通俗来讲就是,张三造假币(Generator生成器),然后用验钞机去验证真假(Discriminator辨别器),如果是假的就继续提高造假技术,直到验钞机检验不出来为止,也就是说一个造假一个验假(验钞机也需升级),两者互相学习和提高的过程,就叫做GAN,那在图片领域,就是想要生成的图片达到以假乱真的效果!
好了,这里试图将StyleGAN3篇论文都解读在一起,方便大家更快熟悉这个让人惊艳的大模型,水平有限,有误处欢迎指正,感谢。
1、StyleGAN
可以先来看一个StyleGAN视频,看下生成的效果:StyleGAN生成图片
1.1、StyleGAN架构图

左边是传统的生成器,右边是基于样式的生成器
传统生成器比较简单,就是通过输入层提供Latent潜在代码(一般我写成隐藏编码),而基于样式的生成器,首先将输入映射到中间潜在空间W,也就是说增加了一个映射网络,然后将这些仿射变换的A分别作为style输入到自适应实例规范化(AdaIN),进行上采样等操作控制生成器。另外在AdaIN之前和在卷积之后添加高斯噪声。
这里“A”代表学习到的仿射变换,“B”将学习到的每通道缩放因子,应用于噪声输入映射网络f(8层),以及合成网络g或叫生成网络(18层)。最后一层的输出使用单独的1×1卷积转换为RGB。
我们的生成器参数,共有2620万个可训练参数,而传统生成器只有23.1万个。
其中基于样式生成器的Mapping network映射网络,主要就是将随机采样的数据投影到w(图像特征的子集)空间中,接全连接层(FC)组成,其中生成网络里的输入是4x4x512的常数张量。
重大的变化就是增加映射网络这一步骤,就是从z∈Z到w∈W,隐藏编码到中间隐编码的过程。我们知道一张人脸图片有很多特征,眼睛、鼻子、表情、肤色等等,这些特征之间是关联着的或者说相互纠缠着,我们叫做耦合度高,这对于我们想控制不同的细节比较麻烦,所以需要做一步解耦的操作,就是把这些特征给分层或说分成很多个维度,这样的话,我们就好操作了,比如操作眼睛就不会影响到鼻子等其他维度。
1.2、FFHQ数据集
我们这里使用的数据集是FFHQ(Flickr-Faces-HQ),Flickr是以前雅虎的一个图片站点,收集的是高质量的人脸图像,最初是作为生成对抗网络(GAN)的基准而创建的,该数据集由70,000张分辨率为1024×1024的高质量PNG图像组成,并且在年龄,种族和图像背景方面包含相当大的差异。由于图片是从Flickr抓取的,因此继承了该网站的所有偏见,使用dlib自动对齐和裁剪。尊重用户的隐私,所以仅收集用户许可下的图像。
1.3、AdaIN自适应实例规范化
上面我们提到的Adaptive Instance Normalization(AdaIN)自适应实例规范化,作用是对每层输入进来的风格做处理,我们来看下它的公式:
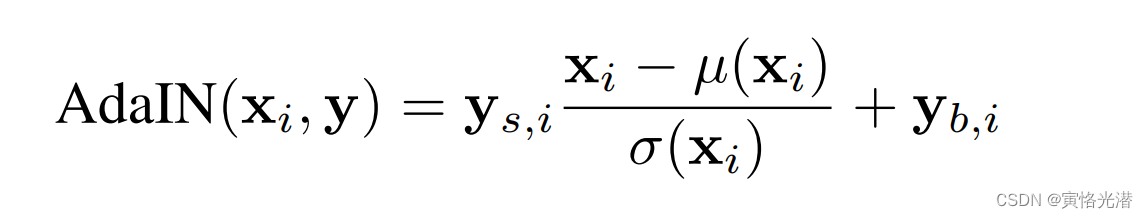
表示每个特征图,
和
是中间隐编码W转换过来的风格,
,其中每个特征映射
分别归一化,然后使用样式y的相应标量分量进行缩放和偏置。因此y的维数是该层上特征映射数量的两倍。
1.4、风格混合
我们按照上面的架构来生成一组示例看下:

样式如何混合:生成网络中随机选择的点从一个隐藏编码切换到另一个,具体来说,就是通过映射网络运行两个隐藏编码z1, z2,并由对应的w1, w2控制样式,使w1在交叉点前应用,w2在交叉点后应用。
这里使用了截断技巧,就是防止在W的一些极端区域进行采样,可以看到生成的效果很不错,而且眼镜等都能很好的合成,其中样式分三类:
粗犷样式:从源B中带来姿势、发型、脸型和眼镜等高级方面,而所有颜色(眼睛、头发、光线)和更精细的面部特征来源于A
中间样式:从源B那里继承了较小尺度的面部特征、发型、眼睛的睁眼/闭眼,而从源A那里保留了姿势、大致的脸型和眼镜。
精细样式:身份特征跟源A相似,肤色来自源B,主要带来了配色方案和微观结构。由此我们可以知道,低分辨率的style控制姿态、脸型、配件(眼镜、发型等),高分辨率的style控制肤色、头发颜色、背景色等,这里也再次看到,样式的每个子集都控制着图像的有意义的高级属性,也就是我们做的那个网络映射,就是将隐编码到中间隐编码这个处理过程,做了解耦的一个操作,分离了不同特征。
1.5、噪声输入
我们在架构图的最右边可以看到,有噪声的输入,这个起到什么作用呢?我们先来看一张图:

(a)、每层加入噪声,效果很自然,头发卷曲跟真的一样,皮肤更细腻
(b)、没有加噪声,头发看起来像是,没有特色的“绘画”外观,没有卷曲
(c)、细微层噪声,头发卷曲很细
(b)、粗层噪声,头发是大面积卷曲
这里我们从图片可以看出,随着噪声的比例不同,效果发生了不同的变化!
我们这里使用的是随机变化,因为在脸部有很多方面可以被认为是随机的,比如头发、胡茬、雀斑或皮肤毛孔的确切位置。这些都可以随机化而不影响我们对图像的感知,只要它们遵循正确的分布,换句话说就是雀斑,毛孔等这些在脸部的其他位置也关系不大,而且这些噪声的加入让脸部的这些细节显得更真实自然。
1.6、感知路径长度PPL
隐藏空间(中间隐编码)向量的插值,可能会在图像中产生令人惊讶的非线性变化。为了量化这种影响,我们可以测量当我们在潜在空间中执行插值时图像经历的剧烈变化。直观地说,一个较少弯曲的潜在空间应该比一个高度弯曲的潜在空间产生更平滑的过渡。 感知路径长度的一个自然定义将是这个总和在无限精细细分下的极限,但在实践中,我们使用一个小的值epsilon来近似它,ε=0.0001,因此,在所有可能的端点上,潜在空间Z中的平均感知路径长度为:

其中z1, z2就是上面说的隐编码,生成的初始图像P(z),通过P和x之间的差距来设置损失函数,然后迭代z,最后得到图像x的隐编码。
G是生成器网络(f是映射网络),d(·,·)评估感知路径长度的,也叫做辨别器,这里的slerp表示球面插值,这是在我们的归一化输入潜在空间中最合适的插值方式。为了专注于面部特征而不是背景,我们在评估成对图像度量之前裁剪生成的图像以仅包含面部,由于度规d是二次的,我们除以ε²,t是某个时间点,那t+ε就表示下一时间点。
2、StyleGAN2
我们可以看到在StyleGAN图像中会产生类似水滴的伪影。这些在生成的图像中并不总是很明显,但如果我们观察生成网络内部的激活,问题总是存在的,虽然不是经常出现,但是一个很不好的现象,如图:
 我们重新设计了生成器归一化,重新审视了渐进式增长,并对生成器进行了正则化,以鼓励从隐藏编码到图像的映射中的良好调节,除了提高图像质量之外,这个路径长度正则化器还带来了额外的好处,即生成器变得更容易反转。这使得将生成的图像可靠地归因于特定网络成为可能。我们进一步可视化生成器如何很好地利用其输出分辨率,并确定一个容量问题,激励我们训练更大的模型,以获得额外的质量改进。
我们重新设计了生成器归一化,重新审视了渐进式增长,并对生成器进行了正则化,以鼓励从隐藏编码到图像的映射中的良好调节,除了提高图像质量之外,这个路径长度正则化器还带来了额外的好处,即生成器变得更容易反转。这使得将生成的图像可靠地归因于特定网络成为可能。我们进一步可视化生成器如何很好地利用其输出分辨率,并确定一个容量问题,激励我们训练更大的模型,以获得额外的质量改进。
2.1、StyleGAN2架构图
StyleGAN和StyleGANv2两者架构的对比图(四个子图,第一个StyleGAN,第二个是StyleGAN的详细图,第三个就是StyleGAN2,改进的架构,第四个是对权重的调制与解调):

