这里前面的linux基础就不补充了,只写一些比较高级的
目录
一、文件查找
1.按照名字查找
2.通配符
3.文件大小查找
二、压缩和打包
1.zip
2.gzip
3.tar命令
三、权限管理
四、多进程
1.创建进程
2.获取进程id
3.进程传参
4.进程不共享全局变量
5.守护进程
5.1.方式1
5.2.方式2
五、线程
1.线程创建
2.线程执行带有参数的任务
3.线程的无序性
4.守护主线程
5.阻塞线程
6.线程间共享全局变量
7.多线程中共享变量的资源竞争问题
8.使用线程同步解决
9.互斥锁
10.死锁
11.死锁哲学家问题
结语
一、文件查找
1.按照名字查找
find 查找目录 -name 文件名字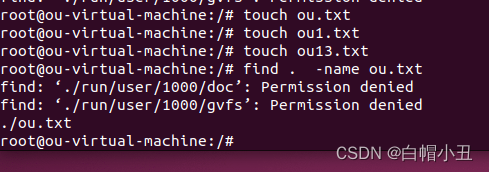
2.通配符
*匹配多个字符
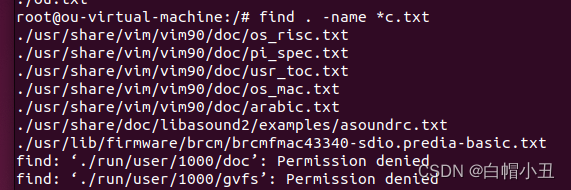
?匹配单个字符

3.文件大小查找
find 文件目录 -size [+,-]长度查找当前目录以及子目录下大于4K的文件
find . -size +4k查找当前目录以及子目录下小于4K的文件
find . -size -4k二、压缩和打包
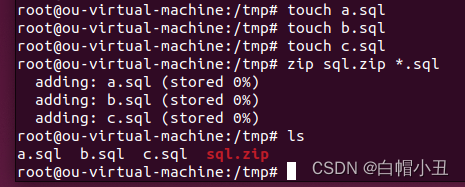
1.zip
zip
![]()
unzip

2.gzip
gzip使用
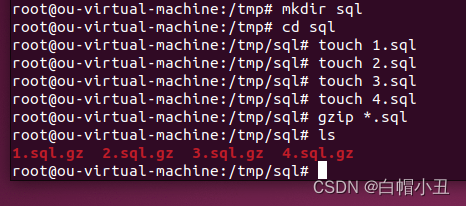
解压
gzip -d
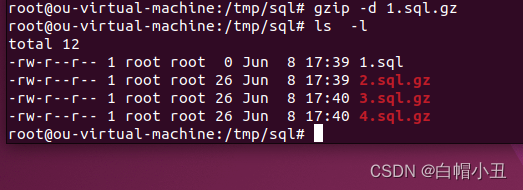
3.tar命令
常用
打包
tar cvf
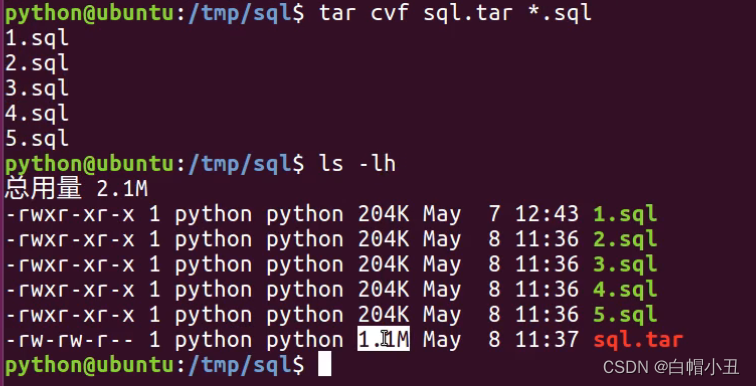
压缩

所以说压缩一个文件分两步,先打包,后压缩
tar命令也可以一步到位
tar zcvf
相应的解包也可以一步到位
tar xcvf
或者tart xvf先解压,-C执行解压到的目录
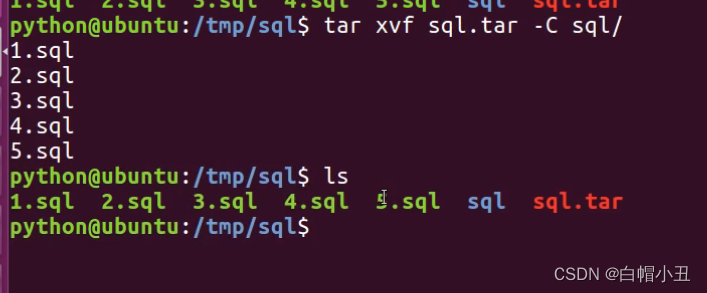
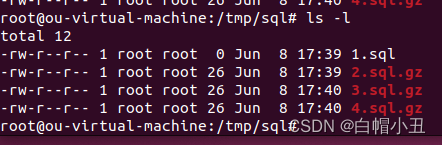
三、权限管理
rwx-rwx-rwx

四、多进程
1.创建进程
import multiprocessing
import time
def task1():
for i in range(10):
print('A -- ',i + 1)
time.sleep(1)
def task2():
for i in range(10):
print('B -- ',i + 1)
time.sleep(1)
if __name__ == '__main__':
p1 = multiprocessing.Process(target=task1)
p2 = multiprocessing.Process(target=task2)
p1.start()
p2.start()2.获取进程id
获取进程ID和进程的父ID,进程名
这两个进程都是同一个父进程拉起来的
import multiprocessing
import time
import os
def task1():
mp = multiprocessing.current_process()
print("task1: ", mp)
print(f"任务1的PID:{os.getpid()} 父进程的PID是{os.getppid()}")
time.sleep(1)
