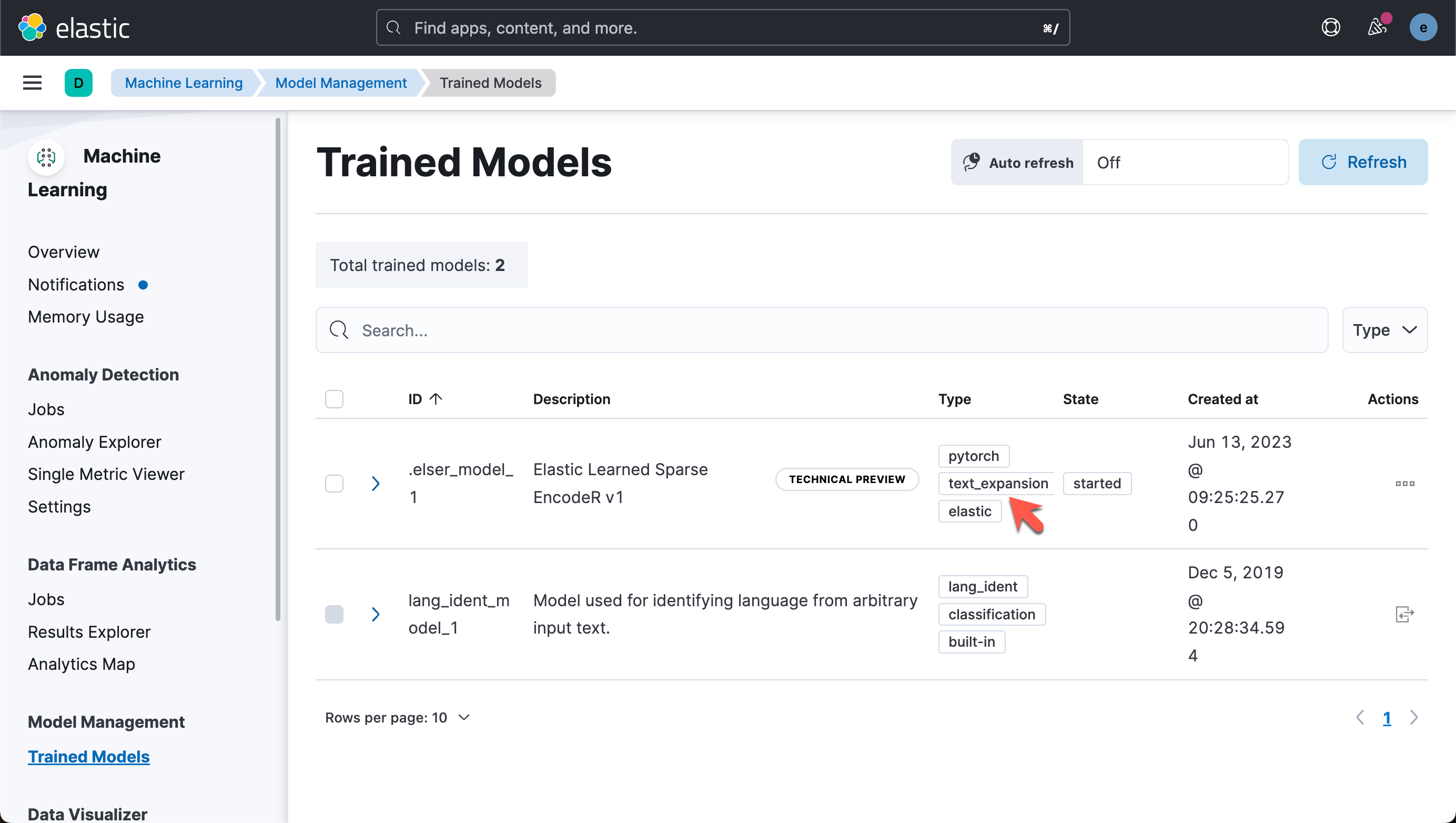
1. 前言
在学习 CreateML 之前,我们先了解一下什么是机器学习?目前还不存在被广泛认可的定义来准确定义机器学习是什么。第一个机器学习的定义来自于Arthur Samuel。他定义机器学习为,在进行特定编程的情况下,给予计算机学习能力的领域。Samuel的定义可以回溯到50年代,他编写了一个西洋棋程序。这程序神奇之处在于编程者自己下棋很菜,但是他通过编程,让西洋棋程序自己跟自己下了上万盘棋,久而久之,这西洋棋程序明白了什么是好布局,什么是坏布局。通过学习后的程序,玩西洋棋的水平远超过了Samuel。上述是有点不正式的定义,也比较古老。
另一个年代近一点的定义,由Tom Mitchell提出,来自卡内基梅隆大学,Tom定义的机器学习是,程序能从经验E中学习,解决任务T,达到性能度量值P,当且仅当有了经验E后,经过P评判,程序在处理T时的性能有所提升。 上面的例子中,经验 E 就是程序上万次的自我练习的经验而任务 T 就是下棋。性能度量值 P 呢,就是它在与一些新的对手比赛时,赢得比赛的概率。
机器学习可以分为监督学习(Supervised Learning)和非监督学习(Unsupervised Learning),监督学习的基本思想是,我们数据集中的每个样本都有相应的输出,再根据这些样本作出预测。非监督学习中,是将一系列无标签的训练数据,输入到一个算法中,然后我们告诉这个算法,快去为我们找找这个数据的内在结构给定数据。
