这里写目录标题
- GPU流式多处理器
- CUDA内置变量
- WARP技术细节
- 性能优化
- 规约
- 规约算法
- 总结
- 并行规约算法1
- 规约2
- 规约算法 3
- 规约算法4
- 规约5‘
- 规约6
- for 循环展开
- 成功优化关键
- volatile
- cuda优化2
- 规约算法应用:内积
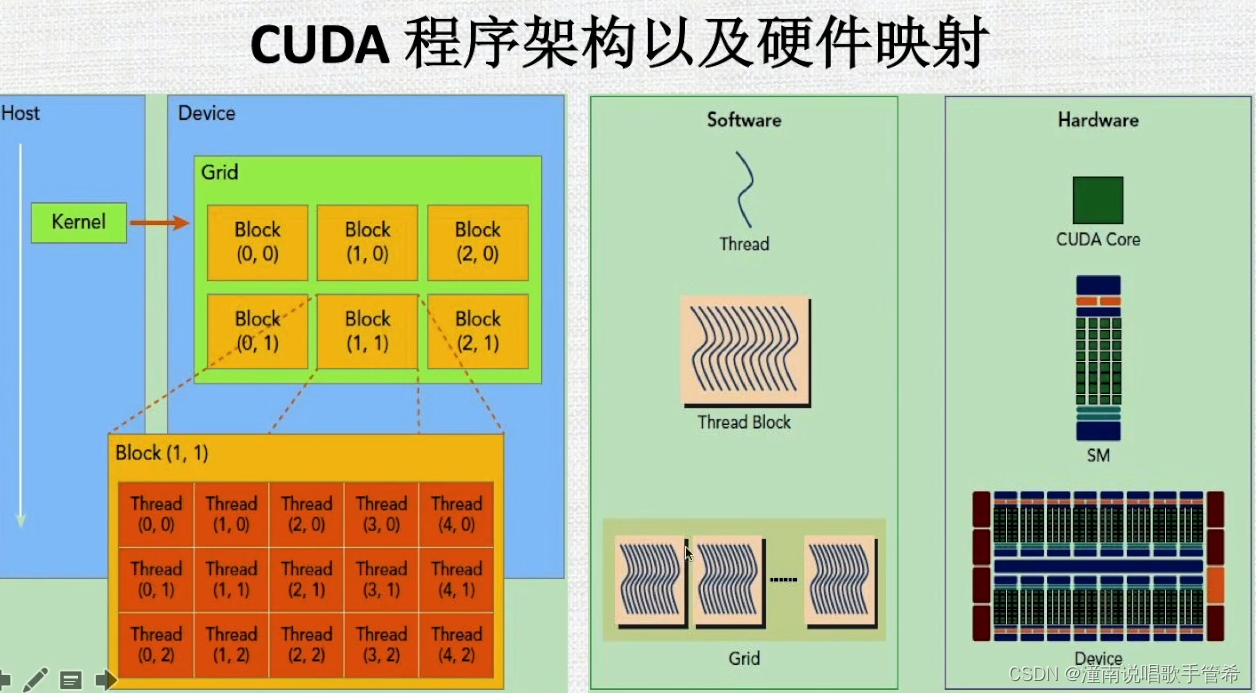
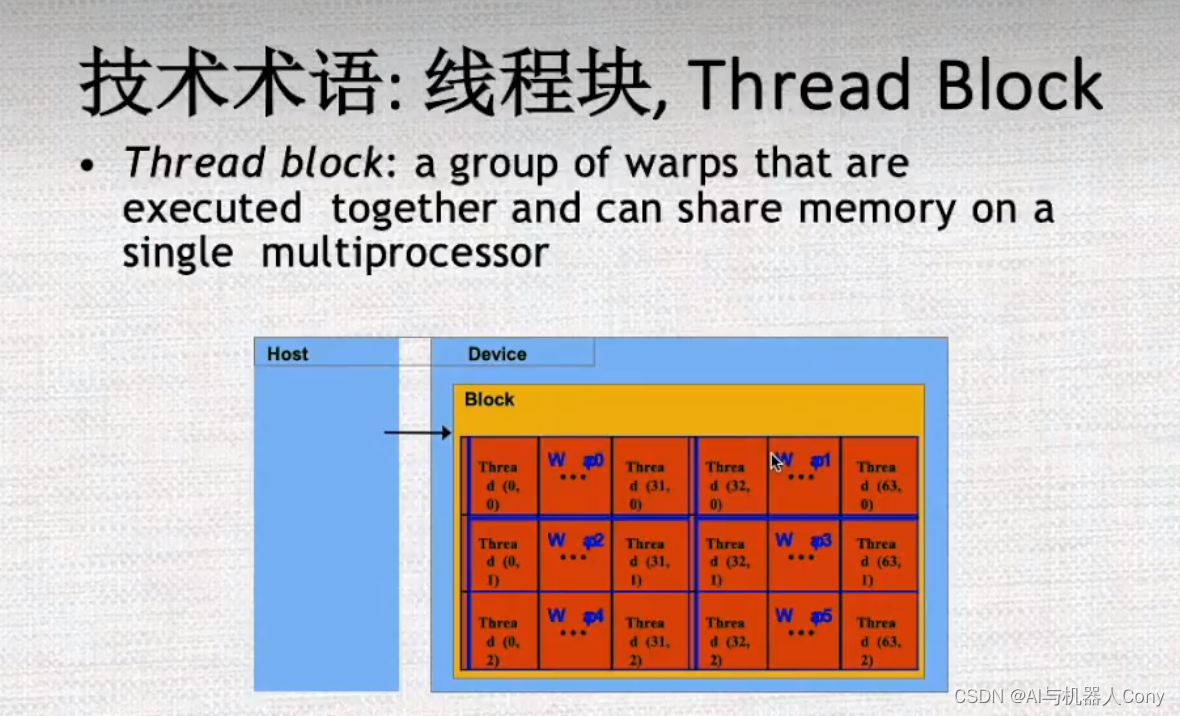
线程块对应SM
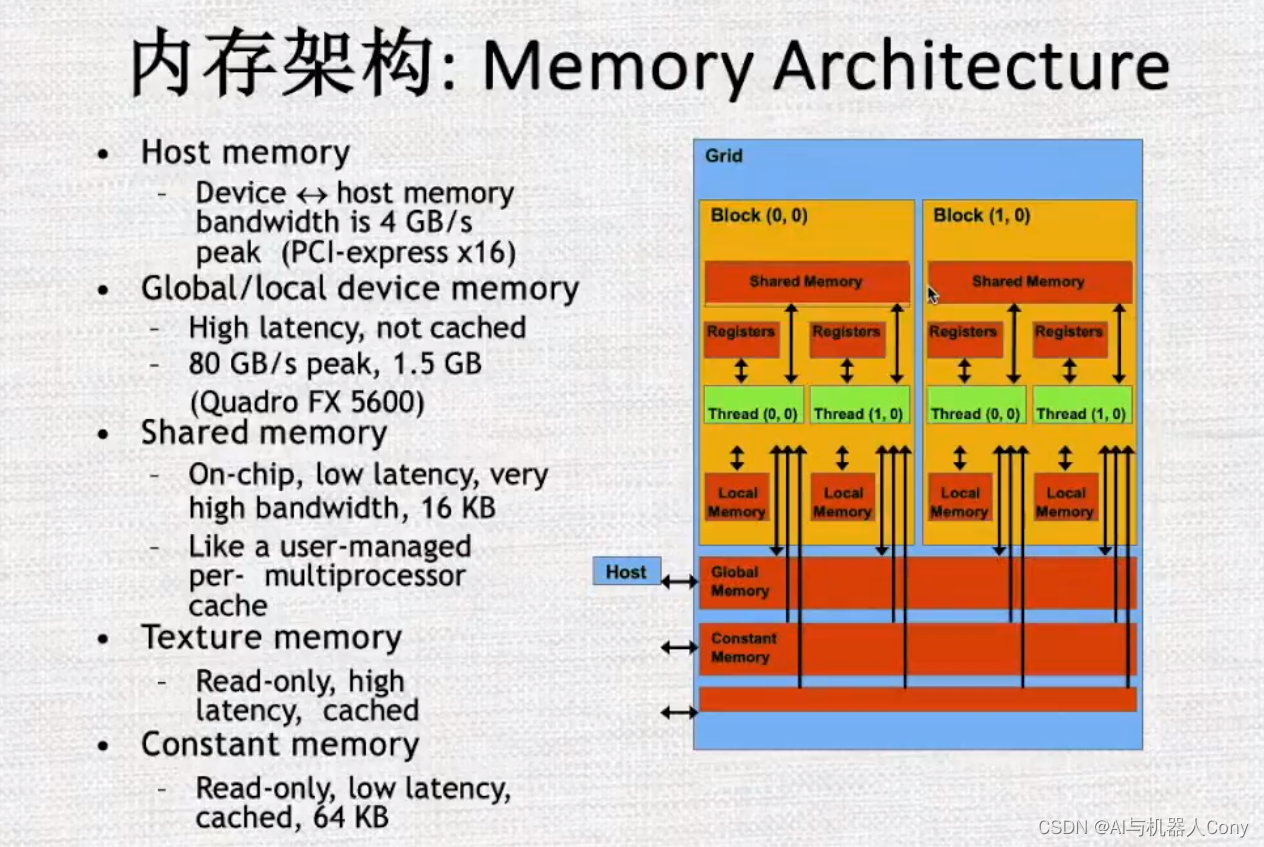
GPU流式多处理器

