Graph Machine Learning Explainability with PyG
- 框架总览
- 示例:解释器
- The Explanation Class
- The Explainer Class and Explanation Settings
- Explanation评估
- 基准数据集
- Explainability Visualisation
- 实现自己的ExplainerAlgorithm
- 对于异质图的扩展
- 解释链路预测
- 总结
- 参考文献
图神经网络(Graph Neural Networks,简称GNNs)在处理图结构数据(例如社交网络、分子图和知识图谱)方面越来越受欢迎。然而,基于图的数据的复杂性以及图中节点之间的非线性关系可能会导致理解GNN为何作出特定预测变得困难。随着图神经网络的普及,对解释其预测的兴趣也越来越大。
在实际机器学习应用中,解释的重要性不可低估。解释帮助建立模型的信任和透明度,用户可以更好地理解预测是如何生成以及影响预测的因素。它们提高决策制定的质量,决策者可以更好地理解模型预测的基础上做出更明智的决策。解释还使从业者更容易调试和改进他们开发的模型的性能。在某些领域,如金融和医疗保健,由于合规性和法规要求,解释甚至可能是必需的。
在图机器学习中,解释仍然是一项持续的研究工作,图上的可解释性不如计算机视觉或自然语言处理等其他子领域的解释成熟。此外,由于GNN在复杂的关系数据上操作,解释本身也有所不同:
- 上下文理解(Contextual Understanding):解释需要对图中节点之间的关系和实体进行上下文理解,这可能很复杂,也很难理解;
- 动态关系(Dynamic relationships):图中节点之间的关系可能会随着时间的推移而变化,因此很难为不同时间点的预测提供解释;
- 异质数据(Heterogeneous Data):GML通常涉及处理具有复杂特征的异构数据类型,这使得很难提供统一的解释方法;
- 解释粒度(Explanation granularity):解释必须解释预测的结构起源,以及特征的重要性。这意味着解释哪些节点、边或子图是重要的,以及哪些节点或边特征对预测结果有很大贡献。
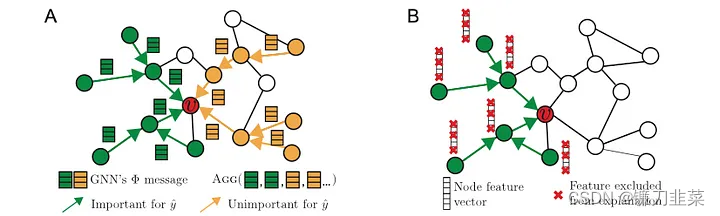
图1 图机器学习中解释的复杂性。左手边显示了用于在节点
v
v
v进行预测的GNN计算图。计算图中的一些边是重要的神经消息传递路径(绿色),而其他边则不是(橙色)。然而,GNN需要聚合重要和不重要的特征来进行预测,而解释方法的目标是识别一小部分对预测至关重要的重要特征和途径。
除了图形机器学习的困难和复杂性,最近在该领域有很多统一的工作,该作品均旨在为评估解释[1,2]提供统一的框架[1,2],并提供了现有解释动物园的分类法可用的方法[3]。
在最近的社区快速迭代中,PyG社区实现了一个核心的可解释性框架,同时提供了各种评估方法、基准数据集和可视化工具,使得在PyG中开始使用图机器学习解释变得非常简单。此外,该框架既适用于想要直接使用常见图解释器(如GNNExplainer [4]或PGExplainer [5]),也适用于想要实现、测试和评估自己的解释方法的用户。
在本博客文章中,我们将逐步介绍可解释性模块,详细说明框架的每个组件如何工作以及其作用。随后,我们将介绍各种解释评估方法和合成基准数据集,这些方法与数据集相辅相成,确保您为当前任务生成最佳的解释结果。接下来,我们将介绍一些可立即使用的可视化方法。最后,我们将详细介绍在PyG中实现自己的解释方法所需的步骤,并强调异构图和链接预测解释等高级用例的工作。
框架总览
在设计解释性框架时,PyG的目标是设计一个易于使用的解释性模块,该模块:
- 可以扩展以满足许多GNN应用的要求
- 可以适应各种类型的图和解释设定
- 可以提供解释输出,以全面评估和可视化
框架有四个核心概念:
- 解释器(Explainer)类:一个用于实例级解释的PyG可解释性模块的包装器;
- 解释(Explanation)类:封装解释程序输出的类
