一、TLD工程编译及运行
1.1 源码下载
网上的TLD有两个版本,一个是Zdenek Kalal自己使用matlab+vs混合编程实现的,另外一个是 arthurv利用c++和opencv实现的。
我利用的是arthurv版本的Tracking-Learning-Detection
连接:https://github.com/alantrrs/OpenTLD
git clone https://gitclone.com/github.com/alantrrs/OpenTLD
1.2 编译
根据官网的方法进行编译即可。但是出现了下下面的错误,原因是opencv3以上的版本,已经不包含该功能包了。修改方法,见下面的解决方法:
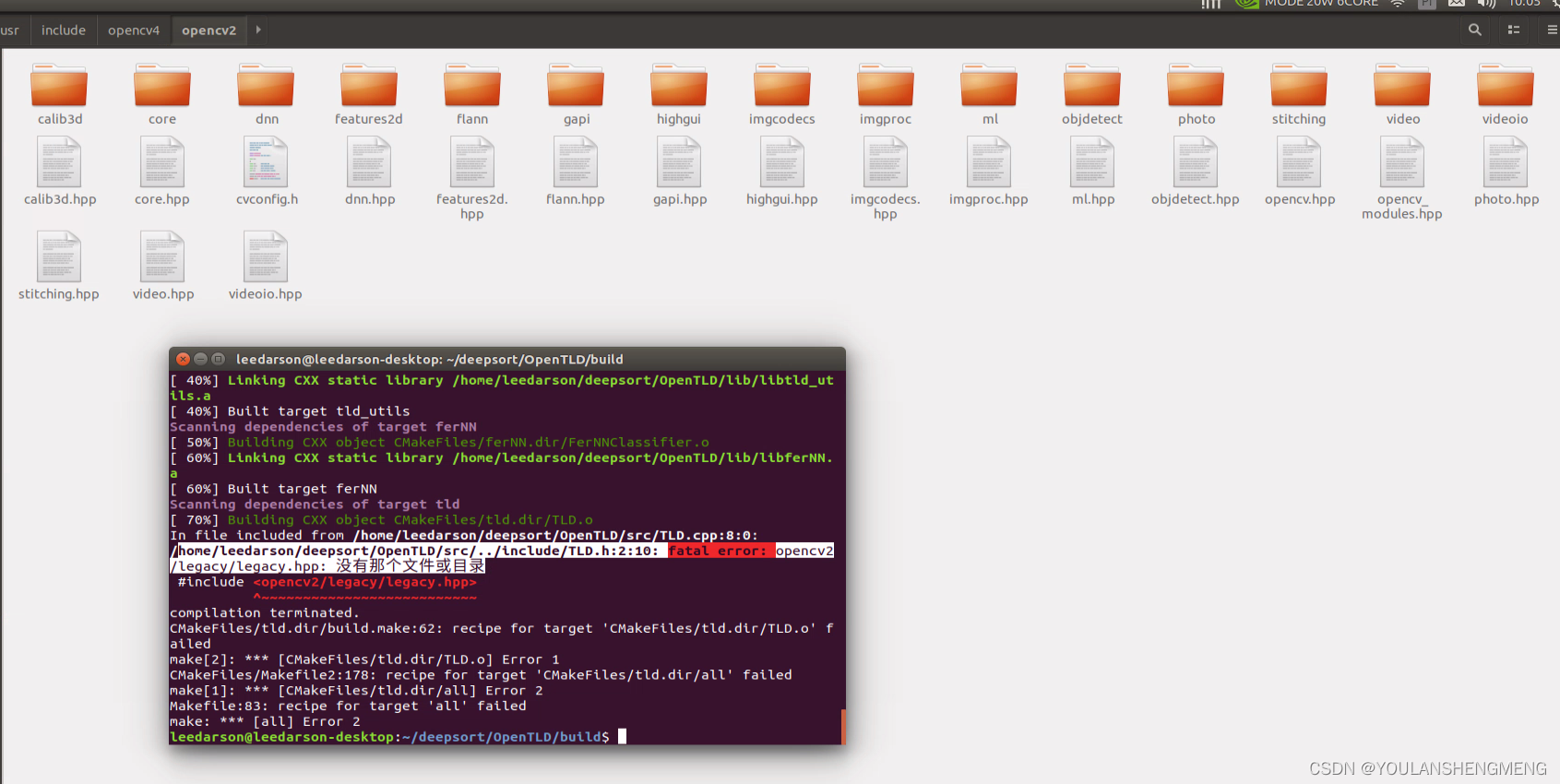 参考博文:
参考博文:
深度探索TLD的C++源码,多图慎入 - 爱码网
 PatchGenerator.h
PatchGenerator.h
#include <opencv2/opencv.hpp>
#ifndef PATCHGENERATOR_H
#define PATCHGENERATOR_H
namespace cv
{
class CV_EXPORTS PatchGenerator
{
public:
PatchGenerator();
PatchGenerator(double _backgroundMin, double _backgroundMax,
double _noiseRange, bool _randomBlur = true,
double _lambdaMin = 0.6, double _lambdaMax = 1.5,
double _thetaMin = -CV_PI, double _thetaMax = CV_PI,
double _phiMin = -CV_PI, double _phiMax = CV_PI);
void operator()(const Mat& image, Point2f pt, Mat& patch, Size patchSize, RNG& rng) const;
void operator()(const Mat& image, const Mat& transform, Mat& patch,
Size patchSize, RNG& rng) const;
void warpWholeImage(const Mat& image, Mat& matT, Mat& buf,
CV_OUT Mat& warped, int border, RNG& rng) const;
void generateRandomTransform(Point2f srcCenter, Point2f dstCenter,
CV_OUT Mat& transform, RNG& rng,
bool inverse = false) const;
void setAffineParam(double lambda, double theta, double phi);
double backgroundMin, backgroundMax;
double noiseRange;
bool randomBlur;
double lambdaMin, lambdaMax;
double thetaMin, thetaMax;
double phiMin, phiMax;
};
};
#endif
PatchGenerator.cpp
#include <opencv2/opencv.hpp>
#include <PatchGenerator.h>
namespace cv
{
/*
The code below implements keypoint detector, fern-based point classifier and a planar object detector.
References:
1. Mustafa Özuysal, Michael Calonder, Vincent Lepetit, Pascal Fua,
"Fast KeyPoint Recognition Using Random Ferns,"
IEEE Transactions on Pattern Analysis and Machine Intelligence, 15 Jan. 2009.
2. Vincent Lepetit, Pascal Fua,
"Towards Recognizing Feature Points Using Classification Trees,"