一个sm 有32个cuda core
CUDA内置变量

WARP技术细节

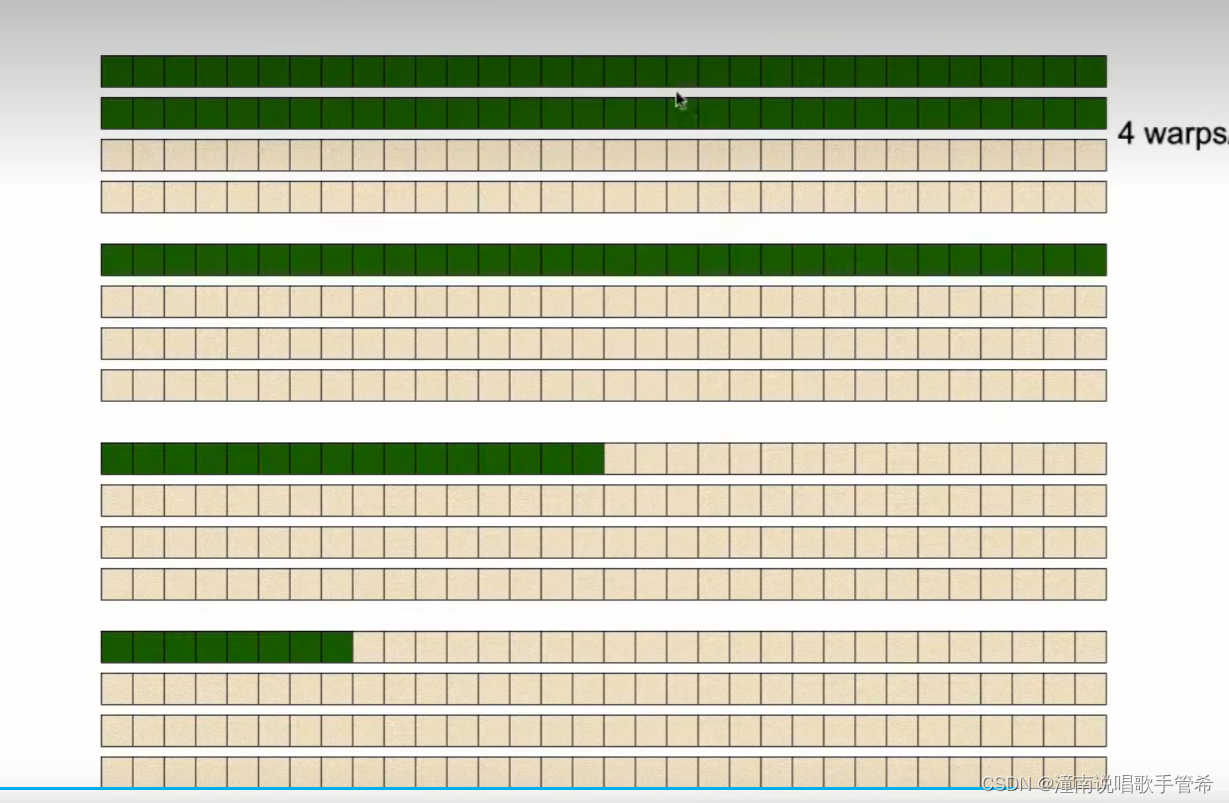
内核和线程对齐,如果发生跳跃,造成效率降低
性能优化

线程块 被分配到流多处理器上,快里面有线程
规约
规约操作(reduction operation)是指将多个值缩减为一个值的操作。通常情况下,规约操作是在并行计算中使用的,可以大幅提升计算效率。
在并行计算中,规约操作经常用于将一个大型数组中所有元素相加、求最大值或最小值等。例如,假设有一个长度为 N 的数组 A,我们想要对其进行求和,这时可以将数组分成多个子数组,分别在每个子数组内部求和,然后将各个子数组的和累加起来。这就是一种常见的规约操作,通过并行化的方式,大幅提高了求和的效率。
除了数组求和之外,排序、矩阵乘法、向量点积等也是典型的规约操作。在实现规约操作时,需要考虑任务的分配、同步和结果的合并等问题。因为规约操作涉及到多个任务的计算结果,因此必须确保所有任务完成后再开始最终的结果处理。
总之,规约操作是在并行计算中经常用到的一种技术,通过将数据分割、并行计算、结果合并等方式,提高了计算效率和性能。在实际应用中,需要根据具体问题选择适当的规约操作,并考虑任务划分、同步等问题。
规约算法

