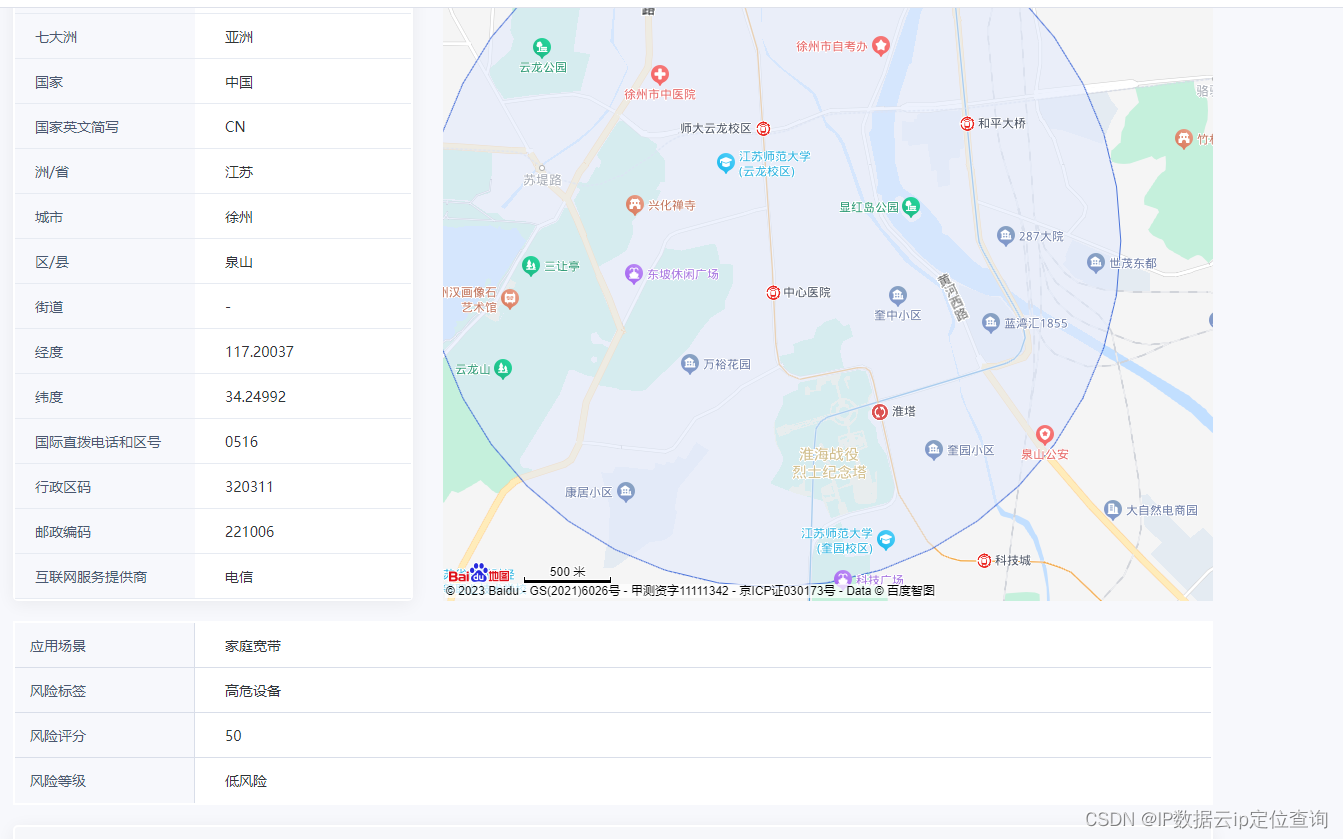
顾名思义,单链表就是一个相邻节点用一个单向指针串起来,形成一种链式结构,那怎么将这些节点连结起来方便管理呢?
