目录
前言:
执行步骤:
1 创建好目录文件,上传Hadoop版本压缩包,一般都是tar.gz 结尾包
1.1这里压缩包可以直接拖拽到指定虚拟机目录下, 例如xshell连接指定虚拟机, 然后可以拖拽,如果拖拽不了,那就需要设置一下配置, 或者 使用 xftp工具 连接xshell 然后上传文件
2 解压压缩包, tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
2.1 tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/ 命令详解
3 然后去module目录查看解压情况,配置对应的环境变量
3.1 这一步需要做的操作
3.2 配置环境变量
编辑完etc的环境变量以后, 退出来使用命令source /etc/profile, 生效以后 执行hadoop指令
生效以后的hadoop的目录下都有什么文件:
bin目录下:
etc目录:
Sbin目录
总结下来就是, 我们经常使用的hadoop,目录有etc,bin,sbin
本地虚拟机上演示hadoop:
先创建一个 wcinput文件夹, 需要跟bin,sbin目录平级 注意
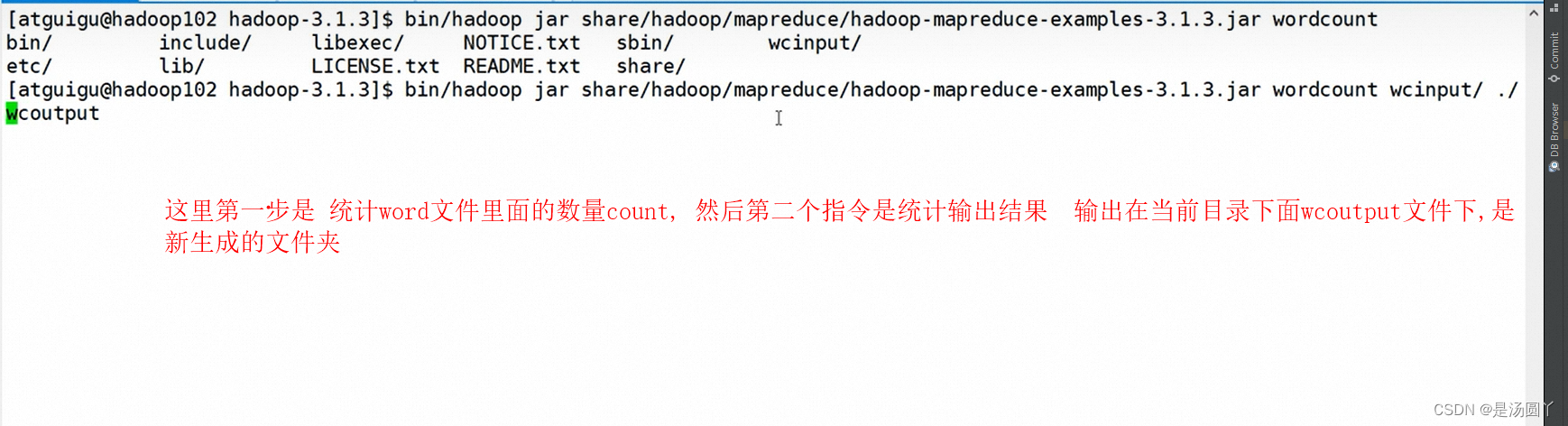
下面这个统计, 需要看一下 examples 你对应在那个目录下面,然后去统计数量
然后找到输出的文件wcoutput文件, cat 查看 part -r -0000文件编辑
前言:
总是避免不了过来学习一手
Hadoop官网地址:
Apache Hadoop
版本下载地址: 下载自己合适的版本
Index of /dist/hadoop/core/hadoop-2.7.5
执行步骤:
1 创建好目录文件,上传Hadoop版本压缩包,一般都是tar.gz 结尾包
1.1这里压缩包可以直接拖拽到指定虚拟机目录下, 例如xshell连接指定虚拟机, 然后可以拖拽,如果拖拽不了,那就需要设置一下配置, 或者 使用 xftp工具 连接xshell 然后上传文件