串行操作直接进行
并行操作可以考虑树结构
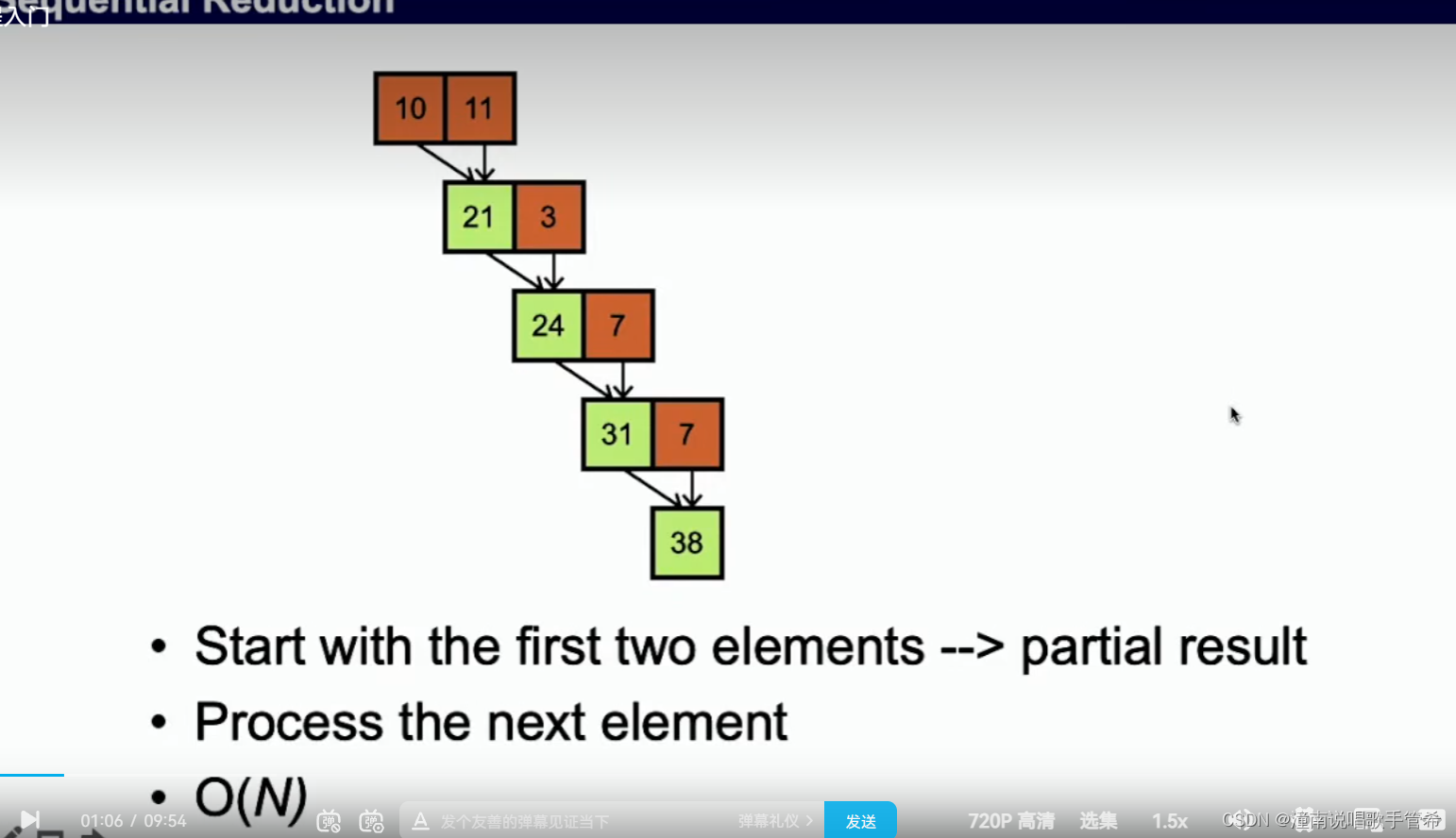
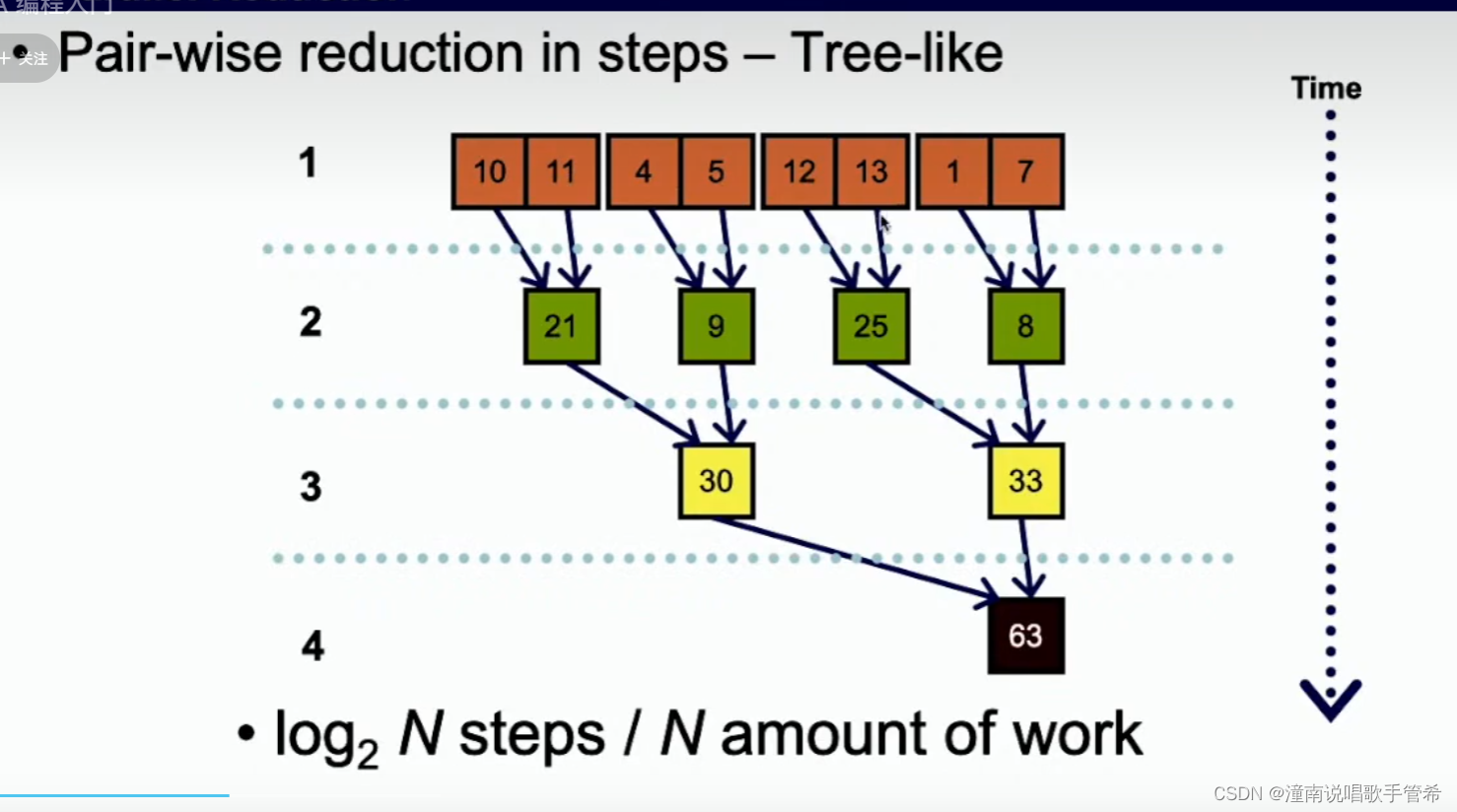
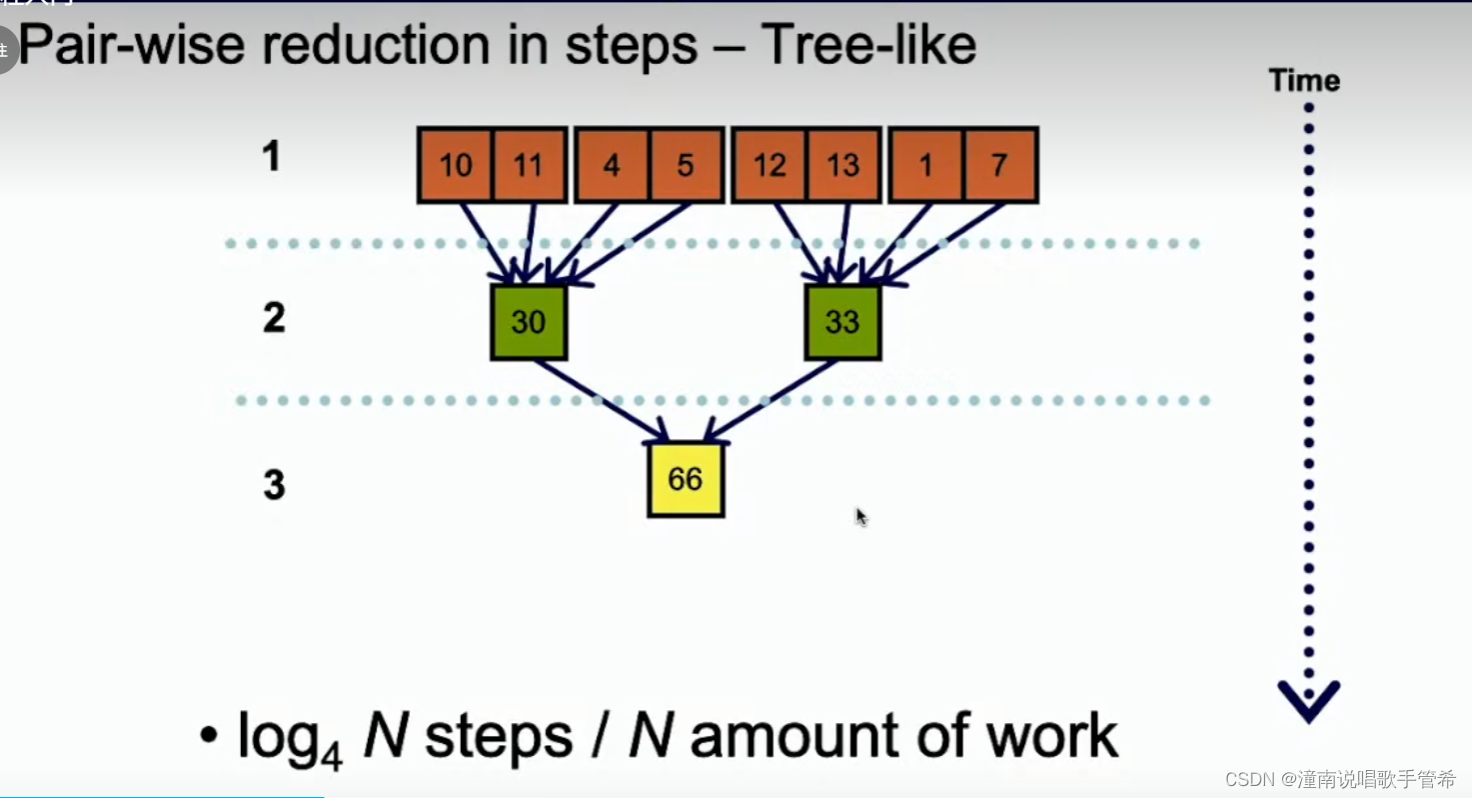