目录
单链表定义
申请空间
创建节点
打印链表
尾插
尾删
头插
头删
查找
插入
删除
pos后删除
pos位置删除
释放
完整代码
单链表定义
typedef int SLDateType
typedef struct SListNode
{
SLTDataType data;
struct SListNode* next;
}SLTNode;需要注意,在结构体定义时定义的typedef需要在出了结构体才生效,不能直接在结构体内使用。
在定义一个单链表节点时,我们只能在堆上申请空间,因为局部的声明周期在出了作用域后消失,而全局是静态区里的,做不到动态的增删查改数据,所以在堆区使得管理更加灵活高效。
申请空间
在顺序表中插入数据需要检查节点空间是否足够来选择是否进行扩容,在单链表中每创建一个节点都要进行一次动态开辟,我们可以实现一个函数来满足我们的需求。
SLTNode* BuySLTNode(SLTDataType x)
{
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));//节点
if(newnode == nullptr)
{
perror("malloc fail");
exit(-1);
}
newnode->data = x;
newnode->next = nullptr;//置空,否则野指针
return newnode;
}因为这里每个申请的节点都是独立的,所以不像顺序表一样开辟失败可以用一个临时对象接收。
我们先来测试一下:
 可以看到我们成功申请了空间,但是现在他们之间彼此独立,所以我们要将他们链接起来。在这之前,给大家引入一个很重要的概念:逻辑结构和物理结构
可以看到我们成功申请了空间,但是现在他们之间彼此独立,所以我们要将他们链接起来。在这之前,给大家引入一个很重要的概念:逻辑结构和物理结构
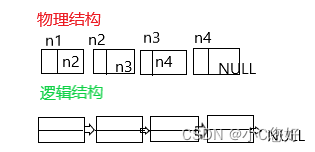
这里的n1,n2...是指向的是堆上的空间,本身(地址)是在栈上。
n1->next = n2;
n2->next = n3;
n3->next = n4;
n4->next = NULL;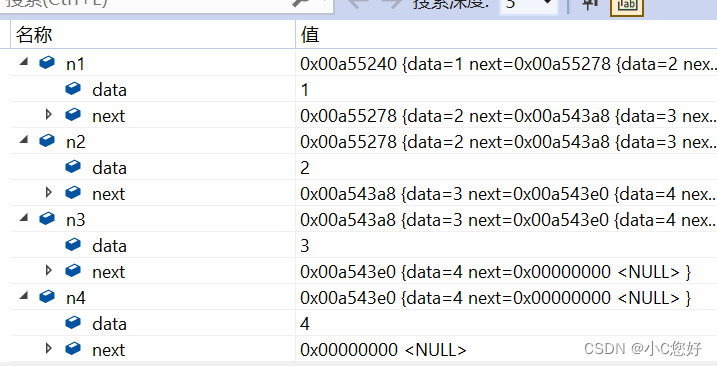
我们把它封装成一个函数,方便创建n个节点的链表。
创建节点
SLTNode* CreateSList(int n)
{
SLTNode* phead = nullptr, *ptail = nullptr;
//int x=0;
for (int i = 0; i < n; i++)
{
//sacnf("%d",&x);
SLTNode* newnode = BuySLTNode(i);//新节点