def task2():
mp = multiprocessing.current_process()
print("task2: ", mp)
print(f"任务2的PID:{os.getpid()} 父进程的PID是{os.getppid()}")
time.sleep(1)
if __name__ == '__main__':
print(f"主进程的PID:{os.getpid()} 父进程的PID是{os.getppid()}")
#获取当前进程对象
mp = multiprocessing.current_process()
print("main: ",mp)
p1 = multiprocessing.Process(target=task1,name='p1')
p2 = multiprocessing.Process(target=task2,name='p2')
print(p1)
print(p2)
p1.start()
p2.start()
print(p1)
print(p2)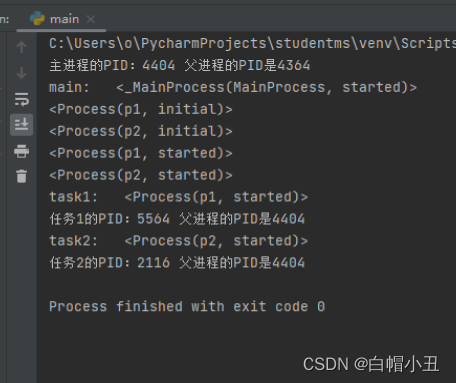
3.进程传参
必须要传入可迭代参数
import multiprocessing
import time
def task(count):
for i in range(count):
print("任务执行中。。。")
time.sleep(0.2)
else:
print("任务执行完成")
if __name__ == '__main__':
#因为参数
sub_process = multiprocessing.Process(target=task,args=5)
sub_process.start()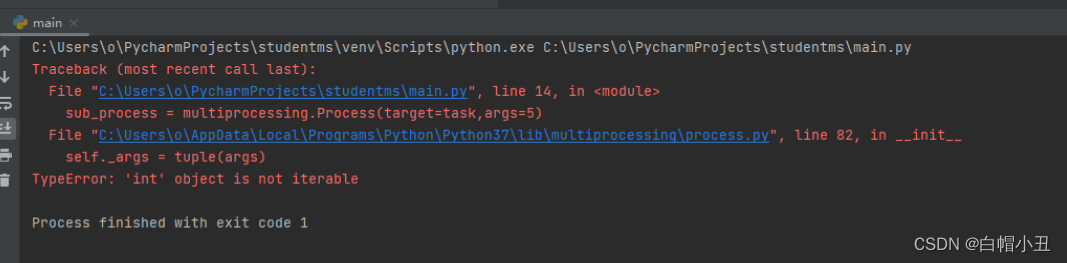
import multiprocessing
import time
def task(count):
for i in range(count):
print("任务执行中。。。")
time.sleep(0.2)
else:
print("任务执行完成")
if __name__ == '__main__':
sub_process = multiprocessing.Process(target=task,kwargs={"count": 4})
sub_process.start()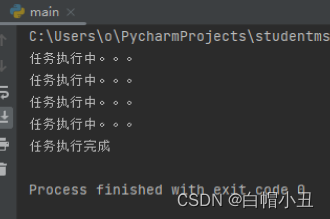
字典必须要要与参数名相同
import multiprocessing
import time
def task(count):
for i in range(count):
print("任务执行中。。。")
time.sleep(0.2)
else:
print("任务执行完成")
if __name__ == '__main__':
#因为参数
sub_process = multiprocessing.Process(target=task,kwargs={'a':2})
sub_process.start()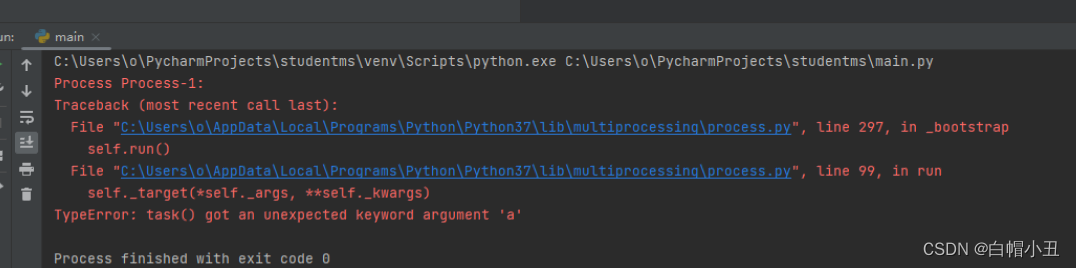
4.进程不共享全局变量
import multiprocessing
import time
g_list = list()
def add_data():
for i in range(6):
g_list.append(i)
print("add: ",i)
