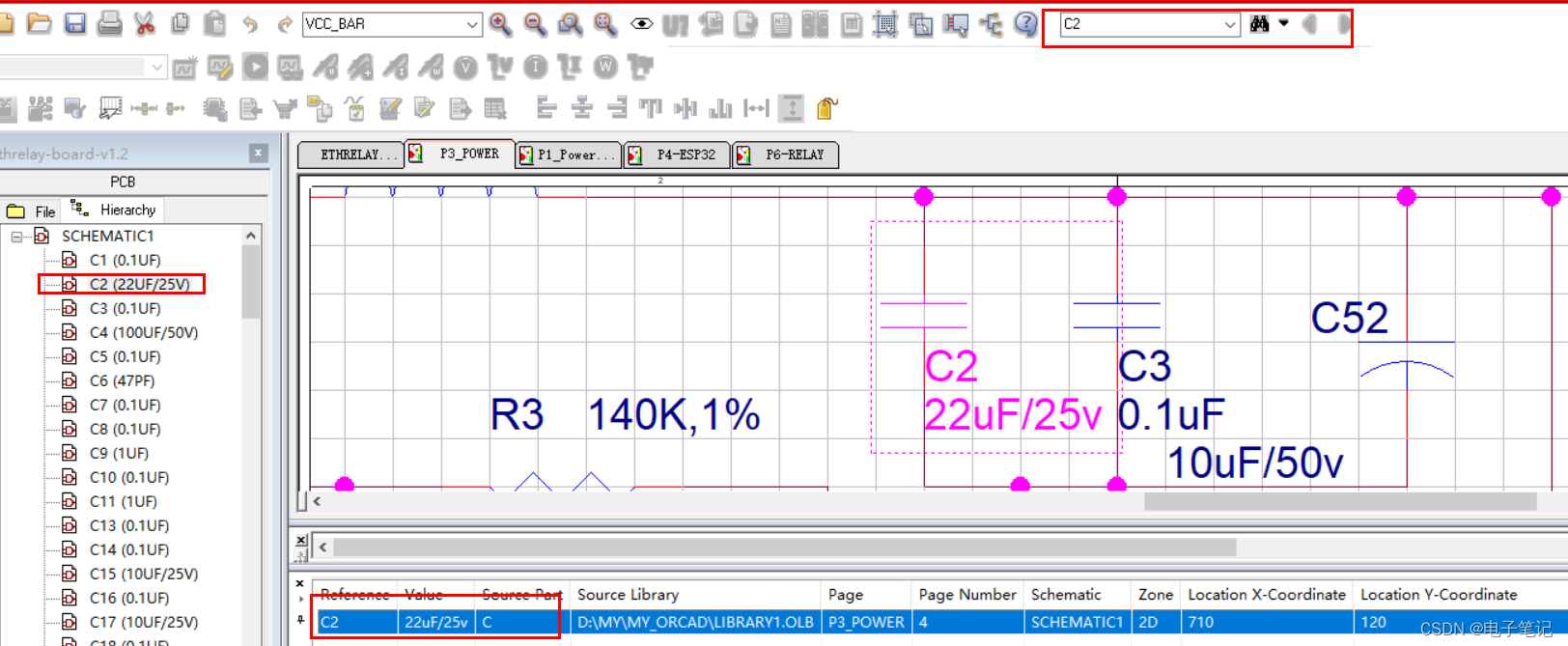
如果分类问题具有预测这样带有自然顺序的问题,如{婴⼉, ⼉童, ⻘少年, ⻘年⼈, 中年⼈, ⽼年⼈},那么可以把分类问题转变为回归问题了。不过可以使用独热编码one-hot encoding。
类别对应的分量设置为1,其他所有分量设置为0。在我们的例⼦中,标签y将是⼀个三维向量,其中(1, 0, 0)对应于 “猫”、(0, 1, 0)对应于“鸡”、(0, 0, 1)对应于“狗”: y ∈ {(1, 0, 0),(0, 1, 0),(0, 0, 1)}.
