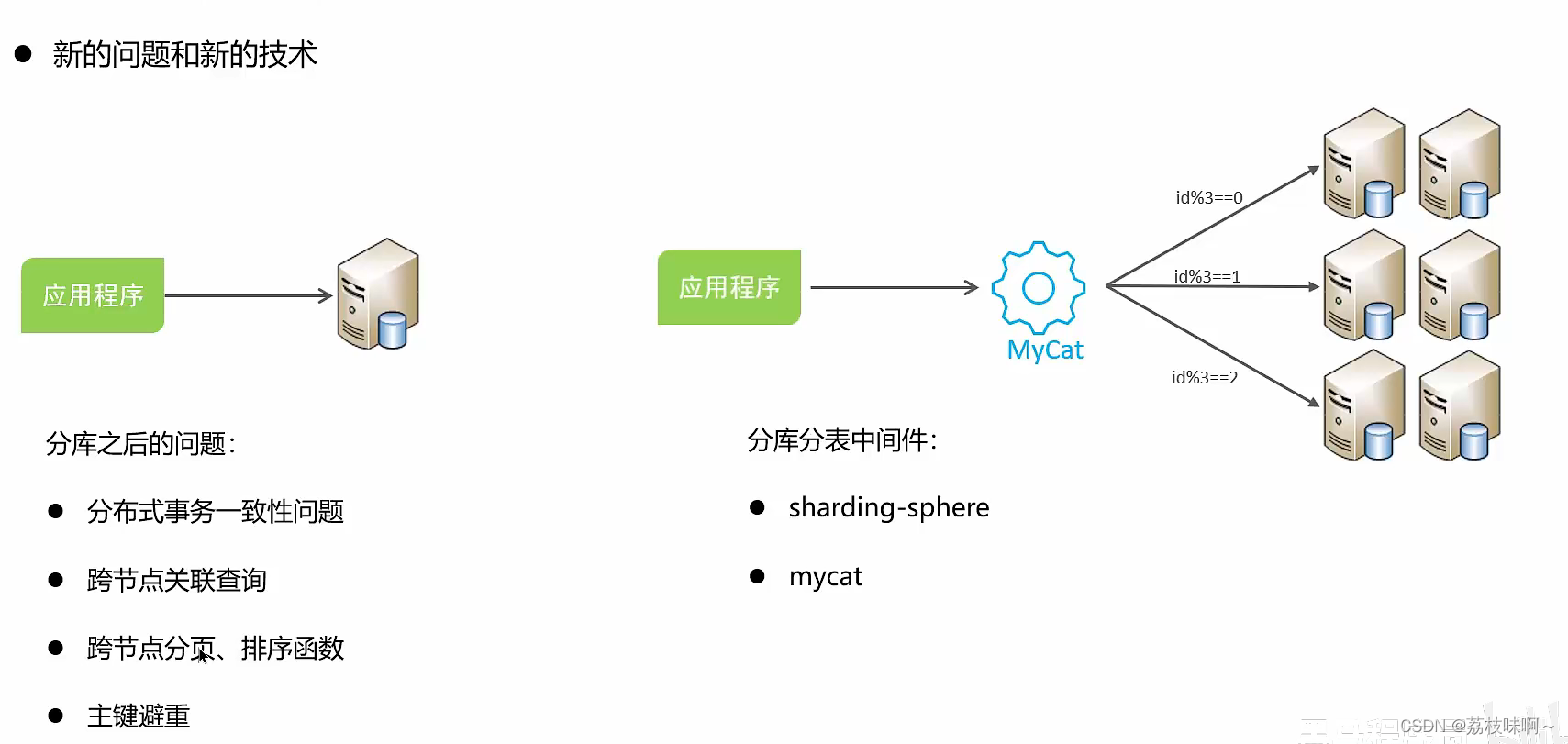
1. protobuf内部的实现原理
序列化与反序列化,比如对于数字它要求根据数字的大小选择存储空间,小于15的数字只用1个字节来表示,大于15的数用2个字节来表示,以此类推,这样要求可以尽可能地节省空间。Protobuf的一大特点是编码后的数据量很小,可以节省网络带宽。
还有一种说法是,JSON和MessagePack都使用字符串Key键值作为映射到程序变量的连接桥梁,用变量字符串去查看对应的Key键值是否存在,这样免不了因Key键值字符串太多而消耗更多空间。Protobuf则用数字编号来作为Key键值与变量映射的连接桥梁,每个变量都必须有一个不重复的标签号(即数字编号),使用Protobuf结构中变量字段后跟着的数字编号来映射数据中的数字编号,进而读取数据。Protobuf为每个结构变量都定义了一个标签号(即数字编号),这个数字编号就代表程序变量与指定编号数据的映射关系。
2. 实现函数
void memcpy(void* dest, const void* source, size_t count);参数说明:
void *dest:指向某一缓冲区,该缓冲区用来存放要拷贝的数据(即目标缓冲区)
const void *source:指向某一缓冲区,该缓冲区用来存放要拷贝给他人的数据(即源缓冲区)
size_t count:要拷贝多少个字节
功能说明:
此函数可将source缓冲区中前count个字节的数据拷贝到dest缓冲区中。请注意,当dest缓冲区和source缓冲区中有部分重叠的情形发生时,用户应使用memmove函数来进行数据的拷贝,因为这种情况下,memcpy并不能保证其结果是正确的。
返回值:
NULL。
实例代码:
#include <stdio.h>
#include <string.h>
#include <iostream>
#include <string>
using namespace std;
void memcpy(void* psrc, void* pdst, size_t length) {
if (psrc == NULL || pdst == NULL) return;
void* ret = psrc;
if (pdst <= psrc || (char*)pdst >= (char*)psrc + length) {
// 没有内存重叠,从低地址开始复制
while (length--) {
*(char*)pdst = *(char*)psrc;
pdst = (char*)pdst + 1;
psrc = (char*)psrc + 1;
}
} else {
// 有内存重叠,从高地址开始复制
psrc = (char*)psrc + length - 1;
pdst = (char*)pdst + length - 1;
while (length--) {
*(char*)pdst = *(char*)psrc;
pdst = (char*)pdst - 1;
psrc = (char*)psrc - 1;
}
}
return;
}
int main() {
char* src[10] = {"C BIBLE"};
char* dst[10] = {"C Bible"};
cout << "Before memcpy..." << endl;
cout << "src = " << *src << endl;
cout << "dst = " << *dst << endl;
memcpy(src, dst, 10);
cout << "After memcpy..." << endl;
cout << "src = " << *src << endl;
cout << "dst = " << *dst << endl;
return 0;
}输出:
Before memcpy...
