编者按:要理解一种新的机器学习架构(以及其他任何新技术),最有效的方法就是从头开始实现它。然而,还有一种更简单的方法——计算参数数量。
通过计算参数数量,读者可以更好地理解模型架构,并检查其解决方案中是否存在未被发现的错误。
该文章提供了精确的Transformers模型的参数量计算公式和不太准确的简略公式版本,使读者能够快速估算基于Transformer的任何模型中参数的数量。
以下是译文,Enjoy!
作者 | Dmytro Nikolaiev (Dimid)
编译 | 岳扬
要理解一种新的机器学习架构(以及其他任何新技术),最有效的方法就是从头开始实现它。 虽然这可能会非常复杂、耗时,并且有时几乎不可能实现,但这是帮助我们理解每个技术细节的最佳方法。例如,如果没有类似的计算资源或数据,我们将无法确保我们的解决方案中没有未被发现的错误。
然而,还有一种更简单的方法——计算参数数量。 这比仅仅阅读论文要困难得多,但可以让我们深入挖掘并检查是否完全理解了新架构的构件(在本文的例子是Transformer的编码器(Encoder)和解码器(Decoder)构件)。
我们可以通过下面这幅图表来思考这个问题,这张图表展示了三种理解新ML架构的方法——圆圈的大小表示对该架构的理解程度。

本文主要研究著名的Transformer架构,并考虑如何计算PyTorch TransformerEncoderLayer[1]和TransformerDecoderLayer[2]类中的参数数量。因此,我们需要确保对于该架构由哪些部分组成不再充满神秘感。
TLDR(总结)
(该文篇幅比较长,如果不想深入探讨或时间有限,可以直接看总结部分)
您可以阅读“结论 Conclusions”部分,所有参数量计算公式都总结在“结论 Conclusions”部分。
本文不仅提供精确的参数量计算公式,还能够提供不太准确的公式近似版本,将使您能够快速估算基于Transformer的任何模型中参数的数量。
01 Transformer架构
著名的Transformer架构于2017年在《Attention Is All You Need[3]》这篇论文中提出,并因其具有能够有效捕捉长距离的依赖关系(long-range dependencies)的能力而成为自然语言处理和计算机视觉任务中的标准架构。
