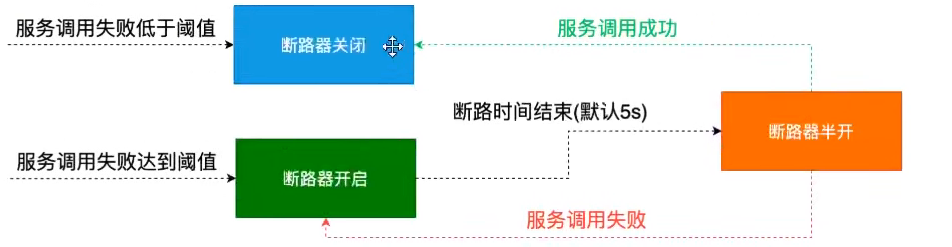
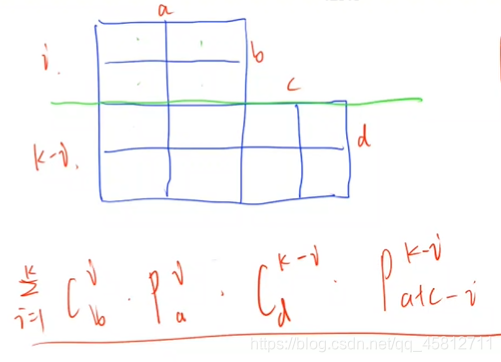
一、定义
1.源域和目标域
源域(Source)和目标域(Target)之间不同但存在联系(different but related)。迁移学习的人物是从源域学习到知识并使其在目标域中取得较好的成绩。
迁移学习可以分为正迁移(postive transfer)和负迁移(negtive transfer),划分依据是迁移学习的效果好坏。
2.迁移学习的优势
①缺乏大量(已标注)数据或计算资源
②需要快速训练个性化模型
③冷启动服务(例如一个新用户的产品推荐,可以依赖用户关联来做)
二、相关符号
域(Domain):
源域(Source Domain):,目标域(Target Domain):
任务(Task):
条件:需要满足以下两个条件之一才是迁移学习:
①域不同:
②任务不同:
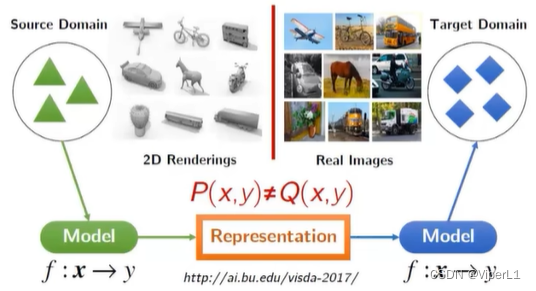
三、迁移学习
1.域不同
进行贝叶斯展开后:
如果相同,其具有不同的边缘分布(marginal distribution):
如果相同,其具有不同的条件分布(conditional distribution):

2.损失函数
经验风险最小化(ERM):;其中 L 为损失函数
上述公式是一般机器学习使用的迭代公式,在迁移学习中,一般通过在后面加入一个迁移正则化表达式(Transfer regularization),可以表示如下:
;其中 R 即为需要学习的参数,一般分以下几种情况对 R 进行学习:
①(子集),可得
,这种情况下不需要R
②R可以写作或
③当两个任务相似时(),可以跳过R的优化
上述三种学习方法分别对应:
①Instance-based TL:基于实例,需要选择一部分样本使其接近目标域,这种方法现在使用比较少,其具体可分为以下几种做法:
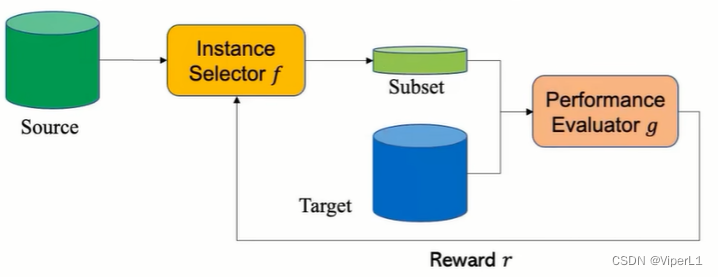
1.Instance selection:设计一个实例选择器,从源域中筛选出和目标域接近的数据,并改变其权重(增加分得好的样本的权重,减少分得不好的样本权重)。其由一个实例选择器(Instance Selector)和一个性能评估器(Performance Evaluator)
组成,按照下图循环执行。总体思路接近强化学习。
2.Instance reweighting:使用这种方法的前提是,且
,
相同。此时,代价函数将被改写为:
,化简后可得
②Feature-based TL:基于特征,将迁移正则项R显式表示并使之最小化,一般为两个域之间的距离。可以根据源域和目标域的类型分为两类:同类特征空间(例如源域和目标域均为图片),异类特征空间(例如源域和目标域一种是文字,一种是图片)