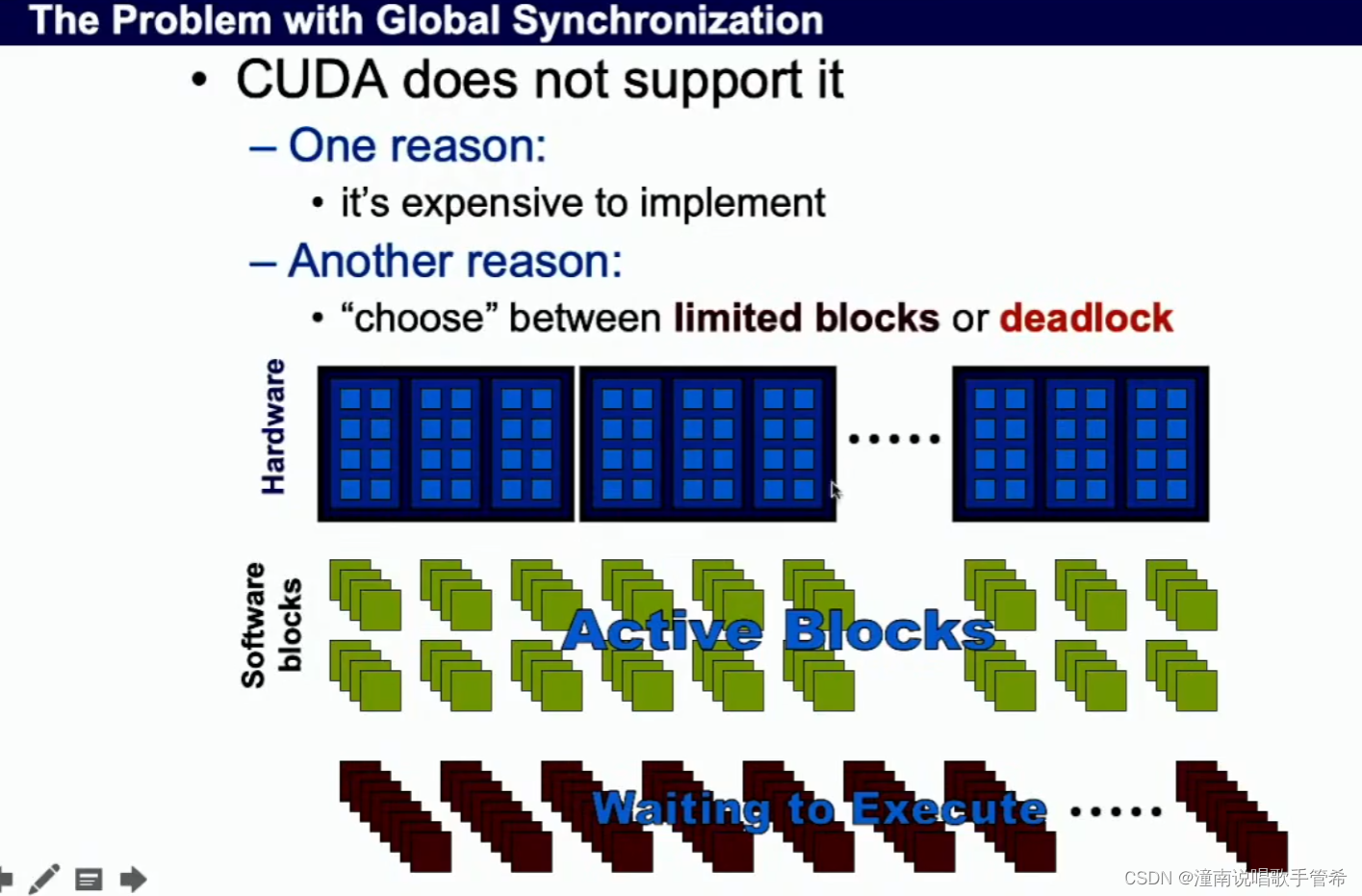
使用一个块容易造成计算资源浪费
如果使用多个块,使用全局同步
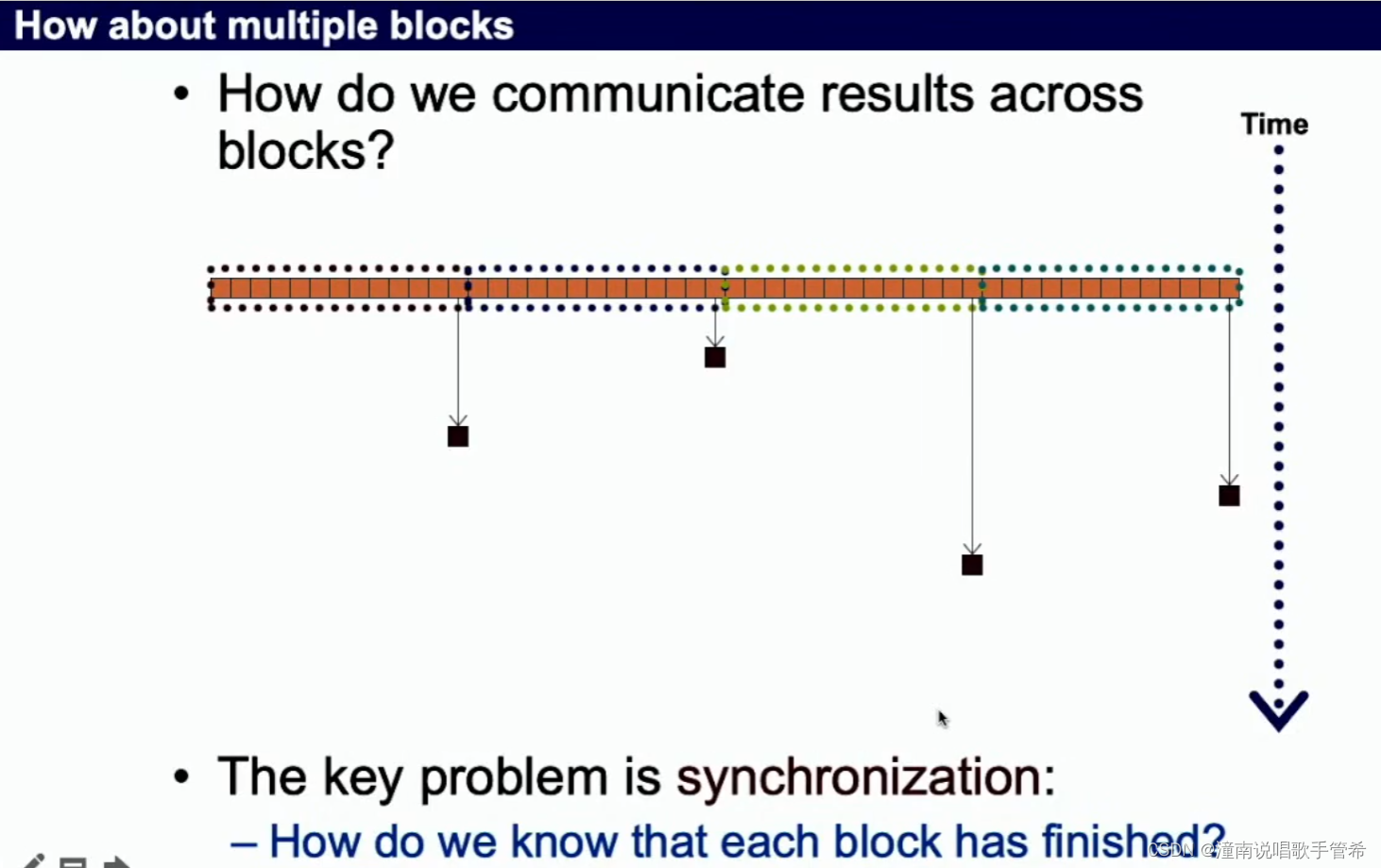
npi barry