在介绍StyleGAN的时候,我们知道,其中A表示从W学习的仿射变换,产生的风格,B是噪声广播操作。将AdaIN分解为显式归一化,然后进行调制,同时对每个特征映射的平均值和标准差进行操作。
我们来重点关注修改的架构,首先去掉了一开始的一些冗余操作,以及将偏置b和噪声B的加法移到样式块的活动区域之外(橙色圈标注的地方),只调整每个特征映射的标准差,也就是说将平均值去掉了,第四个是我们能够用“解调”操作取代AdaIN实例规范化,然后我们将其应用于与每个卷积层相关的权重。
修改之后的架构显得更加的独立(卷积块就变得很内聚了),看起来更加简洁。模块之间的耦合度也减少了很多,这对于后期操作图片是很关键的。
2.2、架构修改说明
我们将问题定位到AdaIN操作,该操作分别对每个特征映射的均值和方差进行归一化,从而可能破坏在特征相对于彼此的大小里面发现的任何信息。当从生成器中删除归一化步骤时,水滴伪影完全消失。
在StyleGAN的样式块中应用了偏差和噪声,导致它们的相对影响与当前样式的大小成反比。于是我们将这些操作移到Style block[样式块]之外(规范化数据后面),发现可以获得更可预测的结果。另外对恒定输入的偏置、噪声和归一化的应用也可以安全地去除,而不会有明显的缺点,也就是第三个子图,c1输入后面没有了b1和B以及Norm mean/std这些操作,直接进入到了样式块。
我们知道StyleGAN的一个主要优势是可以通过样式混合来控制生成的图像,也就是在推理时向不同的层提供不同的中间隐藏编码w。在实践中,样式调制可以将某些特征映射放大一个数量级或更多。为了使样式混合工作,我们必须明确地在每个样本的基础上抵消这种放大,否则后续层将无法以有意义的方式对数据进行操作。
这个权重的调制与解调的过程,我们来看下公式:
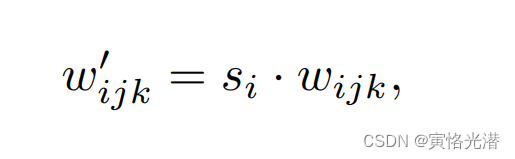

其中w和w'分别为原始权值和调制权值,为第i个输入特征映射对应的尺度,j和k分别枚举卷积的输出特征映射和空间足迹。
然后解调就比较简单了,除以L2范式即可,加一个ε防止分母为0
我们来看下在FFHQ和LSUN Cat数据集中的实验结果的对比(四个指标分别是FID,路径长度,精度,召回率):
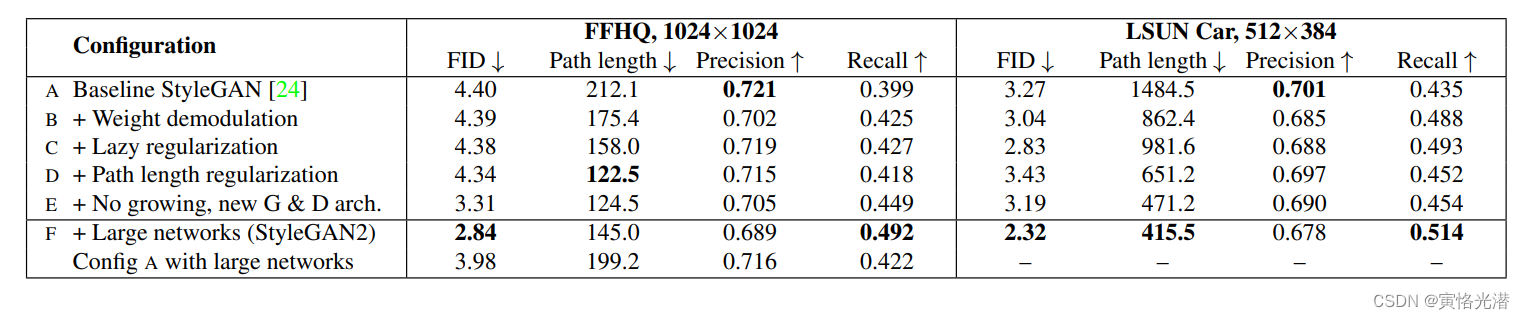 另外通过这些修改,用解调代替归一化,消除了图像和激活中的特征伪影,我们来看张图片:
另外通过这些修改,用解调代替归一化,消除了图像和激活中的特征伪影,我们来看张图片:

虽然FID(Fréchet Inception Distance)或Precision精确率和Recall召回率(P&R)成功地捕获了生成器的许多方面,但它们在图像质量方面仍然存在某种盲点。如下图,它们对比了具有相同FID和P&R分数但总体质量明显不同的生成器。