这种方法的前提是源域和目标域之间存在一些通用特征(common features),我们需要做的是将源域和目标域变换到同一特征空间中并缩小其距离。可以分为两种做法:
1.显式距离(Explicit distance):;空间距离,即使用一些数学工具来度量两个域之间的距离。常见的有以下几种:
①基于Kernel:MMD、KL散度、Cosine相似度
②基于几何:流式核(GFK)、协方差、漂移对齐、黎曼流形
其中使用最多的是MMD(最大矩阵差异),详见第四章。
2.隐式距离(Implicit distance):;可分性,在无法选择空间距离的情况下进行,一般使用对抗网络GAN来实现。
3.两者结合(explict+implicit dist):例如MMD-AAE网络、DAAN网络。
③Parameter-based TL:基于参数,复用源域上训练好的模型。代表方法为预训练。
四、MMD
1.定义
MMD,即最大矩阵差异。是一个用来度量域之间差异的值,其可以定义为将x和y分别映射到P和Q两个数据分布上(),
为一个可以将x映射到希尔伯特空间
的函数,MMD计算的是两个域映射后之间期望的最大差异,其数学公式可以写作:
而实际计算时候往往进行有限的随机采样获取一些数据,再计算这些数据的均值差异,这些均值差异中最大的即为MMD,一般写作:
基于统计学,当MMD的值非常接近0时,可以认为两个域之间的分布近似相等(即打成域对齐的目标)
2.分类
①Marginal dist
这种方法是用MMD衡量两个域之间分布的差异,原公式
经过一定的计算可以写作:
,式中
,其核形式可以记作:
,其中

该方法通常被称为:TCA(Transfer Component Analysis)-迁移成分分析

从上图可以看到,两个域经过PCA(主成分分析)后分布并不相等,但是讲过TCA处理后分布趋于一致。
②conditional dist
该方式的公式可以写作:
化简后可以得:,可以看出和上面的TCA公式结构相似,区别在于式中的
代表类别,相当于将TCA加入类别中。

通过变换,可以得到一种叫JDA(Joint Distribution Adaptation)的方法,写作:
JDA相较于TCA而言,拥有更好的性能和更短的分布距离。同时由于JDA能进行迭代,可以更好的学习分布间的差异。

③dynamic dist
这种方法可以缩写为DDA,其相当于将TCA和JDA使用一个通用公式写出,可以写作:

当时,式子可以写作:
,即为TCA
当时,式子可以写作:
,即为JDA
该方法的难点在于如何评价参数,一般在用A-distance的估计方法。具体做法可以写作:
;其中
为线性分类器,
为
的错误
然后可以用上式来估计;其中
是边缘分布,
是条件分布。
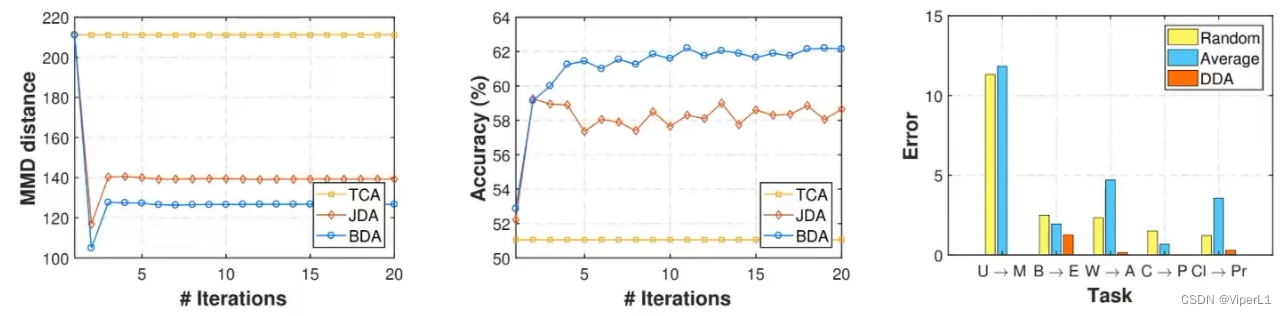
3.MMD在深度学习中的应用
上述的TCA、JDA、DDA均可采用Deep domain confusion(DDC)或Dynamic distribution adaptation network(DDAN)的方法加入神经网络,改进后的网络结构如下:
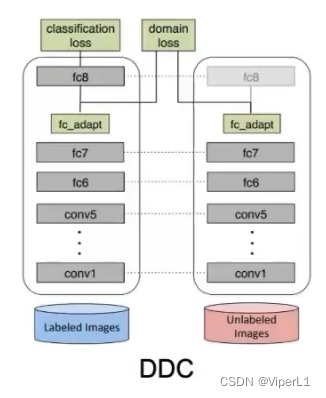

网络的损失函数为:;式中的Distance可以是TCA、JDA、DDA。可以通过随机梯度下降进行学习。是一种端到端的学习方式。
五、迁移学习的热门方向
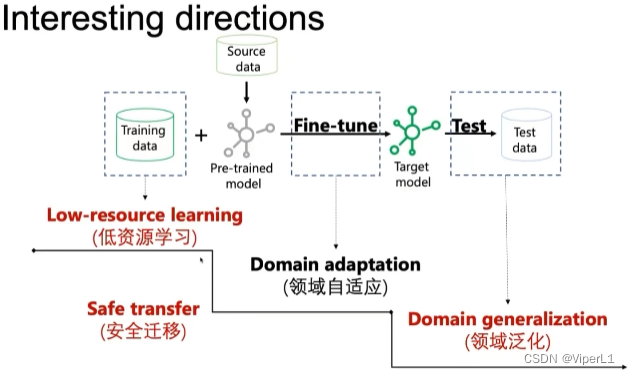
1.Low-resource learing:在仅有少量标签数据的情况下进行训练。即自训练。
2.Safe transfer:防止继承公开模型的漏洞而被针对性攻击
3.Domain adaptation:域自适应
4.Domain generalization:域泛化