if (phead == nullptr)
{
phead = ptail = newnode;
}
else
{
ptail->next = newnode;
ptail = newnode;
}
}
return phead;
}phead记录头部是为了返回时能够找到这个指针的起始位置,ptail负责移动并更新为下一个节点,创建n个节点后ptail的next指向空。
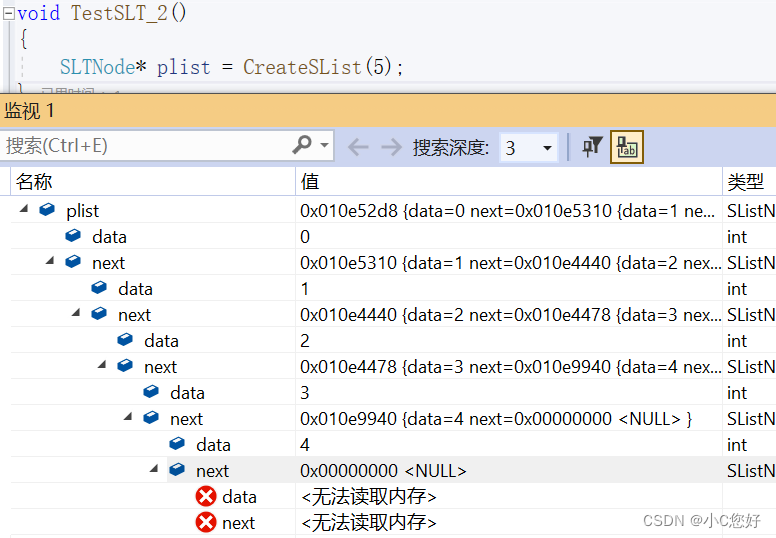 成功链接起来!虽然phead也会销毁,但我们使用返回的phead指针传递给plist使其找到链表的头。
成功链接起来!虽然phead也会销毁,但我们使用返回的phead指针传递给plist使其找到链表的头。
打印链表
对于打印函数,我们可以不用记录头指针的位置,因为他只是对链表进行一个读,它的作用域在打印完链表后结束。
void Print(SLTNode* plist)
{
//SLTNode* cur = plist;
while (plist != nullptr)
{
printf("%d->", plist->data);
plist = plist->next;
}
printf("NULL");//方便判空
}不用加assert因为空链表也能打印

到这里大家可能感受到单链表的特点了,它只需一个指针就能连结所有节点,前提是必须要有一个指针指向它的头部。而顺序表是一个具有连续储存空间的结构,需要size和capacity来记录数据。
尾插
大家看看下面这段代码有什么问题:
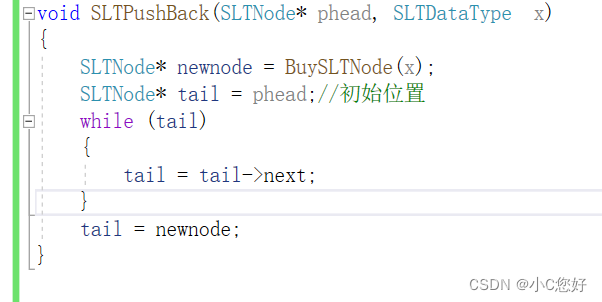
运行结果:

咦,为什么10没有插入进去呢?有没有一种可能它根本就没有被链接起来。
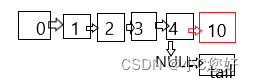
可以看到,错误的程序走的是下面的这条路,在tail为空时进行赋值,导致根本没有被链接上,所以我们应像下面这样写才行:
成功插入!
如果是这种情况:phead为空时,会发生对空指针解引用的情况,我们能用断言处理吗?当然不行,当链表为空时,我们也能插入数据,那我们只能分情况处理。
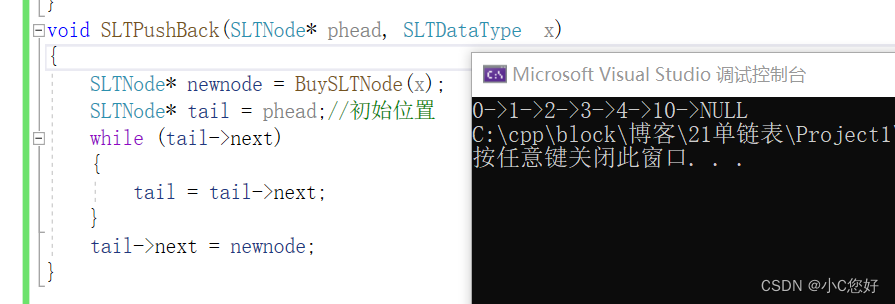
void SLTPushBack(SLTNode* phead, SLTDataType x)
{
SLTNode* newnode = BuySLTNode(x);
if (phead == nullptr)
{
phead = newnode;
}
else
{
SLTNode* tail = phead;//初始位置
while (tail->next)
{