Technical Report IC/2004/74, EPFL, 2004.
*/
const int progressBarSize = 50;
//Patch Generator
static const double DEFAULT_BACKGROUND_MIN = 0;
static const double DEFAULT_BACKGROUND_MAX = 256;
static const double DEFAULT_NOISE_RANGE = 5;
static const double DEFAULT_LAMBDA_MIN = 0.6;
static const double DEFAULT_LAMBDA_MAX = 1.5;
static const double DEFAULT_THETA_MIN = -CV_PI;
static const double DEFAULT_THETA_MAX = CV_PI;
static const double DEFAULT_PHI_MIN = -CV_PI;
static const double DEFAULT_PHI_MAX = CV_PI;
PatchGenerator::PatchGenerator()
: backgroundMin(DEFAULT_BACKGROUND_MIN), backgroundMax(DEFAULT_BACKGROUND_MAX),
noiseRange(DEFAULT_NOISE_RANGE), randomBlur(true), lambdaMin(DEFAULT_LAMBDA_MIN),
lambdaMax(DEFAULT_LAMBDA_MAX), thetaMin(DEFAULT_THETA_MIN),
thetaMax(DEFAULT_THETA_MAX), phiMin(DEFAULT_PHI_MIN),
phiMax(DEFAULT_PHI_MAX)
{
}
PatchGenerator::PatchGenerator(double _backgroundMin, double _backgroundMax,
double _noiseRange, bool _randomBlur,
double _lambdaMin, double _lambdaMax,
double _thetaMin, double _thetaMax,
double _phiMin, double _phiMax )
: backgroundMin(_backgroundMin), backgroundMax(_backgroundMax),
noiseRange(_noiseRange), randomBlur(_randomBlur),
lambdaMin(_lambdaMin), lambdaMax(_lambdaMax),
thetaMin(_thetaMin), thetaMax(_thetaMax),
phiMin(_phiMin), phiMax(_phiMax)
{
}
void PatchGenerator::generateRandomTransform(Point2f srcCenter, Point2f dstCenter,
Mat& transform, RNG& rng, bool inverse) const
{
double lambda1 = rng.uniform(lambdaMin, lambdaMax);
double lambda2 = rng.uniform(lambdaMin, lambdaMax);
double theta = rng.uniform(thetaMin, thetaMax);
double phi = rng.uniform(phiMin, phiMax);
// Calculate random parameterized affine transformation A,
// A = T(patch center) * R(theta) * R(phi)' *
// S(lambda1, lambda2) * R(phi) * T(-pt)
double st = sin(theta);
double ct = cos(theta);
double sp = sin(phi);
double cp = cos(phi);
double c2p = cp*cp;
double s2p = sp*sp;
double A = lambda1*c2p + lambda2*s2p;