- 解释器算法(ExplainerAlgorithm)类:解释器使用的解释性算法在给定训练实例的情况下生成解释
- 度量(metric)包:使用解释(Explanation)输出以及GNN模型 /ground truth的评估指标来评估解释性
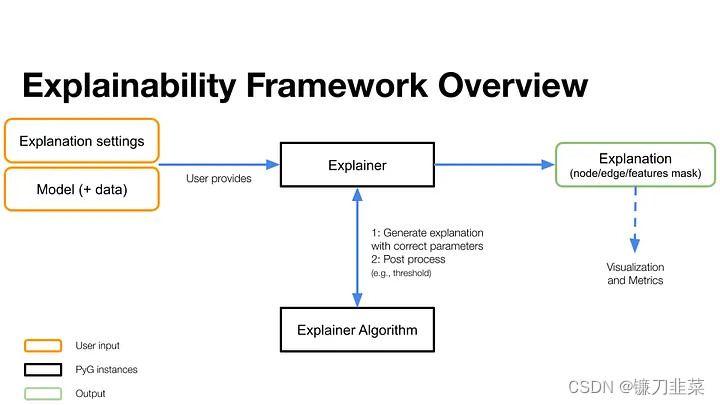
图2 PyG可解释框架总览。用户提供explanation settings,以及需要解释的模型和数据。Explainer类是一个PyG实例,封装了一个解释器算法,即特定的解释方法,用于为给定的模型和数据生成解释。解释结果被封装在Explanation类中,可以进行进一步的post-processed、可视化和评估。
现在让我们更深入地了解可用的各种解释设置。
示例:解释器
这里是一个示例Explainer设置,它使用GNNEexplainer对Cora数据集进行模型解释(请参见gnn_Explainer.py示例)。
explainer = Explainer(
model=model,
algorithm=GNNExplainer(epochs=200),
explanation_type='model',
node_mask_type='attributes',
edge_mask_type='object',
model_config=dict(
mode='multiclass_classification',
task_level='node',
return_type='log_probs',
),
)
为所有属性设置节点级别掩码,为边设置边作为对象。为了对模型的一个特定预测给出一个解释,我们简单地称之为解释者(explainer):
node_index = 10 # which node index to explain
explanation = explainer(data.x, data.edge_index, index=node_index)
现在让我们来看看所有的螺母和螺栓,它们使PyG中的解释变得如此简单!
The Explanation Class
使用Explanation类来表示解释,该类是一个Data或HeteroData对象,其中包含节点、边、特征和数据的任何属性的掩码。在这个范例中,掩码作为相应节点/边/特征的解释归因。掩码的值越大,相应组件对解释的重要性就越高(0表示完全不重要)。Explanation类包含获取诱导解释子图的方法,该子图由所有非零解释归因组成,以及解释子图的补集。此外,它还包括用于解释的阈值化和可视化方法。
The Explainer Class and Explanation Settings
Explainer类被设计为处理所有的可解释性settings,这些settings可以作为Explainer的直接参数或者在ModelConfig或ThresholdConfig的配置中设置。这个新接口提供了许多设置选项。
# Explainer Parameters
model: torch.nn.Module,
algorithm: ExplainerAlgorithm,
explanation_type: Union[ExplanationType, str],
model_config: Union[ModelConfig, Dict[str, Any]],
node_mask_type: Optional[Union[MaskType, str]] = None,
edge_mask_type: Optional[Union[MaskType, str]] = None,
threshold_config: Optional[ThresholdConfig] = None,
model可以是我们用来生成解释的任何PyG模型。额外的模型设置在ModelConfig中指定,该设置指定了模式(mode)、任务级别(task_level)和模型的返回类型(return_type)。模式描述了任务类型,例如mode=multiclass-classification;任务级别表示任务级别(节点级、边级或图级任务);返回类型描述了模型的预期返回类型(原始值raws、概率probs或对数概率log_probs)。