等待全局同步点
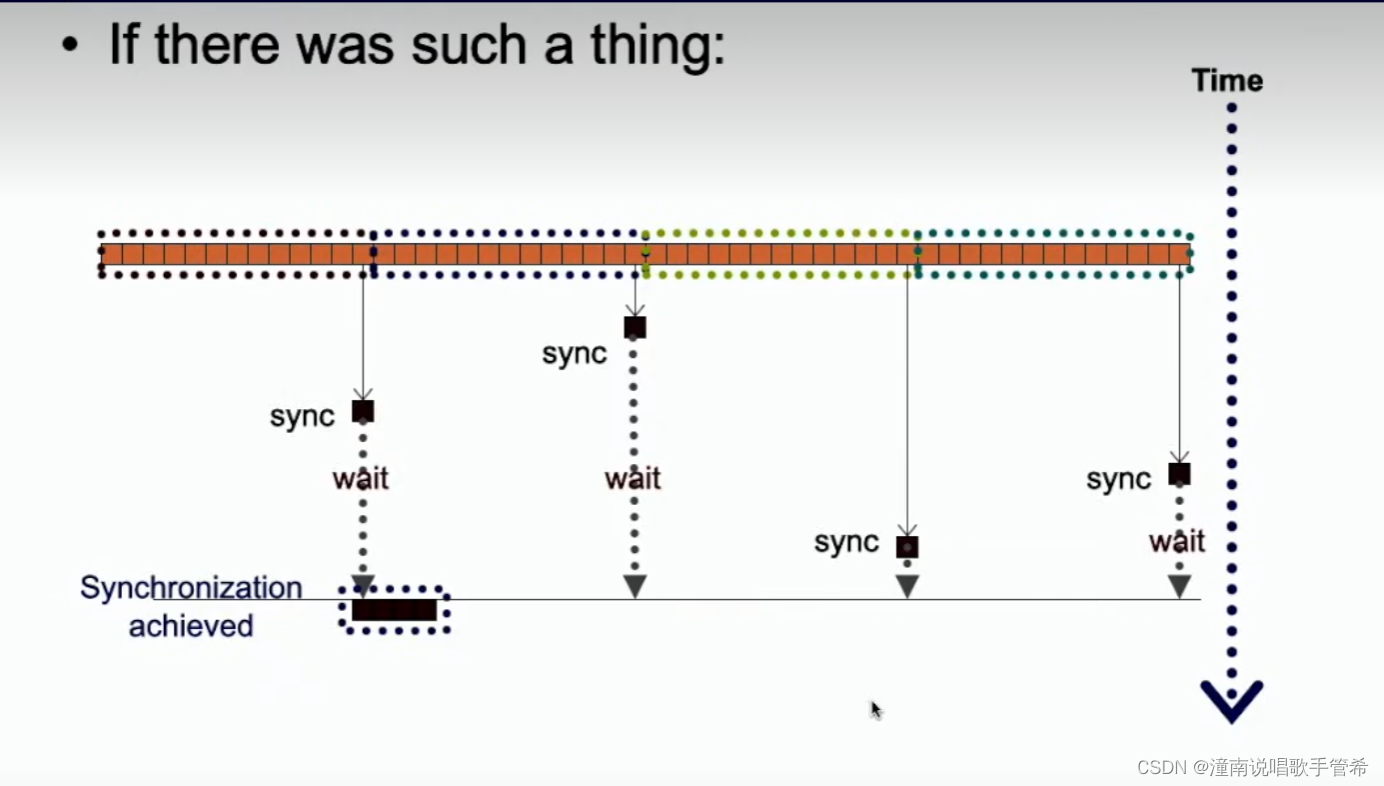
容易因等待造成资源浪费
容易造成死锁,都在等待,没有活跃的sm
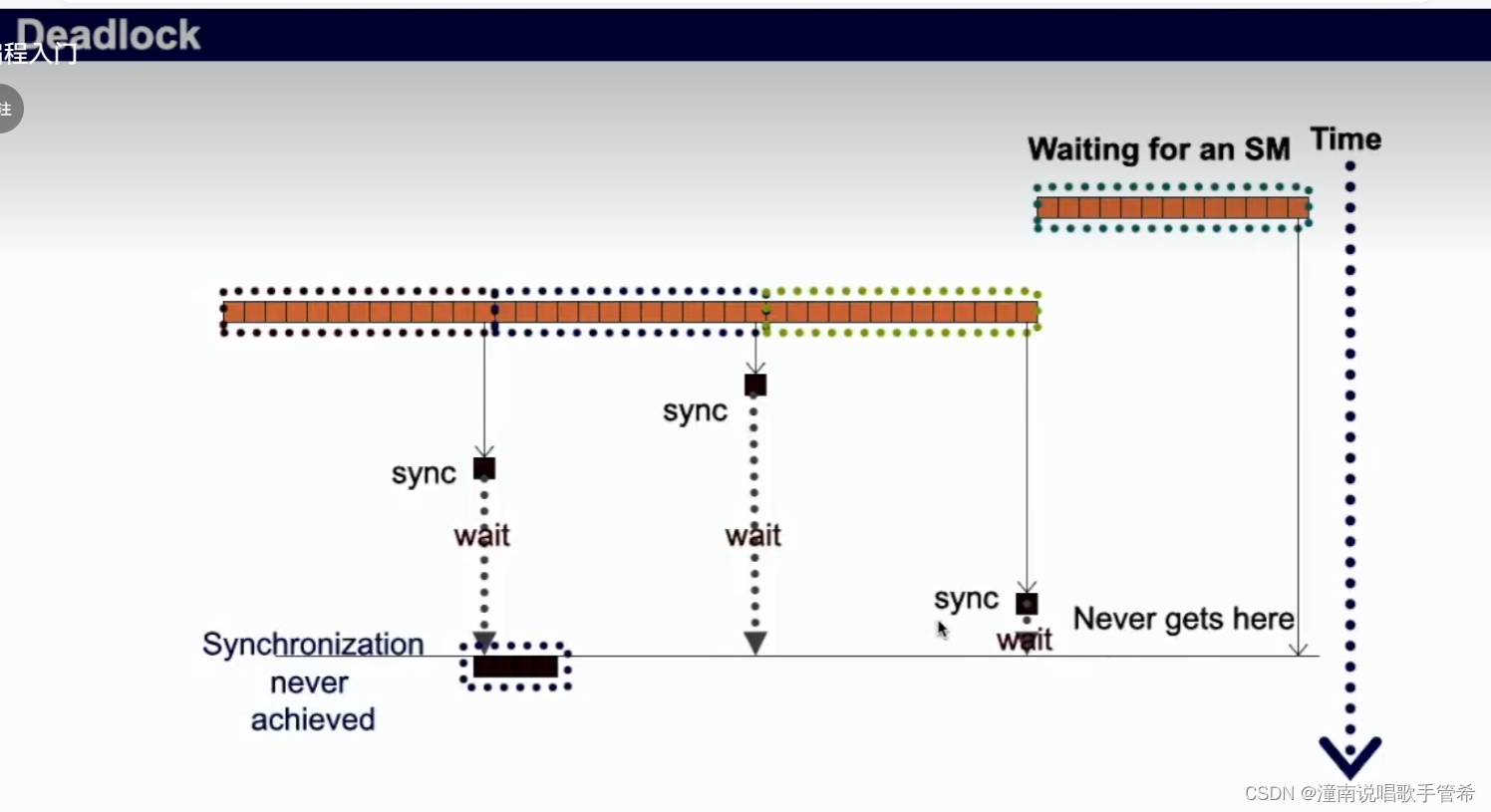
总结