time.sleep(0.2)
print("add_data: ",g_list)
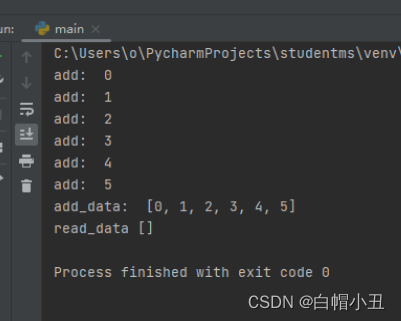
def read_data():
print("read_data",g_list)
if __name__ == '__main__':
# 创建添加数据的子进程
add_data_process = multiprocessing.Process(target=add_data)
# 创建读取数据的子进程
read_data_process = multiprocessing.Process(target=read_data)
#启动子进程执行对应的任务
add_data_process.start()
#阻塞函数,add_data_process执行完才会继续向下执行
add_data_process.join()
#全局变量不共享
read_data_process.start()
5.守护进程
5.1.方式1
import multiprocessing
import time
g_list = list()
def add_data():
for i in range(6):
g_list.append(i)
print("add: ",i)
time.sleep(0.2)
print("add_data: ",g_list)
def read_data():
print("read_data",g_list)
if __name__ == '__main__':
# 创建添加数据的子进程
add_data_process = multiprocessing.Process(target=add_data)
# 创建读取数据的子进程
read_data_process = multiprocessing.Process(target=read_data)
#启动子进程执行对应的任务
add_data_process.start()
#阻塞函数,add_data_process执行完才会继续向下执行
add_data_process.join()
#主进程结束之前,手动调用方法结束子进程
add_data_process.terminate()
print("add_data terminate")
#全局变量不共享
read_data_process.start()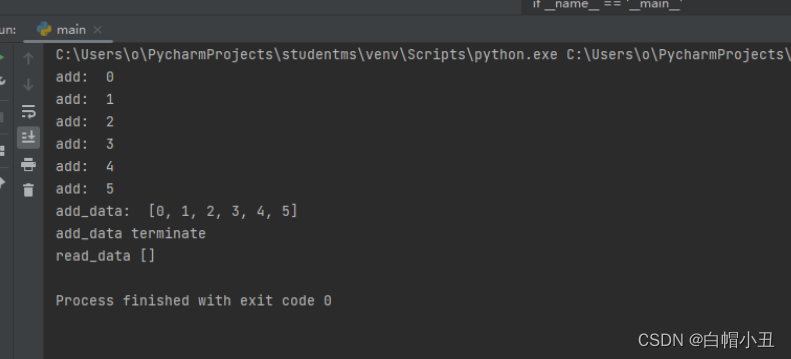
5.2.方式2
import multiprocessing
import time
g_list = list()
def add_data():
for i in range(6):
g_list.append(i)
print("add: ",i)
time.sleep(0.2)
print("add_data: ",g_list)
def read_data():
print("read_data",g_list)
if __name__ == '__main__':
# 创建添加数据的子进程
add_data_process = multiprocessing.Process(target=add_data)
# 创建读取数据的子进程
read_data_process = multiprocessing.Process(target=read_data)
#锁
add_data_process.daemon = True
#启动子进程执行对应的任务
