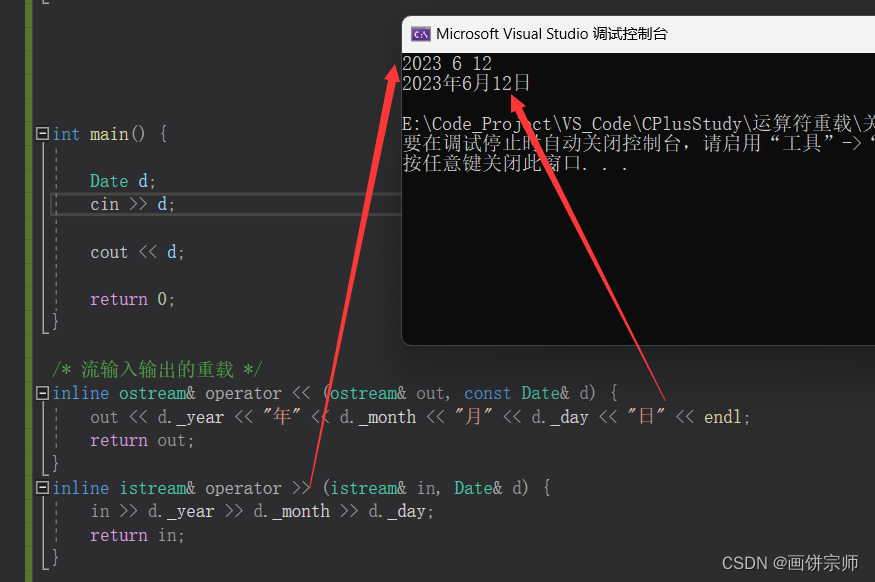
到目前为止,我们已经为节点分类任务单独以全批方式训练了图神经网络。特别是,这意味着每个节点的隐藏表示都是并行计算的,并且可以在下一层中重复使用。
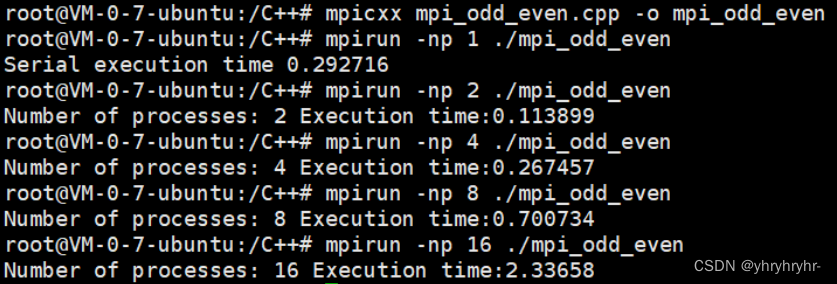
然而,一旦我们想在更大的图上操作,由于内存消耗爆炸,这种方案就不再可行。例如,一个具有大约1000万个节点和128个隐藏特征维度的图已经为每层消耗了大约5GB的GPU内存。
因此,最近有一些努力让图神经网络扩展到更大的图。其中一种方法被称为Cluster-GCN (Chiang et al. (2019),它基于将图预先划分为子图,可以在子图上以小批量的方式进行操作。
为了展示,让我们从 Planetoid 节点分类基准套件(Yang et al. (2016))中加载PubMed 图:
import torch
from torch_geometric.datasets import Planetoid
from torch_geometric.transforms import NormalizeFeatures
dataset = Planetoid(root='data/Planetoid', name='PubMed', transform=NormalizeFeatures())
print()
print(f'Dataset: {dataset}:')
print('==================')
print(f'Number of graphs: {len(dataset)}')
print(f'Number of features: {dataset.num_features}')
print(f'Number of classes: {dataset.num_classes}')
data = dataset[0] # Get the first graph object.
print()
print(data)
print('===============================================================================================================')
# Gather some statistics about the graph.
print(f'Number of nodes: {data.num_nodes}')
print(f'Number of edges: {data.num_edges}')
print(f'Average node degree: {data.num_edges / data.num_nodes:.2f}')
print(f'Number of training nodes: {data.train_mask.sum()}')
print(f'Training node label rate: {int(data.train_mask.sum()) / data.num_nodes:.3f}')
print(f'Has isolated nodes: {data.has_isolated_nodes()}')
print(f'Has self-loops: {data.has_self_loops()}')
print(f'Is undirected: {data.is_undirected()}')

