警告:此功能处于技术预览阶段,可能会在未来的版本中更改或删除。 Elastic 将尽最大努力修复任何问题,但技术预览中的功能不受官方 GA 功能的支持 SLA 约束。
Elastic Learned Sparse EncodeR - 或 ELSER - 是由 Elastic 训练的检索模型,使你能够执行语义搜索以检索更相关的搜索结果。 此搜索类型为您提供基于上下文含义和用户意图的搜索结果,而不是精确的关键字匹配。
ELSER 是一种域外(out-of-domain)模型,这意味着它不需要对你自己的数据进行微调,因此可以开箱即用地适应各种用例。
ELSER 将索引和搜索的段落扩展为术语集合,这些术语被学习为在不同的训练数据集中经常共同出现。 模型将文本扩展成的术语不是搜索术语的同义词; 他们是博学的协会。 这些扩展的术语被加权,因为其中一些比其他的更重要。 然后 Elasticsearch rank-feature 字段类型用于在索引时存储术语和权重,并在以后进行搜索。
以下安装是在 Elastic Stack 8.8 下完成的。
要求
要使用 ELSER,你必须具有相应的语义搜索(semantic search)订阅级别或激活试用期。
安装
如果你还没有安装好自己的 Elasticsearch 及 Kibana,请参阅如下的链接来进行安装:
-
如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch
-
Kibana:如何在 Linux,MacOS 及 Windows 上安装 Elastic 栈中的 Kibana
在安装的时候,请注意选择 Elastic Stack 8.x 的指南来进行安装。我们需要安装 Elastic Stack 8.8 及以上版本。
启动白金试用
由于语义搜索是一个机器学习的范畴,是一个收费的功能。如果我们不启动试用版本,那么在下载的时候,会出现如下的错误信息:

我们按照如下的方式来启动白金试用:


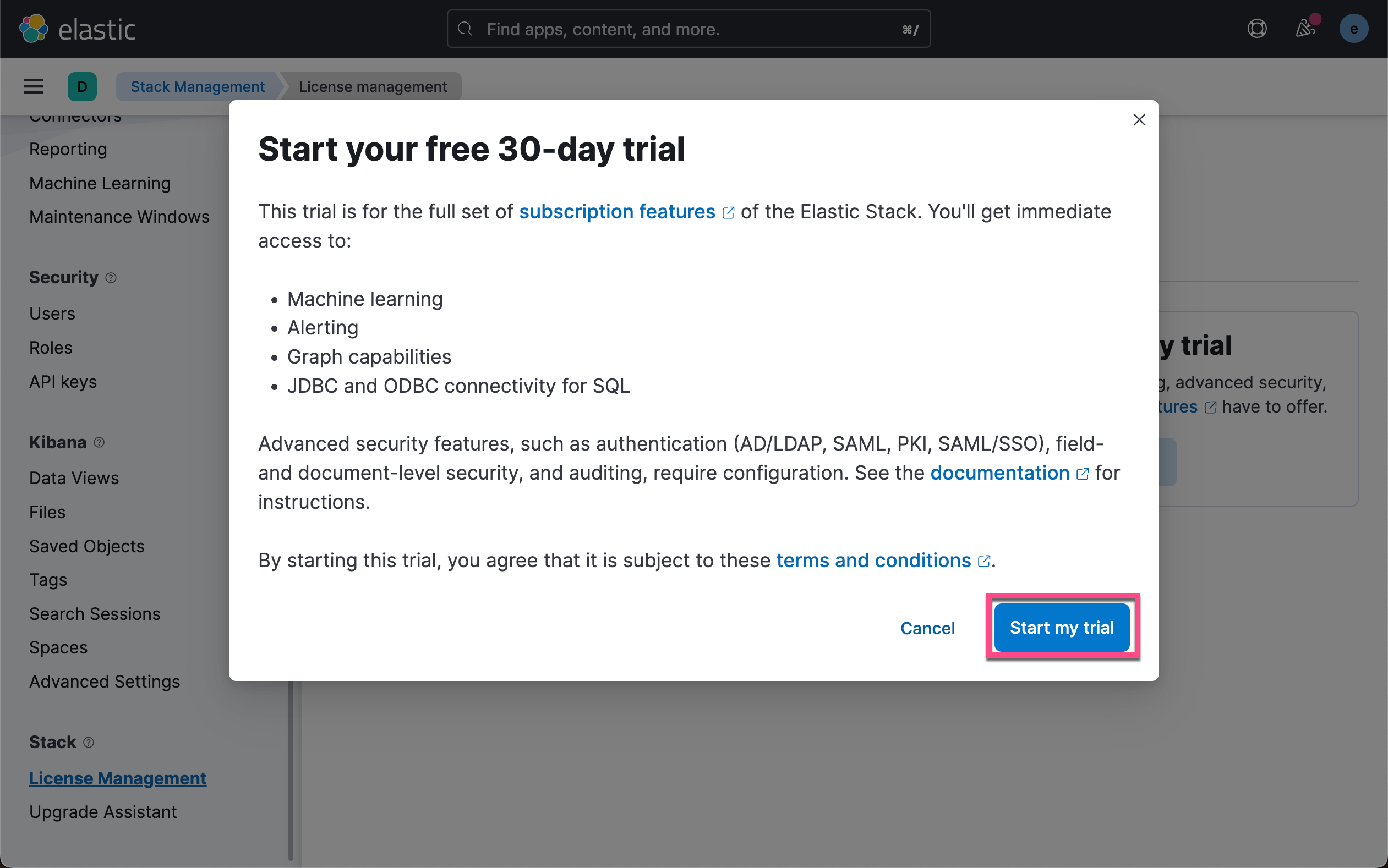

这样,我们试用授权已经启动了。
下载并部署 ELSER
我们有如下的三种方法来下载并部署 ELSER:
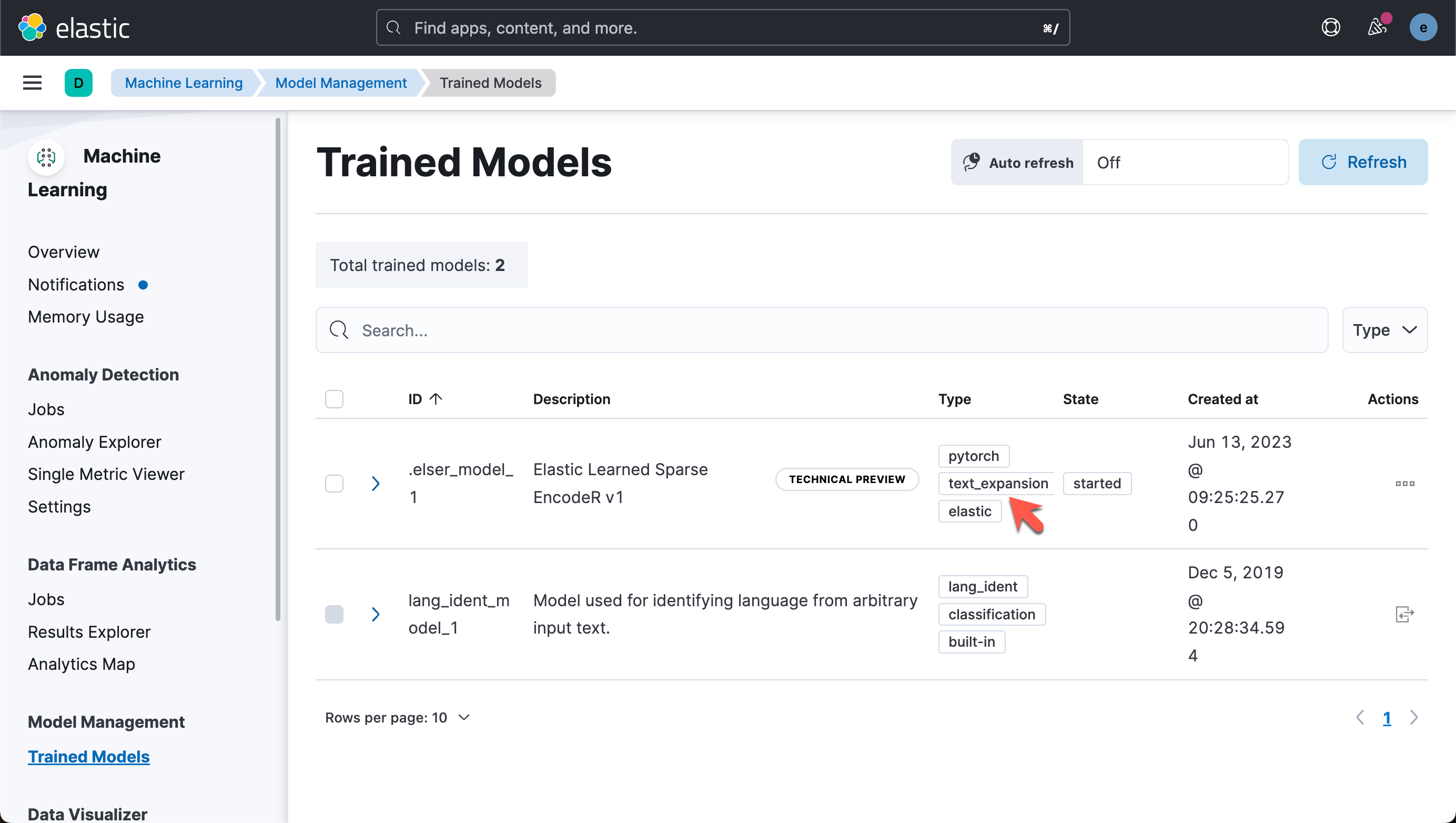
- Machine Learning => Trained Models
- Enterprise Search => Indices
- 通过 Dev Console
下面,我们来详细介绍它的步骤。
通过机器学的 Trained Model 页面