add_data_process.start()
#阻塞函数,add_data_process执行完才会继续向下执行
add_data_process.join()
#全局变量不共享
read_data_process.start()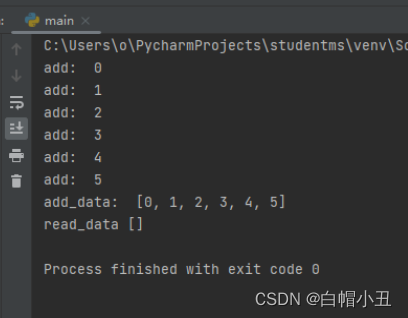
五、线程
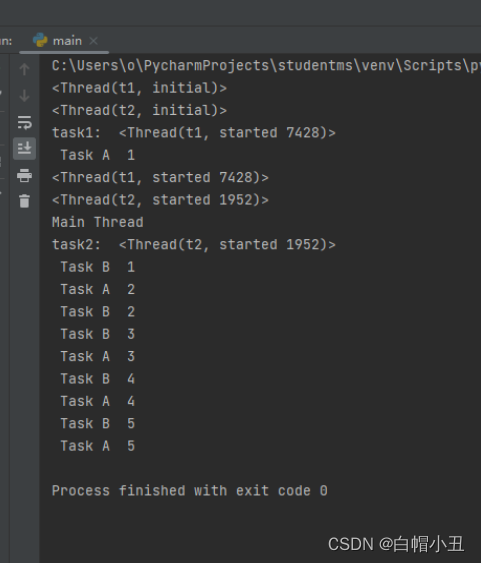
1.线程创建
import threading
import time
def task1():
t = threading.currentThread()
print("task1: ",t)
for i in range(5):
print(" Task A ", i+1)
time.sleep(0.5)
def task2():
t = threading.currentThread()
print("task2: ",t)
for i in range(5):
print(" Task B ", i+1)
time.sleep(0.5)
#创建线程
if __name__ == '__main__':
t1 = threading.Thread(target=task1,name='t1')
t2 = threading.Thread(target=task2,name='t2')
print(t1)
print(t2)
#创建好线程后,线程并不会被执行
#必须启动线程
t1.start()
t2.start()
print(t1)
print(t2)
print("Main Thread")
2.线程执行带有参数的任务
import threading
import time
def task(count):
for i in range(count):
print("任务执行中。。。")
time.sleep(0.2)
else:
print("任务执行完成")
def task1(content , count):
for i in range(count):
print(content,'--',i+1)
time.sleep(0.5)
if __name__ == '__main__':
sub_thread = threading.Thread(target=task,args=(5,))
sub_thread2 = threading.Thread(target=task1,args=('Python',5))
sub_thread.start()
sub_thread2.start()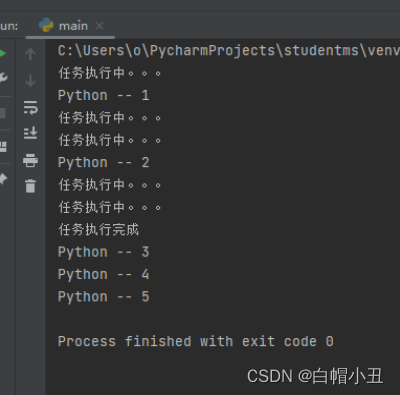
3.线程的无序性
import threading
import time
def task():
t = threading.current_thread()
for i in range(10):
print(t.name)
time.sleep(0.5)
if __name__ == '__main__':
for i in range(5):
t = threading.Thread(target=task)
t.start()
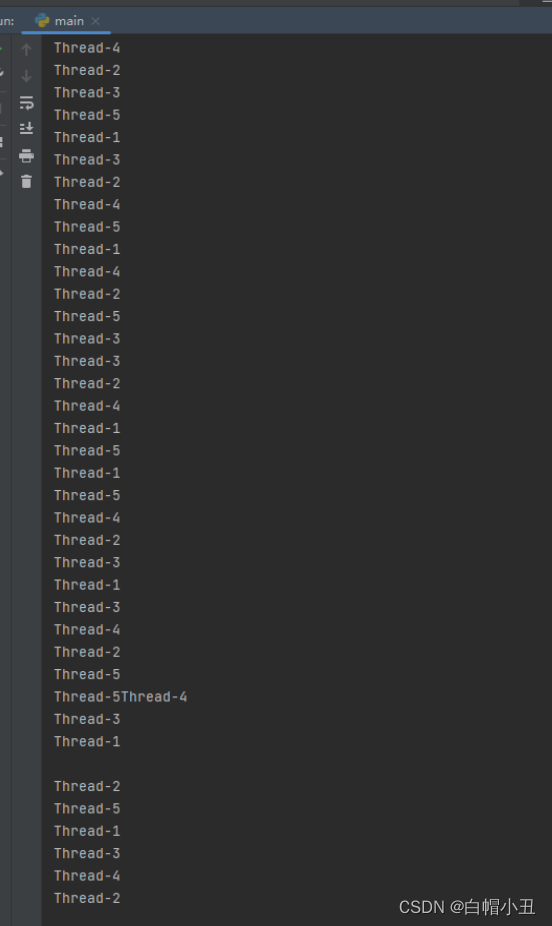
4.守护主线程
没有守护线程,主线程会随即执行
import threading
import time
def task():
t = threading.current_thread()