tail = tail->next;
}
tail->next = newnode;
}
}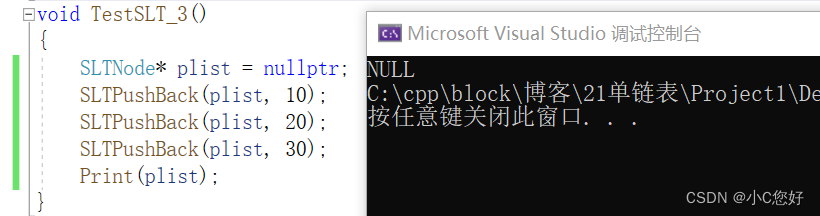
这是怎么回事呢?我们插入的数据都去哪呢?我们用一张图来解释。
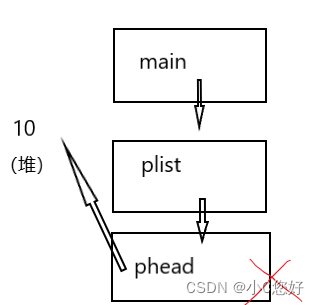
phead是plist的拷贝,也就是说,因为plist此时为空,而传递过去的phead不能遍历plist将数据插入尾部,在堆上申请的空间并不会影响plist,在函数结束时phead销毁,造成内存泄露。
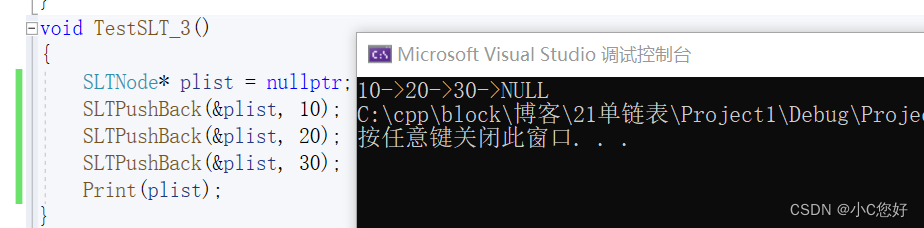
正确的做法是传递plist的地址,并用二级指针接收,达到修改plist的效果。
void SLTPushBack(SLTNode** pphead, SLTDataType x)
{
SLTNode* newnode = BuySLTNode(x);
if (*pphead == nullptr)
{
*pphead = newnode;
}
else
{
SLTNode* tail = *pphead;//实际是接收plist
while (tail->next)
{
tail = tail->next;
}
tail->next = newnode;
}
}
前面测试时不传二级指针能行是因为我们改变的是结构体,现在我们改变的是一级指针,所以我们统一传二级指针,以绝后患。
尾删
void SLTPopBack(SLTNode* phead)
{
assert(phead);
SLTNode* ptail = phead;
while (ptail->next)
{
ptail = ptail->next;
}
free(ptail);
ptail = nullptr;
}
这段代码是不是没有任何问题?如果你这样想就大错特错了。因为ptail是局部变量,是对实参的拷贝,如果仅剩一个数据,作用域内将它置空不会影响phead。如果不只一个数据,应将前一个位置的next置空。
为此我们提供下面两种方式:
void SLTPopBack(SLTNode* phead)
{
//方法1
SLTNode* prev = nullptr;
SLTNode* tail = phead;
while(tail->next)
{
prev = tail;
tail = tail->next;
}
free(tail);
prev->next = nullptr;
}
//方法2
SLTNode* tail = phead;
while(tail->next->next)
{
tail = tail->next;
}
free(tail->next);
