Pandas的窗口函数rolling和expanding
1、rolling 移动窗口
rolling() 移动窗口函数,它可以与 mean、count、sum、median、std 等聚合函数一起使用。为了使用方便,Pandas 为移动函数定义了专门的方法聚合方法,比如 rolling_mean()、rolling_count()、rolling_sum() 等。
其的语法格式如下:
rolling(window, min_periods=None, center=False, win_type=None, on=None, axis=0, closed=None)
(1)参数:
- window:表示时间窗的大小,有两种形式:
1)使用数值int,则表示观测值的数量,即向前几个数据;
2)也可以使用offset类型,这种类型较复杂,使用场景较少,此处暂不做介绍; - min_periods:每个窗口最少包含的观测值数量,小于这个值的窗口结果为NA。值可以是int,默认None。offset情况下,默认为1;
- center: 把窗口的标签设置为居中,布尔型,默认False,居右
- win_type: 窗口的类型。截取窗的各种函数。字符串类型,默认为None;
- on: 可选参数。对于dataframe而言,指定要计算滚动窗口的列。值为列名。
- axis: 默认为0,即对列进行计算
- closed:定义区间的开闭,支持int类型的window。对于offset类型默认是左开右闭的即默认为right。可以根据情况指定为left、both等。
(2)用例:
# -*- coding: utf-8 -*-
import pandas as pd
import numpy as np
seed = 8
s = pd.Series(range(seed), index=pd.date_range('2023-01-01', periods=seed, freq='1D'))
print(s)
print(s.rolling(window=3).sum())
print(s.rolling(window=3, min_periods=1).sum())
print(s.rolling(window='3D').sum())
结果如下:
2023-01-01 0
2023-01-02 1
2023-01-03 2
2023-01-04 3
2023-01-05 4
2023-01-06 5
2023-01-07 6
2023-01-08 7
Freq: D, dtype: int64
2023-01-01 NaN
2023-01-02 NaN
2023-01-03 3.0
2023-01-04 6.0
2023-01-05 9.0
2023-01-06 12.0
2023-01-07 15.0
2023-01-08 18.0
Freq: D, dtype: float64
2023-01-01 0.0
2023-01-02 1.0
2023-01-03 3.0
2023-01-04 6.0
2023-01-05 9.0
2023-01-06 12.0
2023-01-07 15.0
2023-01-08 18.0
Freq: D, dtype: float64
2023-01-01 0.0
2023-01-02 1.0
2023-01-03 3.0
2023-01-04 6.0
2023-01-05 9.0
2023-01-06 12.0
2023-01-07 15.0
2023-01-08 18.0
Freq: D, dtype: float64
print(s.rolling(window=3).sum())
窗口宽度是3,1月1日前两天无数据,是空值,因此1日和2日的结果都是NaN
2023-01-01 NaN
2023-01-02 NaN
2023-01-03 3.0
print(s.rolling(window=3, min_periods=1).sum())
为了解决上述问题,使用min_periods,如果没有数据,最小窗口就是1 ,所以1日和2日有数据。
2023-01-01 0.0
2023-01-02 1.0
2023-01-03 3.0
print(s.rolling(window=‘3D’).sum())
索引是日期,按索引的日期3天作为窗口宽度,则同使用min_periods=1参数一样的效果。
(3)用法拓展
rolling()函数除了sum(),还支持很多函数,比如:
count() 非空观测值数量
mean() 值的平均值
median() 值的算术中值
min() 最小值
max() 最大
std() 贝塞尔修正样本标准差
var() 无偏方差
skew() 样品偏斜度(三阶矩)
kurt() 样品峰度(四阶矩)
quantile() 样本分位数(百分位上的值)
cov() 无偏协方差(二元)
corr() 相关性(二进制)
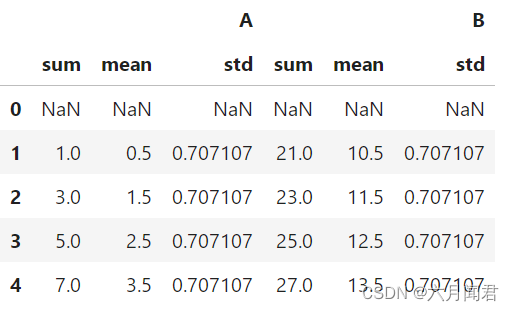
还可以与agg聚合函数使用
df = pd.DataFrame({"A": range(5), "B": range(10, 15)})
df.rolling(window=2).agg([np.sum, np.mean, np.std])
结果如下:
2、expanding 扩展窗口函数
expanding() 扩展窗口函数,扩展是指由序列的第一个元素开始,逐个向后计算元素的聚合值。
(1)参数:
expanding()函数的参数,与rolling()函数的参数用法相同;没有window参数。不固定窗口大小,实现累计计算,即不断扩展。
rolling()函数,是固定窗口大小,进行滑动计算,expanding()函数只设置最小的观测值数量。
expanding()函数,类似cumsum()函数的累计求和,其优势在于还可以进行更多的聚类计算;
(2)用例:
seed =21
df = pd.DataFrame({'a':np.random.randint(20,500,seed),'b':np.random.randint(20,100,seed)}, index=pd.date_range('2020-01-01', periods=seed, freq='1D'))
df.index.name='testdate'
print(df)
print(df.expanding(min_periods=7).max())
print(df.expanding(min_periods=7).min())
最小窗口是7天,所以最大值和最小值,1日到6日都是NaN 。
窗口从7天,不断扩展到全部dataframe记录 。
a列:
2020-01-01 492 ,
一直到最后一天 ,超过了第一天的最大值,max值变化
2020-01-21 499.0
同理b列最大值。
结果如下:
a b