for i in range(5):
print(t.name)
time.sleep(0.5)
if __name__ == '__main__':
t1 = threading.Thread(target=task,name='t1')
t2 = threading.Thread(target=task,name='t2')
t1.start()
t2.start()
print("main over") 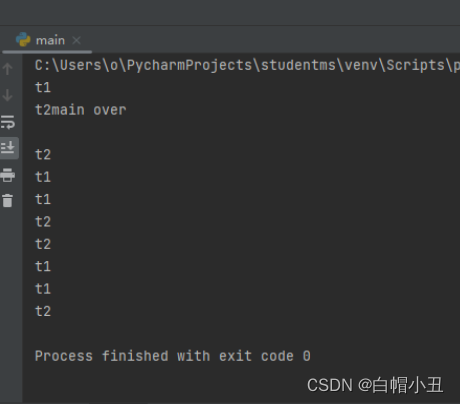
方法1
这个方法主线程不等待子线程所以会出现问题
import threading
import time
def task():
t = threading.current_thread()
for i in range(5):
print(t.name)
time.sleep(0.5)
if __name__ == '__main__':
t1 = threading.Thread(target=task,name='t1',daemon=True)
t2 = threading.Thread(target=task,name='t2',daemon=True)
t1.start()
t2.start()
print("main over")
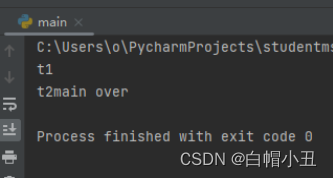
方法2
import threading
import time
def task():
t = threading.current_thread()
for i in range(5):
print(t.name)
time.sleep(0.5)
if __name__ == '__main__':
t1 = threading.Thread(target=task,name='t1')
t2 = threading.Thread(target=task,name='t2')
t1.setDaemon(True)
t2.setDaemon(True)
t1.start()
t2.start()
print("main over")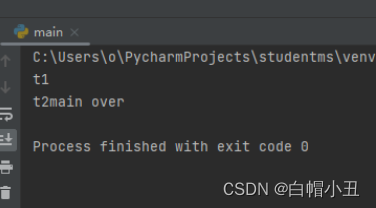
5.阻塞线程
import threading
import time
def task():
t = threading.current_thread()
for i in range(5):
print(t.name)
time.sleep(0.5)
if __name__ == '__main__':
t1 = threading.Thread(target=task,name='t1')
t2 = threading.Thread(target=task,name='t2')
t1.setDaemon(True)
t2.setDaemon(True)
t1.start()
t2.start()
t1.join()
t2.join()
print("main over")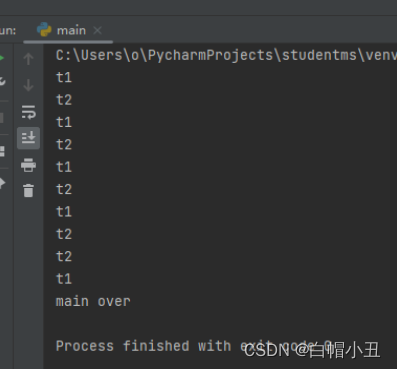
6.线程间共享全局变量
import threading
import time
c_list = []
def add_data():
for i in range(5):
c_list.append(i)
print(c_list)
time.sleep(0.5)
def read_data():