tail->next = nullptr;
}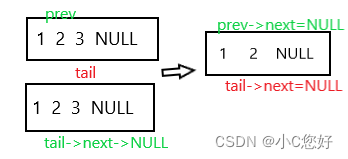
一种是保留最后一个数据的前一个,另一种是找后两个位置,注意判断next是否为空(只有一个数据时)。两种方法都要对只有一个数据的情况进行处理。
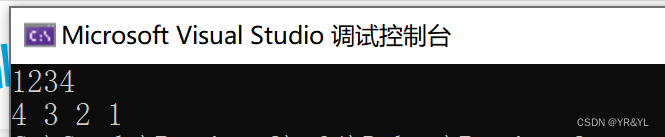
运行结果:
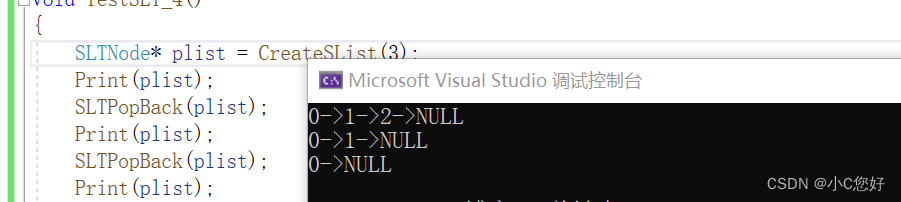
到这里会不会有人觉得程序已经没问题了,当然不是。
如果删到空该怎么办,两种方法中如果tail->next为空又该怎么办
基于种种情况,我们还是必须得用二级指针传参,对这种特殊情况进行处理,规避野指针的情况。
void SLTPopBack(SLTNode** pphead)
{
assert(*pphead);
if ((*pphead)->next == NULL)
{
free(*pphead);
*pphead = NULL;
}
else
{
SLTNode* tail = *pphead;
while (tail->next->next)
{
tail = tail->next;
}
free(tail->next);
tail->next = NULL;
//方法一
//SLTNode* prev = nullptr;
//SLTNode* tail = *pphead;
//while (tail->next)
//{
// prev = tail;//更新
// tail = tail->next;
//}
//free(prev->next);//free(tail);
//prev->next = NULL;
}
}需要注意的是,因为传递的是二级指针,所以不能直接拿头部去遍历(修改了指针),以后都要注意最好用新的指针遍历链表。
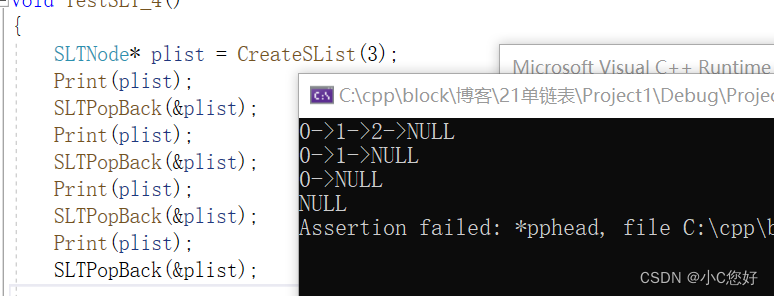 这里我们故意多删了一次,可以看到,程序可以完美运行。
这里我们故意多删了一次,可以看到,程序可以完美运行。
头插
头插的实现十分简单,而且当链表为空时,他也能顺利插入。
void SLTPushFront(SLTNode** pphead, SLTDataType x)//头插
{
SLTNode* newnode = BuySLTNode(x);
newnode->next = *pphead;
*pphead = newnode;
}在这里简要说一下有些程序传一级指针也可以那是因为它记录了一个返回值并被接收,但如果频繁接收反而显得繁杂冗余,所以我们用二级传参的方式。
头删
头删也十分简单,只需在删除前将其储存的下一块空间的地址保存即可。