说明有两种类型的解释,如explanation_type所示(有关更深入的讨论,请参见[1]):
explanation_type='phenomenon'旨在解释为什么要对特定的输入做出特定的决定。我们对数据中从输入到输出的现象感兴趣。在这种情况下,标签被用作解释的目标。explanation_type='model'旨在为所提供的模型提供事后解释。在这种设置中,我们试图打开黑盒并解释其背后的逻辑。在这种情况下,模型预测被用作解释的目标。
Explanation的精确计算方式由algorithm参数指定,模块中有几个现成的:
- GNNExplainer:GNN-Explainer模型来自 “GNNExplainer: Generating Explanations for Graph Neural Networks”论文。
- PGExplainer:PGExplainer模型来自“Parameterized Explainer for Graph Neural Network” 论文
- AttentionExplainer:使用基于注意力的GNN(例如,GATConv、GATv2Conv或TransformerConv)产生的注意力系数作为边解释的解释器
- CaptumExplainer:基于Captum的解释器
- GraphMaskExplainer:GraphMask-Explainer来自”Interpreting Graph Neural Networks for NLP With Differentiable Edge Masking“论文(
torch_geometry.contrib的一部分) - PGMExplainer:PGMExplainer模型来自”PGMExplainer: Probabilistic Graphical Model Explanations for Graph Neural Networks“论文(
torch_geometry.contrib的一部分)
我们还支持许多不同类型的掩码,这些掩码设置为node_mask_type和edge_mask_type,可以是:
None没有任何节点/边执行掩码- ”object“将会对每个节点/边执行掩码
- ”common_attributes“将会掩码每个节点特征/边属性
- ”attributes“将在所有节点/边上分别屏蔽每个节点特征/边属性
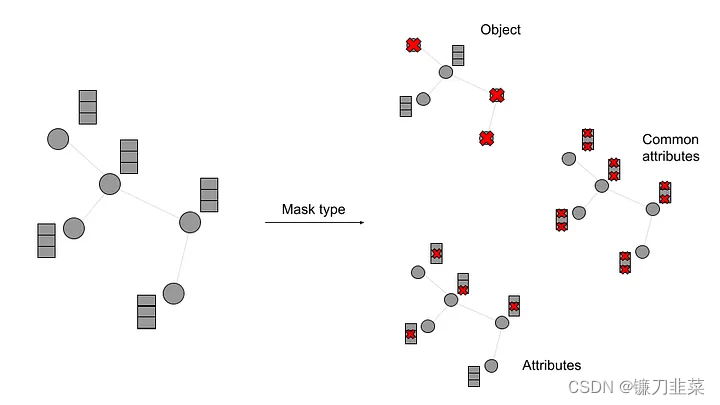
图3 Explainer类中提供的不同节点掩码类型
最后,还可以通过ThresholdConfig设置阈值行为。如果不想对解释掩码进行阈值处理,可以将其设置为None;或者,可以在任意值上应用hard阈值;或者,可以仅保留top-k个值(使用topk选项),或者将top-k个值设为1(使用topk_hard选项)。
Explanation评估
生成解释绝不是可解释性工作流程的终点。解释的质量可以通过多种不同的方法进行评估。PyG支持一些开箱即用的解释评估指标,可以在metric包中找到它们。
也许最流行的评估指标是Fidelity+/-(详见1)。Fidelity评估产生的解释子图对初始预测的贡献,可以通过仅将子图提供给模型(fidelity-)或从整个图中移除子图(fidelity+)来进行评估。
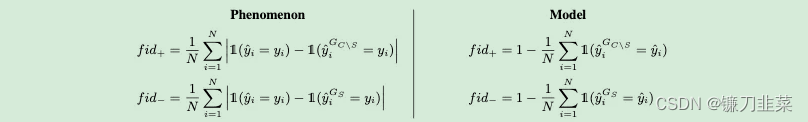
Fidelity +/-现象和模型模式的定义(source [1])
保真度分数(Fidelity scores)表明了可解释模型再现自然现象或GNN模型逻辑的程度。一旦给出了一个解释,就可以获得以下两种信心:
from torch_geometric.explain.metric import fidelity
fid_pm = fidelity(explainer, explanation)