print("read: ",c_list)
if __name__ == '__main__':
add_t = threading.Thread(target=add_data)
read_t = threading.Thread(target=read_data)
add_t.start()
read_t.start()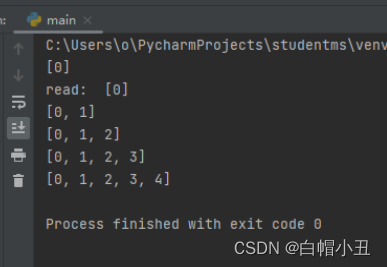
7.多线程中共享变量的资源竞争问题
import threading
import time
g_num = 0
def sum_num1():
for i in range(1000000000):
global g_num
g_num += 1
print("sum1: ",g_num)
if __name__ == '__main__':
f_t = threading.Thread(target=sum_num1)
f_t2 = threading.Thread(target=sum_num1)
f_t.start()
f_t2.start()
time.sleep(3)
print("main",g_num)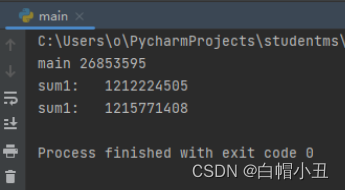
转存失败重新上传取消
时间片轮转的问题
8.使用线程同步解决
线程等待(阻塞)
import threading
import time
g_num = 0
def sum_num1():
for i in range(1000000000):
global g_num
g_num += 1
print("sum1: ",g_num)
if __name__ == '__main__':
f_t = threading.Thread(target=sum_num1)
f_t2 = threading.Thread(target=sum_num1)
f_t.start()
#阻塞
f_t.join()
f_t2.start()
f_t2.join()
time.sleep(3)
print("main",g_num)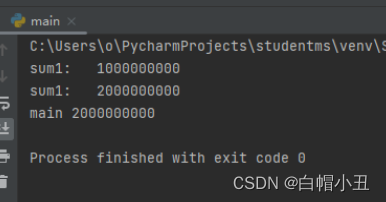
转存失败重新上传取消
9.互斥锁
上锁
原子操作
解锁
import threading
import time
#创建一个实例锁
metax_lock = threading.Lock()
g_num = 0
def sum_num1():
t = threading.current_thread()
for i in range(1000000000):
metax_lock.acquire()
global g_num
g_num += 1
print(t.name,"=------=",g_num)
metax_lock.release()
print("sum1: ",g_num)
if __name__ == '__main__':
f_t = threading.Thread(target=sum_num1)
f_t2 = threading.Thread(target=sum_num1)
f_t.start()
f_t2.start()
time.sleep(3)
print("main",g_num)
注意不要变成同步锁,一般都是异步执行
10.死锁
这个函数就有个死锁
import multiprocessing
import threading
import time