2. CreateML 是什么
Create ML 是苹果于2018年 WWDC 推出的生成机器学习模型的工具,它是通过机器学习算法,训练出模型,来解决实际问题。CreateML 所涉及的训练都是监督学习,主要处理分类问题、回归问题以及推荐,对应的是 MLClassifier、MLRegressor 以及 MLRecommender。下面主要介绍对应的机器学习的背景知识,来帮助大家更好的理解。
大概介绍一下 CreateML 是怎么训练模型的,它可以利用系统(iOS 12 或 macOS Mojave )内置的机器学习基础设施进行迁移学习(Transfer Learning),这种训练需要少量数据就足够了,训练出来的模型是将苹果内置模型最后几层由我们的数据训练。这样训练时间大大减少,甚至几秒钟就能训练完成。模型大小也可以减少到 kb 级别,更容易接入到我们的 App 中。虽然要求少量数据也不能无中生有,想找数据的同学可以从这里找找看。
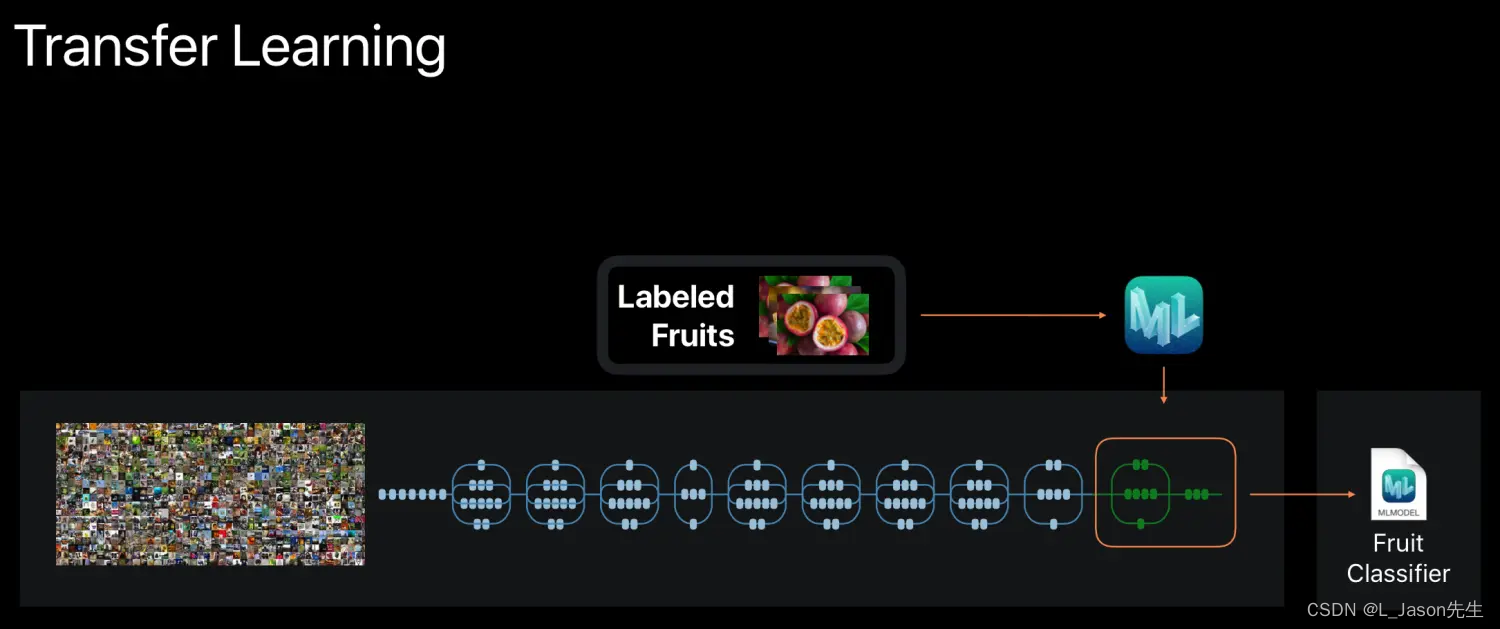
3. 什么是分类问题
让我们来看一组数据:这个糖尿病预测的数据集中,前8列为特征,最后一列为 label,1和0表示是否为糖尿病。