来自LSUN数据集的猫,第一张和第二张的FID和P&R差不多,区别在于第二张的PPL(Perceptual Path Length感知路径长度)要小,我们观察到图像的质量与感知路径长度之间存在相关性,PPL最初是为了量化从隐藏空间到输出图像映射的平滑度而引入的度量,通过测量隐藏空间中,小扰动下生成图像之间的平均LPIPS距离(一种用于衡量两张图像之间相似度的指标,越小越相似),而且我们通过上面图片对比发现较小的PPL(更平滑的生成器映射)似乎与更高的整体图像质量相关。
虽然低的PPL对图像质量有所改善,但与图像质量相关并不是很明显。我们假设,在训练过程中,由于鉴别器会惩罚损坏的图像,因此生成器改进的最直接方法是有效地拉伸产生好图像的隐藏空间区域。这将导致低质量的图像被压缩到快速变化的小的隐藏空间区域。虽然这在短期内提高了平均输出质量,但累积的失真损害了训练动态,从而影响了最终的图像质量。
所以说我们不能简单地鼓励最小PPL,因为这将引导生成器走向零召回的退化解决方案。相反,我们将描述一个新的正则化器,它旨在实现更平滑的生成器映射,而没有这个缺点。
2.3、惰性正则化Lazy regularization
主损失函数和正则化项是在一个表达式里面,可以同时进行优化。观察到正则化项的计算频率比主损失函数要低,所以我们采用惰性正则化,通过在一个单独的正则化过程中评估正则化项,每k次训练迭代执行一次。
我们在主损失项和正则化项之间共享Adam优化器的内部状态,因此优化器首先看到k次迭代的主损失的梯度,然后是一次迭代的正则化项的梯度。换句话来将就是主损失函数迭代16次,这个正则化项才执行一次。
2.4、路径长度正则化Path length regularization
路径长度正则化是一种用于控制神经网络模型复杂度的正则化方法。在深层神经网络中,由于模型的复杂度很高,容易导致过拟合的现象。而路径长度正则化方法可以通过对网络中路径长度的约束,来限制模型的复杂度,从而提高模型的泛化能力。该方法在计算机视觉和自然语言处理等领域有着广泛的应用。
该方法的基本思想是,通过限制神经网络中每个神经元到输出层的路径长度,来控制模型的复杂度。具体来说,该方法会对每个神经元到输出层的路径长度进行计算,并对这些路径长度进行惩罚项的加权和。这个惩罚项可以理解为对模型复杂度的约束,从而可以有效避免过拟合现象的发生。
优点在于,与其他正则化方法相比,它不会引入额外的超参数。这意味着,在使用该方法时,不需要手动调整超参数,可以直接使用默认参数。并且,该方法的计算量也相对较小,适用于大规模的深度神经网络。
来看下公式:

w是隐藏空间点,y是在生成的图像空间里的单位正态分布随机变量(RGB图像的维度是3*w*h),J是雅可比矩阵,a是表示期望的梯度规模的全局值,当雅可比矩阵J正交时,内部期望(近似)最小化。当然这个地方将转化成一些正交操作,有兴趣的可以看论文,更加细致的去了解,这里就不贴公式了。
2.5、渐进式增长的优缺点
渐进式增长在稳定高分辨率图像合成方面非常成功,但它会导致自己的特征伪像。关键问题在于渐进式增长的生成器似乎对细节具有很强的位置偏好,我们先来看张图:
 仔细观察,我们发现人的头部偏移的时候,牙齿的位置没有跟着发生变动,而是跟相机保持对齐。
仔细观察,我们发现人的头部偏移的时候,牙齿的位置没有跟着发生变动,而是跟相机保持对齐。
我们认为问题在于,在渐进式增长中,每个分辨率都瞬间充当输出分辨率,迫使它产生最大频率的细节,然后导致训练过的网络在中间层具有过高的频率,从而损害了平移不变性。
这些问题促使我们寻找一种保留渐进式增长的优点而避免其缺点的替代方法,我们来看下三种没有渐进式增长的架构图以及实验的结果:
1、MSG-GAN:使用多个跳跃连接将生成器和辨别器的匹配分辨率连接起来,输出mipmap而不是图像。这mipmap是多级贴图,一种计算机图形技术,用于在不同分辨率下更高效地显示纹理。
2、Input/output skips:通过上采样和总结对应于不同分辨率的RGB输出的贡献来简化此设计。辨别器里面,我们同样将下采样图像提供给辨别器的每个分辨率块。我们在所有上采样和下采样操作中使用的是双线性滤波。
3、Residual nets:使用的是残差连接。这个设计类似于LAPGAN,但没有Denton等人使用的每个分辨率辨别器。
通过9种组合的FID和PPL,我们可以看到两个广泛的趋势:跳跃连接在所有配置中显著提高了PPL,而残差辨别器网络对FID显然是有益的,因为辨别器的结构类似于分类器。然而,残差网络的架构在生成器中是有害的(唯一的例外是LSUN CAR中的FID),当两个网络都是残差时。
综合考虑我们使用跳跃连接生成器和残差辨别器。
2.6、StyleGAN2能耗
原始的StyleGAN在NVIDIA DGX-1上配备8个Tesla V100 GPU时以每秒37张图像的速度训练,而我们训练速度达到了每秒61张图片 。大部分加速来自由于权重解调,懒惰的正则化和代码优化而导致的简化数据流程。其总训练时间为FFHQ为9天,LSUN CAR为13天,整个项目,包括所有探索,消耗了132 MWh(兆瓦时)的电力,其中0.68 MWh用于训练最终的FFHQ模型,这里的一兆瓦是1000千瓦时,就是一小时消耗1000度电的意思。也就是需要13万多度电,耗电量还是非常大的。
最后看下精心挑选的4张生成图片,效果非常好,跟真人一样。