第二个kernel调用会在第一个执行完之后才会,相当于隐含的同步点

调用两个kernel
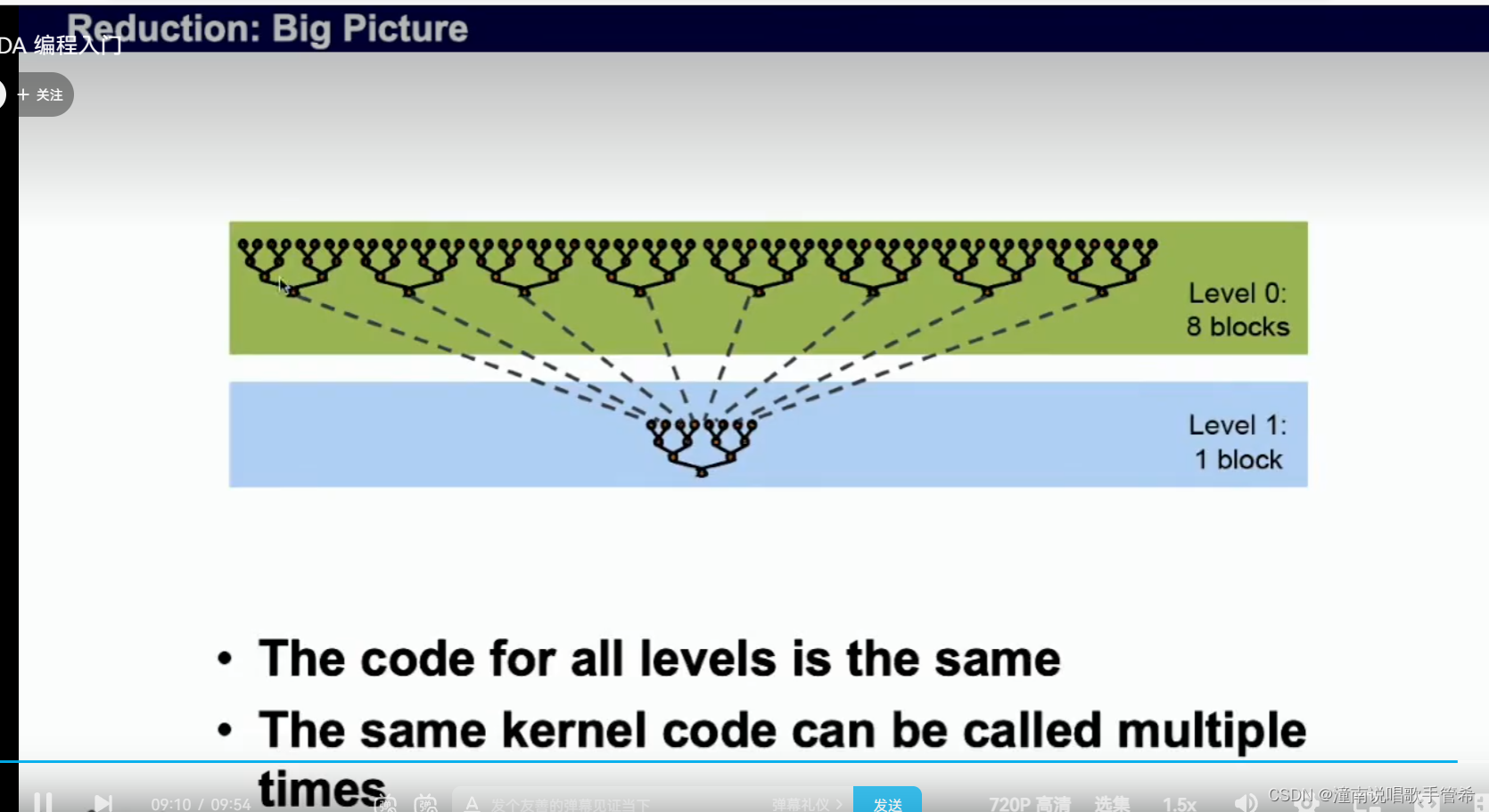
并行规约算法1

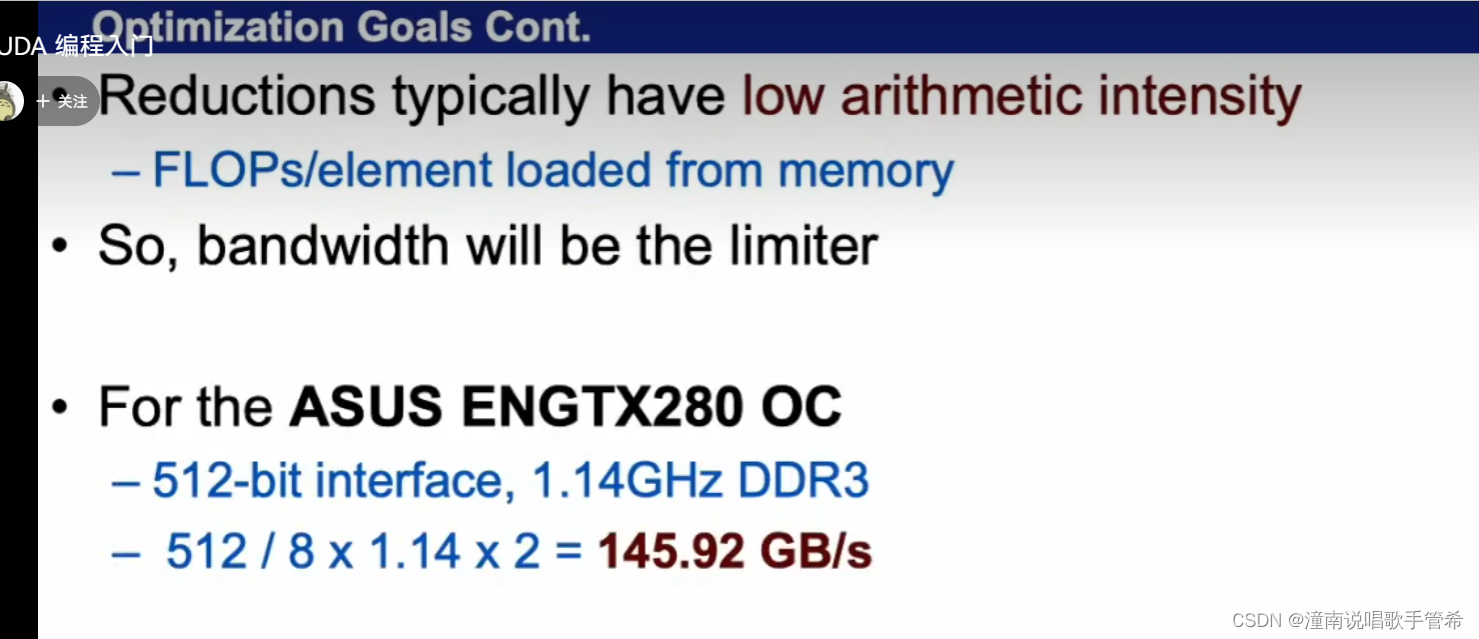
浮点运算最大
有限带宽达到极致

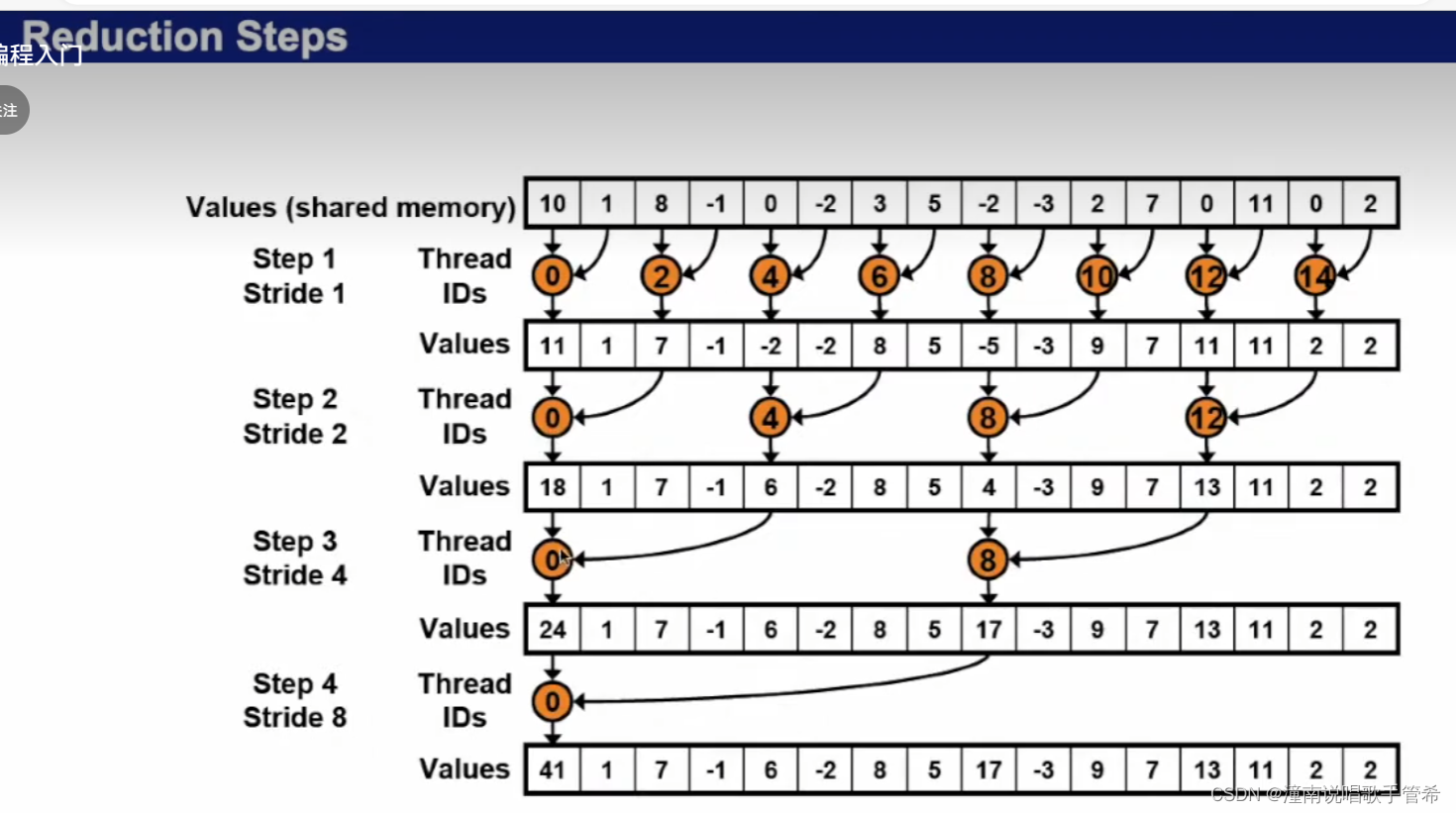
线程的利用率极低,每次线程数量都会减半

说明block是一维的
根据步长,处理相应线程
只有线程为0的时候才会写入
理论带宽有100多,所以有效利用率很低

128+1 =129次访问
非常抱歉,我在上一条回答中犯了错误。由于每个块需要读取 128 个元素和写入 1 个元素,因此总的元素读取次数应该是 N × (128/128) = N,总的元素写入次数是 N/128。因此,最终需要进行的元素读取操作次数是 N,元素写入操作次数是 N/128。
因此,正确的表达式应该是 N + N/128,即元素读取操作次数为 N,元素写入操作次数是 N/128。非常抱歉再次出现错误,感谢您的指正。
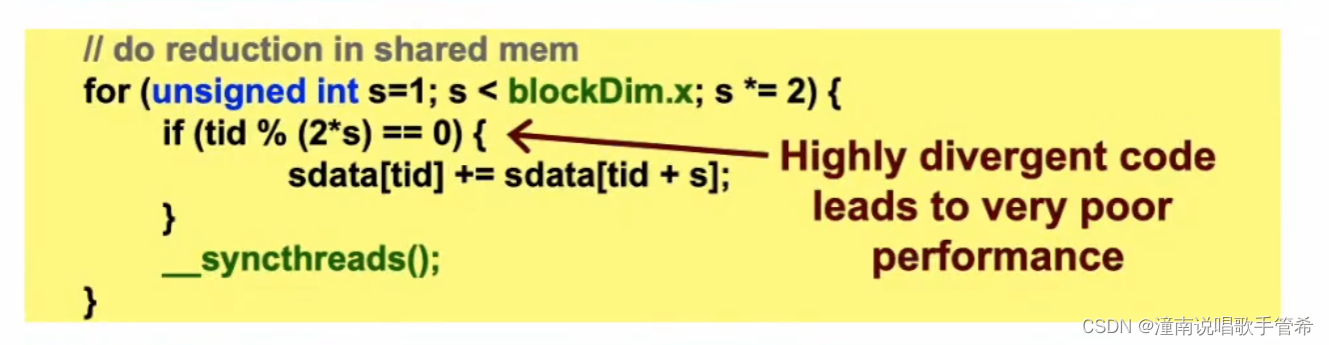
设计不好,指令分化了

浪费严重,指令分化
规约2
引入临时变量,避免同一个wrap指令不同

前面一个只要是偶数倍才执行相加,不同线程执行命令不一样,不好,造成串行执行
第一个循环,128只有前64个线程在执行。连续的
第一个线程和第三个
第二个循环有32个线程。 线程指令都是相同的
和第一个算法比,该命令有效提升

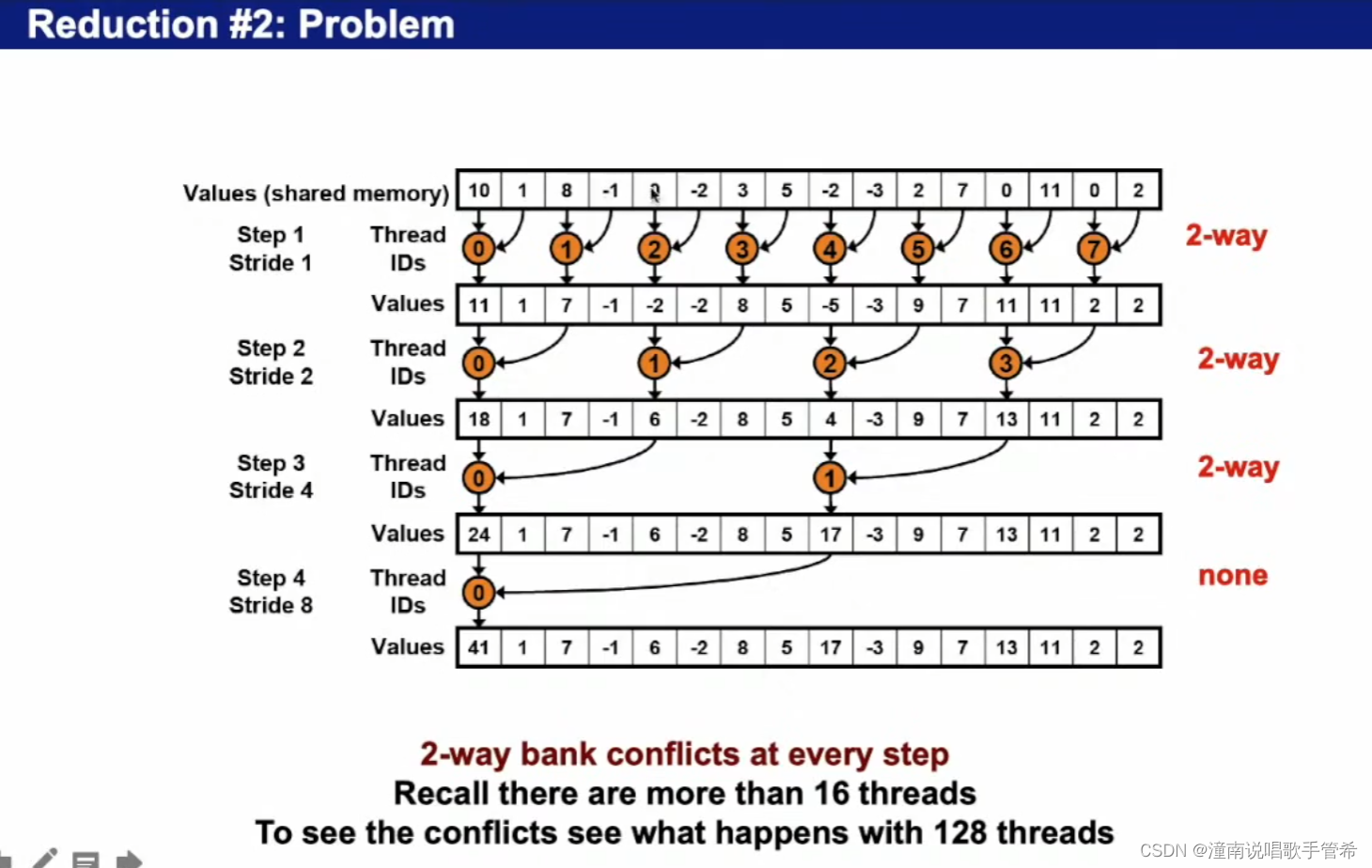
同一个wrap里会有跨bank,会有数据冲突
比方说,访问共享内存时,一个线程会访问两个内存点,这两个内存点跨bank了
2-way bank conflicts at every step 的意思是,在每个步骤(step)中都会发生 2 路(2-way)的银行冲突(bank conflict)。
在 GPU 计算中,每个线程(thread)都需要访问显存中的数据,而显卡的显存通常被组织成一系列的银行(bank)。当多个线程同时访问同一个银行时,就会发生银行冲突,从而导致内存访问效率的下降。
