引言
我们在做接口测试,经常会用到excel去管理测试数据,对Excel的操作比较频繁,那么使用python如何操作Excel文件的读与写呢?由于之前讲的都是大的框框,没有讲这么小的模块使用,现在就化整为0的讲解。
读写模块介绍
python有三个模块是对Excel文件的操作,分别是:openpyxl,xlrd和xlwt。下面简单的介绍一下各个模块的特点及使用案例。
如果你想学习自动化测试,我这边给你推荐一套视频,这个视频可以说是B站播放全网第一的接口测试教程,同时在线人数到达1000人,并且还有笔记可以领取及各路大神技术交流:798478386
B站讲的最详细的Python接口自动化测试实战教程全集(实战最新版)_哔哩哔哩_bilibiliB站讲的最详细的Python接口自动化测试实战教程全集(实战最新版)共计200条视频,包括:1、接口自动化之为什么要做接口自动化、2、接口自动化之request全局观、3、接口自动化之接口实战等,UP主更多精彩视频,请关注UP账号。 https://www.bilibili.com/video/BV17p4y1B77x/?spm_id_from=333.337.search-card.all.click
https://www.bilibili.com/video/BV17p4y1B77x/?spm_id_from=333.337.search-card.all.click
xlrd
xlrd是用来从Excel中读写数据的,但我平常只用它进行读操作,写操作会遇到些问题。用xlrd进行读取比较方便,流程和平常手动操作Excel一样,打开工作簿(Workbook),选择工作表(sheets),然后操作单元格(cell)。下面举个例子,例如要打开当前目录下名为”data.xlsx”的Excel文件,选择第一张工作表,然后读取第一行的全部内容并打印出来。Python代码如下:
import os
import xlrd
from xlutils.copy import copy
# 获取当前文件的绝对路径
curPath = os.path.abspath(os.path.dirname(__file__))
print(curPath)
# 获取项目根目录
rootPath = os.path.abspath(os.path.dirname(curPath))
print(rootPath)
# 获取文件路径
file_path = r'APItest_ddt\data\data.xls'
file_path = os.path.join(rootPath,file_path)
print(file_path)
#打开excel文件
data=xlrd.open_workbook(file_path)
#获取第一张工作表(通过索引的方式)
table=data.sheets()[0]
#data_list用来存放数据
data_list=[]
#将table中第一行的数据读取并添加到data_list中