void SLTPopFront(SLTNode** pphead)//头删
{
assert(*pphead);
SLTNode* next = (*pphead)->next;
free(*pphead);
*pphead = next;
}可以看出头插头删的流程十分简单,这也是单链表的优势所在,它没有尾插尾删那样去遍历和复杂的判断条件。
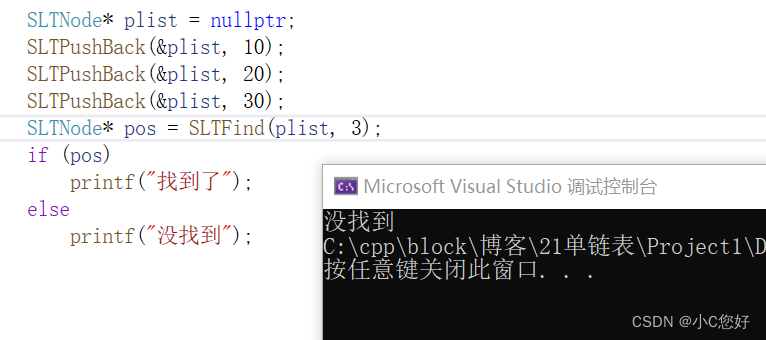
查找
查找跟打印数据一样,只需传递一级指针和所需查找的数据即可,无需判空。
SLTNode* SLTFind(SLTNode* phead, SLTDataType x)//查找
{
SLTNode* cur = phead;
while (cur)
{
if (cur->data == x)
return cur;
cur = cur->next;
}
return nullptr;
}
插入
单链表的插入分为在pos位置前插入和pos位置后插入,一般我们使用在pos位置后插入。
void SListInsertAfter(SLTNode* pos, SLTDataType x)//插入pos之前
{
assert(pos);//找不到不插入
SLTNode* newnode = BuySLTNode(x);
newnode->next = pos->next;
pos->next = newnode;
}注意插入顺序,如果没有保存pos->next的位置或者先让它指向新结点,就会导致死循环。
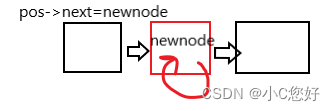
为什么这里不用二级指针?
因为我们并没有改变指针位置,我们只需改变结构体。
这里的pos位置是通过查找函数定位的。
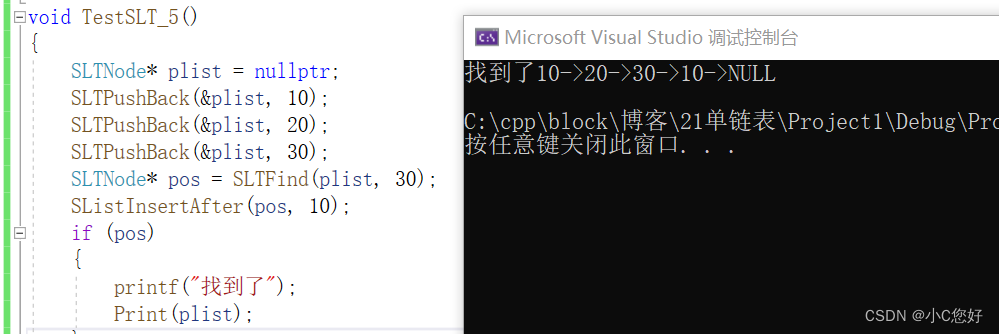
现在思考一下在pos前该怎么插入呢?
因为是pos前插入,所以我们遍历条件是用新指针的next去遍历而非自身。
void SListInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x)//可能改变指针
{
assert(pos);
if (pos == *pphead)
{
SLTPushFront(pphead,x);//等价于头插
}
else
{
SLTNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
SLTNode* newnode = BuySLTNode(x);
prev->next = newnode;
newnode->next = pos;
}
}有人问为什么在pos后插入怎么不复用一个尾插?
