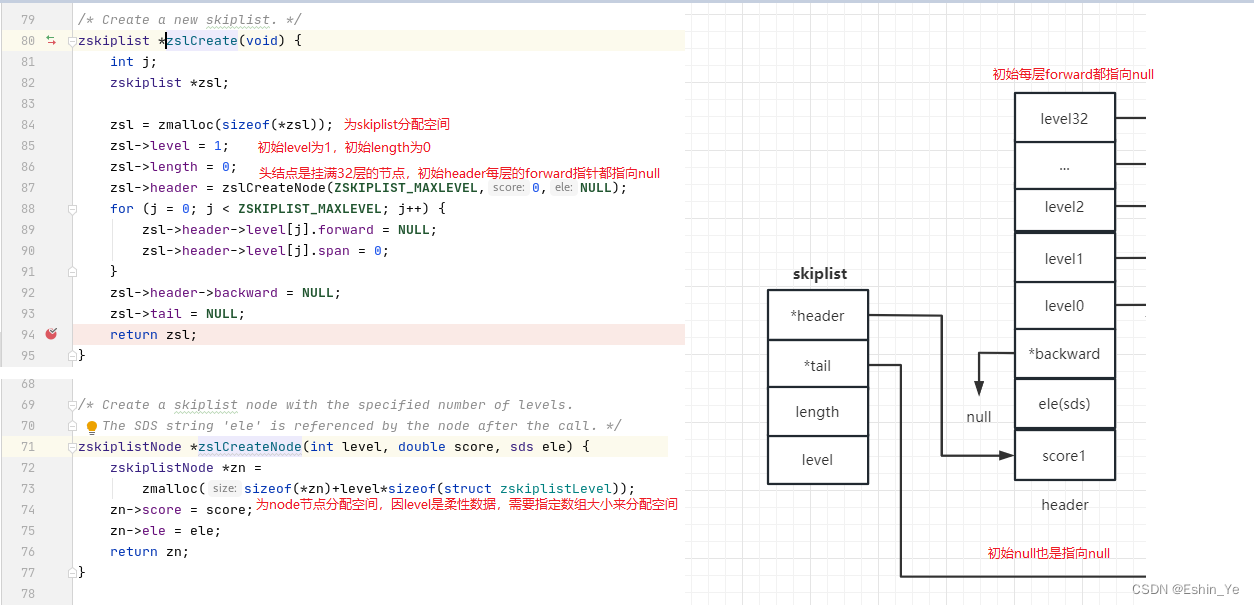
二、节点插入
节点插入是构建skiplist最核心的逻辑,主要调用zslInsert()方法:

关于level的生成:
int zslRandomLevel(void) { int level = 1; //0-65535 <0.25*65535的概率 while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF)) level += 1;//每次加一的概率为0.25 return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL; }那么为1的概率:1-0.25
大于1的概率:0.25
为2的概率:0.25*(1-0.25)
为3的概率:0.25* 0.25*(1-0.25)
为n的概率:0.25^n-1 * (1-0.25),
n最大为32
delete和update相对没什么新的技术点,这里就不做更深入研究了。
与红黑树对比有何优势劣势:
同二分查找,红黑树和跳跃表的时间复杂度都能达到Olog(n).,但跳跃表实现上更加简单易懂;
跳跃表牺牲一定的空间用于层级管理,但是层级中只是保存了节点指针,相对而言,空间的牺牲较小;
跳跃表的插入删除影响的局部范围小并发能力强,红黑树可能会涉及树的旋转调整,影响较大;
跳跃表可以很方便通过层级节点定位实现范围查找;
Redis源码剖析之跳表(skiplist)
【Redis】skiplist跳跃表
Skiplist论文原地址










![[Hadoop安装配置 ]](https://img-blog.csdnimg.cn/4353d0b2707f4dfcb1c4c09a2b5d05e8.png)