PyG提供表征分数(characterization score)作为将两个Fidelity指标结合为单一度量的手段[1]。此外,如果对许多不同阈值(或熵)的解释都有Fidelity对,可以使用Fidelity曲线下面积(Fidelity curve auc)计算Fidelity曲线下面积。此外,还提供了不忠实(unfaithfulness)度量指标,用于评估解释对底层GNN预测器的忠实程度[6]。
在没有可用的“真实解释”时,诸如忠实度分数和不忠实度量等指标对于评估解释非常有用。即没有一个预先确定的节点/特征/边集合来完全解释特定的模型预测或现象。特别是在开发新的解释算法时,我们可能对在某些标准基准数据集上的性能感兴趣[1,2]。groundtruth_metrics方法比较解释掩码并返回标准度量的选择(”accuracy“,”recall“,”precision“,”f1_score“,”auroc“):
from torch_geometric.explain.metric import groundtruth_metrics
accuracy, auroc = groundtruth_metrics(pred_mask,
target_mask,
metrics=["accuracy", "auroc"])
当然,以这种方式评估解释器首先需要有ground truth解释的基准数据集。
基准数据集
为了促进新的图解释算法的开发和严格评估,PyG现在提供了几个解释器数据集,例如BA2MotifDataset、BAMultiShapesDataset和InfectionDataset,以及一种创建合成基准数据集的简便方法。通过ExplainerDataset类提供支持,该类通过GraphGenerator创建合成图,并随机附加num_motifs个来自MotifGenerator的模式。基于节点和边是否属于特定模式,给出了节点级和边级的解释能力掩码,作为ground-truth。
当前支持的GraphGenerator有:
BAGraph:随机Barabasi-Albert(BA)图ERGraph:随机Erdos-Renyi(ER)图GridGraph:二维网格图
但是也可以自定义,通过创建GraphGenerator的子类。除此之外,对于motifs,支持:
HouseMotif:[4]中的House structured motifCycleMotif:[4]中的cycle motifCustomMotif:基于自定义结构从Data对象或networkx.Graph对象添加任何motif的简单方法(例如一个轮子形状)
可以使用上述设置生成的数据集是GNNExplainer[4]、PGExplainer[5]、SubgraphX[8]、PGMExplainer[9]、GraphFramEx[1]等中使用的一类基准数据集的超类(super-class)。
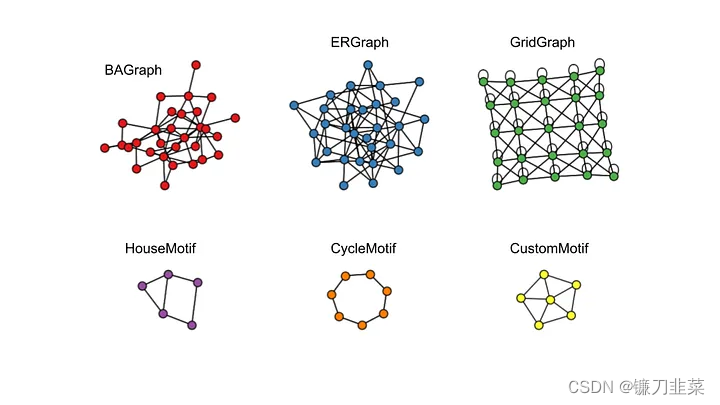
图4 随机图生成器和motif生成器。可以动态生成具有所需种子和大小的新数据集。例如,为了生成基于Barabasi-Albert图的数据集,其中80个house motifs用作ground truth解释标签,我们将使用:
from torch_geometric.datasets import ExplainerDataset
from torch_geometric.datasets.graph_generator import BAGraph
dataset = ExplainerDataset(
graph_generator=BAGraph(num_nodes=300, num_edges=5),
motif_generator='house',
num_motifs=80,
)
BAMultiShapesDataset是用于评估图分类可解释性算法的合成数据集[10]。给定三个原子模式,即House(H)、Wheel(W)和Grid(G),BAMultiShapesDataset包含1,000个Barabasi-Albert图,其标签取决于原子模式的附加方式,如下所示:
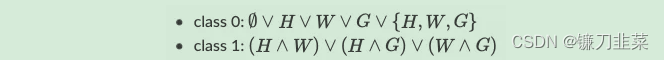
数据集是预先计算的,以便与官方实现相一致。
另一个预先计算的数据集是BA2MotifDataset[5]。它包含1,000个Barabasi-Albert图。一半的图附有HouseMotif,剩下的图附有五节点的CycleMotif。根据附加模式的类型,将图分配给两个类别之一。要创建类似的数据集,可以使用带有图和模式生成器的ExplainerDataset。
此外,PyG还提供了InfectionDataset [2]生成器,其中节点预测它们与infected节点(黄色节点)的距离,并使用到infected节点的唯一路径作为解释。非唯一路径到infected节点的节点被排除在外。不可达节点和距离至少为max_path_length的节点被合并为一个类别。
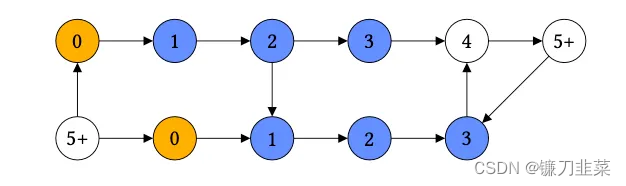
图5 来自[2]的infection dataset
为了生成infection dataset,指定了一个图生成器、感染路径长度和感染节点的数量:
# Generate Barabási-Albert base graph
graph_generator = BAGraph(num_nodes=300, num_edges=500)
# Create the InfectionDataset to the generated base graph
dataset = InfectionDataset(
graph_generator=graph_generator,
num_infected_nodes=50,
max_path_length=3
)
PyG的目标是在未来添加更多的解释数据集和图形生成器。
Explainability Visualisation
如前所述,Explanation类提供了基本的可视化功能,包括两个方法visualize_feature_importance()和visualize_graph()。
对于可视化特性,我们可以指定使用top_k绘制top特性的数量,或者使用feat_labels传递feature labels。
explanation.visualize_feature_importance(feature_importance.png, top_k=10)
输出被存储到指定的路径,这里是上面Cora数据集解释器的输出示例:
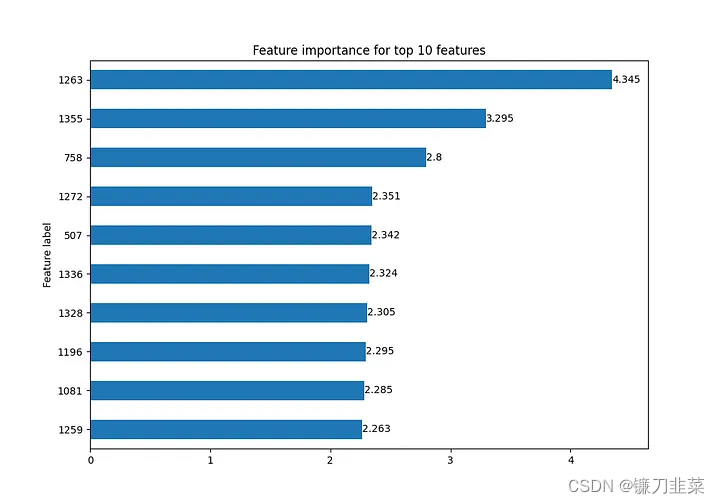
图6 Cora上的特征重要性,有关详细信息,请参见gnn_explainer.py示例
还可以很容易地看到explanation引起的图形。visualize_graph()的输出是explanation subgraph的可视化,根据其重要性值(如果需要,通过配置的阈值)过滤出来后。我们可以选择两个backends (graphviz或networkx):
explanation.visualize_graph('subgraph.png', backend="graphviz")
我们得到了有助于解释的节点和边的局部图,边的不透明度对应于边的重要性。
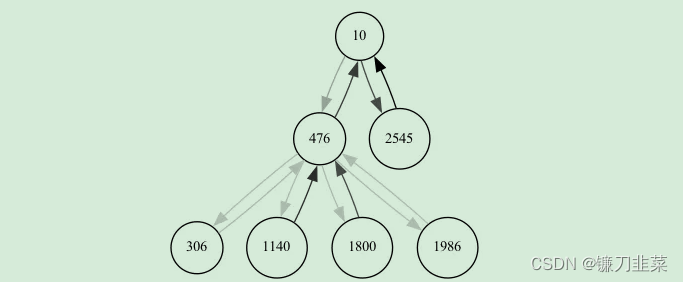
图7 由gnn_explainer.py示例的解释引起的子图
实现自己的ExplainerAlgorithm
所有的解释计算工作都发生在传递给Explainer类的ExplainerAlgorithm中。已经实现了许多流行的解释算法(如GNNExplainer、PGExplainer等),可以直接使用。然而,如果发现需要一个未实现的ExplainerAlgorithm,只需子类化ExplainerAlgorithm接口并实现两个必要的抽象方法即可。
forward方法计算解释,它具有以下signature:
def forward(
self,
# the model used for explanations
model: torch.nn.Module,
# the input node features
x: Union[torch.Tensor, Dict[NodeType, torch.Tensor]],
# the input edge indices
edge_index: Union[torch.Tensor, Dict[NodeType, torch.Tensor]],
# the target of the model (what we are explaining)
target: torch.tensor,
# The index of the model output to explain.
# Can be a single index or a tensor of indices.
index: Union[int, Tensor], optional,
# Additional keyword arguments passed to the model
**kwargs: optional,
) -> Union[Explanation, HeteroExplanation]
为了帮助为不同的解释算法构建forward()方法,基类ExplainerAlgorithm提供了几个有用的辅助函数,如_post_process_mask,用于后处理任何掩码,以不包括消息传递过程中未涉及的元素的任何属性,_get_hard_masks返回仅包括在消息传递期间访问的节点和边的硬节点和边掩码、用于获取模型聚合信息的跳数的_num_hops等。
第二个需要实现的方法是supports()方法:
supports(self) -> bool
supports()函数检查解释器是否支持self.conplainer_configand和self.model_config中提供的用户定义的设置,它检查说明算法是否为使用的特定说明设置定义了。
对于异质图的扩展
如上所述,解释(Explanation)可以简单地扩展到异质图和HeteroData。在这种情况下,解释也是一个掩码,但应用于所有节点和边特征(具有不同类型)。为此,PyG实现了HeteroExplanation类,其接口与Explanation几乎完全相同。
此外,为了促进未来在这个方向上的工作,PyG还将异构图支持添加到了CaptumExplainer中,它可以作为未来实现的模板。此外,大部分可解释性框架已经在这个方向上具备了未来的兼容性,其中许多参数被设置为适用于异构情况的可选字典。

解释链路预测
对于那些希望为链接预测提供解释的用户,PyG已经添加了GNNExplainer链接解释支持。这个想法是将边的解释视为一种新的目标索引方法,通过索引到边张量而不是节点特征张量。链接预测解释考虑了两个端点的k-跳邻域的并集。
这个实现与现有代码很好地集成在一起,支持大多数解释配置。一个用于解释链接预测的示例设置如下所示:
model_config = ModelConfig(
mode='binary_classification',
task_level='edge',
return_type='raw',
)
# Explain model output for a single edge:
edge_label_index = val_data.edge_label_index[:, 0]
explainer = Explainer(
model=model,
explanation_type='model',
algorithm=GNNExplainer(epochs=200),
node_mask_type='attributes',
edge_mask_type='object',
model_config=model_config,
)
explanation = explainer(
x=train_data.x,
edge_index=train_data.edge_index,
edge_label_index=edge_label_index,
)
print(f'Generated model explanations in {explanation.available_explanations}')
要查看完整的示例,请查看gnn_explainer_link_pred.py。为了更容易开始实现任何任务级别的解释方法,PyG还提供了对所有任务级别(图形、节点、边)进行参数化测试的示例。有兴趣的读者可以查看test/explain。
总结
这是对PyG中可解释性的快速介绍。目前,PyG中的许多令人兴奋的事情正在进行中,无论是在图解释方面,还是其他图机器学习领域。如果您想加入开源开发者社区,请访问PyG的Slack和GitHub页面!
参考文献
[1] Amara, K., Ying, R., Zhang, Z., Han, Z., Shan, Y., Brandes, U., Schemm, S. and Zhang, C., 2022. GraphFramEx: Towards Systematic Evaluation of Explainability Methods for Graph Neural Networks. arXiv preprint arXiv:2206.09677.
[2] Faber, L., K. Moghaddam, A. and Wattenhofer, R., 2021, August. When comparing to ground truth is wrong: On evaluating gnn explanation methods. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining (pp. 332–341).
[3] Yuan, H., Yu, H., Gui, S. and Ji, S., 2022. Explainability in graph neural networks: A taxonomic survey. IEEE Transactions on Pattern Analysis and Machine Intelligence.
[4] Ying, Z., Bourgeois, D., You, J., Zitnik, M. and Leskovec, J., 2019. Gnnexplainer: Generating explanations for graph neural networks. Advances in neural information processing systems, 32.
[5] Luo, D., Cheng, W., Xu, D., Yu, W., Zong, B., Chen, H. and Zhang, X., 2020. Parameterized explainer for graph neural network. Advances in neural information processing systems, 33, pp.19620–19631.
[6] Agarwal, C., Queen, O., Lakkaraju, H. and Zitnik, M., 2022. Evaluating explainability for graph neural networks. arXiv preprint arXiv:2208.09339.
[7] Baldassarre, F. and Azizpour, H., 2019. Explainability techniques for graph convolutional networks. arXiv preprint arXiv:1905.13686.
[8] Yuan, H., Yu, H., Wang, J., Li, K. and Ji, S., 2021, July. On explainability of graph neural networks via subgraph explorations. In International Conference on Machine Learning(pp. 12241–12252). PMLR.
[9] Vu, M. and Thai, M.T., 2020. Pgm-explainer: Probabilistic graphical model explanations for graph neural networks. Advances in neural information processing systems, 33, pp.12225–12235.
[10] Azzolin, S., Longa, A., Barbiero, P., Liò, P. and Passerini, A., 2022. Global explainability of gnns via logic combination of learned concepts. arXiv preprint arXiv:2210.07147.