早在2023年初,扩散模型(Diffusion)[4]由于文转图生成模型[5]的大火而变得极其流行。也许,很快扩散模型将成为各种任务的最先进技术,就像Transformer与LSTM和CNN一样。但我们先来看看Transformer……
本文并不试图去解释Transformer架构,因为已经有很多足够好的文章做到了这一点。这篇文章只是让我们能够从不同的角度去看待它,或者讲解一些细节问题。所以如果你正在寻找更多有关此架构的学习资源,我可以向你推荐一些;否则,您可以继续阅读下去。
1.1 了解更多Transformer的资源
如果你正在寻找更加详细的Transformer架构概述,可以阅读以下材料(请注意,互联网上有很多技术内容,我只是个人喜欢这些):
- 首先,可以阅读官方论文[3]。第一次接触Transformer就阅读论文可能不是最佳方式,但这并不像看起来那么复杂。可以尝试使用Explainpaper来帮助您阅读此论文[6]或其他论文(这是一种基于AI的工具,可以解释用鼠标标记的文本)。
- Jay Alammar的“Great Illustrated Transformer[7]”。如果您不喜欢阅读文章,可以观看同一作者的YouTube视频[8]。
- Lukasz Kaiser在Google Brain的 “Awesome Tensor2Tensor” 讲座[9]。
- 如果想直接进行实操并使用各种Transformer模型构建应用程序,请查看Hugging Face课程[10]。
1.2 Original Transformer
首先,让我们回顾一下Transformer的基础知识。
Transformer的架构由两个组件组成:编码器(在左边)和解码器(在右边)。编码器接受输入token序列并生成隐藏状态序列(sequence of hidden states),而解码器则接受这个隐藏状态序列并生成输出token序列。
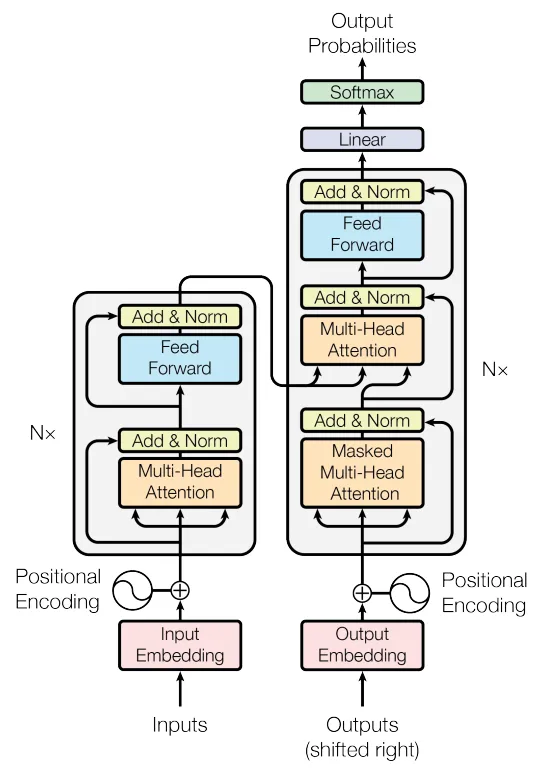
Transformer 架构图,来自https://arxiv.org/pdf/1706.03762.pdf
编码器和解码器都由一堆相同的层组成。对于编码器,该层包括多头注意力(multi-head attention)(1——此处及下文中的数字指的是下面的图片中标序号的部分)和一个带有一些层归一化(3)和跳跃连接(skip connections)的前馈神经网络(feed-forward neural network)(2)。