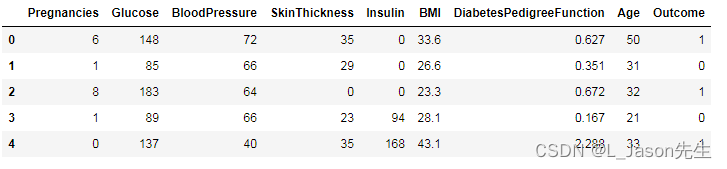
那么机器学习的问题就在于,你能否估算出其他人是否患有糖尿病。用术语来讲,这是一个分类问题。
分类指的是,我们试着推测出离散的输出值:0或1是否患病,而事实上在分类问题中,输出可能不止两个值。比如说可能有两种糖尿病,所以你希望预测离散输出0、1、2。0 代表未患糖尿病,1 表示第1类糖尿病,2表示第2类糖尿病,但这也是分类问题。
所以在使用 CreateML 时,也就需要传入训练数据,以及标签的列(labelColumn)以及特征的列(featureColumn),根据实际情况是可以支持多个或者一个多 Column 的。
当然看图识物也是分类问题,它的输入是图片或者视频的一帧的所有像素点,为了提高计算效率以及准确度还会通过池化层、卷积层等来对原始特征进行处理。
Create ML 中不同的分类器(Classifier),会设定对应的 DataSource 来描述特征以及标签。这是音频相关的注释信息。
/// - featureColumn: The name of the column that contains the audio
// features.
///
/// - labelColumn: The name of the column that contains the audio
/// labels.
