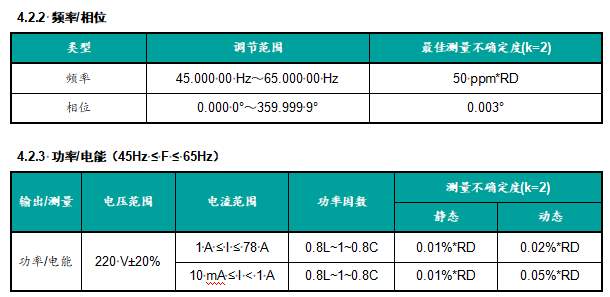
// App.tsx
const id = Math.random();
export default function App() {
return <div id={id}>Hello</div>
}
如果应用是CSR(客户端渲染),id是稳定的,App组件没有问题。
但如果应用是SSR(服务端渲染),那么App.tsx会经历:
-
React在服务端渲染,生成随机id(假设为0.1234),这一步叫dehydrate(脱水) -
<div id="0.12345">Hello</div>作为HTML传递给客户端,作为首屏内容 -
React在客户端渲染,生成随机id(假设为0.6789),这一步叫hydrate(注水)
客户端、服务端生成的id不匹配!
React18推出了官方Hook——useId:
function Checkbox() {
// 生成唯一、稳定id
const id = useId();
return (
<>
<label htmlFor={id}>Do you like React?</label>
<input type="checkbox" name="react" id={id} />
</>
);
);
虽然用法简单,但背后的原理却很有意思 —— 每个id代表该组件在组件树中的层级结构。
这个问题虽然一直存在,但之前一直可以使用自增的全局计数变量作为id,考虑如下例子:
// 全局通用的计数变量
let globalIdIndex = 0;
export default function App() {
const id = useState(() => globalIdIndex++);
return <div id={id}>Hello</div>
}
只要React在服务端、客户端的运行流程一致,那么双端产生的id就是对应的。
但是,随着React Fizz(React新的服务端流式渲染器)的到来,渲染顺序不再一定。
客户端渲染有 reconciler ,服务端渲染有 fizz,他们的作用大概相同,那就是根据某种优先级进行任务调度。于是,无论是客户端还是服务端,都可能不会按照稳定的顺序渲染组件了,这种递增的计数器方案就无法解决问题。
比如,有个特性叫 Selective Hydration,可以根据用户交互改变hydrate的顺序。
当下图左侧部分在hydrate时,用户点击了右下角部分:

此时React会优先对右下角部分hydrate:

关于
Selective Hydration更详细的解释见:New Suspense SSR Architecture in React 18
如果应用中使用自增的全局计数变量作为id,那么显然先hydrate的组件id会更小,所以id是不稳定的。
那么,有没有什么是服务端、客户端都稳定的标记呢?
答案是:组件的层次结构(组件树的层级结构是不变的)
useId的原理
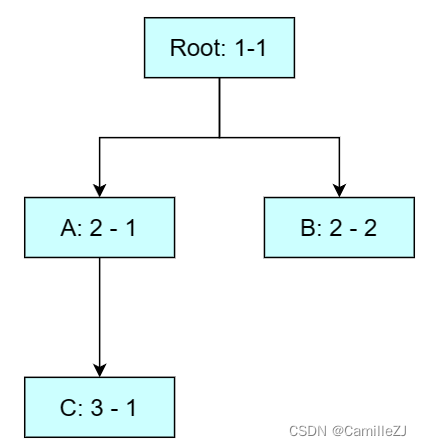
假设应用的组件树如下图:

不管B和C谁先hydrate,他们的层级结构是不变的,所以层级本身就能作为服务端、客户端之间不变的标识。
比如B可以使用2-1作为id,C使用2-2作为id:
function B() {
// id为"2-1"
const id = useId();
return <div id={id}>B</div>;
}
实际需要考虑两个要素:
1. 同一个组件使用多个id
比如这样:
function B() {
const id0 = useId();
const id1 = useId();
return (
<ul>
<li id={id0}></li>
<li id={id1}></li>
</ul>
);
}
2. 要跳过没有使用useId的组件
还是考虑这个组件树结构:

如果组件A、D使用了useId,B、C没有使用,那么只需要为A、D划定层级,这样就能减少需要表示层级。
在useId的实际实现中,层级被表示为32进制的数。(32进制数表示树中节点对应的位置)
之所以选择32进制,是因为选择尽可能大的进制会让生成的字符串尽可能紧凑。比如:
const a = 18;
// "10010" length 5
a.toString(2)
// "i" length 1
a.toString(32)
具体的
useId层级算法参考useId
因为 32 是 toString() 支持的 2 的最大幂。我们希望基数很大,以便生成的 id 是紧凑的,并且我们希望基数是 2 的幂,因为每个 log2(base) 位对应于一个字符,即每个 log2(32) = 5 位 = 1 个基数 32 个字符。这意味着我们可以一次从末尾 5 个中删除位,而不会影响最终结果。
React源码内部有多种栈结构(比如用于保存context数据的栈)。
useId 栈的逻辑是其中比较复杂的一种。
谁能想到用法如此简单的API背后,实现起来居然这么复杂?
兴趣了解:身份生成算法
身份 id 是 32 进制的字符串,其二进制表示对应树中节点的位置。
每次树分叉成多个子节点时,我们都会在序列的左侧添加额外的位数,表示子节点在当前子节点层级中的位置。
00101 00010001011010101
╰─┬─╯ ╰───────┬───────╯
Fork 5 of 20 Parent id
这里我们使用了两个前置 0 位。如果只考虑当前的子节点,我们使用 101 就可以了,但是要表达当前层级所有的子节点,三位就不够用。因此需要 5 位。
出于同样的原因,slots 是 1-indexed 而不是 0-indexed。否则就无法区分该层级第 0 个子节点与父节点。
如果一个节点只有一个子节点,并且没有具体化的 id,声明时没有包含 useId hook。那么我们不需要在序列中分配任何空间。例如这两颗数会产生相同的 id:
<> <> <Indirection> <A /> <A /> <B /> </Indirection> </> <B /> </>
但是我们不能跳过任何包含了 useId 的节点。否则,只有一个子节点的父节点就无法区分开来。比如,这棵树只有一个子节点,但是父子节点必须有不同的 id
<Parent> <Child /> </Parent>
为了处理这种情况,每次我们生成一个 id 时,都会分配一个一个新的层级。当然这个层级就只有一个节点「长度为 1 的数组」。
最后,序列的大小可能会超出 32 位,发生这种情况时,我们通过将 id 的右侧部分转换为字符串并将其存储在溢出变量中。之所以使用 32 位字符串,是因为 32 是
toString() 支持的 2 的最大幂数。这样基数足够大就能够得到紧凑的 id 序列,并且我们希望基数是 2 的幂,因为每个 log2(base) 对应一个字符,也就是 log2(32) = 5 bits = 1 ,这样意味着我们可以在不影响最终结果的情况下删除末尾 5 的位。
和其他的 hook 一样,执行useId 会在 mount 阶段会调用 mountId,在 update 阶段会调用 updateId
mount 阶段
可以看到 mountId 会做以下几件事情
- 创建 hook 对象
- 获取当前组件的 root Fiber 上的
identifierPrefixid 前缀 - 判断是 SSR 还是 CSR
- SSR 会根据 Tree 来生成 Id,并夹杂大写字母 R
- CSR 会根据一个全局变量来生成自增的 Id,夹杂小写字母 r
- 最后挂载到
memoizedState上
function mountId(): string {
const hook = mountWorkInProgressHook();
const root = ((getWorkInProgressRoot(): any): FiberRoot);
const identifierPrefix = root.identifierPrefix;
let id;
if (getIsHydrating()) {
const treeId = getTreeId();
// Use a captial R prefix for server-generated ids.
id = ':' + identifierPrefix + 'R' + treeId;
const localId = localIdCounter++;
if (localId > 0) {
id += 'H' + localId.toString(32);
}
id += ':';
} else {
// Use a lowercase r prefix for client-generated ids.
const globalClientId = globalClientIdCounter++;
id = ':' + identifierPrefix + 'r' + globalClientId.toString(32) + ':';
}
hook.memoizedState = id;
return id;
}
注意
identifierPrefix: React 用于生成的 id 的可选前缀,在同一页面上使用多个根时避免冲突很有用。必须与服务器上使用的前缀相同。
hydrateRoot(container, element[, options])
写在 options 里的
重点需要放到这个 getTreeId 的方法上,这个函数究竟是如何工作的呢?
getTreeId
getTreeId 使用组件的树状结构(在客户端和服务端都绝对稳定)来生成id。这里涉及到了 React 的 Id 生成算法具体可以看这个 PR
为了让 Id 更加的紧凑,并不是所有的组件都会生成 ID,只有调用了 useId 的组件才会生成 Id,并且 Id 是连续的,如果有其中一层组件没有调用 useId 那就跳过这一层
在 useId 的实际实现中,层级被表示为32进制的数。
如果 组件的层数超过了 32 进制数能表达的数时,会通过 treeContextOverflow 来将超出的几位截断,转成字符串,继续拼接在 id 的后面
export function getTreeId(): string {
const overflow = treeContextOverflow;
const idWithLeadingBit = treeContextId;
const id = idWithLeadingBit & ~getLeadingBit(idWithLeadingBit);
return id.toString(32) + overflow;
}
update 阶段
update 时,不需要做什么事情,获取 id 返回即可
function updateId(): string {
const hook = updateWorkInProgressHook();
const id: string = hook.memoizedState;
return id;
}你应该在以下情况下使用 useId:
- 你想生成唯一 ID
- 你想要连接 HTML 元素,比如 label 和 input。
在以下情况下不应该使用 useId:
- 映射列表后需要 key。
- 你需要定位 CSS 选择器。useId 生成一个包含 : 的字符串 token字符串,这有助于确保 token 是唯一的,如下面的示例所示。但在 CSS 选择器或
querySelectorAll等 API 中不受支持。 - 你正在使用不可变的值。