data_list.extend(table.row_values(0))
#打印出第一行的全部数据
for item in data_list:
print(item)
# 写入数据
copy_data = copy(data)
# 读取复制的excel的sheet页
copy_data_to_sheet = copy_data.get_sheet(0)
# 通过get_sheet()获取的sheet有write()方法,写入数据
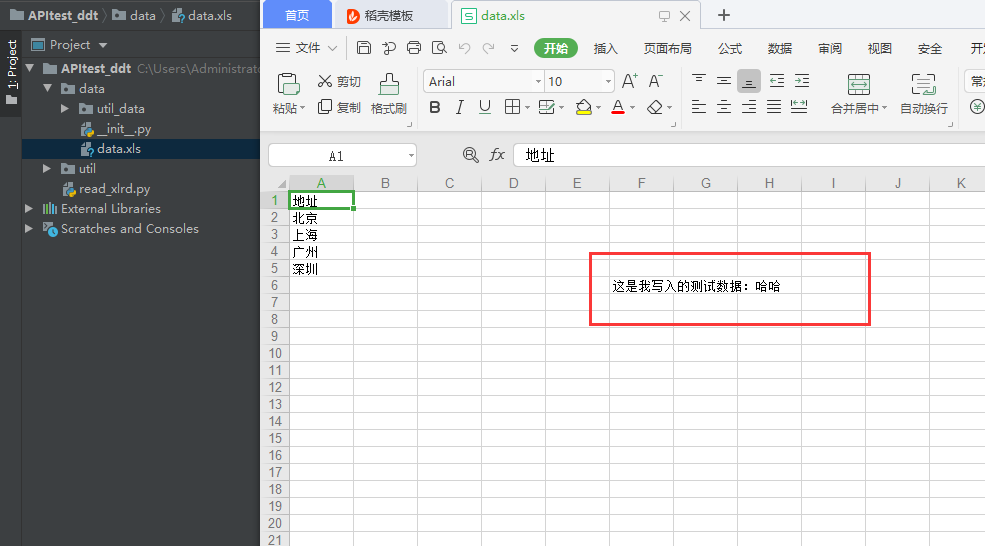
copy_data_to_sheet.write(5,5,"这是我写入的测试数据:哈哈")
# 保存数据
copy_data.save(file_path)运行结果:
C:\Users\Administrator\Desktop\APItest_ddt
C:\Users\Administrator\Desktop
C:\Users\Administrator\Desktop\APItest_ddt/data/data.xls
地址打开data.xls文件:
在处理excel数据时发现了xlwt的局限性–不能写入超过65535行、256列的数据(因为它只支持Excel 2003及之前的版本,在这些版本的Excel中行数和列数有此限制),这对于实际应用还是不够的。为此经过一番寻找发现了一个支持07/10/13版本Excel的openpyxl,虽然功能很强大,但是操作起来感觉没有xlwt方便。以上是xlrd的几个简单操作,并且可以发现,xlrd可以读,也可以写的。只是写的话,没那么方便。
xlwt
如果说xlrd不是一个单纯的Reader(如果把xlrd中的后两个字符看成Reader,那么xlwt后两个字符类似看成Writer),那么xlwt就是一个纯粹的Writer了,因为它只能对Excel进行写操作。xlwt和xlrd不光名字像,连很多函数和操作格式也是完全相同。下面简要归纳一下常用操作。
import xlwt
# 新建一个Excel文件(只能通过新建写入)
data=xlwt.Workbook()
# 新建一个工作表
table=data.add_sheet('name')
# 写入数据到A1单元格
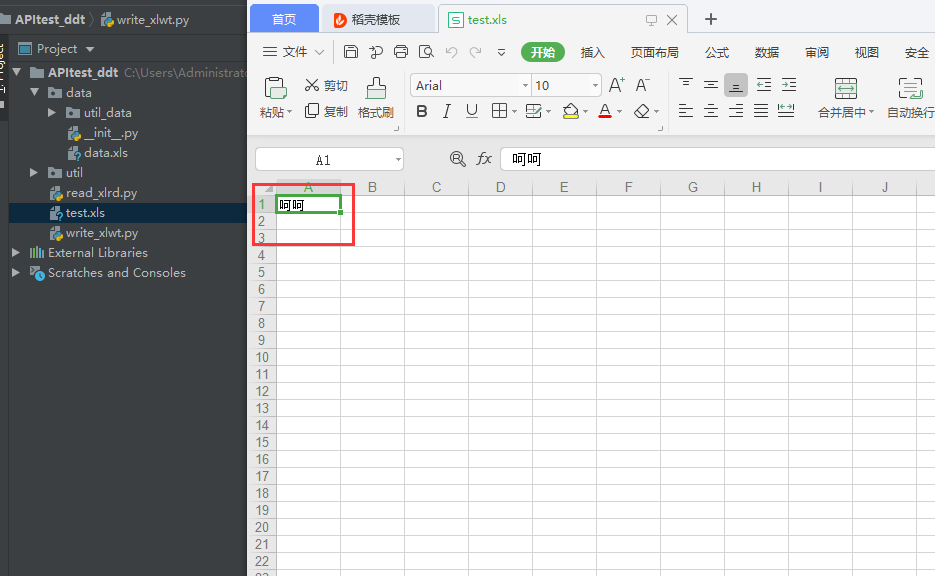
table.write(0,0,u'呵呵')
# 注意:如果对同一个单元格重复操作,会引发overwrite Exception,想要取消该功能,需要在添加工作表时指定为可覆盖,像下面这样
table=data.add_sheet('sheet1',cell_overwrite_ok=True)
# 保存
data.save('test.xls')查看结果:
openpyxl
该模块支持最新版的Excel文件格式,对Excel文件具有响应的读写操作,对此有专门的Reader和Writer两个类,便于对Excel文件的操作。虽然如此,但我一般还是用默认的workbook来进行操作。常用操作归纳如下:
from openpyxl.reader.excel import load_workbook
wb=load_workbook(filename=r"openpyxl_test.xlsx")
import openpyxl
if __name__ == '__main__':
wb = load_workbook(filename=r"openpyxl_test.xlsx")
# 显示所有工作表的名字
sheet_name = wb.get_sheet_names()
print(sheet_name)
# 取第一张表
sheetnames = wb.sheetnames
ws = wb[sheetnames[0]]
# 显示表名,表行数,表列数
print("Work Sheet Title:", ws.title)
print("Work Sheet Rows:", ws.max_row)
print("Work Sheet Cols:", ws.max_column)
# 获取指定行的值,如第三行
row3_values = []
row3_cell_list = list(ws.rows)[2]
for cell in row3_cell_list:
row3_values.append(cell.value)
print(row3_values) # output:['A3', 'B3', 'C3', 'D3']
# 获取所有行的数据
# 建立存储数据的字典
data = {}
# 获取表格所有值
# 法1:
for i in range(0, ws.max_row):
every_row_values = []
every_row_cell_list = list(ws.rows)[i]
for cell in every_row_cell_list:
every_row_values.append(cell.value)
data[i + 1] = every_row_values
print(data)
# {1: ['A1', 'B1', 'C1', 'D1'], 2: ['A2', 'B2', 'C2', 'D2'], 3: ['A3', 'B3', 'C3', 'D3'], 4: ['A4', 'B4', 'C4', 'D4'], 5: ['A5', 'B5', 'C5', 'D5'],
# 6: ['A6', 'B6', 'C6', 'D6'], 7: ['A7', 'B7', 'C7', 'D7'], 8: ['A8', 'B8', 'C8', 'D8'], 9: ['A9', 'B9', 'C9', 'D9'], 10: ['A10', 'B10', 'C10', 'D10'],
# 11: ['A11', 'B11', 'C11', 'D11']}
# 法2
for row in ws.rows:
line = [cell.value for cell in row]
print(
line) # output:['A1', 'B1', 'C1', 'D1'],['A2', 'B2', 'C2', 'D2'], ['A3', 'B3', 'C3', 'D3'],['A4', 'B4', 'C4', 'D4'], ['A5', 'B5', 'C5', 'D5'],['A6', 'B6', 'C6', 'D6'],['A7', 'B7', 'C7', 'D7'],['A8', 'B8', 'C8', 'D8'],['A9', 'B9', 'C9', 'D9'],['A10', 'B10', 'C10', 'D10'],['A11', 'B11', 'C11', 'D11']
# 获取某个区间的值,例:获得了以A3为左上角,C6为右下角矩形区域的所有单元格
# 法1:使用range
data1 = {}
for i in range(2, 6):
every_row_values = []
every_row_cell_list = list(ws.rows)[i]
for cell in every_row_cell_list:
every_row_values.append(cell.value)
data1[i + 1] = every_row_values
print(data1)
# output{3: ['A3', 'B3', 'C3', 'D3'], 4: ['A4', 'B4', 'C4', 'D4'], 5: ['A5', 'B5', 'C5', 'D5'], 6: ['A6', 'B6', 'C6', 'D6']}
# 法2:使用切片
data_list = []
for row_cell in ws['A3':'C6']:
every_row_value = []
for cell in row_cell:
every_row_value.append(cell.value)
data_list.append(every_row_value)
print(data_list) # output:[['A3', 'B3', 'C3'], ['A4', 'B4', 'C4'], ['A5', 'B5', 'C5'], ['A6', 'B6', 'C6']]
# 测试写入数据:
wb = load_workbook(filename=r"openpyxl_test.xlsx")
ws = wb.active
# 第一个sheet是ws
ws = wb.worksheets[0]
# 设置ws的名称
ws.title = "range names"
# 向某个单元格中写入数据
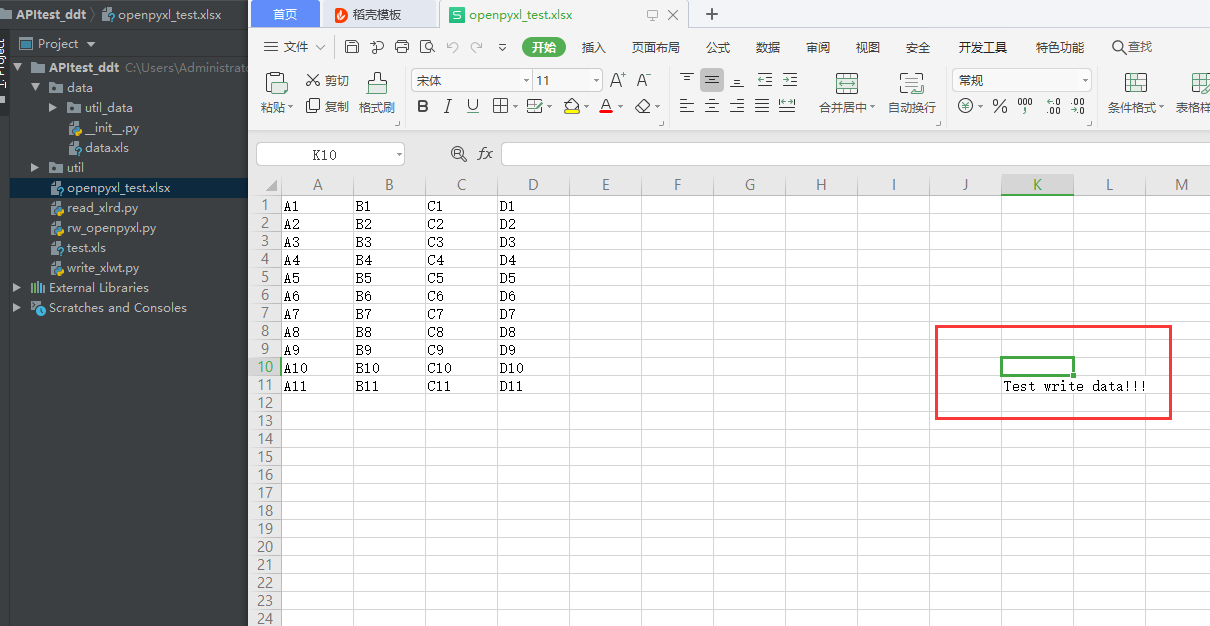
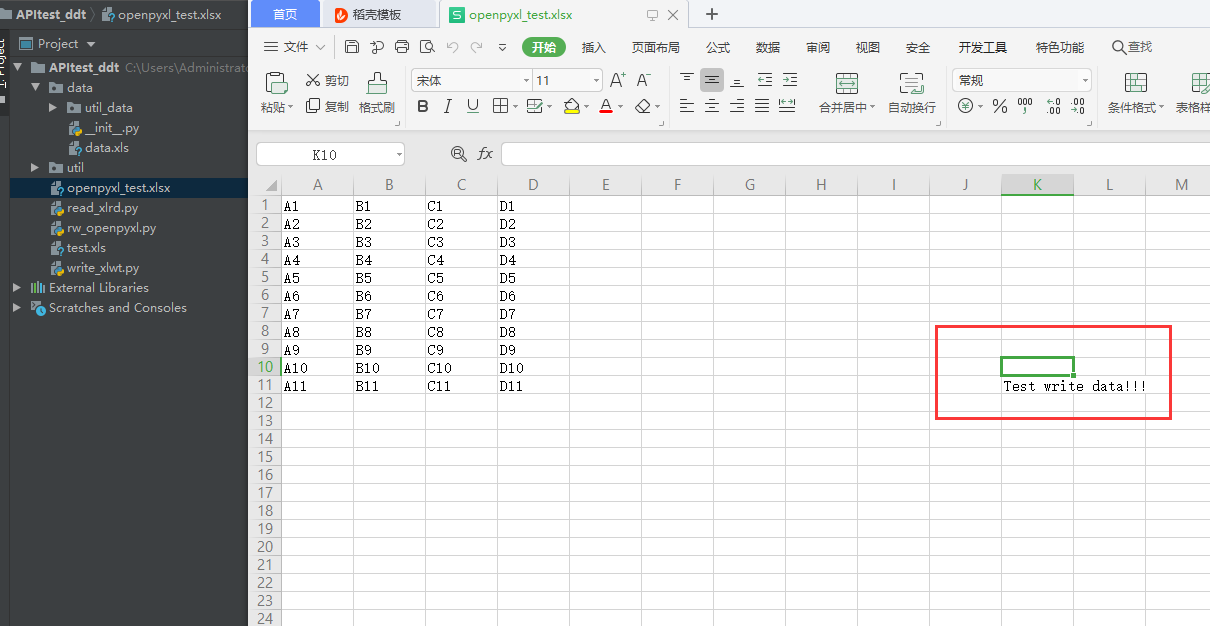
ws.cell(11,11).value = u'Test write data!!!'