解码器也类似于编码器,但除了第一个多头注意力(4)(在机器翻译任务中被屏蔽,所以解码器不会通过查看未来的tokens进行舞弊)和一个前缀网络(5)之外,它还具有第二个多头注意力机制(6)。它允许解码器在生成输出时使用编码器提供的上下文(context)。与编码器一样,解码器也有一些层归一化(layer normalization)(7)和跳跃连接组件。
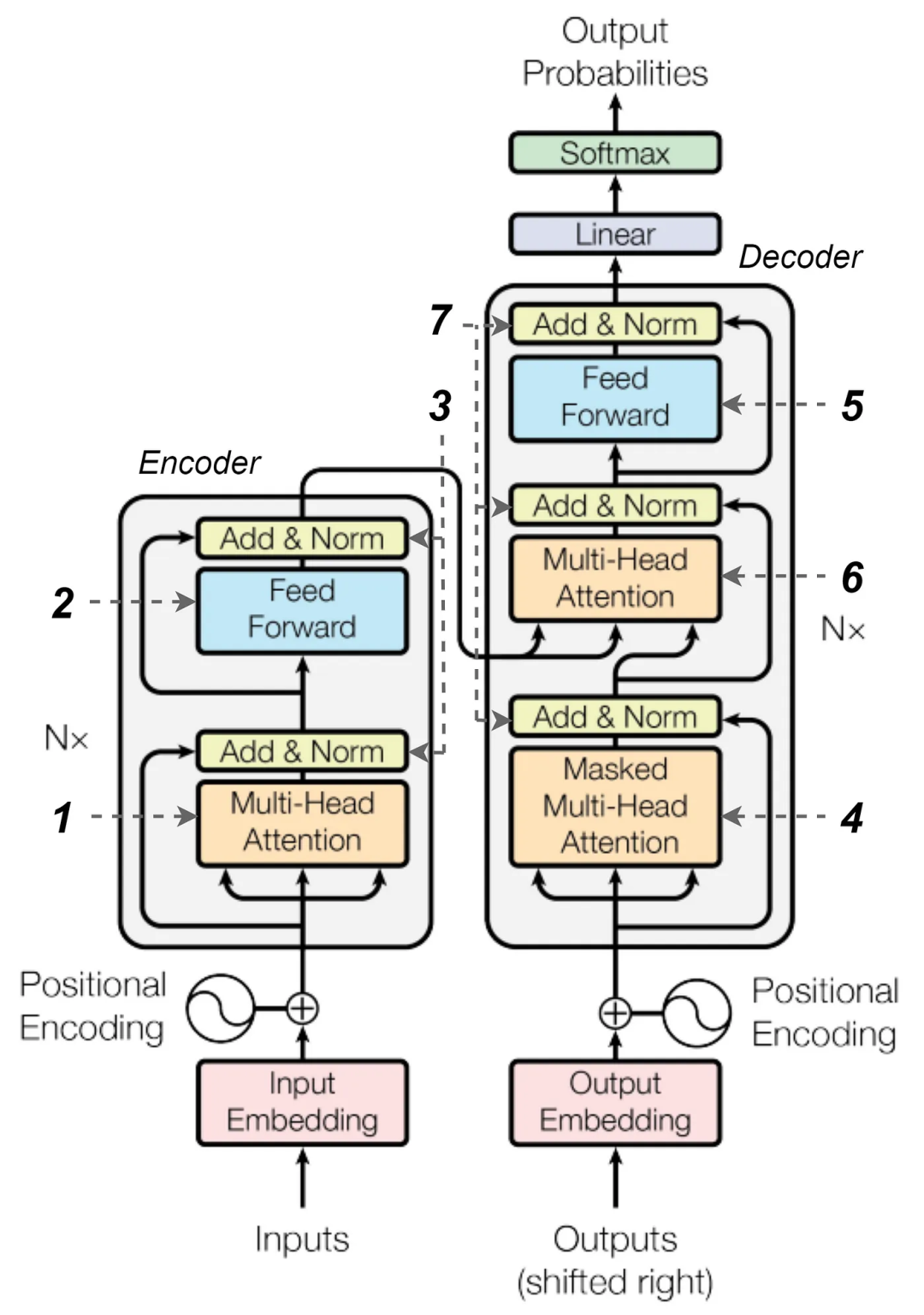
带有序号标记组件的Transformer架构图
来自https://arxiv.org/pdf/1706.03762.pdf
我不会将输入嵌入层(带有位置编码)和最终输出层(linear+softmax)视为Transformer组件,而只关注编码器和解码器块。这样做是因为这些组件是适用于某些特定任务和嵌入方法的,而编码器和解码器栈是其他体系结构的基础。
这种架构的例子包括用于编码器的基于BERT的模型(BERT、RoBERTa、ALBERT、DeBERTa等),用于解码器的基于GPT的模型(GPT、GPT-2、GPT-3、ChatGPT),以及构建在完整的编码器-解码器框架上的模型(T5、BART等)。
尽管我们在该架构中标记了七个组件,但我们可以看到,其中仅有三个独特的组件:
- 多头注意力(Multi-head attention);
- 前馈网络(Feed-forward network);
- 层的归一化(Layer normalization)。
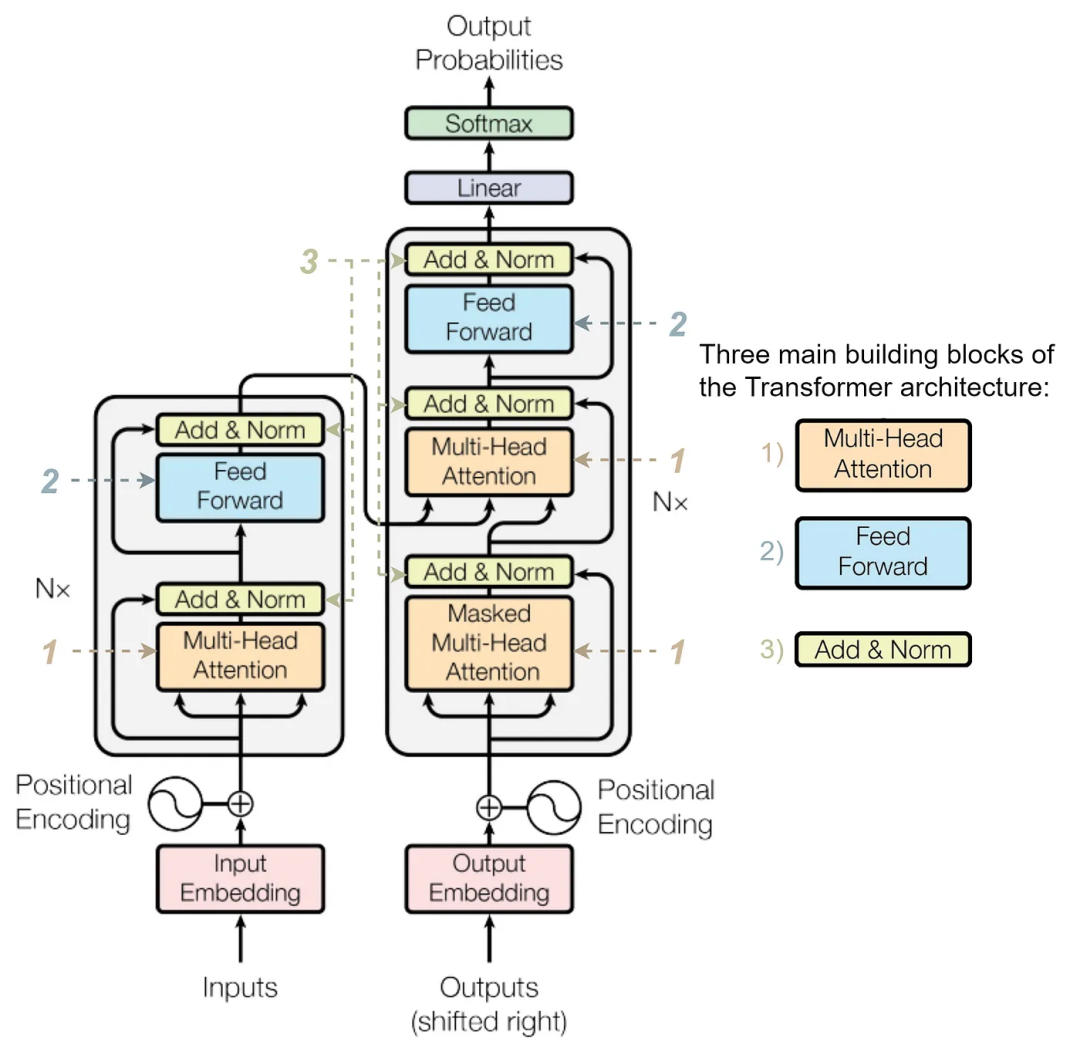
Transformer构件 来自论文https://arxiv.org/pdf/1706.03762.pdf
02 Transformer构件块
让我们考虑一下每个模块的内部结构以及它需要多少参数。在本节中,我们还将开始使用PyTorch[11]来验证我们的计算结果。
为了检查某个模型块的参数数量,我将使用以下这行函数[12]:
import torch
# https://discuss.pytorch.org/t/how-do-i-check-the-number-of-parameters-of-a-model/4325/9
def count_parameters(model: torch.nn.Module) -> int:
""" Returns the number of learnable parameters for a PyTorch model """
return sum(p.numel() for p in model.parameters() if p.requires_grad)
在我们开始之前,请注意一个事实,即所有构件块都是标准化的,并且使用跳跃连接。这意味着所有输入和输出的shape(更确切地说,是其最后一个数字 , 因为batch size和tokens数量可能会有所不同)必须相同 。 对于原论文,这个数字(d_model)为512。
2.1 多头注意力
著名的注意力机制是Transformer架构的关键。但是,无论设计动机和技术细节如何,它只涉及几个矩阵乘法。
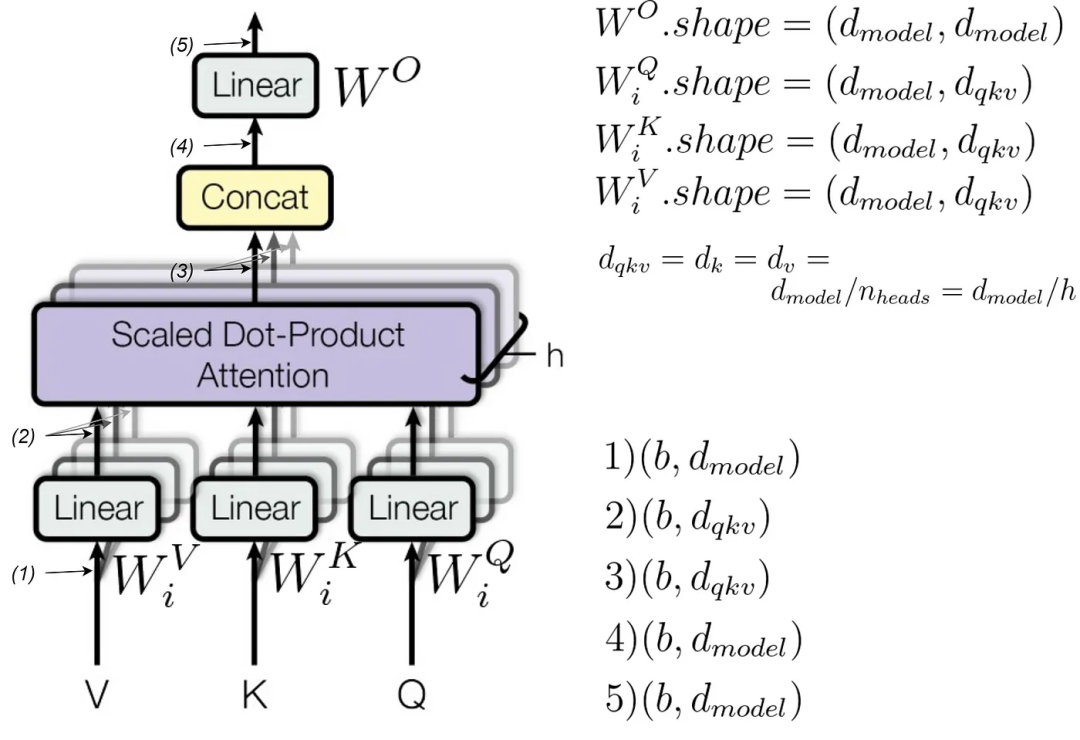
Transformer多头注意力架构图
来自论文https://arxiv.org/pdf/1706.03762.pdf
计算了每个head的注意力后,我们将所有head连接起来,并通过一个线性层(W_O矩阵)进行传递。反过来,每个head都是用三个独立的矩阵乘以query、key 和 value(分别为W_Q、W_K和W_V矩阵)的Scaled dot-product attention(缩放点积注意力)。这三个矩阵对每个head都是不同的,这就是下标i出现的原因。
最终线性层(final linear layer)(W_O)的shape为d_model到d_model。其余三个矩阵(W_Q、W_K和W_V)的shape相同:d_model到d_qkv。
请注意,在上面的图像中,d_qkv被表示为原论文中的d_k或d_v。我认为这个名称更直观,因为尽管这些矩阵可能具有不同的shape,但几乎总是相同的。
此外,请注意,d_qkv = d_model / num_heads (文中的h)。这就是为什么d_model必须能够被num_heads整除的原因:以确保后面的连接正确。
可以通过检查上图中的所有中间阶段的shape(正确的shape在右下角标出)来自行测试。
因此,我们需要每个head有三个较小的矩阵和一个大的最终矩阵。那么我们需要多少参数(不要忽略偏差)?