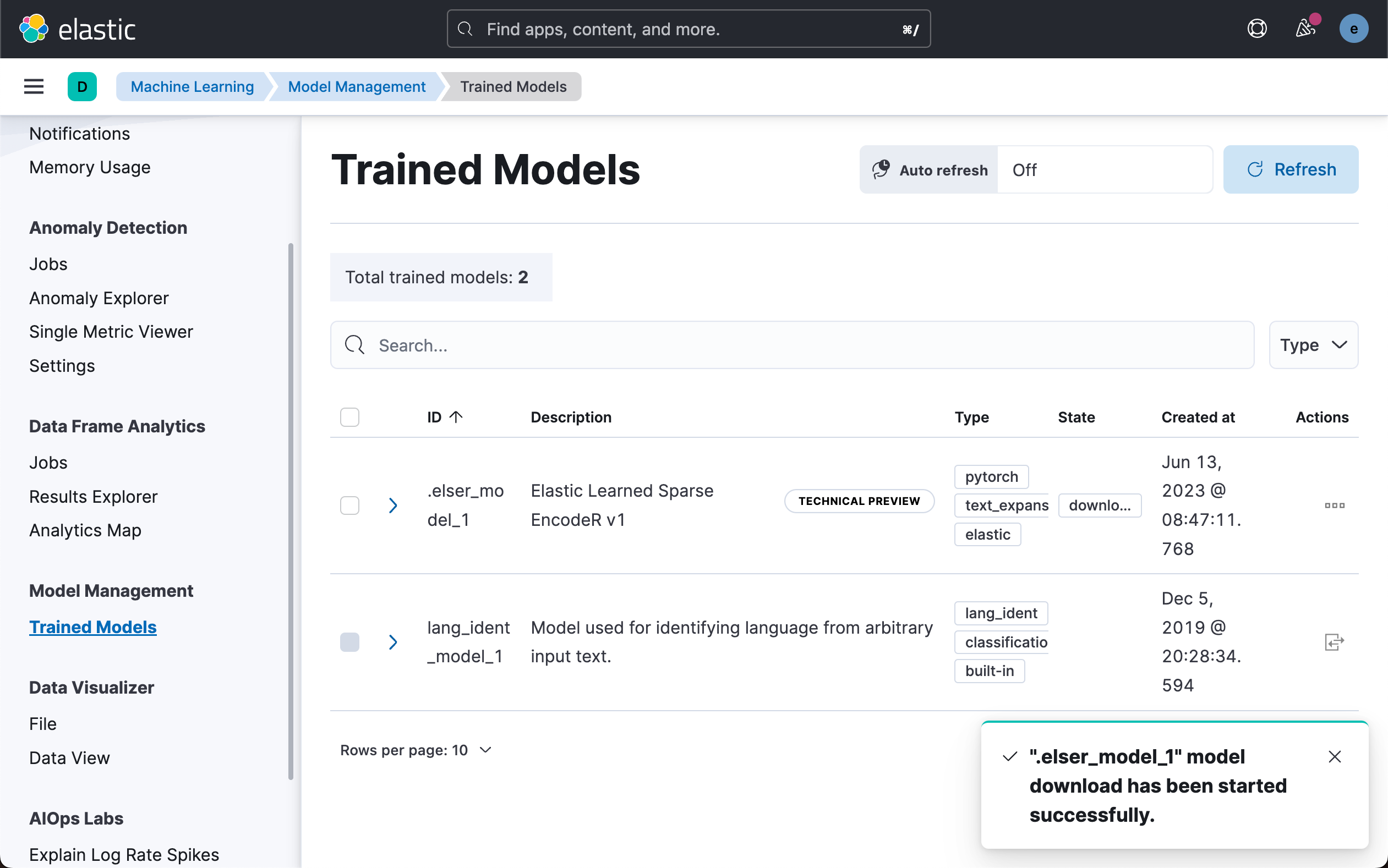
上面显示:

我们可以看到它正在下载当中。我们需要等待一点时间。

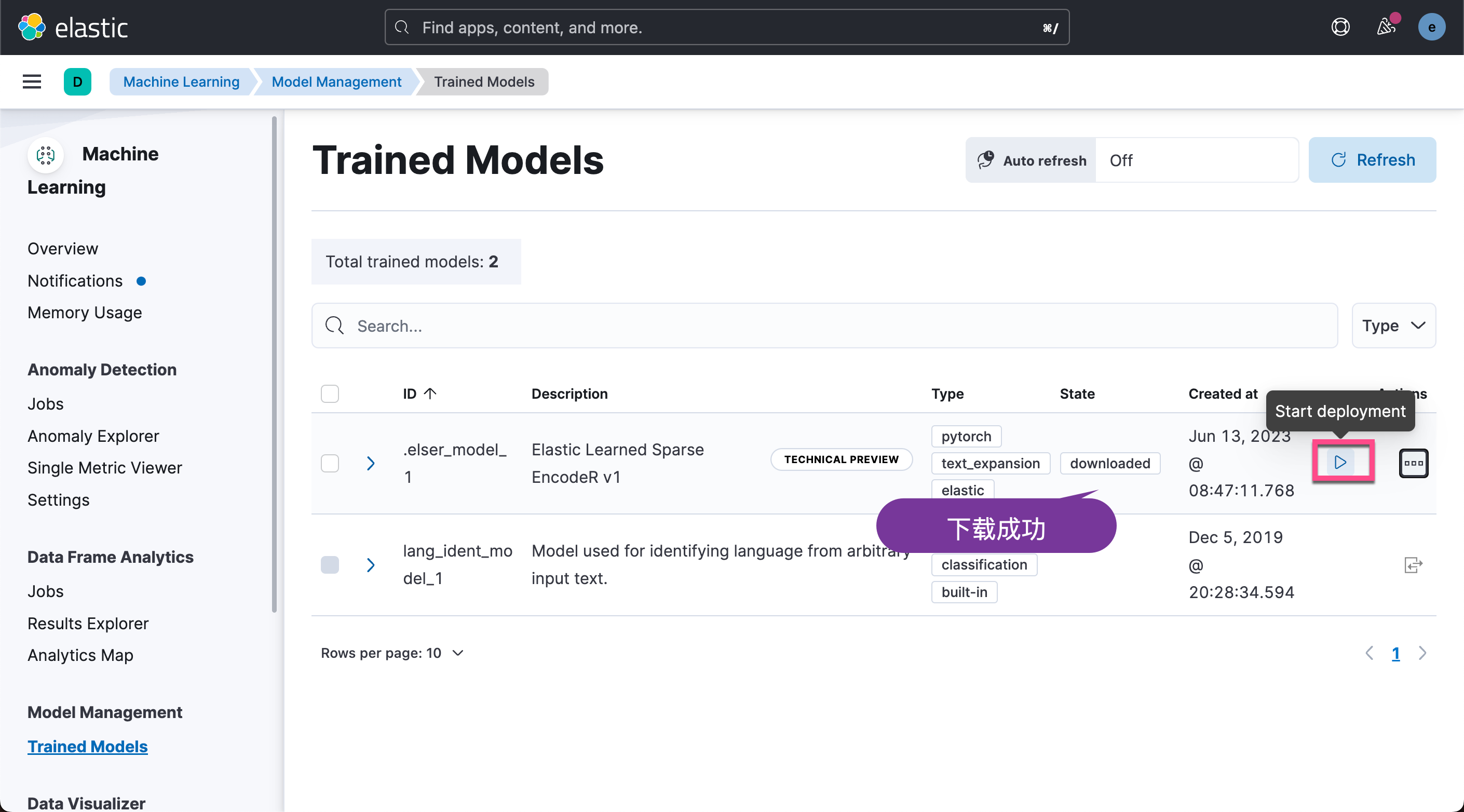
我们点击 Play 按钮来进行部署。


至此,我们已经成功地部署了 ELSER。
通过 Enterprise Search 中的 Indices 页面
针对 Enterprise search 的安装,请参考文章 “Enterprise:使用 Elastic Stack 8.2 中的 Elasticsearch API 来定位 App Search 中的文档”。
你还可以直接从 Enterprise Search 应用下载 ELSER 并将其部署到推理管道。如果你的 Elasticsearch 还没有任何的索引的话,你可以使用类似如下的命令来创建一个索引:
PUT twitter/_doc/1
{
"name": "Xiaoguo Liu from Elastic"
}上述命令将生成一个叫做 twitter 的索引。





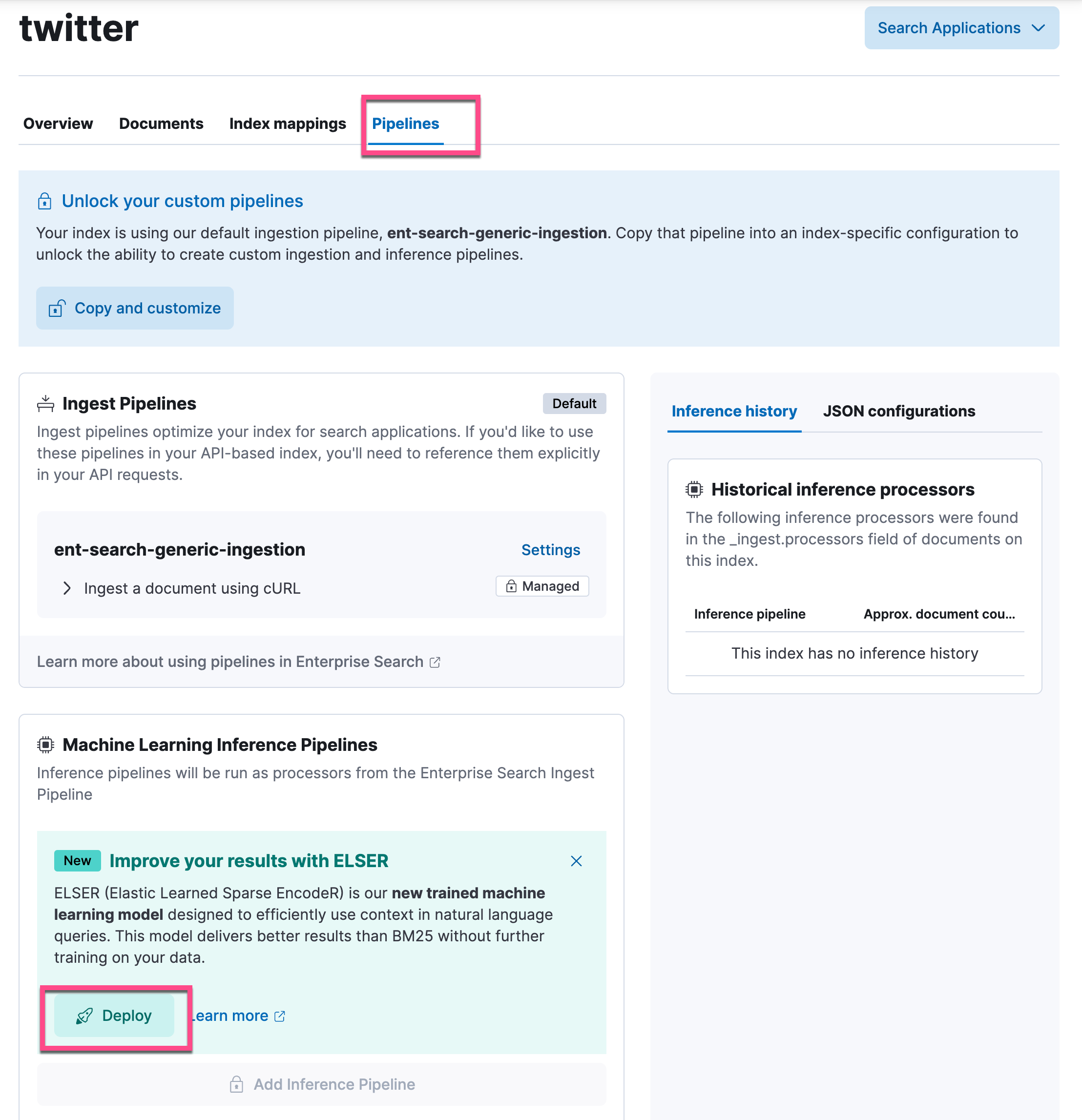



从上面我们可以看出来模型已经被成功地部署。我们可以在这个页面进行配置它的部署。