double B = (lambda2 - lambda1)*sp*cp;
double C = lambda1*s2p + lambda2*c2p;
double Ax_plus_By = A*srcCenter.x + B*srcCenter.y;
double Bx_plus_Cy = B*srcCenter.x + C*srcCenter.y;
transform.create(2, 3, CV_64F);
Mat_<double>& T = (Mat_<double>&)transform;
T(0,0) = A*ct - B*st;
T(0,1) = B*ct - C*st;
T(0,2) = -ct*Ax_plus_By + st*Bx_plus_Cy + dstCenter.x;
T(1,0) = A*st + B*ct;
T(1,1) = B*st + C*ct;
T(1,2) = -st*Ax_plus_By - ct*Bx_plus_Cy + dstCenter.y;
if( inverse )
invertAffineTransform(T, T);
}
void PatchGenerator::operator ()(const Mat& image, Point2f pt, Mat& patch, Size patchSize, RNG& rng) const
{
double buffer[6];
Mat_<double> T(2, 3, buffer);
generateRandomTransform(pt, Point2f((patchSize.width-1)*0.5f, (patchSize.height-1)*0.5f), T, rng);
(*this)(image, T, patch, patchSize, rng);
}
void PatchGenerator::operator ()(const Mat& image, const Mat& T,
Mat& patch, Size patchSize, RNG& rng) const
{
patch.create( patchSize, image.type() );
if( backgroundMin != backgroundMax )
{
rng.fill(patch, RNG::UNIFORM, Scalar::all(backgroundMin), Scalar::all(backgroundMax));
warpAffine(image, patch, T, patchSize, INTER_LINEAR, BORDER_TRANSPARENT);
}
else
warpAffine(image, patch, T, patchSize, INTER_LINEAR, BORDER_CONSTANT, Scalar::all(backgroundMin));
int ksize = randomBlur ? (unsigned)rng % 9 - 5 : 0;
if( ksize > 0 )
{
ksize = ksize*2 + 1;
GaussianBlur(patch, patch, Size(ksize, ksize), 0, 0);
}
if( noiseRange > 0 )
{
AutoBuffer<uchar> _noiseBuf( patchSize.width*patchSize.height*image.elemSize() );
Mat noise(patchSize, image.type(), (uchar*)_noiseBuf);
int delta = image.depth() == CV_8U ? 128 : image.depth() == CV_16U ? 32768 : 0;
rng.fill(noise, RNG::NORMAL, Scalar::all(delta), Scalar::all(noiseRange));
if( backgroundMin != backgroundMax )
addWeighted(patch, 1, noise, 1, -delta, patch);
else
{
for( int i = 0; i < patchSize.height; i++ )
{
uchar* prow = patch.ptr<uchar>(i);
const uchar* nrow = noise.ptr<uchar>(i);
for( int j = 0; j < patchSize.width; j++ )