4. 什么是回归问题
举一个例子,估计火星房价,我们可以应用学习算法,在这组数据中画一条直线,或叫做拟合一条直线,根据这条线我们可以推测出,太阳能电池板数为 3 时的价格,当然这不是唯一的算法。可能还有更好的,比如我们不用直线拟合这些数据,还可以根据实际情况采用二次方程或者更高阶的方程去拟合。
假设房价只精确到整数,所以房价实际上是一系列离散值,但是我们通常又把房价看成实数,即一个连续的数值。
回归这个词的意思是,我们在试着推测出这一系列连续值属性。这就是回归问题,即通过回归来推出一个连续的输出。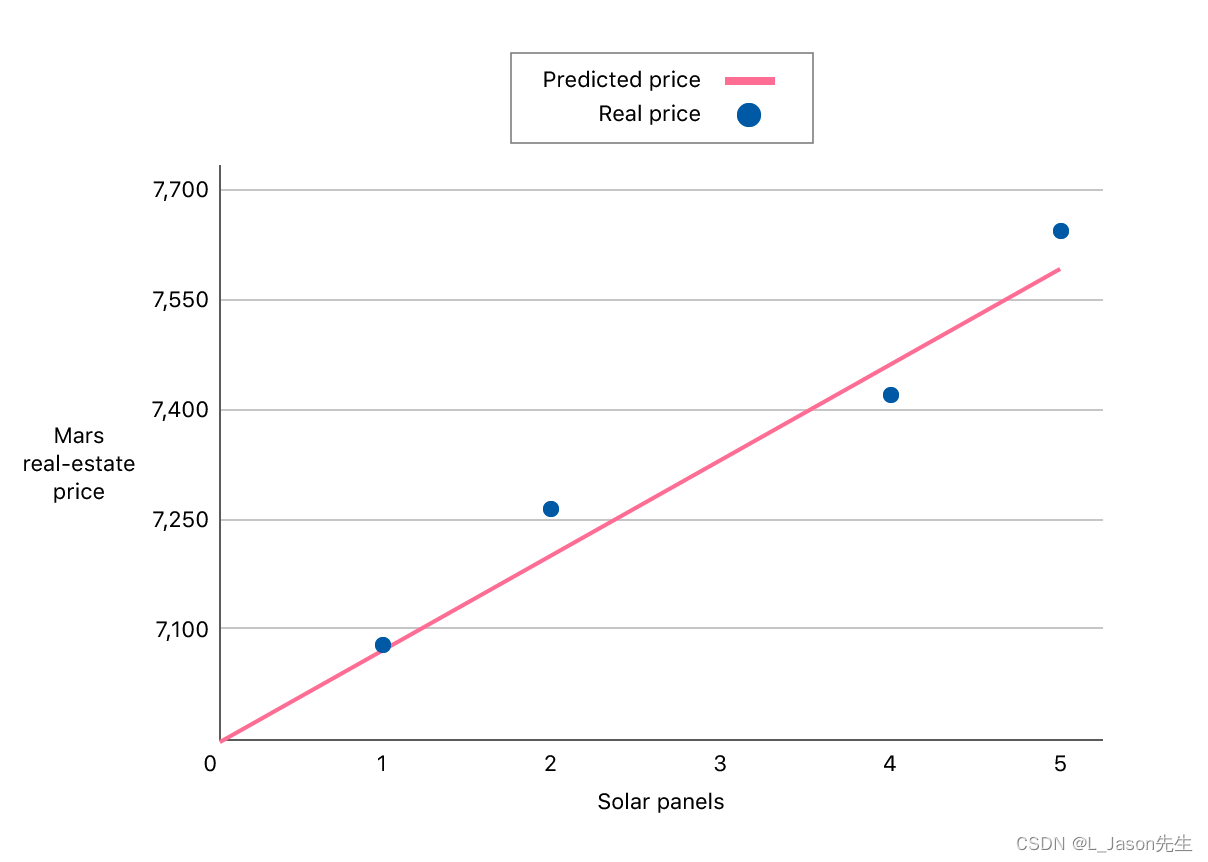
回归问题在 CreateML 训练模型的时,需要传入的数据也基本一致,也就需要传入训练数据,以及标签列(这里命名叫做 targetColumn, 本质还是一样的)以及特征的列(featureColumn)
/// - targetColumn: A String specifying the target column name in the trainingData
/// - featureColumns: An optional list of Strings specifying feature columns to be
/// used to predict the target, if not provided, default to use all the
/// other columns in the trainingData, except the one specified by targetColumn
5. 推荐系统
推荐系统可能大家比较陌生一些,下面举个例子来定义推荐系统的问题。
假设我们是电影供应商,我们有 5 部电影和 4 个用户,我们要求用户为电影打分。
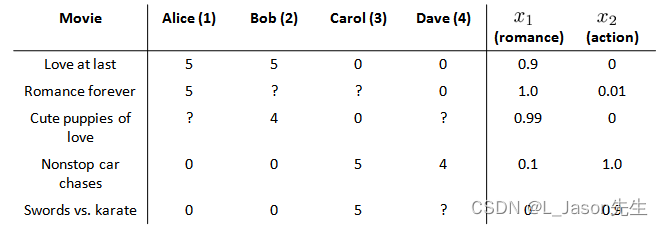
前三部电影是爱情片,后两部是动作片,我们可以看出Alice和Bob似乎更倾向与爱情片, 而 Carol 和 Dave 似乎更倾向与动作片。并且没有一个用户给所有的电影都打过分。我们希望构建一个算法来预测他们每个人可能会给他们没看过的电影打多少分,并以此作为推荐的依据。