使用 Dev Console 来进行部署
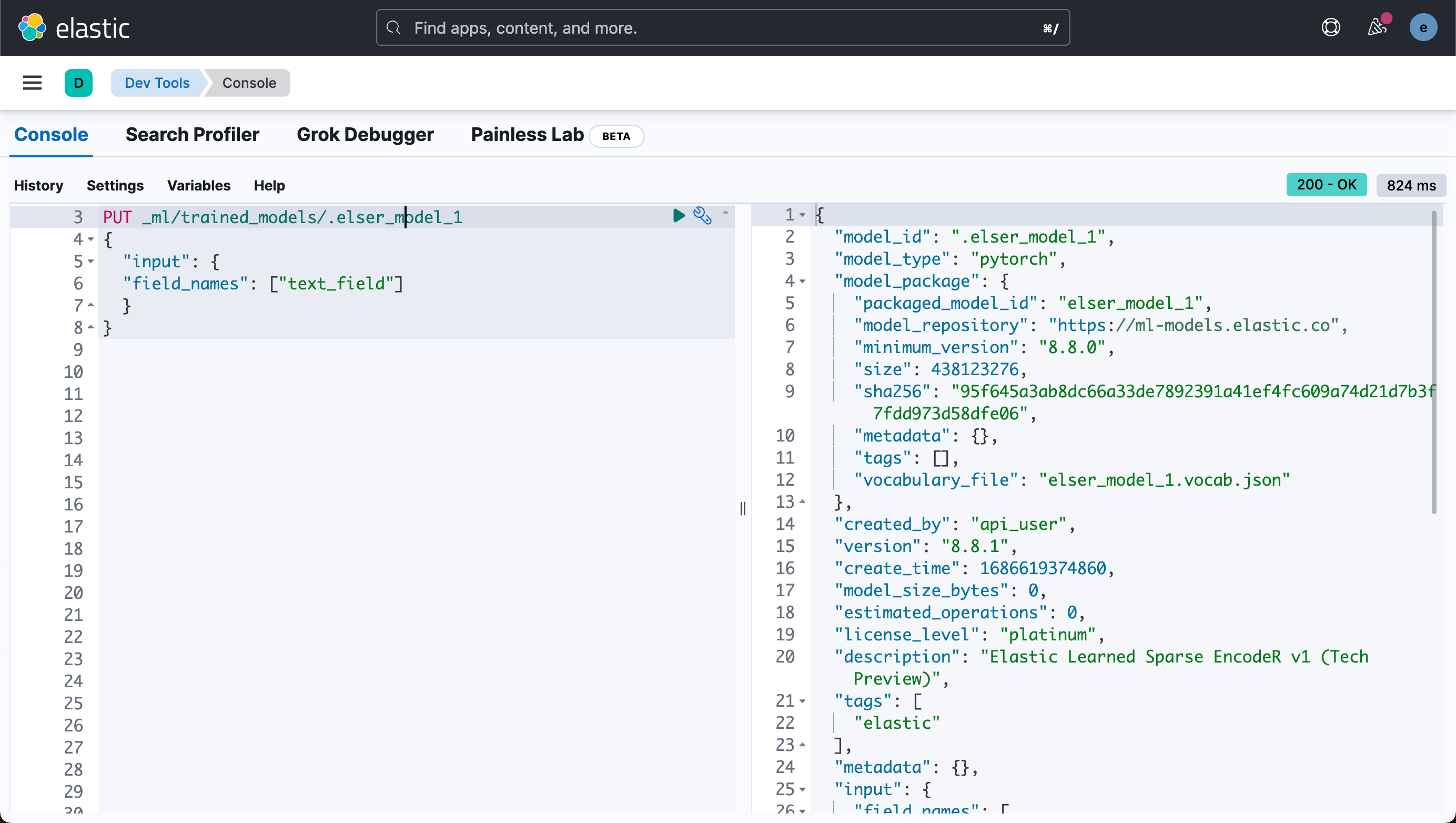
我们在 Dev Tools 中,通过运行以下 API 调用创建 ELSER 模型配置:
PUT _ml/trained_models/.elser_model_1
{
"input": {
"field_names": ["text_field"]
}
}
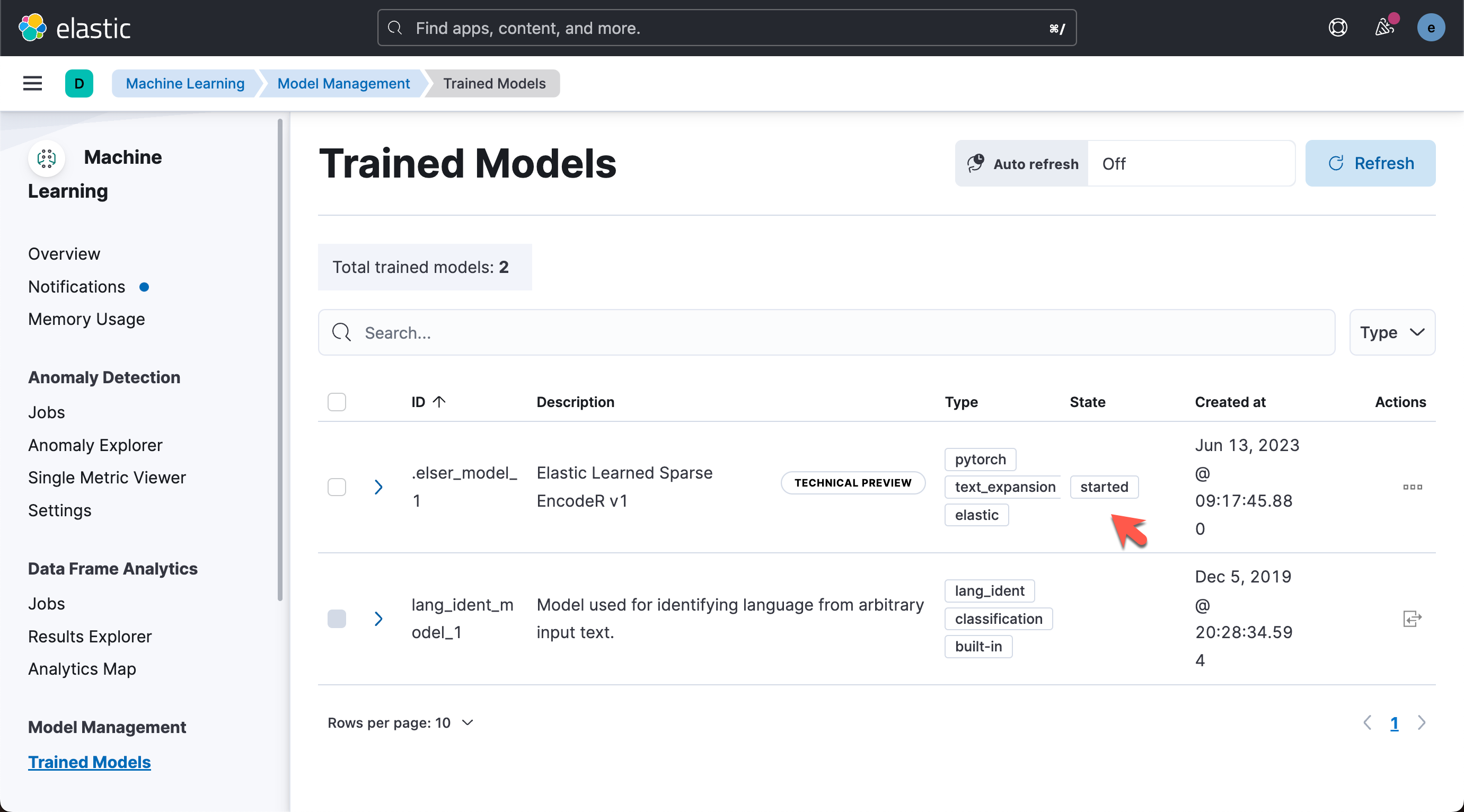
如果尚未下载模型,API 调用会自动启动模型下载。
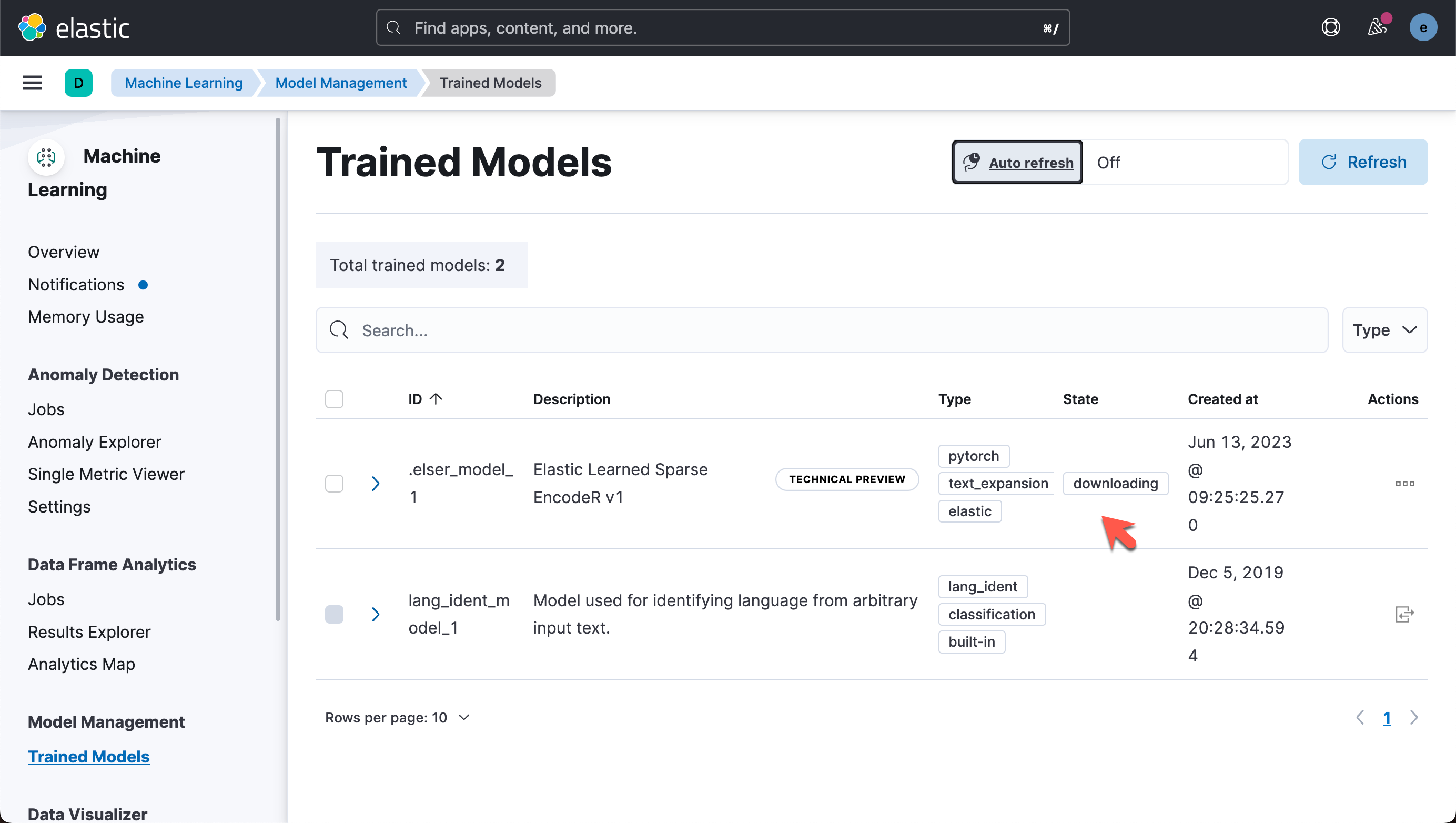
等过一会儿,我们可以看到如下的页面:

我们可以在机器学习的 Trained Models 里进行查看。
我们可以使用带有 delpoyment ID 的开始训练模型部署 API 来部署模型:
POST _ml/trained_models/.elser_model_1/deployment/_start?deployment_id=for_search

我们可以在机器学习的页面查看它的状态。上面显示已经是 started 状态。你可以使用不同的部署 ID 多次部署模型。