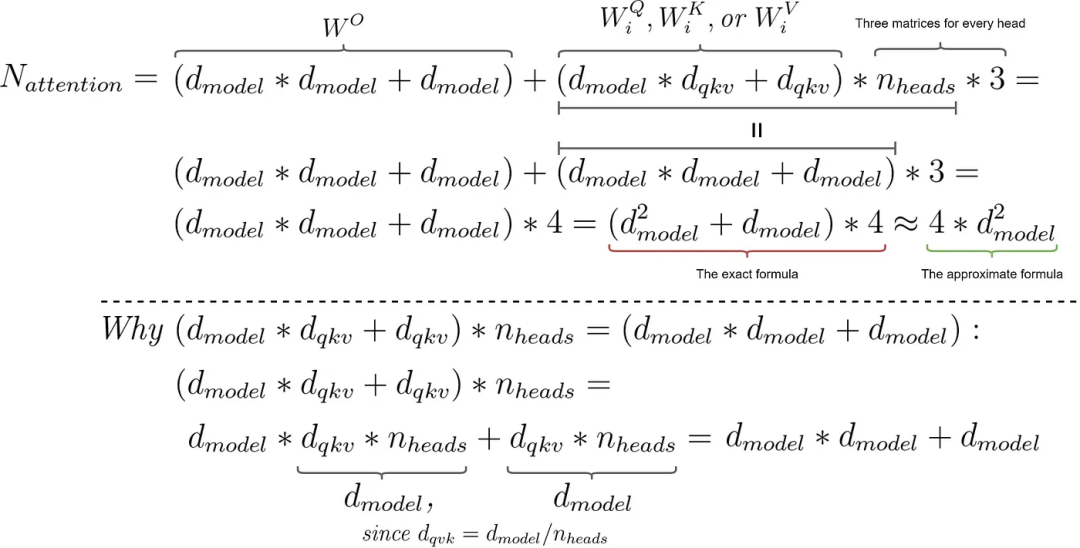
用于计算Transformer注意力模块中参数数量的公式。图片由作者提供
我希望这个公式不会太繁琐——我试图让推导的结果尽可能的清晰。不要担心! 未来的公式会更加简短。
参数的大致数量是这样的,因为与4 * d_model相比,我们可以忽略4 * d_model^2。让我们现在用PyTorch进行测试。
from torch import nn
d_model = 512
n_heads = 8 # must be a divisor of `d_model`
multi_head_attention = nn.MultiheadAttention(embed_dim=d_model, num_heads=n_heads)
print(count_parameters(multi_head_attention)) # 1050624
print(4 * (d_model * d_model + d_model)) # 1050624
数字匹配,这意味着我们做得很好!
2.2 前馈网络
Transformer中的前馈网络由两个全连接层(fully connected layers)组成,其中间有一个ReLU激活函数。该网络的内部部分比输入和输出(input and output)更具表现力(输入和输出必须相同)。
在一般情况下,它是MLP(d_model, d_ff) -> ReLU -> MLP(d_ff, d_model),对于原始论文,d_ff = 2048。

前馈神经网络描述 图来自论文https://arxiv.org/pdf/1706.03762.pdf
稍微进行一下可视化不会有坏处。
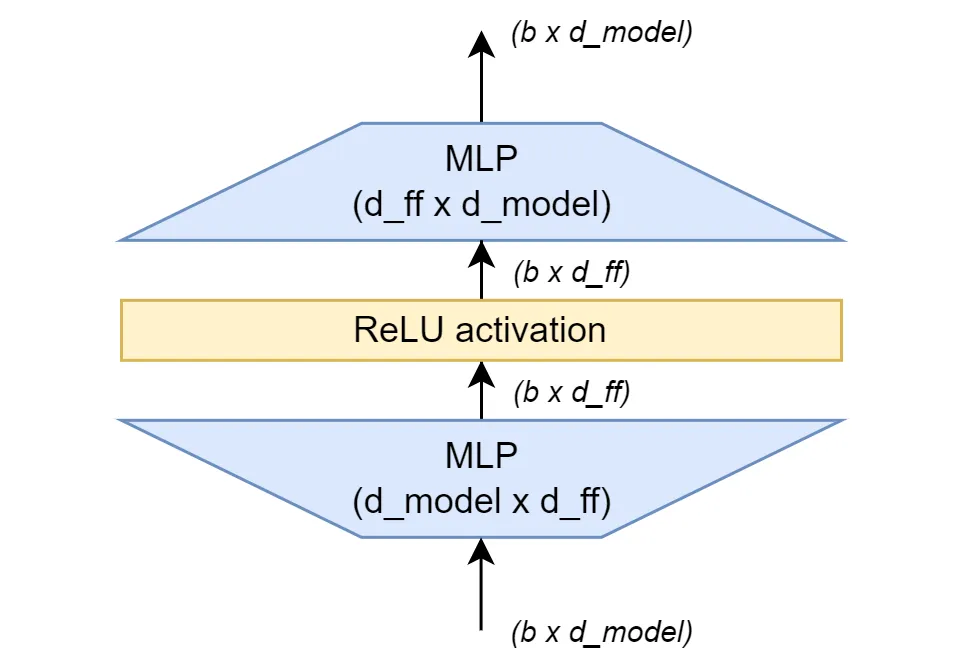
Transformer中的前馈网络。作者提供的图像。
参数的计算相当容易,主要的还是不要被弄混。

用于计算Transformer前馈网络中参数数量的公式。图像由作者提供。
我们可以使用以下代码描述这样一个简单的网络并检查其参数的数量(请注意,官方的PyTorch实现也使用了dropout,我们将在后面的编码器/解码器代码中看到。但是正如我们所知,dropout层没有可训练的参数,因此为了简单起见,我在这里省略它):
from torch import nn
class TransformerFeedForward(nn.Module):