# 最后保存文件
wb.save(filename=r"openpyxl_test.xlsx")结果如下:
封装读写
上面已经介绍了三个模块的使用,那么在搭建接口测试框架的时候,不可能这样写,一方面不利于代码可读性与维护,另一方面不雅观。所以,要对零散的代码进行二次封装,一下就是针对常用方法进行二次封装:
import xlrd
from xlutils.copy import copy
import os
# 获取当前文件的绝对路径
curPath = os.path.abspath(os.path.dirname(__file__))
print(curPath)
# 获取项目根目录
rootPath = os.path.abspath(os.path.dirname(curPath))
print(rootPath)
# 类中使用装饰器 @classmethod定义方法,是类方法
# 类中使用装饰器 @staticmethod定义方法,是静态方法
class Operate_Excel(object):
"""
操作excel类
"""
# 定义构造函数,创建对象自动执行
def __init__(self,file_path=None,sheet_id=None):
"""
:param file_path:如果没传值,默认为excel路径
:param sheet_id:如果没传值,默认为第一个sheet页
"""
if file_path:
# 成员变量
self.file_path = file_path
self.sheet_id = sheet_id
else:
self.file_path = r'data/util_data/operate_excel.xls'
# 将文件目录拼接成绝对路径
self.file_path = os.path.join(rootPath,self.file_path)
print(self.file_path)
if sheet_id:
self.sheet_id = sheet_id
else:
self.sheet_id = 0
# 调用成员方法
self.sheet_table = self.get_sheet()
"""成员方法"""
# 获取sheet页操作对象
def get_sheet(self):
data = xlrd.open_workbook(self.file_path)
sheet_table = data.sheets()[self.sheet_id]
return sheet_table
# 获取sheet页的行数和列数,返回的是一个元组
def get_sheet_nrows_ncols(self):
return self.sheet_table.nrows,self.sheet_table.ncols
# 获取sheet页的行数
def get_sheet_nrows(self):
return self.sheet_table.nrows
# 获取sheet页的列数
def get_sheet_ncols(self):
return self.sheet_table.ncols
# 获取具体单元格的数据
def get_sheet_cell(self,row,col):
"""
:params row: 单元格行值
:params col: 单元格列值
:return: cell_data
"""
cell_data = self.sheet_table.cell_value(row,col)
return cell_data
# 写入数据到excel中
def write_to_excel(self,row,col,values):
# 打开excel文件读取数据句柄
data = xlrd.open_workbook(self.file_path)
# 复制excel
copy_data = copy(data)
# 读取复制的excel的sheet页
copy_data_to_sheet = copy_data.get_sheet(0)
# 通过get_sheet()获取的sheet有write()方法,写入数据
copy_data_to_sheet.write(row,col,values)
# 保存数据
copy_data.save(self.file_path)
if __name__ == '__main__':
read_xls = Operate_Excel()
print("获取excel表的行数与列数,返回元组格式: ",read_xls.get_sheet_nrows_ncols())
print("获取excel表的行数: ",read_xls.get_sheet_nrows())
print("获取excel表的列数: ",read_xls.get_sheet_ncols())
print("获取excel表的单元格(1,1)的值: ",read_xls.get_sheet_cell(1,1))
print("获取excel表的单元格(1,2)的值: ",read_xls.get_sheet_cell(1,2))
print("获取excel表的单元格(2,2)的值: ",read_xls.get_sheet_cell(2,2))
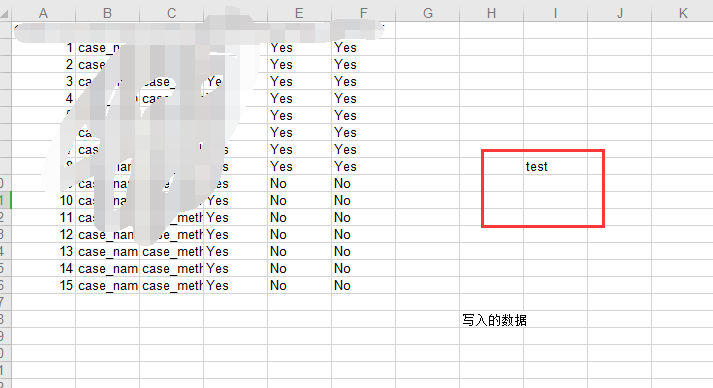
print("写入excel表的单元格(2,2)的值: ",read_xls.write_to_excel(8,8,'test'))运行结果:
获取excel表的行数与列数,返回元组格式: (18, 9)
获取excel表的行数: 18
获取excel表的列数: 9
获取excel表的单元格(1,1)的值: case_name01
获取excel表的单元格(1,2)的值: case_method01
获取excel表的单元格(2,2)的值: case_method02
写入excel表的单元格(2,2)的值: Noneexcel文件:
总结
到此,Excel读写功能已经介绍完,以上功能大部分满足日常使用,当然你也可以深入研究,继续加入其它方法进来。以上源码,已上传到群文件中,可以加入QQ测试开发交流群:798478386 索取。