可以看出,该图大约有19717个节点。虽然这个数量的节点应该可以轻松地放入GPU内存,但它仍然是一个很好的例子,可以展示如何在PyTorch Geometric中扩展GNN。
Cluster-GCN的工作原理是首先基于图划分算法将图划分为子图。因此,GNN被限制为仅在其特定子图内进行卷积,从而省略了邻域爆炸的问题。

然而,在对图进行分区后,会删除一些链接,这可能会由于有偏差的估计而限制模型的性能。为了解决这个问题,Cluster-GCN还将类别之间的连接合并到一个小批量中,这导致了以下随机划分方案:

这里,颜色表示每批维护的邻接信息(对于每个epoch可能不同)。PyTorch Geometric提供了Cluster-GCN算法的两阶段实现:
ClusterData将一个Data对象转换为包含num_parts分区的子图的数据集。- 给定一个用户定义的
batch_size,ClusterLoader实现随机划分方案以创建小批量。
然后,制作小批量的程序如下:
from torch_geometric.loader import ClusterData, ClusterLoader
torch.manual_seed(12345)
cluster_data = ClusterData(data, num_parts=128) # 1. Create subgraphs.
train_loader = ClusterLoader(cluster_data, batch_size=32, shuffle=True) # 2. Stochastic partioning scheme.
print()
total_num_nodes = 0
for step, sub_data in enumerate(train_loader):
print(f'Step {step + 1}:')
print('=======')
print(f'Number of nodes in the current batch: {sub_data.num_nodes}')
print(sub_data)
print()
total_num_nodes += sub_data.num_nodes
print(f'Iterated over {total_num_nodes} of {data.num_nodes} nodes!')

在这里,我们将初始图划分为128个分区,并使用32个子图的batch_size来形成mini-batches(每个epoch4批)。正如我们所看到的,在一个epoch之后,每个节点都被精确地看到了一次。
Cluster-GCN的伟大之处在于它不会使GNN模型的实现复杂化。我们构造如下一个简单模型:

这种图神经网络的训练与用于图分类任务的图神经网络训练非常相似。我们现在不再以全批处理的方式对图进行操作,而是对每个小批进行迭代,并相互独立地优化每个批:
model = GCN(hidden_channels=16)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)
criterion = torch.nn.CrossEntropyLoss()
def train():
model.train()
for sub_data in train_loader: # Iterate over each mini-batch.
out = model(sub_data.x, sub_data.edge_index) # Perform a single forward pass.
loss = criterion(out[sub_data.train_mask], sub_data.y[sub_data.train_mask]) # Compute the loss solely based on the training nodes.
loss.backward() # Derive gradients.
optimizer.step() # Update parameters based on gradients.
optimizer.zero_grad() # Clear gradients.
def test():
model.eval()
out = model(data.x, data.edge_index)
pred = out.argmax(dim=1) # Use the class with highest probability.
accs = []
for mask in [data.train_mask, data.val_mask, data.test_mask]:
correct = pred[mask] == data.y[mask] # Check against ground-truth labels.
accs.append(int(correct.sum()) / int(mask.sum())) # Derive ratio of correct predictions.
return accs
for epoch in range(1, 51):
loss = train()
train_acc, val_acc, test_acc = test()
print(f'Epoch: {epoch:03d}, Train: {train_acc:.4f}, Val Acc: {val_acc:.4f}, Test Acc: {test_acc:.4f}')

在本文中,我们向您介绍了一种将 scale GNNs to large graphs的方法,否则这些图将不适合GPU内存。
本文内容参考:PyG官网

![[CKA]考试之K8s 版本升级](https://img-blog.csdnimg.cn/e7da1dd29b2f4bea8ecc182f507a4347.png)