def __init__(self, d_model, d_ff):
super(TransformerFeedForward, self).__init__()
self.d_model = d_model
self.d_ff = d_ff
self.linear1 = nn.Linear(self.d_model, self.d_ff)
self.relu = nn.ReLU()
self.linear2 = nn.Linear(self.d_ff, self.d_model)
def forward(self, x):
x = self.linear1(x)
x = self.relu(x)
x = self.linear2(x)
return x
d_model = 512
d_ff = 2048
feed_forward = TransformerFeedForward(d_model, d_ff)
print(count_parameters(feed_forward)) # 2099712
print(2 * d_model * d_ff + d_model + d_ff) # 2099712
再次看看图中的数字,仅剩下一个组件没有介绍啦。
2.3 层归一化
Transformer架构的最后一个构件块是层归一化。简单地说,只是一种智能的(即可学习的)归一化方式,具有缩放功能,可以提高训练过程的稳定性。
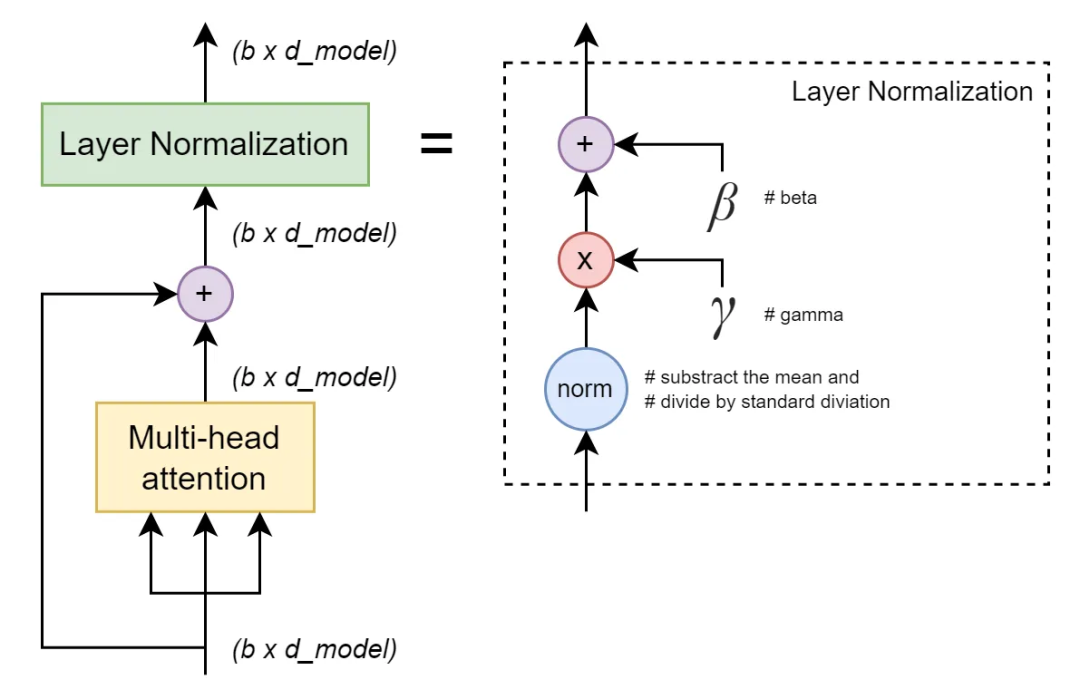
Transformer的层归一化,图片由作者提供
这里的可训练参数是两个向量gamma和beta,每个向量的维度都是d_model。
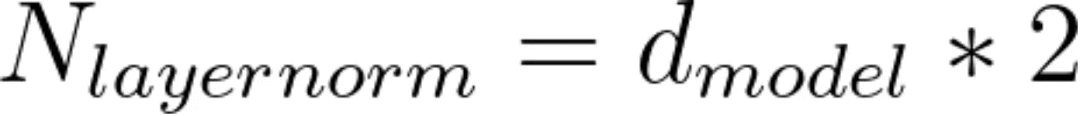
用于计算Transformer层归一化模块中参数数量的公式。作者提供的图像。
让我们使用代码来检验我们的假设。
from torch import nn
d_model = 512
layer_normalization = nn.LayerNorm(d_model)
print(count_parameters(layer_normalization)) # 1024
print(d_model * 2) # 1024
很好! 在近似计算中,这个数字可以忽略不计,因为层归一化的参数大大少于前馈网络或多头注意力块(尽管这个模块出现了几次)。
03 推导出完整的公式
现在我们有了一切,可以计算整个编码器/解码器模块的参数了!