在这个例子是属于推荐问题的一种形式,我们假设每部电影都有两个特征,如 x1 代表电影的浪漫指数,x2 代表电影的动作指数。[x1, x2] 就是电影的特征,我们可以通过特征数据对每个人进行线性回归,来补充其他电影的打分,这种是基于内容的推荐系统(Content Based Recommendations),想详细了解的可以从这里看。
上面这个例子我们有用户参数,也有电影的特征,其实还有一种推荐问题的形式,就是这两种我们都没有,这个该如何解决呢。目前是有协同过滤算法(Collaborative Filtering)是可以同时学习这两者的,相当于自我学习特征,学习的这些数据不是都能读懂的,但是可以用这些数据作为给用户推荐电影的依据。想了解详细内容的可以从这里看。
从上面的介绍我们可以看到,训练数据包括三部分,被推荐的元素,用户以及评分,在 CreateML 中我们我们训练数据也需要包含这三列数据
/// - itemColumn: Name of the Int or String typed column in the training data containing item identifiers.
///
/// - userColumn: Name of the Int or String typed column in the training data containing user identifiers.
///
/// - ratingColumn: Name of an Int or Double typed column optionally in the training data containing scores or ratings.
/// The default is nil, which corresponds to no rating column.
6 如何训练推荐模型
6.1 使用 CreateML App
CreatML App 来训练,简单易用的可视化操作,直接拖动数据即可,这里有篇文章介绍了各个模型类型,还有举例如何使用,可以从这里看