c_list = [1,2,3,4325]
lock = threading.Lock()
def get_value(index):
#锁
lock.acquire()
t = threading.current_thread()
if index >= len(c_list):
print(f'{index} 下界太大,导致下标越界')
return
print(t.name,"取得第",index,'个值,值为',c_list[index])
lock.release()
if __name__ == '__main__':
for i in range(5):
t = threading.Thread(target=get_value,args=(i,))
t.start()
我们解决掉他
import multiprocessing
import threading
import time
c_list = [1,2,3,4325]
lock = threading.Lock()
def get_value(index):
#锁
lock.acquire()
t = threading.current_thread()
if index >= len(c_list):
print(f'{index} 下界太大,导致下标越界')
lock.release()
return
print(t.name,"取得第",index,'个值,值为',c_list[index])
lock.release()
if __name__ == '__main__':
for i in range(5):
t = threading.Thread(target=get_value,args=(i,))
t.start()但这里其实还有问题,我们后面讨论
11.死锁哲学家问题
import multiprocessing
import threading
import time
lock_a = threading.Lock()
lock_b = threading.Lock()
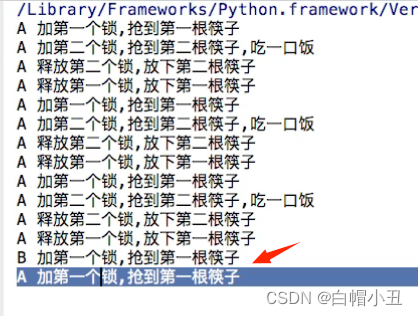
def PersonA():
for i in range(100):
lock_a.acquire()
print("A抢到第一个筷子,加一个锁")
lock_b.acquire()
print("A加第二个锁,强盗第二根筷子,吃一口饭")
lock_b.release()
print("A释放锁,放下第二根筷子")
lock_a.release()
print("A加第一个锁,抢到第一根筷子")
def PersonB():
for i in range(100):
lock_a.acquire()
print("B抢到第一个筷子,加一个锁")
lock_b.acquire()
print("B加第二个锁,强盗第二根筷子,吃一口饭")
lock_b.release()
print("B释放锁,放下第二根筷子")
lock_a.release()
print("B加第一个锁,抢到第一根筷子")
if __name__ == '__main__':
pa = threading.Thread(target=PersonA)
pb = threading.Thread(target=PersonB)
pa.start()
pb.start()
结语
python的部分快要结束了,后面要更新linux服务器和k8s的笔记,希望大家多多👍