- cd 目录文件 例如 cd/opt/software
- ll 展示该目录下的信息

2 解压压缩包, tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
2.1 tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/ 命令详解
- 这个命令是将名为"hadoop-3.1.3.tar.gz"的压缩文件解压缩到"/opt/module/"目录下。
- 具体来说,命令中的参数含义如下:
- tar:Linux系统下的压缩和解压缩命令。
- -zxvf:解压缩选项,其中"z"表示使用gzip压缩格式,"x"表示解压缩,"v"表示显示详细信息,"f"表示指定要解压缩的文件。
- hadoop-3.1.3.tar.gz:要解压缩的压缩文件名。
- -C /opt/module/:指定解压缩后的文件存放目录为"/opt/module/"。
- 因此,执行该命令后,会将"hadoop-3.1.3.tar.gz"解压缩到"/opt/module/"目录下,生成一个名为"hadoop-3.1.3"的目录,其中包含Hadoop的安装文件和相关配置文件。
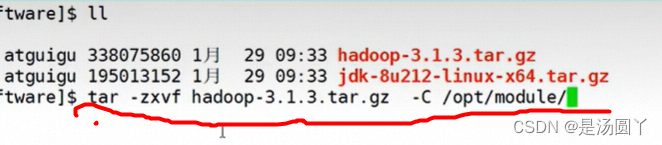
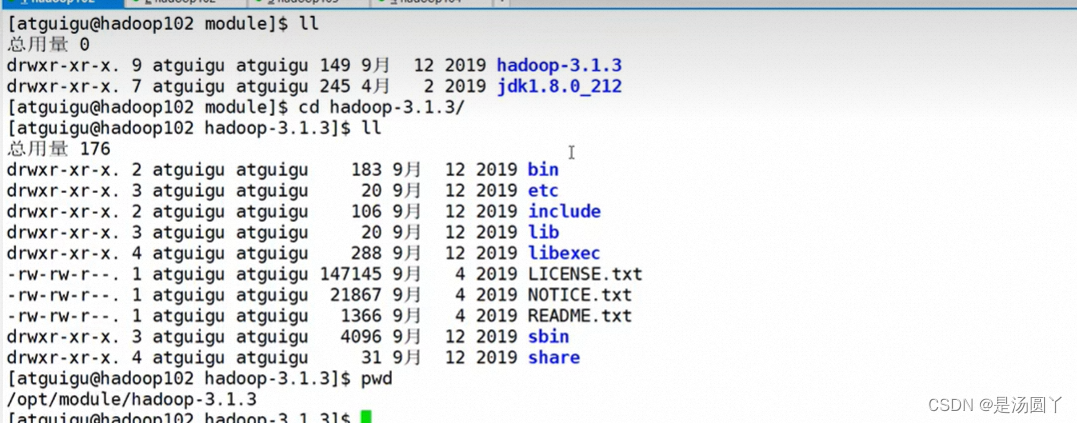
3 然后去module目录查看解压情况,配置对应的环境变量
3.1 这一步需要做的操作
- cd .. 退出当前目录,
- cd module 进入指定 module目录
- ll 查看对应目录下信息
- cd hadoop-3.1.3 进入这个文件
- pwd pwd指令是用来显示当前工作目录的命令,然后复制显示的路径,去etc里面配置环境变量
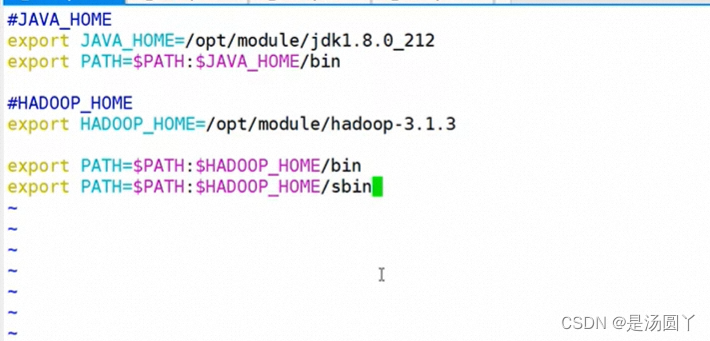
3.2 配置环境变量
- sudo vim/etc/profile.d/my_env.sh 去对应配置文件里面配置
- sudo:以超级用户权限执行命令。