3.1 用PyTorch实现的编码器和解码器
请让我们记住,编码器是由一个注意力块、前馈网络和两个层归一化组成。
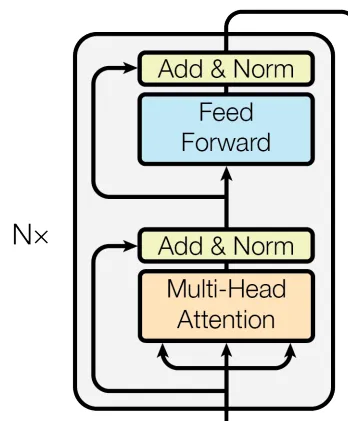
Transformer编码器。来源于论文https://arxiv.org/pdf/1706.03762.pdf
我们可以查看PyTorch代码中的细节来验证所有组件是否都已就位。其中多头注意力机制用红色标注(左侧),前馈网络用蓝色标注,层归一化用绿色标注(在PyCharm中的Python控制台截图)。
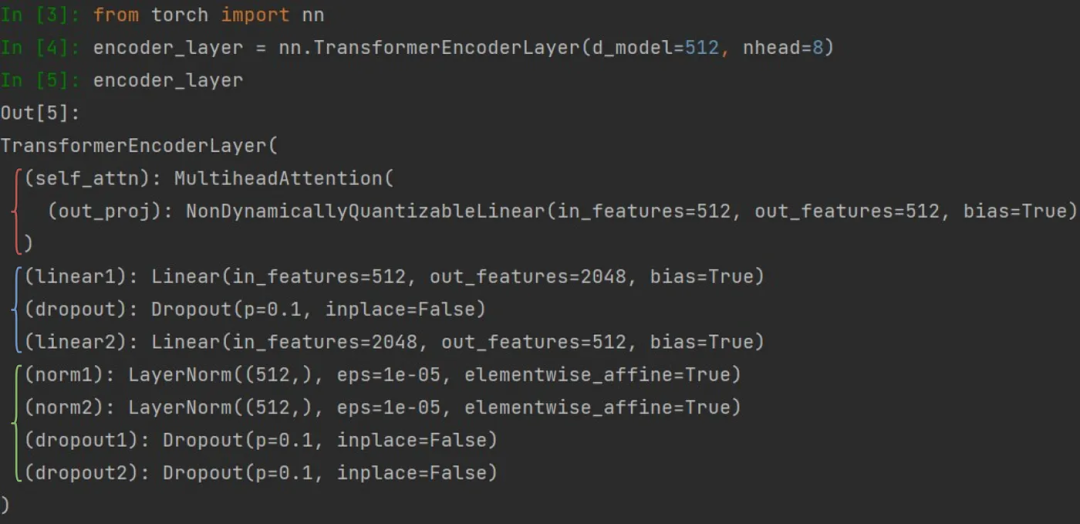
PyTorch TransformerEncoderLayer。图片由作者提供
3.2 最终公式
确认好之后,我们可以编写以下函数来计算参数数量。实际上,这只是三行代码,甚至可以合并为一行。函数的其余部分是文档字符串以作说明。
def transformer_count_params(d_model=512, d_ff=2048, encoder=True, approx=False):
"""
Calculate the number of parameters in Transformer Encoder/Decoder.
Formulas are the following:
multi-head attention: 4*(d_model^2 + d_model)
if approx=False, 4*d_model^2 otherwise
feed-forward: 2*d_model*d_ff + d_model + d_ff
if approx=False, 2*d_model*d_ff otherwise
layer normalization: 2*d_model if approx=False, 0 otherwise
Encoder block consists of:
1 multi-head attention block,
1 feed-forward net, and
2 layer normalizations.
Decoder block consists of:
2 multi-head attention blocks,
1 feed-forward net, and
3 layer normalizations.