以下示例为 ID 为 my_model_for_ingest 的 .elser_model_1 训练模型启动新部署。 部署 ID 可用于推理 API 调用或推理处理器。
POST _ml/trained_models/.elser_model_1/deployment/_start?deployment_id=my_model_for_ingest可以使用不同的 ID 再次部署经过 my_model 训练的模型:
POST _ml/trained_models/.elser_model_1/deployment/_start?deployment_id=my_model_for_search部署完成后,ELSER 就可以在摄取管道或 text_expansion 查询中使用以执行语义搜索。
如何使用 ELSER 模型
我们可以使用如下的命令来进行测试:
POST /_ml/trained_models/.elser_model_1/_infer
{
"docs": {
"text_field": "how is the weather in jamaica"
}
}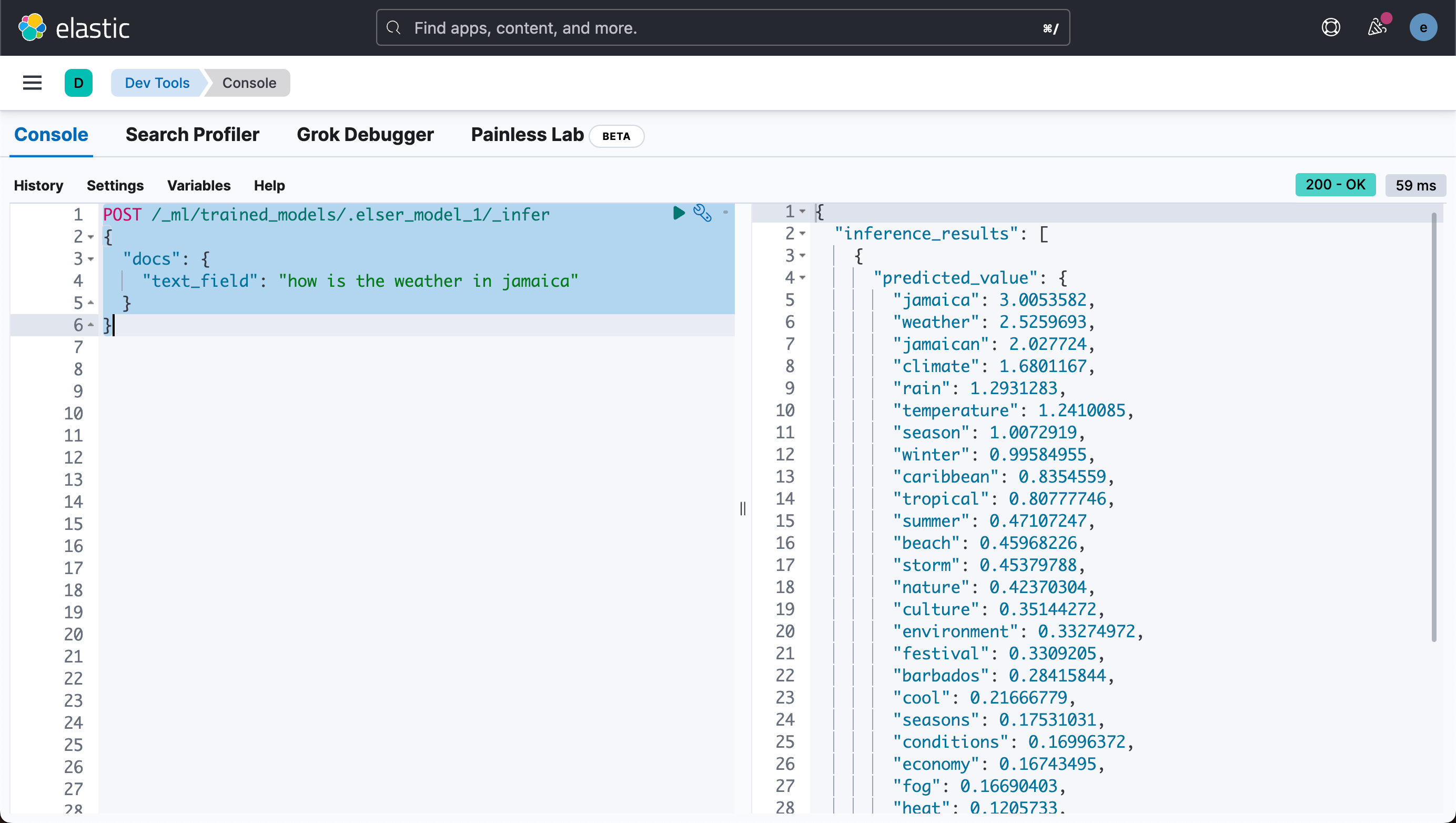

从上面我们可以看出来它是一个 text_expansion 类型的模型:
在气隙环境中部署 ELSER
如果你想在受限或封闭的网络中部署 ELSER,你有两种选择:
- 创建你自己的带有模型工件的 HTTP/HTTPS 端点,
- 将模型工件放入所有符合主节点条件的配置目录内的目录中。
你的系统中需要以下文件:
https://ml-models.elastic.co/elser_model_1.metadata.json
https://ml-models.elastic.co/elser_model_1.pt
https://ml-models.elastic.co/elser_model_1.vocab.json使用 HTTP 服务器
提示:如果你使用现有的 HTTP 服务器,请注意模型下载器仅支持无密码 HTTP 服务器。
你可以使用任何 HTTP 服务来部署 ELSER。 此示例使用官方 Nginx Docker 映像来设置新的 HTTP 下载服务。
1)从 https://ml-models.elastic.co/ 下载模型工件文件。
2)将文件放入你选择的子目录中。
3)运行以下命令:
export ELASTIC_ML_MODELS="/path/to/models"
docker run --rm -d -p 8080:80 --name ml-models -v ${ELASTIC_ML_MODELS}:/usr/share/nginx/html nginx不要忘记将 /path/to/models 更改为模型工件文件所在的子目录的路径。
这些命令使用 Nginx 服务器启动本地 Docker 映像,其子目录包含模型文件。 由于需要下载和构建Docker镜像,第一次启动可能需要较长的时间。 随后的运行开始得更快。
4)通过在浏览器中访问以下 URL 来验证 Nginx 是否正常运行:
http://{IP_ADDRESS_OR_HOSTNAME}:8080/elser_model_1.metadata.json如果 Nginx 正常运行,你会看到模型的元数据文件的内容。
5)通过将以下行添加到 config/elasticsearch.yml 文件,将你的 Elasticsearch 部署指向 HTTP 服务器上的模型工件:
xpack.ml.model_repository: http://{IP_ADDRESS_OR_HOSTNAME}:8080如果你使用自己的 HTTP 或 HTTPS 服务器,请相应地更改地址。 指定协议很重要(“http://”或“https://”)。 确保所有符合主节点条件的节点都可以访问你指定的服务器。
6)在所有符合主节点资格的节点上重复步骤 5。
7)一个接一个地重启 master-eligible节点。
仅下载模型需要 HTTP 服务器。 下载完成后,你可以停止并删除该服务。 你可以通过运行以下命令停止此示例中使用的 Docker 镜像:
docker stop ml-models使用基于文件的访问
对于基于文件的访问,请执行以下步骤:
1)从 https://ml-models.elastic.co/ 下载模型工件文件。
2)将文件放入 Elasticsearch 部署的配置目录内的模型子目录中。
3)通过将以下行添加到 config/elasticsearch.yml 文件,将你的 Elasticsearch 部署指向模型目录:
xpack.ml.model_repository: file://${path.home}/config/models/`4)在所有符合主节点资格的节点上重复步骤 2 和步骤 3。
5)一个接一个地重启 master-eligible 节点。









![[游戏开发][Unreal]项目启动](https://img-blog.csdnimg.cn/img_convert/bdc3c4575fdb7a37cfb79a2cff79683c.png)