if( prow[j] != backgroundMin )
prow[j] = saturate_cast<uchar>(prow[j] + nrow[j] - delta);
}
}
}
}
void PatchGenerator::warpWholeImage(const Mat& image, Mat& matT, Mat& buf,
Mat& warped, int border, RNG& rng) const
{
Mat_<double> T = matT;
Rect roi(INT_MAX, INT_MAX, INT_MIN, INT_MIN);
for( int k = 0; k < 4; k++ )
{
Point2f pt0, pt1;
pt0.x = (float)(k == 0 || k == 3 ? 0 : image.cols);
pt0.y = (float)(k < 2 ? 0 : image.rows);
pt1.x = (float)(T(0,0)*pt0.x + T(0,1)*pt0.y + T(0,2));
pt1.y = (float)(T(1,0)*pt0.x + T(1,1)*pt0.y + T(1,2));
roi.x = std::min(roi.x, cvFloor(pt1.x));
roi.y = std::min(roi.y, cvFloor(pt1.y));
roi.width = std::max(roi.width, cvCeil(pt1.x));
roi.height = std::max(roi.height, cvCeil(pt1.y));
}
roi.width -= roi.x - 1;
roi.height -= roi.y - 1;
int dx = border - roi.x;
int dy = border - roi.y;
if( (roi.width+border*2)*(roi.height+border*2) > buf.cols )
buf.create(1, (roi.width+border*2)*(roi.height+border*2), image.type());
warped = Mat(roi.height + border*2, roi.width + border*2,
image.type(), buf.data);
T(0,2) += dx;
T(1,2) += dy;
(*this)(image, T, warped, warped.size(), rng);
if( T.data != matT.data )
T.convertTo(matT, matT.type());
}
// Params are assumed to be symmetrical: lambda w.r.t. 1, theta and phi w.r.t. 0
void PatchGenerator::setAffineParam(double lambda, double theta, double phi)
{
lambdaMin = 1. - lambda;
lambdaMax = 1. + lambda;
thetaMin = -theta;
thetaMax = theta;
phiMin = -phi;
phiMax = phi;
}
};创建这两个文件,然后将该文件放置在对应的位置:
参考该博文
OpenTLD编译_永望的博客-CSDN博客
创建后需要更改编译文件:
#Set minimum version requered
cmake_minimum_required(VERSION 2.4.6)
#just to avoid the warning
if(COMMAND cmake_policy)
cmake_policy(SET CMP0003 NEW)
endif(COMMAND cmake_policy)
#set project name
project(TLD)
#Append path to the module path
list(APPEND CMAKE_MODULE_PATH ${PROJECT_SOURCE_DIR})
#OpenCV
find_package(OpenCV REQUIRED)
#set the default path for built executables to the "bin" directory
set(EXECUTABLE_OUTPUT_PATH ${PROJECT_SOURCE_DIR}/../bin)