最后有兴趣的可以看下StyleGAN2的视频:StyleGAN2视频 对英语听力有点要求。
3、StyleGAN3
我们来回顾下StyleGAN2的架构,它的生成器是由两部分组成。首先,映射网络将初始的正态分布隐藏编码变换为为中间隐藏编码,然后是合成网络G从一个学习到的4×4×512常数开始,并应用一个N层的序列,由卷积、非线性、上采样和逐像素噪声组成,来产生一个输出图像。
中间隐藏编码控制生成器网络中卷积核的调制。每层遵循严格的2倍上采样计划,其中在每个分辨率下执行两层,并且每次上采样后特征映射的数量减半。此外,StyleGAN2还采用了跳过连接、混合正则化和路径长度正则化对StyleGAN的改进。
我们先来看下StyleGAN2和StyleGAN3的对比视频:StyleGAN3视频
Alias-Free Generative Adversarial Networks,不失真(无锯齿)的生成对抗网络。一般大家就叫做StyleGAN3,是对StyleGAN2的改进,主要是针对在StyleGAN2中平移或旋转时,存在“粘滞”现象,比如视频中,头部的移动,正常来说脸部上面的特征是要跟着一起移动的,而在StyleGAN2中出现胡子没有很好贴着皮肤一起移动,出现一种胡子像是粘在嘴巴上,分离的感觉,这种情况就是特征依赖绝对坐标,而没有很好的做到跟随周边的特征一起移动。
StyleGAN3的改进,使得即使在亚像素尺度上,它们也能够做到平移和旋转不变性,这样的结果为视频和动画的生成模型铺平了道路。其中亚像素的概念附带说下,平时大家都知道图像是有像素组成的,其实像素之间存在空隙,而空隙之间存在的空间,我们就叫做亚像素,比如我们做上采样时,常见的双线性插值就是在X,Y方向相邻像素之间分别采样,然后在采样点之间插入数值。
3.1、邻域是否锐化
我们来看张对比图:
 注意看猫眼睛周边的模糊情况,正常来说我们预期的结果是周边都会一起模糊,而StyleGAN2的毛发(左边红色箭头)显示出了不必要的清晰度(锐化),没有跟随,右边红色箭头对比可以看到,全部做了模糊处理。同样的,我们抽取垂直头发,StyleGAN2显示的是没有变化,右边的很好的显示出了头发的渐变。
注意看猫眼睛周边的模糊情况,正常来说我们预期的结果是周边都会一起模糊,而StyleGAN2的毛发(左边红色箭头)显示出了不必要的清晰度(锐化),没有跟随,右边红色箭头对比可以看到,全部做了模糊处理。同样的,我们抽取垂直头发,StyleGAN2显示的是没有变化,右边的很好的显示出了头发的渐变。
3.2、离散特征与连续特征
StyleGAN3改进的一个关键点,是将离散特征做了映射成了连续特征,这样的好处会在接下来有具体说明,我们先来看张图,了解下这个离散特征与连续特征之间的转换。