由于每个步骤中都发生 2 路的银行冲突,可以推断出每个时钟周期内,有两个线程同时访问了同一个银行。这种情况下,GPU 可能需要等待多个时钟周期才能完成内存访问操作,从而导致性能下降。
因此,在程序的设计和优化过程中,需要尽量避免银行冲突的发生,以提高 GPU 的内存访问效率和计算性能。
可以把 interleaved addressing 和 non-divergent branching 理解为两个相对独立的概念。
Interleaved addressing(交错寻址)是一种内存访问模式,它将连续的内存地址分散到不同的 memory bank 中。例如,如果我们使用 4 个连续的内存地址,它们可能会被交错地分配到四个不同的 bank 中。当多个线程同时访问这些交错的内存地址时,就可能会引起 bank conflicts,因为许多线程需要同时访问同一个 bank 中的数据。
Non-divergent branching(非分歧分支)则是一种程序执行模式,在该模式下,所有线程都按照相同的代码路径执行分支语句,即它们有相同的分支决策。这样可以避免分支预测错误、分支执行效率低下等问题,从而提高计算性能。
如果 interleaved addressing 和 non-divergent branching 同时使用,那么可能会出现 bank conflicts 的问题。这是因为在非分歧分支的情况下,所有线程都会按照相同的代码路径执行,如果这个路径涉及到了交错内存访问,那么所有线程都会访问相同的 bank,从而引起银行冲突。
因此,在 GPU 编程中,我们需要仔细选择合适的内存访问模式和分支模式,以避免银行冲突的问题。这可能涉及到数据划分、内存布局、线程块大小等方面的优化。
规约算法 3
第一个会造成指令分化
第二个指令一样了,但是访问共享内存时会有数据冲突,效率不是很高
wrap访问一个bank,可以通过广播提高访问效率
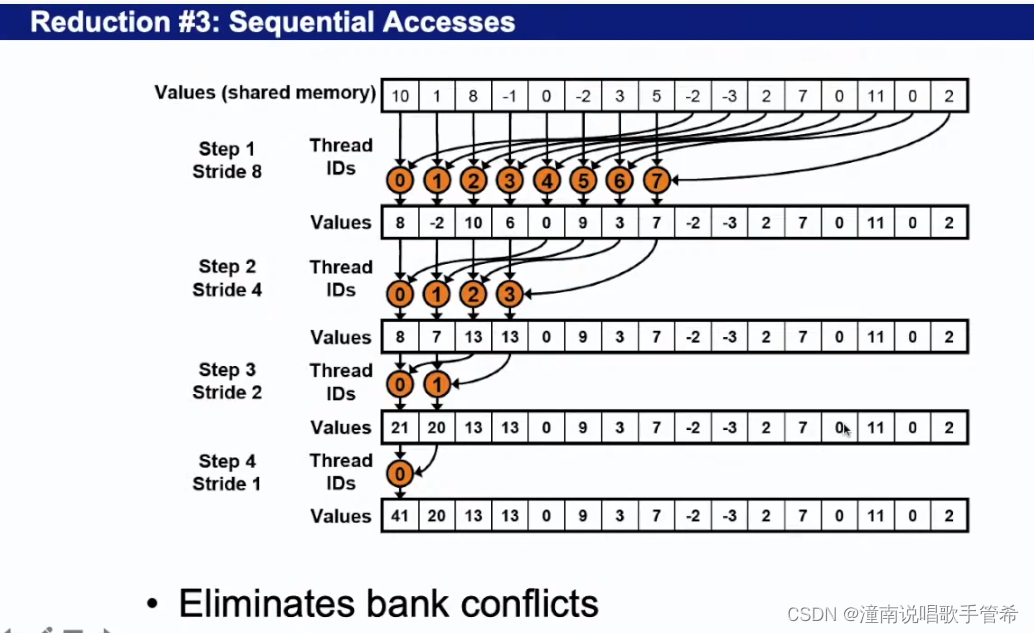
保证每次访问最优,不存在冲突,都是顺序的访问
可以体现在代码中,推算