#set the default path for built libraries to the "lib" directory
set(LIBRARY_OUTPUT_PATH ${PROJECT_SOURCE_DIR}/../lib)
#set the include directories
include_directories (${PROJECT_SOURCE_DIR}/../include ${OpenCV_INCLUDE_DIRS})
#libraries
add_library(tld_utils tld_utils.cpp)
add_library(LKTracker LKTracker.cpp)
add_library(ferNN FerNNClassifier.cpp)
add_library(tld TLD.cpp patchgenerator.cpp)
#executables
add_executable(run_tld run_tld.cpp)
#link the libraries
target_link_libraries(run_tld tld LKTracker ferNN tld_utils ${OpenCV_LIBS})
#set optimization level
set(CMAKE_BUILD_TYPE Release)1.3 运行
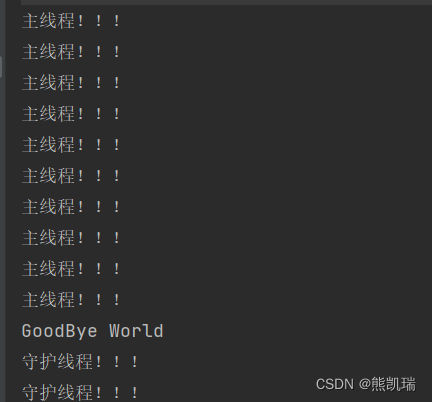
更改后,编译成功后进行测试,使用的命令为:
cd ../bin/
%To run from camera
./run_tld -p ../parameters.yml -tl
%To run from file
./run_tld -p ../parameters.yml -s ../datasets/06_car/car.mpg -tl
%To init bounding box from file
./run_tld -p ../parameters.yml -s ../datasets/06_car/car.mpg -b ../datasets/06_car/init.txt -tl
%To train only in the firs frame (no tracking, no learning)
./run_tld -p ../parameters.yml -s ../datasets/06_car/car.mpg -b ../datasets/06_car/init.txt
%To test the final detector (Repeat the video, first time learns, second time detects)
./run_tld -p ../parameters.yml -s ../datasets/06_car/car.mpg -b ../datasets/06_car/init.txt -tl -r
有博文上说需要进行以下修改,目前依照上面的对数据集中的数据测试未发现问题,如果发现问题后进行更改。
TLD.cpp 中的两个函数进行更改:
int TLD::clusterBB(const vector<BoundingBox>& dbb,vector<int>& indexes){
//FIXME: Conditional jump or move depends on uninitialised value(s)
//const int c = dbb.size();
const int c = 100;
//1. Build proximity matrix
Mat D(c,c,CV_32F);
float d;
for (int i=0;i<c;i++){
for (int j=i+1;j<c;j++){
d = 1-bbOverlap(dbb[i],dbb[j]);
D.at<float>(i,j) = d;
D.at<float>(j,i) = d;
}
}
//2. Initialize disjoint clustering
//float L[c-1]; //Level-----ori
float *L = new float[c - 1];
//int nodes[c-1][2];----ori
int **nodes = new int *[c - 1];
for (int i = 0; i < 2; i++)
{
nodes[i] = new int[c - 1];
}
//int belongs[c];----ori