我们先来看左边部分,大写Z表示离散特征,小写z表示连续特征。Z到z是离散到连续的表示,中间通过理想插值滤波器Φs。
公式:z(x) = Φs ∗ Z(x),其中*表示连续卷积,Φs(x) = sinc() · sinc(
)
其中,辛格函数:sinc(x) =sin(πx)/(πx)
Φs沿水平和垂直方向的带宽限制为s/2,确保得到的连续信号捕获可以用采样率s表示的所有频率。
z到Z是连续到离散的表示,中间通过狄拉克梳状函数(可以作为脉冲序列或者采样函数),这里就是筛选出很多的点。
右边部分,在这个例子中,ReLU可以在连续域σ(z)中产生任意高频率,通过Φs进行低通滤波是必要的,以确保Z'能捕获结果。
其中狄拉克梳状函数公式: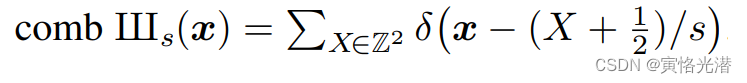
当我们将离散特征和连续特征做了对应关系之后,我们就可以将注意力从通常的以像素为中心的信号视图中转移出来。我们将把z(x)解释为被操作的实际信号,而离散采样的特征Z[x]仅仅是对它的一种方便的编码。
这样我们就可以在网络层进行离散域和连续域的表示如下:
s和s'分别是输入和输出的采样率,需要注意的是,后一种连续到离散的表示,f不能引入超出输出带宽限制的频率内容s'/2。
3.3、上采样和下采样
理想的上采样不修改连续表示。它的唯一目的是增加输出采样率(s' > s),以增加频谱中的剩余空间,其中后续层可能引入额外的内容。
下采样,我们必须使用低通滤波器z来去除高于输出带宽限制的频率,以便在粗的离散中也能忠实的表示。需要注意的是,旋转等变性需要将滤波器修改成径向对称插值滤波器,使用的是jinc函数:

需要注意的是,非线性是我们公式中唯一能够产生新频率的操作,并且我们可以通过在最终离散化操作之前应用具有低于s/2的截止率的重建滤波器来限制这些新频率的范围。这使我们能够精确控制生成器网络的每一层引入的新信息的数量。
3.4、StyelGAN3架构图
同样的,我们来看下StyleGAN3做了哪些修改,架构图:

(a)滤波器的设计,2倍上采样滤波器的1D示例,n = 6, s = 2, fc = 1, fh = 0.4(蓝色)。设置fh = 0.6使过渡带更宽(绿色),这减少了不必要的阻带纹波,从而导致更强的衰减。
(b)StyleGAN3的改进,我们将StyleGAN2学习到的4x4x512的常数更改为傅里叶特征,卷积核也修改为1x1,其中有一个关键的提高性能的地方,自定义了CUDA核,里面是上采样、Leaky ReLU、下采样、裁剪,导致10倍的训练速度和可观的内存节省。另外我们也将StyleGAN2的噪声输入去掉了
(c)灵活层,N = 14,
= 1024。截止频率fc(蓝色)和最小可接受阻带频率ft(橙色),在各层上服从几何级数,采样率s(红色)和实际阻带fc + fh(绿色)是根据我们的设计约束计算的。这个的作用主要是消除伪影,我们的过滤器的衰减对于最低分辨率层仍然不足。这些层在其带宽限制附近往往具有丰富的频率内容,这需要极强的衰减才能完全消除混叠,这个跟在StyleGAN2中使用刚性采样率不同,我们可以看到使用的是不同层不同的采样率。
3.5、傅里叶特征
对于傅里叶变换,相信对数学感兴趣的伙伴们,应该比较熟悉,其有很多重要的特点,总的来说就是将复杂的事情给简单分解来处理,简单介绍几点:
1、两个信号分别进行傅里叶变换,它们的线性组合的傅里叶变换的结果与对线性组合进行傅里叶变换的结果相等。
2、可以将任意周期性信号通过若干正弦波的组合来得到,比说说分离不同频率的声音
3、比如我们用的多的就是这个可逆性,就是可以通过逆傅里叶变换来恢复原始信号。
所以我们回过头来看上面的架构图,其中的输入傅里叶特征就是来自学习到的仿射层输出,这样的设计也是为了让生成器具备基于w变换到z的能力。
3.6、平移等方差
我们的目标是让生成网络的每一层等变都是连续信号,这样所有更精细的细节都与局部邻域的粗糙特征一起变换。如果每层都成功了,那么整个网络也就做到了等变的效果。也就是说我们的平移与旋转作用于连续输入z0: g(t[z0];W) = t[g(z0;w)]。同样的,对于生成的效果会是怎么样的,也需要一个指标,这里的平移指标,平移等方差EQ-T如下:

每一对图像,对应于不同的随机选择w,在其相互有效的区域V内的整数像素位置p进行采样。颜色通道c被独立处理,并且生成图像的预期动态范围−1…+1则 = 2。算子实现了2D偏移量x的空间平移,这里是从分布X²绘制的整数偏移量。我们为旋转定义了一个类似的度量旋转等方差EQ-R,旋转角度取自U(0°,360°),原理也是差不多,只不过一个是平移,一个是旋转,对于旋转的处理一样要注意带宽限制,其中的滤波器也更换为了径向对称插值滤波器。
3.7、峰值信噪比
峰值信噪比PSNR(peak signal-to-noise ratio),这个有必要了解下,该值是通过平移图像的输入和输出得到的,单位是分贝decibels(dB),一般就是通过均方误差MSE来进行定义,我们来看下它的公式:

I是输入参考和K是它的噪声近似值,D是离散域,通常是一个二维像素网格。那么我们看到分母是MSE,所以这个误差越小,它的PSNR值就越大,当然如果K和I相等,那么分母是0这样的极端情况,峰值信噪比就是∞dB
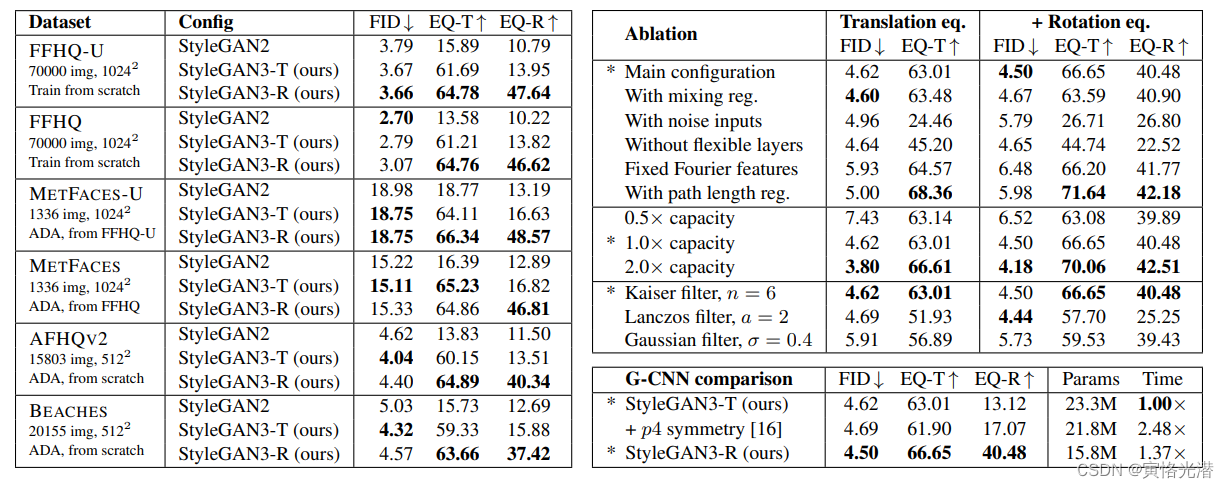
最后看下这个配置和参数,在不同架构上面的指标情况:

以及对比StyleGAN2在6个数据集上的表现情况:
3.8、窗口方法
边界伪影和远程交互引起的振铃(信号转换时容易出现那种残影现象),解决这些问题的最常见方法,是使用窗口方法来限制滤波器的空间范围:

是窗函数,
是ψ(x)的实际近似值。在本文中,我们使用Kaiser凯瑟窗口,也称为凯瑟-贝塞尔窗口,它提供了对这种权衡的显式控制。Kaiser窗口定义为:

其中L是期望的空间范围,β是控制窗口形状的自由参数,是第一类的零阶修正贝塞尔函数。
3.9、二维滤波器
任何一维滤波器,包括,都可以通过定义相应的可分离滤波器轻松地扩展到二维:
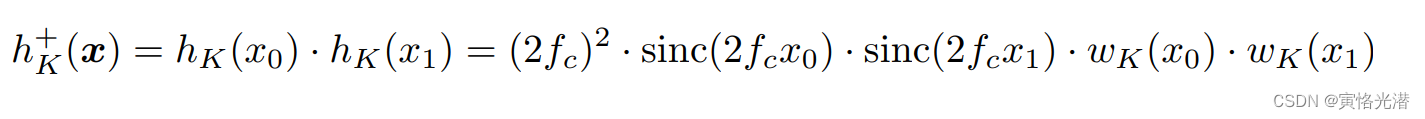 在实践中,可分离滤波器可以通过,先用
在实践中,可分离滤波器可以通过,先用独立滤波二维信号的每一行,再对每一列进行相同的处理来有效地实现。但这个不是径向对称的,我们修改为下面这个jinc函数:
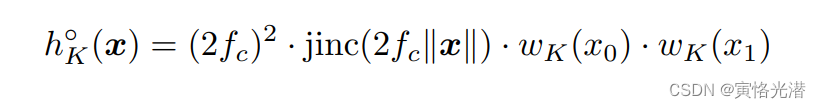
其中的理想的旋转算子公式如下:
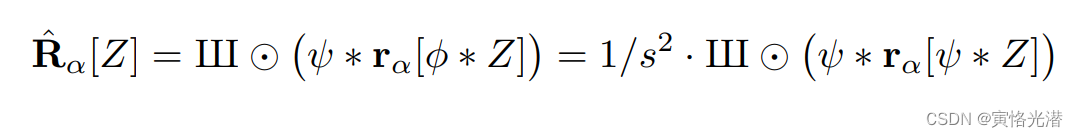
离散采样的输入图像Z与Φ进行卷积,以获得相应的连续表示。然后我们使用旋转这个连续表示,通过与ψ卷积来限制结果的带宽,再通过狄拉克梳状函数提取相应的离散表示。为了减少符号混乱,我们省略了表示采样率s的下标。我们可以交换上面公式中的旋转和卷积的顺序,通过将核旋转到相反的方向来补偿,公式如下:

其中代表一个理想的"旋转滤波器",它对信号的输入和输出都有带宽限制。它的光谱是原矩形和旋转后的矩形的八面多边形交点。
3.10、数据增强
由于我们的数据集本质上是水平对称的,因此我们在所有实验中都启用了数据集x-flip增强。为了防止判别器过拟合,我们启用了自适应判别器增强(ADA),默认设置为METFACES,METFACES-U,AFHQV2和海滩数据集,但禁用FFHQ和FFHQ-U这些高清头像数据集。此外,我们使用迁移学习从具有最低FID的相应FFHQ或FFHQ-U快照中训练METFACES和METFACES-U。
3.11、训练trick
我们模糊了鉴别器在训练开始时看到的所有图像。这个高斯模糊是在ADA增强之前执行的。我们从σ=10像素开始,在前20万张图像中将其渐变为零。这可以防止鉴别器在早期过于集中在高频上。似乎在这种配置中,生成器有时会学习产生具有小延迟的高频率,允许鉴别器从生成的图像中轻松地区分训练数据,而无需向生成器提供有用的反馈。如果没有这个技巧,在训练开始时很容易出现随机训练失败。
3.12、StyleGAN3能耗
计算单位是单个NVIDIA V100 GPU,执行该项目大约需要92年,整个项目消耗了大约225兆瓦时(MWh)的电力,22万5千多度电。其中大约70%用于勘探作业。
而且这个能耗,我们知道是做了很高的性能提升的,比如使用自定义的CUDA内核,我们知道在中间特征映射时,必须在GPU芯片内外的内存之间多次传输,并保留向后传递。这种计算是特别昂贵的,为了克服这个问题,就将整个序列实现为单个操作CUDA内核。由于内存减少,训练性能提高了大约一个数量级,并且还显著降低了GPU内存的使用。原理:计算通过将输出特征映射细分为不重叠的块来并行化,并且每个CUDA线程块计算一个输出块。在输入阶段,将相应的输入区域读入线程块的片上共享内存,所有这些卷积和非线性在片上共享内存操作,只有下采样阶段的最终输出被写入片外GPU内存。
3.13、存在的缺陷
我们来看下手工挑选的风格混合示例:
 coarse粗(0-6)层和fine细(7-14)层使用不同的隐藏编码
coarse粗(0-6)层和fine细(7-14)层使用不同的隐藏编码
在训练中没有使用混合正则化。头部姿势、粗糙的脸型、头发长度和眼镜似乎是从粗层传递下来的,而肤色和更精细的面部特征大多是从细层遗传下来的。当然也存在缺点,比如说有些控制不是很完美,女性/男性特征不能可靠地从一个来源复制。移动细/粗边界解决了这个问题,但其他类似的问题仍然存在。
论文地址:
A Style-Based Generator Architecture for Generative Adversarial Networks
Analyzing and Improving the Image Quality of StyleGAN
Alias-Free Generative Adversarial Networks
源码地址:
https://github.com/NVlabs/stylegan
https://github.com/NVlabs/stylegan2
https://github.com/NVlabs/stylegan3