因为尾插还要再一次进行遍历,使时间复杂度变为O(n^2)
注意因为我们传递pphead进入头插时传递的是二级指针,二级指针能改变一级指针,等价于传一级指针的地址。
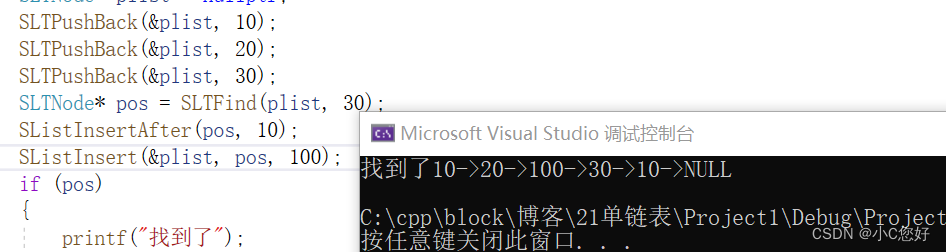
删除
pos后删除
pos后删除需要保存pos的下一个节点再进行连结,最终释放。(不然pos->next将变为野指针)。
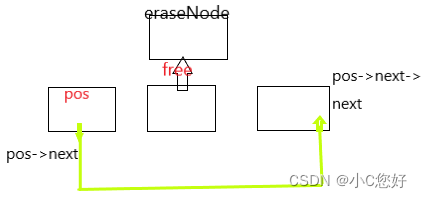
void SLTEraseAfter(SLTNode* pos)//pos后删除
{
assert(pos);
assert(pos->next);//最后一个节点后面没有数据
SLTNode* eraseNode = pos->next;
pos->next = pos->next->next;
free(eraseNode);
}pos位置删除
这里涉及指针改变所以要传递二级指针。我们可以选择保留前一个位置的方式进行删除,只有一个数据就进行头删。
void SLTErase(SLTNode** pphead, SLTNode* pos)//删除
{
assert(pos);
if (pos == *pphead)
{
SLTPopFront(pphead);//头删
}
else
{
SLTNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
prev->next = pos->next;
free(pos);
}
}这里断言pos可以做到同时断言pphead的功能(链表为空时pos亦为空) 。
测试: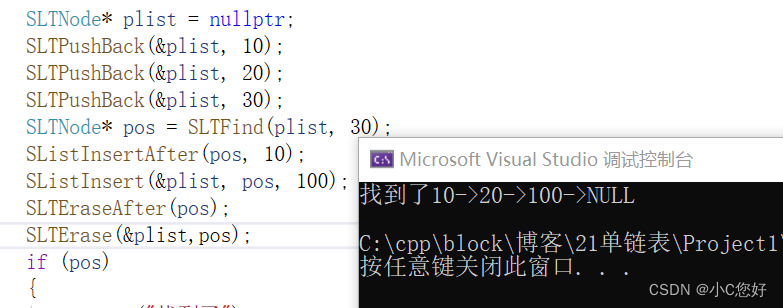
释放
单链表的释放不能像顺序表一样直接释放,我们申请空间时是一次一次申请的,释放也要一次一次释放。因为要将头指针置空,所以我们传递二级指针。
void SLTDestroy(SLTNode** pphead)//释放
{
SLTNode* cur = *pphead;//最好不要用头进行遍历
while (cur)
{
SLTNode* next = cur->next;
free(cur);
cur = next;
}
*pphead = nullptr;//关键置空
}
注意在删除前保存一下下一个节点的地址,并在结束后置空。因为在上一层栈帧如果执行释放操作后再进行其他访问操做不置空可能会产生危害,而函数体内定义的的指针出了作用域就销毁,不用在乎这些指针会有这种问题。
完整代码
//.cpp
#include"SList.h"
SLTNode* BuySLTNode(SLTDataType x)
{
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));//节点
if(newnode == nullptr)
{
perror("malloc fail");
exit(-1);
}
newnode->data = x;
newnode->next = nullptr;
return newnode;
}
SLTNode* CreateSList(int n)
{
SLTNode* phead = nullptr, *ptail = nullptr;
//int x=0;
for (int i = 0; i < n; i++)
{
//sacnf("%d",&x);
SLTNode* newnode = BuySLTNode(i);
if (phead == nullptr)
{
phead = ptail = newnode;
}
else
{
ptail->next = newnode;
ptail = newnode;
}
}
return phead;
}
void SLTPushBack(SLTNode** pphead, SLTDataType x)
{
SLTNode* newnode = BuySLTNode(x);
if (*pphead == nullptr)
{
*pphead = newnode;
}
else
{
SLTNode* tail = *pphead;//实际是接收plist
while (tail->next)
{
tail = tail->next;
}
tail->next = newnode;
}
}
void SListInsertAfter(SLTNode* pos, SLTDataType x)
{
assert(pos);
SLTNode* newnode = BuySLTNode(x);
newnode->next = pos->next;
pos->next = newnode;
}
void SLTPopBack(SLTNode** pphead)
{
assert(*pphead);
if ((*pphead)->next == NULL)
{
free(*pphead);
*pphead = NULL;
}
else
{
SLTNode* tail = *pphead;
while (tail->next->next)
{
tail = tail->next;
}
free(tail->next);
tail->next = NULL;
//方法一
//SLTNode* prev = nullptr;
//SLTNode* tail = *pphead;
//while (tail->next)
//{
// prev = tail;//更新
// tail = tail->next;
//}
//free(prev->next);//free(tail);