int *belongs = new int[c];
int m=c;
for (int i=0;i<c;i++){
belongs[i]=i;
}
for (int it=0;it<c-1;it++){
//3. Find nearest neighbor
float min_d = 1;
int node_a, node_b;
for (int i=0;i<D.rows;i++){
for (int j=i+1;j<D.cols;j++){
if (D.at<float>(i,j)<min_d && belongs[i]!=belongs[j]){
min_d = D.at<float>(i,j);
node_a = i;
node_b = j;
}
}
}
if (min_d>0.5){
int max_idx =0;
bool visited;
for (int j=0;j<c;j++){
visited = false;
for(int i=0;i<2*c-1;i++){
if (belongs[j]==i){
indexes[j]=max_idx;
visited = true;
}
}
if (visited)
max_idx++;
}
return max_idx;
}
//4. Merge clusters and assign level
L[m]=min_d;
nodes[it][0] = belongs[node_a];
nodes[it][1] = belongs[node_b];
for (int k=0;k<c;k++){
if (belongs[k]==belongs[node_a] || belongs[k]==belongs[node_b])
belongs[k]=m;
}
m++;
//释放内存 新添加
delete[] L;
L = NULL;
for (int i = 0; i < 2; i++)
{
delete[] nodes[i];
nodes[i] = NULL;
}
delete[] nodes;
nodes = NULL;
delete[] belongs;
belongs = NULL;
}
return 1;
} 
void TLD::bbPoints(vector<cv::Point2f>& points,const BoundingBox& bb){
int max_pts=10;
int margin_h=0;
int margin_v=0;
int stepx = ceil((bb.width-2.0*margin_h)/max_pts);
int stepy = ceil((bb.height-2.0*margin_v)/max_pts);
for (int y=bb.y+margin_v;y<bb.y+bb.height-margin_v;y+=stepy){
for (int x=bb.x+margin_h;x<bb.x+bb.width-margin_h;x+=stepx){
points.push_back(Point2f(x,y));
}
}
}然后 修改下面的内容,暂时没有修改,先测试下,看看测试的结果

二、TLD算法研究
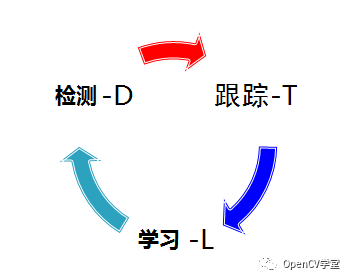
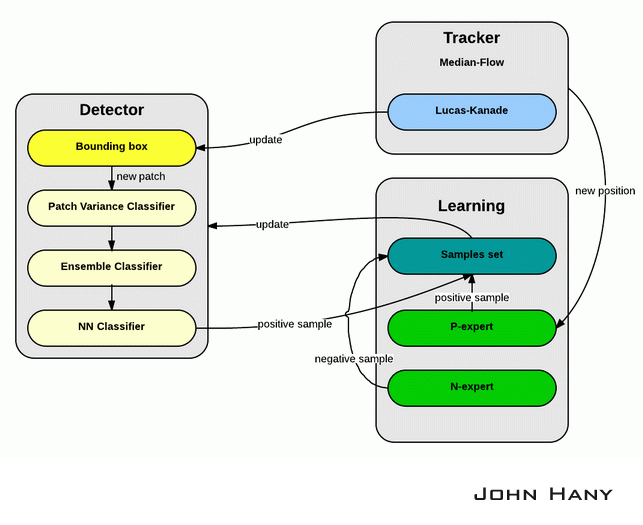
TLD算法主要由三个模块构成:追踪器(tracker),检测器(detector)和机器学习(learning)
对于视频追踪来说,常用的方法有两种:
一是使用追踪器根据物体在上一帧的位置预测它在下一帧的位置,但这样会积累误差,而且一旦物体在图像中消失,追踪器就会永久失效,即使物体再出现也无法完成追踪;
另一种方法是使用检测器,对每一帧单独处理检测物体的位置,但这又需要提前对检测器离线训练,只能用来追踪事先已知的物体。
TLD是对视频中未知物体的长时间跟踪的算法。“未知物体”指的是任意的物体,在开始追踪之前不知道哪个物体是目标。“长时间跟踪”又意味着需要算法实时计算,在追踪中途物体可能会消失再出现,而且随着光照、背景的变化和由于偶尔的部分遮挡,物体在像素上体现出来的“外观”可能会发生很大的变化。从这几点要求看来,单独使用追踪器或检测器都无法胜任这样的工作。所以作者提出把追踪器和检测器结合使用,同时加入机器学习来提高结果的准确度。
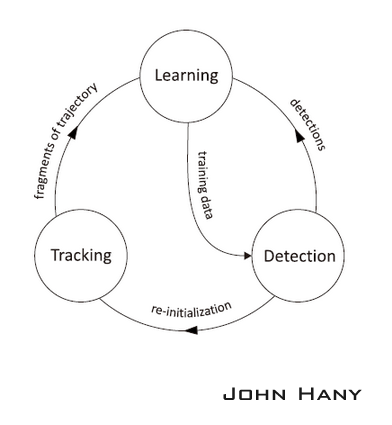