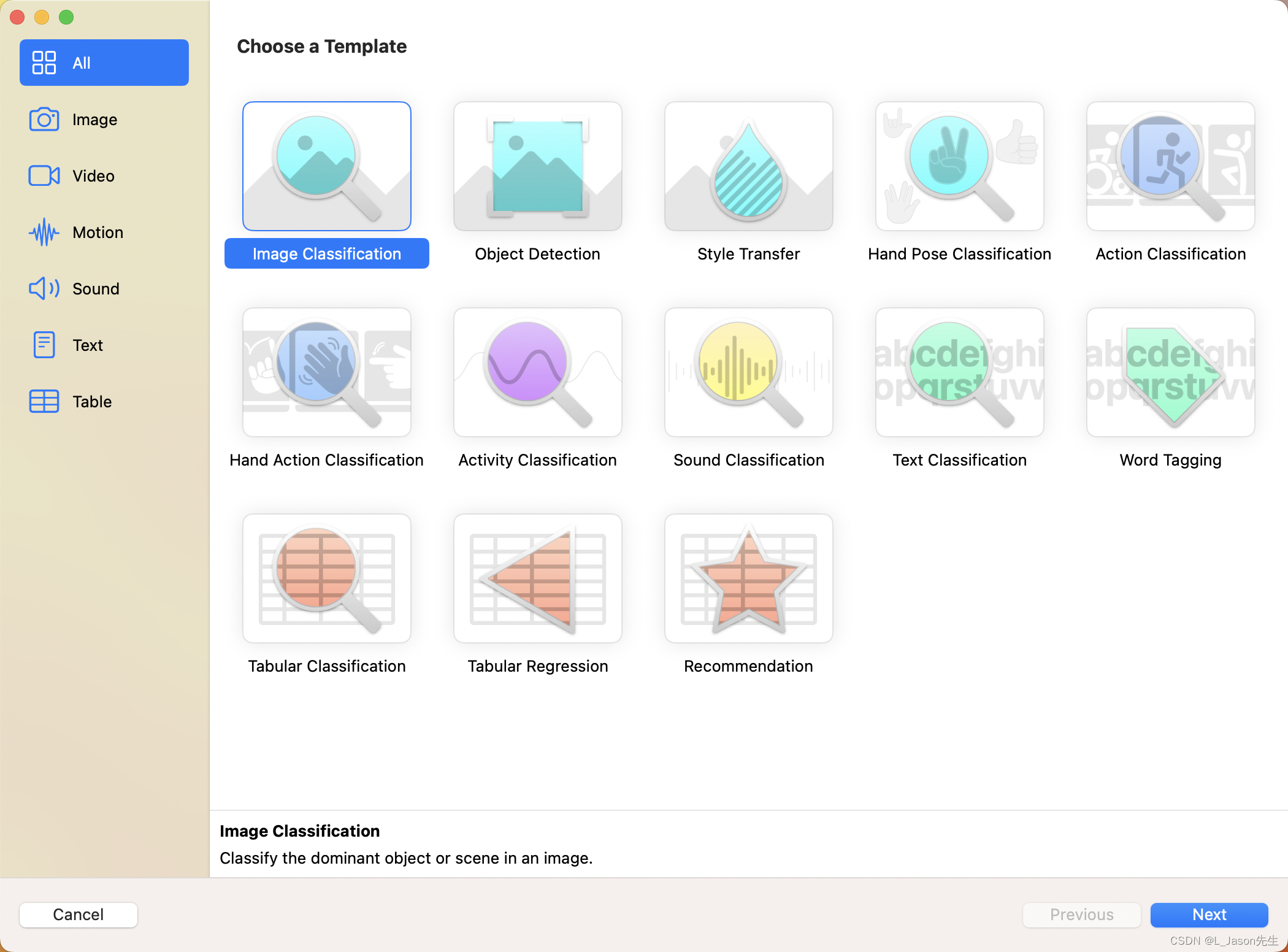
再补充一个如何训练图片分类的链接
6.1 使用 Swift 代码训练
代码也是比较方便的,下面举一个 MLTextClassifier 的例子,其他类型除了数据格式不同一起,使用基本是一致的。推逻辑回归代码示例可以查看参考文章[5],数据准备会有所不同,使用起来是基本一致的
这个模型训练目的是,分析一句话,判断这句话的态度是积极的还是消极的。
第一步,准备数据,数据文件的格式是 csv,数据一共分为两列,其中 class 是标签列,text 是特征列,标签列和特征列的名称可以根据需要来自己定义,先后顺序可以任意
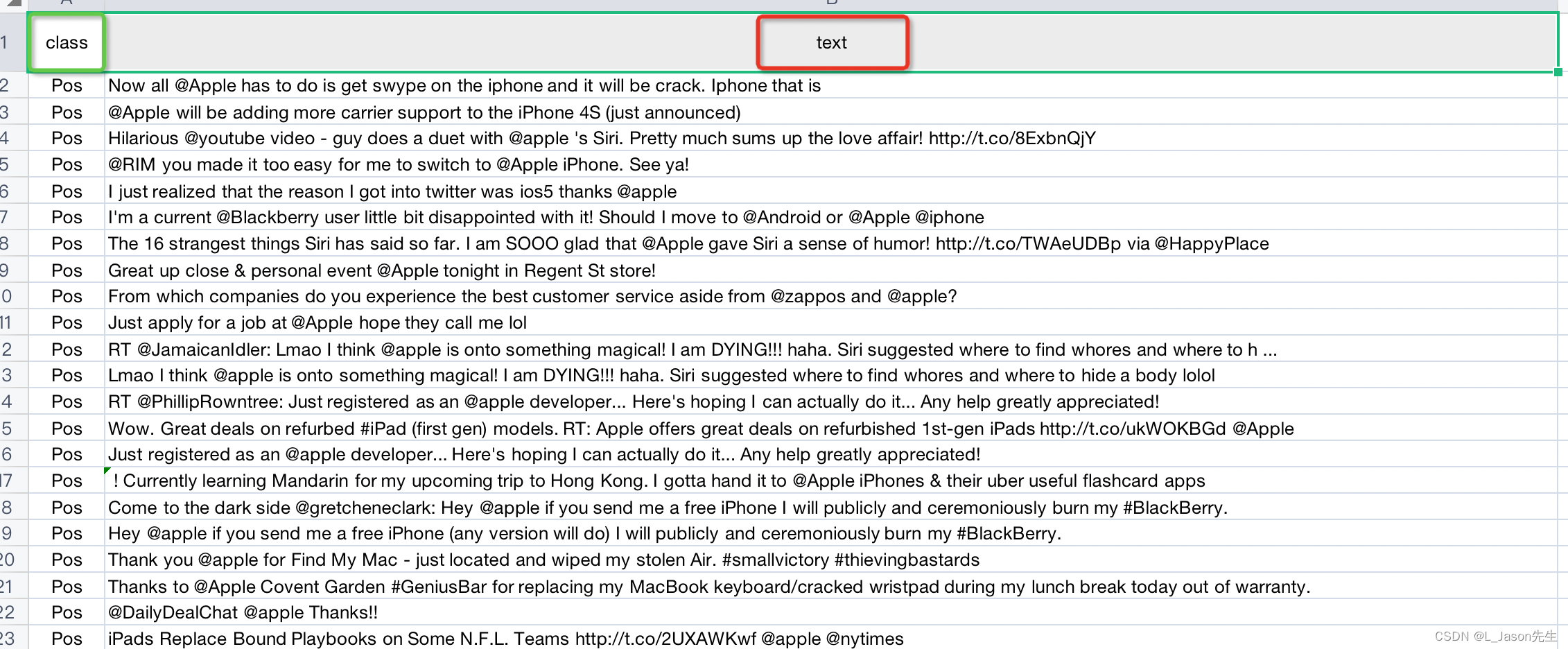
第二步,训练和评估模型,模型训练模型完成之后,还需要评估模型是否准确率。所以我们的训练数据可以分为两部分,分一大部分用于训练,一小部分用于评估验证,这个例子是训练和验证的数据比例是 9:1,可以根据数据量来灵活调整。
其中 metrics.classificationError 来表示在验证集数据的错误率,如果错误率比较高,可以调整数据集,或者更新算法等来调整。
目前训练 API 有更新,下面这个例子是使用 MLDataTable 数据格式,在macOS 13.0 以及 iOS 16.0 版本已经弃用了,具体接口可以根据设备的系统版本来选择就好,新版本的 MLTextClassifier.DataSource 也可以支持多个标签,可以随机分配多组来进行交叉验证,降低过拟合、欠拟合等问题。
guard let url = mlFileURL,
let allData = try? MLDataTable(contentsOf: url) else {
return
}
let data: TrainingData = allData.randomSplit(by: 0.9)
guard let classfier = try? MLTextClassifier(trainingData: data.trainingData, textColumn: "text", labelColumn: "class", parameters: MLTextClassifier.ModelParameters()) else {
return
}
let metrics = classfier.evaluation(on: data.testData, textColumn: "text", labelColumn: "class")
print("classificationError: \(String(describing: metrics.classificationError))")
第三步,如果模型好用可以保存下来
// 保存模型
func saveModel(toFile: String) {
try? classfier?.write(toFile: toFile)
}
第四步,使用模型预测数据
这个像调用函数一样,非常简单了,输入一段文本,查看预测结果就可以了。
func prediction(_ text: String) {
guard let ret = try? classfier?.prediction(from: text) else {
print("prediction error")
return
}
print("prediction result: \(String(describing: ret))")
}
6.参考文章:
- WWDC 2018:初探 Create ML
- CreateML: Start Your Adventure in Machine Learning with Swift
- MLDataTable: The Panda For iOS Developers
- CreateML 使用以及在 iOS 中应用介绍
- Build a Core ML Movie Recommender SwiftUI App Using CreateML








![千万级入口服务[Gateway]框架设计(一)](https://img-blog.csdnimg.cn/e5220fc8d4844163b92429ee98a58fba.png)