//prev->next = NULL;
}
}
void SLTPushFront(SLTNode** pphead, SLTDataType x)//头插
{
SLTNode* newnode = BuySLTNode(x);
newnode->next = *pphead;
*pphead = newnode;
}
void SLTPopFront(SLTNode** pphead)//头删
{
assert(*pphead);
SLTNode* next = (*pphead)->next;
free(*pphead);
*pphead = next;
}
SLTNode* SLTFind(SLTNode* phead, SLTDataType x)//查找
{
SLTNode* cur = phead;
while (cur)
{
if (cur->data == x)
return cur;
cur = cur->next;
}
return nullptr;
}
void SListInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x)
{
assert(pos);
if (pos == *pphead)
{
SLTPushFront(pphead,x);
}
else
{
SLTNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
SLTNode* newnode = BuySLTNode(x);
prev->next = newnode;
newnode->next = pos;
}
}
void SLTEraseAfter(SLTNode* pos)//pos后删除
{
assert(pos);
assert(pos->next);//最后一个节点后面没有数据
SLTNode* eraseNode = pos->next;
pos->next = pos->next->next;
free(eraseNode);
}
void SLTErase(SLTNode** pphead, SLTNode* pos)//删除
{
assert(pos);
if (pos == *pphead)
{
SLTPopFront(pphead);//头删
}
else
{
SLTNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
prev->next = pos->next;
free(pos);
}
}
void Print(SLTNode* plist)
{
//SLTNode* cur = plist;
while (plist != nullptr)
{
//printf("[%d|%p] ", plist->data, plist->next);
printf("%d->", plist->data);
plist = plist->next;
}
printf("NULL\n");
}
void SLTDestroy(SLTNode** pphead)//释放
{
SLTNode* cur = *pphead;//最好不要用头进行遍历
while (cur)
{
SLTNode* next = cur->next;
free(cur);
cur = next;
}
*pphead = nullptr;
}
//.h
#pragma once
#include<stdio.h>
#include <stdlib.h>
#include <assert.h>
typedef int SLTDataType;
typedef struct SListNode
{
SLTDataType data;
struct SListNode* next;
}SLTNode;
SLTNode* BuySLTNode(SLTDataType x);
SLTNode* CreateSList(int n);
void Print(SLTNode* plist);
void SLTPushBack(SLTNode** pphead, SLTDataType x);//尾插
//void SLTPushFront();
void SLTPopBack(SLTNode** pphead);//尾删
void SLTPopFront(SLTNode** pphead);//头删
void SLTPushFront(SLTNode** pphead, SLTDataType x);//头插
SLTNode* SLTFind(SLTNode* phead,SLTDataType x);//查找
void SListInsertAfter(SLTNode* pos, SLTDataType x);//插入pos之前
// 在pos之前插入x
void SListInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x);
void SLTEraseAfter(SLTNode* pos);//pos后删除
void SLTErase(SLTNode** pphead, SLTNode* pos);//删除
void SLTDestroy(SLTNode** pphead);//释放




![[PyTorch][chapter 39][nn.Module]](https://img-blog.csdnimg.cn/d6912724b0794f9287ccfb433b772e71.png)