src = C BIBLE
dst = C Bible
After memcpy...
src = C BIBLE
dst = C BIBLE
关于内存重叠问题:
起初我不太明白,为什么两块分配好的内存空间,会有重叠的问题?后来了解到这种内存重叠在平时写的应用级代码中并不会出现,但是在内核和驱动代码中会存在内存重叠问题。

图中灰色的部分即为内存重叠的部分,dst内存开始的地址在src所分配的内存中(这在应用层面的代码中是不可能出现的)。解决该问题的办法就是将代码从高地址向低地址进行复制。(复制完之后那原来的数据岂不就没办法使用了?这不是copy,将其改为move会更好些)
3. 大端存储和小端存储
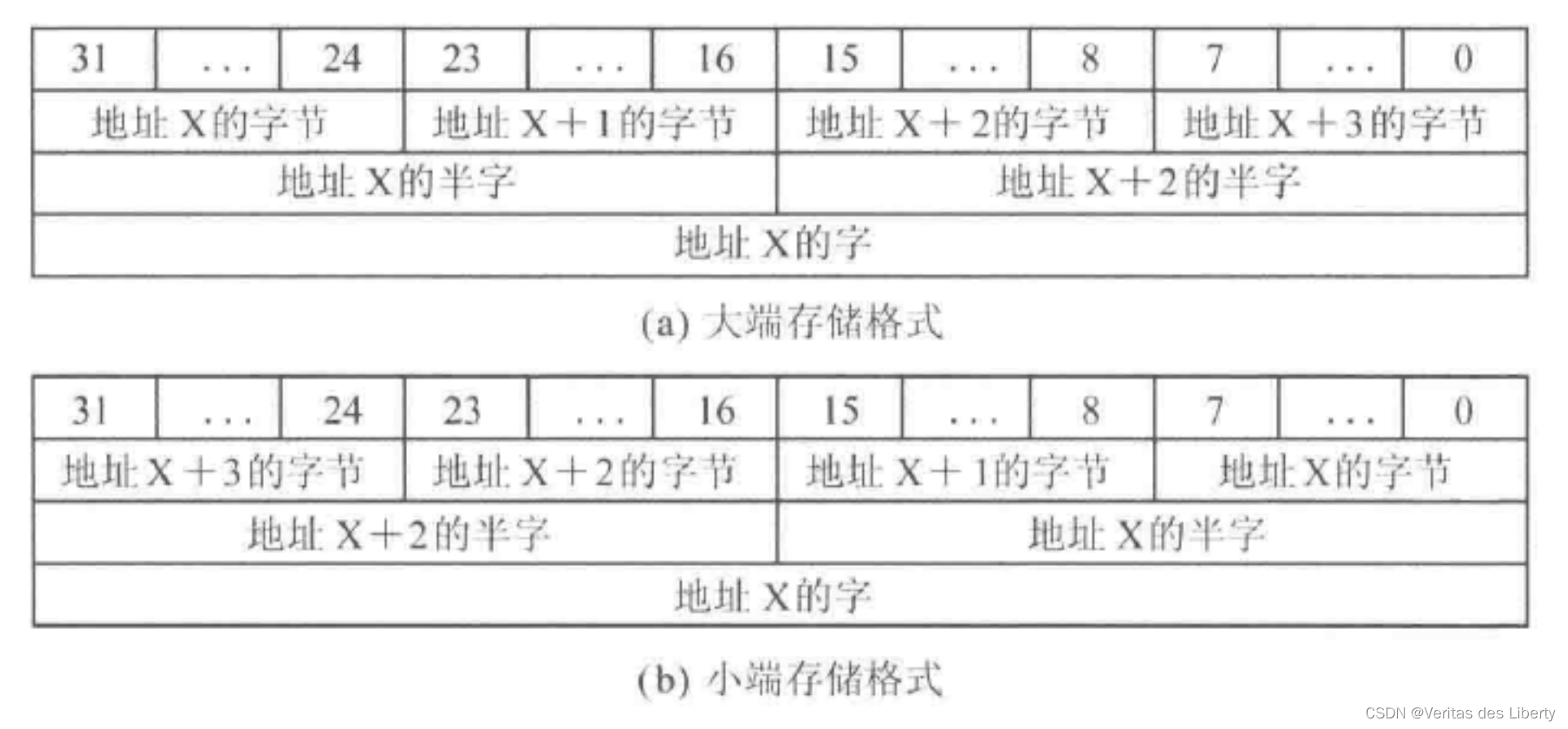
大端存储:把字(4字节)的低位放在高地址位
小端存储:把字(4字节)的低位放在低地址位
采用大端模式进行存放有利于人类的思维模式,而采用小端模式更利于计算机处理。
互联网使用的网络字节序采用大端模式进行编址,而主机字节序根据处理器的不同而不同。socket编程时,可以使用系统提供的函数对大小端字节序进行转换。