- vim:启动vim编辑器,用于编辑文件。
- /etc/profile.d/my_env.sh:要编辑的文件路径。
- 这一步下面需要配置好 对应Hadoop 里面的bin ,sbin文件
编辑完etc的环境变量以后, 退出来使用命令source /etc/profile, 生效以后 执行hadoop指令

- source /etc/profile 是用来重新加载当前 Shell 的配置文件 /etc/profile 的命令。执行该命令后,会使得当前 Shell 立即生效 /etc/profile 中的修改。一般在更改了 /etc/profile 文件之后,需要使用该命令来使更改生效。
生效以后的hadoop的目录下都有什么文件:
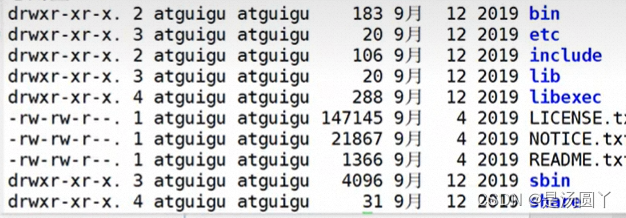
bin目录下:
目录下的 hdfs 存储, mapred计算 ,yarn 资源调度 普遍应用较多
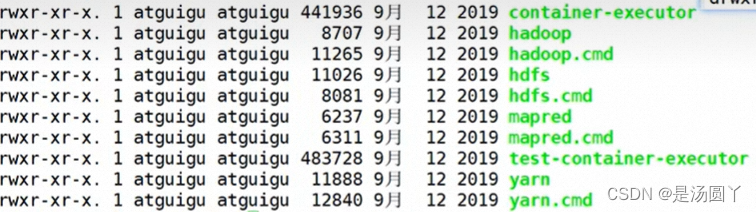
etc目录:
主要去配置xml一些信息
cd /etc/hadoop/
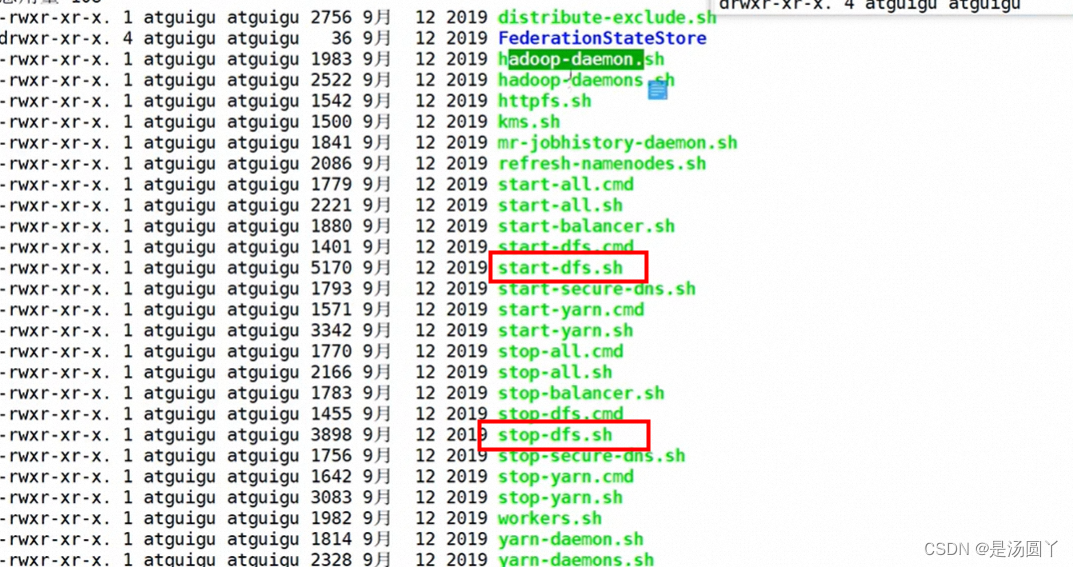
Sbin目录
一般是启动服务的
总结下来就是, 我们经常使用的hadoop,目录有etc,bin,sbin
本地虚拟机上演示hadoop:
先创建一个 wcinput文件夹, 需要跟bin,sbin目录平级 注意

然后进入文件 , cd wcinput , 然后vim word.txt 创建一个txt文件
,然后下面是在txt文件里面写一些内容
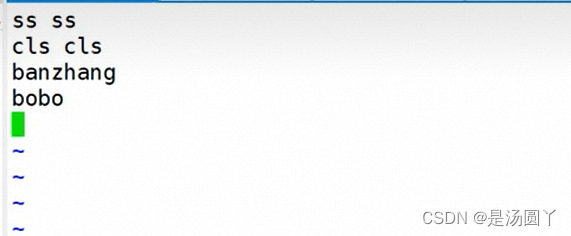
下面这个统计, 需要看一下 examples 你对应在那个目录下面,然后去统计数量
然后找到输出的文件wcoutput文件, cat 查看 part -r -0000文件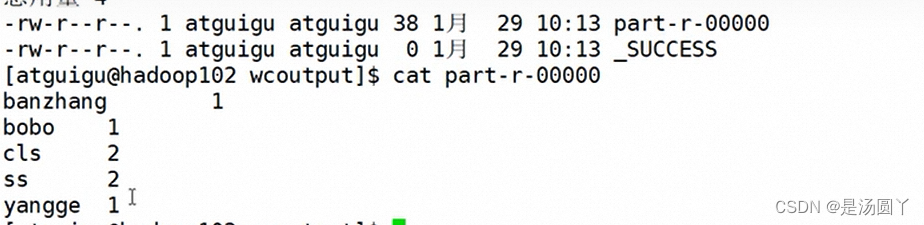
学习地址:
尚硅谷上面安装视频,记录一手