testdate
2020-01-01 492 80
2020-01-02 399 73
2020-01-03 309 58
2020-01-04 66 38
2020-01-05 318 20
2020-01-06 488 29
2020-01-07 328 33
2020-01-08 347 25
2020-01-09 240 47
2020-01-10 80 71
2020-01-11 265 54
2020-01-12 33 65
2020-01-13 396 61
2020-01-14 71 54
2020-01-15 39 49
2020-01-16 189 48
2020-01-17 79 67
2020-01-18 303 62
2020-01-19 482 98
2020-01-20 208 27
2020-01-21 499 43
a b
testdate
2020-01-01 NaN NaN
2020-01-02 NaN NaN
2020-01-03 NaN NaN
2020-01-04 NaN NaN
2020-01-05 NaN NaN
2020-01-06 NaN NaN
2020-01-07 492.0 80.0
2020-01-08 492.0 80.0
2020-01-09 492.0 80.0
2020-01-10 492.0 80.0
2020-01-11 492.0 80.0
2020-01-12 492.0 80.0
2020-01-13 492.0 80.0
2020-01-14 492.0 80.0
2020-01-15 492.0 80.0
2020-01-16 492.0 80.0
2020-01-17 492.0 80.0
2020-01-18 492.0 80.0
2020-01-19 492.0 98.0
2020-01-20 492.0 98.0
2020-01-21 499.0 98.0
a b
testdate
2020-01-01 NaN NaN
2020-01-02 NaN NaN
2020-01-03 NaN NaN
2020-01-04 NaN NaN
2020-01-05 NaN NaN
2020-01-06 NaN NaN
2020-01-07 66.0 20.0
2020-01-08 66.0 20.0
2020-01-09 66.0 20.0
2020-01-10 66.0 20.0
2020-01-11 66.0 20.0
2020-01-12 33.0 20.0
2020-01-13 33.0 20.0
2020-01-14 33.0 20.0
2020-01-15 33.0 20.0
2020-01-16 33.0 20.0
2020-01-17 33.0 20.0
2020-01-18 33.0 20.0
2020-01-19 33.0 20.0
2020-01-20 33.0 20.0
2020-01-21 33.0 20.0
(3)用法拓展:
df = pd.DataFrame(
np.random.rand(6, 4),
index=pd.date_range("2022-01-01", periods=6),
columns=["A", "B", "C", "D"],
)
print(df)
print (df.expanding(min_periods=3).mean())
print('mini window 3 mean result:')
print(df.iloc[0:3].mean())
print('last mean result')
print(df['A'].mean(),df['B'].mean(),df['C'].mean(),df['D'].mean())
3日的平均值,与df.iloc[0:3].mean() 等价。
6日的平均值,与df[‘A’].mean(),df[‘B’].mean(),df[‘C’].mean(),df[‘D’].mean()等价,或者是df.mean()等价 。
结果如下:
A B C D
2022-01-01 0.697834 0.100287 0.652869 0.207896
2022-01-02 0.495769 0.010228 0.033768 0.311194
2022-01-03 0.404906 0.814433 0.447700 0.369165
2022-01-04 0.148014 0.980413 0.869525 0.760739
2022-01-05 0.925820 0.322119 0.363028 0.927978
2022-01-06 0.988882 0.997867 0.419070 0.276822
A B C D
2022-01-01 NaN NaN NaN NaN
2022-01-02 NaN NaN NaN NaN
2022-01-03 0.532836 0.308316 0.378112 0.296085
2022-01-04 0.436631 0.476340 0.500966 0.412248
2022-01-05 0.534469 0.445496 0.473378 0.515394
2022-01-06 0.610204 0.537558 0.464327 0.475632
mini window 3 mean result:
A 0.532836
B 0.308316
C 0.378112
D 0.296085
dtype: float64
last mean result
0.6102041426142952 0.5375578633503776 0.4643265893696882 0.47563227350705956
再次理解一下扩展窗口的含义:
表示至少 3 个数求一次均值,计算方式为
A2=(A0+A1+A2)/3,
A3=(A0+A1+A2+A3)/4
A4=(A0+A1+A2+A3+A4)/5
A5 A6 依次类推。
df = pd.DataFrame({'a':range(5)})
print(df)
print(df.rolling(window=len(df), min_periods=1).mean())
print(df.expanding(min_periods=1).mean())
当rolling()函数的参数window=len(df)时,实现的效果与expanding()函数是一样的。结果如下:
a
0 0
1 1
2 2
3 3
4 4
a
0 0.0
1 0.5
2 1.0
3 1.5
4 2.0
a
0 0.0
1 0.5
2 1.0
3 1.5
4 2.0




![[游戏开发][Unreal]项目启动](https://img-blog.csdnimg.cn/img_convert/bdc3c4575fdb7a37cfb79a2cff79683c.png)