:param d_model: (int) model dimensionality
:param d_ff: (int) internal dimensionality of a feed-forward neural network
:param encoder: (bool) if True, return the number of parameters of the Encoder,
otherwise the Decoder
:param approx: (bool) if True, result is approximate (see formulas)
:return: (int) number of learnable parameters in Transformer Encoder/Decoder
"""
attention = 4 * (d_model ** 2 + d_model) if not approx else 4 * d_model ** 2
feed_forward = 2 * d_model * d_ff + d_model + d_ff if not approx else 2 * d_model * d_ff
layer_norm = 2 * d_model if not approx else 0
return attention + feed_forward + 2 * layer_norm \
if encoder else 2 * attention + feed_forward + 3 * layer_norm
现在是测试它的时候了。
from torch import nn
encoder_layer = nn.TransformerEncoderLayer(d_model=512, nhead=8)
print(count_parameters(encoder_layer)) # 3152384
print(transformer_count_params(d_model=512, d_ff=2048, encoder=True, approx=False)) # 3152384
print(transformer_count_params(d_model=512, d_ff=2048, encoder=True, approx=True)) # 3145728
# ~0.21% difference
decoder_layer = nn.TransformerDecoderLayer(d_model=512, nhead=8)
print(count_parameters(decoder_layer)) # 4204032
print(transformer_count_params(d_model=512, d_ff=2048, encoder=False, approx=False)) # 4204032
print(transformer_count_params(d_model=512, d_ff=2048, encoder=False, approx=True)) # 4194304
# ~0.23% difference
准确的公式是正确的,这意味着我们已经正确地确定了所有构件块并将其分解成其各组成部分。有趣的是,由于我们在近似公式中忽略了相对较小的值(与百万相比只有数千个),因此相对于精确结果,误差仅约为0.2%!但是还有一种方法可以使这些公式更简单。
注意力块的近似参数数量为4 * d_model^2。考虑到d_model是一个重要的超参数,这听起来计算会十分简单。但是对于前馈网络,我们需要知道d_ff,因为公式是2 * d_model * d_ff。
d_ff是一个单独的超参数,现在必须在公式中记住它,因此让我们思考如何摆脱它。正如我们上面看到的,当d_model = 512时,d_ff = 2048,因此d_ff = 4 * d_model。
对于许多Transformer模型来说,这样的假设将是有意义的,大大简化了公式,并仍然给出一个大概的参数数量。毕竟,没有人想知道确切的数量,只是了解这个数量是几十万还是几千万。
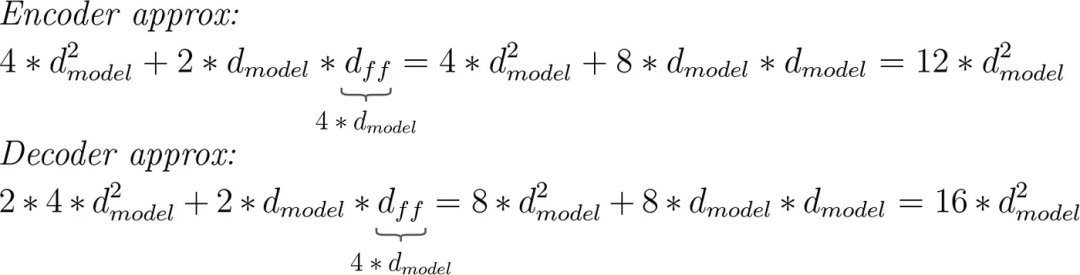
近似的编码器-解码器公式。由作者提供的图像。
为了了解你正在处理的数量级,你也可以将乘数四舍五入。这样每个编码器/解码器层就会得到10 * d_model ^ 2个参数。
04 Conclusion 结论
下面给我们今天推导出的所有公式做一个总结。

公式总结,由作者提供的图像。
在本文计算了Transformer编码器/解码器块中的参数数量,但是当然,我们并不建议您去计算所有新模型的参数。之所以选择这种方法,是因为当我开始研究Transformers时,我很惊讶没有找到这样的文章。
虽然参数数量可以让我们知道模型的复杂性和训练所需数据量,但这只是更深入地了解模型架构的一种方式。我想鼓励您探索和实验:去查看、实现、运行具有不同超参数的代码等等。因此,请继续学习并enjoy人工智能的乐趣!
END
参考资料
1.https://pytorch.org/docs/stable/generated/torch.nn.TransformerEncoderLayer.html
2.https://pytorch.org/docs/stable/generated/torch.nn.TransformerDecoderLayer.html
3.https://arxiv.org/abs/1706.03762
4.https://techcrunch.com/2022/12/22/a-brief-history-of-diffusion-the-tech-at-the-heart-of-modern-image-generating-ai/
5.https://www.washingtonpost.com/technology/interactive/2022/ai-image-generator/
6.https://www.explainpaper.com/papers/attention
7.https://jalammar.github.io/illustrated-transformer/
8.https://youtu.be/-QH8fRhqFHM
9.https://www.youtube.com/watch?v=rBCqOTEfxv
10.https://huggingface.co/course/chapter1/1
11.https://pytorch.org/
12.https://discuss.pytorch.org/t/how-do-i-check-the-number-of-parameters-of-a-model/4325/9
本文经原作者授权,由Baihai IDP编译。如需转载译文,请联系获取授权。
原文链接:
https://towardsdatascience.com/how-to-estimate-the-number-of-parameters-in-transformer-models-ca0f57d8dff0