追踪器的作用是跟踪连续帧间的运动,当物体始终可见时跟踪器才会有效。追踪器根据物体在前一帧已知的位置估计在当前帧的位置,这样就会产生一条物体运动的轨迹,从这条轨迹可以为学习模块产生正样本(Tracking->Learning)。
检测器的作用是估计追踪器的误差,如果误差很大就改正追踪器的结果。检测器对每一帧图像都做全面的扫描,找到与目标物体相似的所有外观的位置,从检测产生的结果中产生正样本和负样本,交给学习模块(Detection->Learning)。算法从所有正样本中选出一个最可信的位置作为这一帧TLD的输出结果,然后用这个结果更新追踪器的起始位置(Detection->Tracking)。
学习模块根据追踪器和检测器产生的正负样本,迭代训练分类器,改善检测器的精度(Learning->Detection)。
2.1 追踪模块
TLD使用作者自己提出的Median-Flow追踪算法。Median-Flow追踪算法采用的是Lucas-Kanade追踪器,也就是常说的光流法追踪器。只需要知道给定若干追踪点,追踪器会根据像素的运动情况确定这些追踪点在下一帧的位置。

算法的原理:首先在上一帧t的物体包围框里均匀地产生一些点,然后用Lucas-Kanade追踪器正向追踪这些点到t+1帧,再反向追踪到t帧,计算FB误差,筛选出FB误差最小的一半点作为最佳追踪点。最后根据这些点的坐标变化和距离的变化计算t+1帧包围框的位置和大小(平移的尺度取中值,缩放的尺度取中值。取中值的光流法,估计这也是名称Median-Flow的由来吧)。
还可以用NCC(Normalized Cross Correlation,归一化互相关)
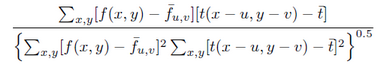
SSD(Sum-of-Squared Differences,差值平方和):
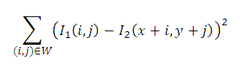
作为筛选追踪点的衡量标准。作者的代码中是把FB误差和NCC结合起来的,所以筛选出的追踪点比原来一半还要少。
2.2 学习模块
可以将跟踪数据分类提供给检测器,用来提供下一帧的跟踪精度,同时还可以重新初始化检测器,从而避免跟踪过程频繁失败的情况发生。
TLD使用的机器学习方法是作者提出的P-N学习(P-N Learning)。P-N学习是一种半监督的机器学习算法,它针对检测器对样本分类时产生的两种错误提供了两种“专家”进行纠正:(PN学习可参考:再谈PN学习_ChenLee_1的博客-CSDN博客)
P专家(P-expert):检出漏检(false negative,正样本误分为负样本)的正样本;
N专家(N-expert):改正误检(false positive,负样本误分为正样本)的正样本。
样本的产生:
用不同尺寸的扫描窗(scanning grid)对图像进行逐行扫描,每在一个位置就形成一个包围框(bounding box),包围框所确定的图像区域称为一个图像元(patch),图像元进入机器学习的样本集就成为一个样本。扫描产生的样本是未标签样本,需要用分类器来分类,确定它的标签。
如果算法已经确定物体在t+1帧的位置(实际上是确定了相应包围框的位置),从检测器产生的包围框中筛选出10个与它距离最近的包围框(两个包围框的交的面积除以并的面积大于0.7),对每个包围框做微小的仿射变换(平移10%、缩放10%、旋转10°以内),产生20个图像元,这样就产生200个正样本。再选出若干距离较远的包围框(交的面积除以并的面积小于0.2),产生负样本。这样产生的样本是已标签的样本,把这些样本放入训练集,用于更新分类器的参数。下图中的a图展示的是扫描窗的例子。

例如:目标车辆是下面的深色车,每一帧中黑色框是检测器检测到的正样本,黄色框是追踪器产生的正样本,红星标记的是每一帧最后的追踪结果。在第t帧,检测器没有发现深色车,但P专家根据追踪器的结果认为深色车也是正样本,N专家经过比较,认为深色车的样本更可信,所以把浅色车输出为负样本。第t+1帧的过程与之类似。第t+2帧时,P专家产生了错误的结果,但经过N专家的比较,又把这个结果排除了,算法仍然可以追踪到正确的车辆。
2.3 检测模块
检测模块使用一个级联分类器,对从包围框获得的样本进行分类。级联分类器包含三个级别:
该模块的介绍可以参考以下博文:
TLD学习_膝盖走路JYM的博客-CSDN博客
2.4 总结
首先,检测器由一系列包围框产生样本,经过级联分类器产生正样本,放入样本集;然后使用追踪器估计出物体的新位置,P专家根据这个位置又产生正样本,N专家从这些正样本里选出一个最可信的,同时把其他正样本标记为负;最后用正样本更新检测器的分类器参数,并确定下一帧物体包围框的位置。