因为分类时,全连接层的输出时存在⼀些问题:⼀⽅⾯,我们没有限制这些输出数字的总和为1。另⼀⽅⾯,根据输⼊的不同,它们可以为负值。这些违反了的概率基本公理。

对“预测求幂”的解释:指数运算等于求幂运算。这里是底数e的oj次幂。
“尽管softmax是⼀个⾮线性函数,但softmax回归的输出仍然由输⼊特征的仿射变换决定。因此,softmax回归是⼀个线性模型(linear model)。”解释:因为模型的非线性表现主要来自于其激活函数,而不是从输入到输出的变换过程。简而言之,在回归模型中,我们使用了一个非线性函数来处理线性模型的输出,以得到更好的结果。

需要指出的是,softmax 回归模型之所以被称为线性模型,是因为它对每个类别的判别都是线性的。
广播机制(broadcasting)是一种在不同形状的张量之间进行计算的方式,它使用了一些规则来确定如何将这些张量扩展到相同的形状,从而进行计算。
交叉熵损失函数的公式为: l(y, yˆ) = − ∑j yj log yˆj,该损失函数是分类问题最常用的损失之一
交叉熵损失函数的公式中,y表示真实标签,而yˆ表示模型预测的概率分布。因此,当模型的预测接近真实标签时,即y和yˆ的差异越小,交叉熵损失函数的值就会越小。
具体来说,如果模型的预测结果越接近真实标签,也就是y和yˆ的差异越小,那么在计算交叉熵损失函数时,log yˆj的取值就会越大(因为yˆj的取值范围在0到1之间,log函数的取值范围为负无穷到0,yˆj是预测的概率),从而导致l(y, yˆ)的值变小。反之,如果模型的预测结果与真实标签差距较大,那么log yˆj的取值就会越小,从而导致l(y, yˆ)的值变大。因此,当模型的预测结果更准确时,交叉熵损失函数的值就会变小。
log_e(2) 表示 1 纳特的原因是,纳特是以自然对数 e 为底的单位,它用于度量信息熵。信息熵是一个随机变量不确定性的度量,也可以理解为对信源进行编码所需的最短平均码长。如果我们使用以 2 为底的对数,则单位就成了比特(bit),即log_2(2)。对于一个概率分布 P,它的信息熵 H(P) 定义为:
H(P) = - Σ p(x) log_e(p(x))
其中,x 是随机变量取值,p(x) 是 x 发生的概率。在这个式子中,log_e 表示以自然对数 e 为底的对数,因此单位是纳特(nat)。具体而言,log_2(p(x)) 表示对信源进行二进制编码时,第 x 种符号需要的码长(通常会向上取整)。
另一方面,log_2(2) 可以表示一比特,因为比特是信息的最小单位,可以是 0 或 1。在一个只有两种可能输出的系统(例如,一个二进制系统)中,一个单一的比特可以有两种不同的状态,即 0 或 1。因此,我们需要使用以 2 为底的对数来度量比特数,而一个单独的比特可以被表示为 log_2(2)。
总之,log_e(2) 表示 1 纳特,因为它在信息熵的定义中扮演了重要角色。而 log_2(2) 表示一比特,因为它用于度量信息的最小单位。
接着解释下1 nat = 1/loge(2) bit ≈ 1.44 bi这个式子的由来:
换底公式:log_a(c) = log_b(c) / log_b(a)
在这个问题中,我们需要将以 2 为底的比特数转换为以 e 为底的纳特数,因此我们使用自然对数 e 作为新的底数,并应用上述公式。
具体地,我们可以将 1 比特表示为以 2 为底的对数(即 log_2(2)),并应用换底公式,得到:
log_e(2) = log_2(2) / log_2(e)
由于 log_2(2) 等于 1,而 log_2(e) 约等于 1.44,因此我们可以将上式简化为:
log_e(2) ≈ 1 / 1.44
从而得到:
1 nat = 1/log_e(2) bit ≈ 1.44 bit