只改了三行代码,性能加倍
下面的代码循环时有一半的线程在空转,GPU没有达到最优状态

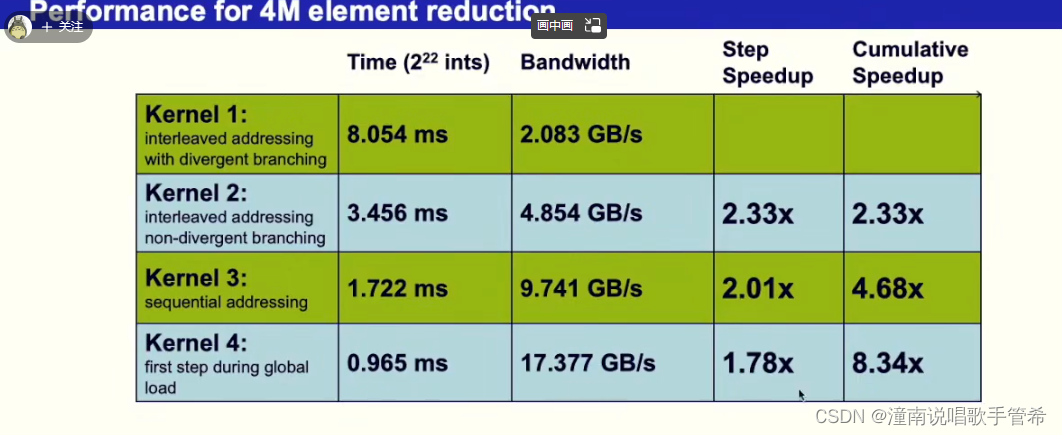
规约算法4
第三种算法按线性访问,比第一种基本快四倍多
i为数组全局编号

block数减半
规约5‘

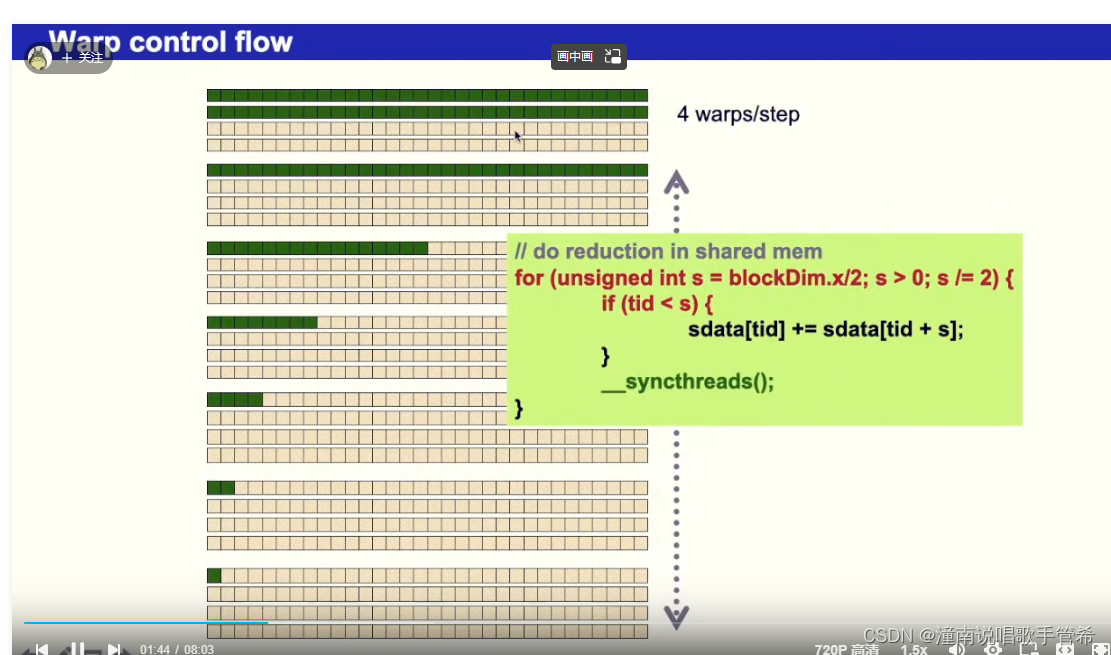

在一个wrap之内所有的线程执行相同的命令
他是0-127,不可能等于32
小于32时全部展开,6次循环就不做了,这样的话省略掉很多更新和同步操作
当小于32的时候,就是在一个wrap内了

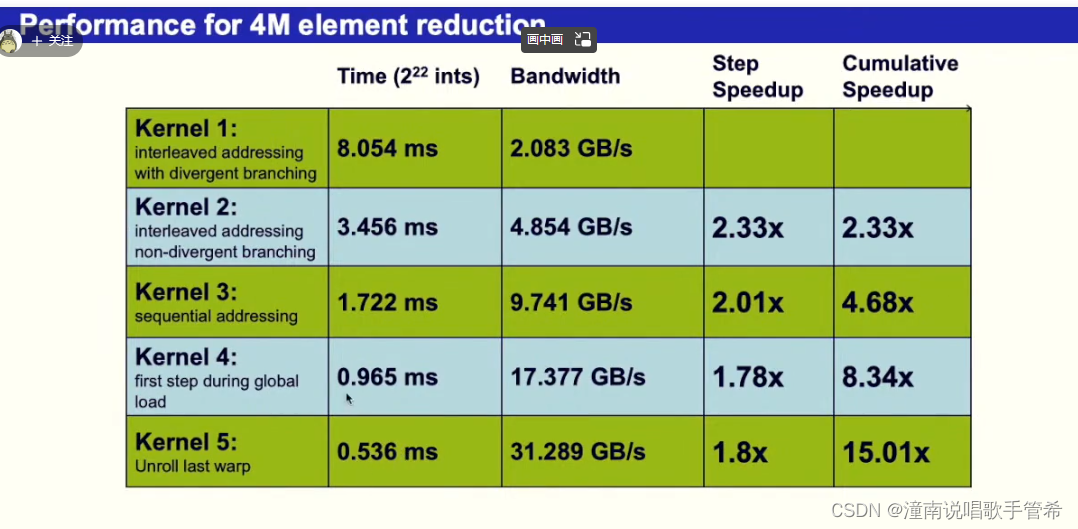
优化技巧对硬件非常接近,GPU优化需要对硬件十分了解
指令分化,内存管理
规约6

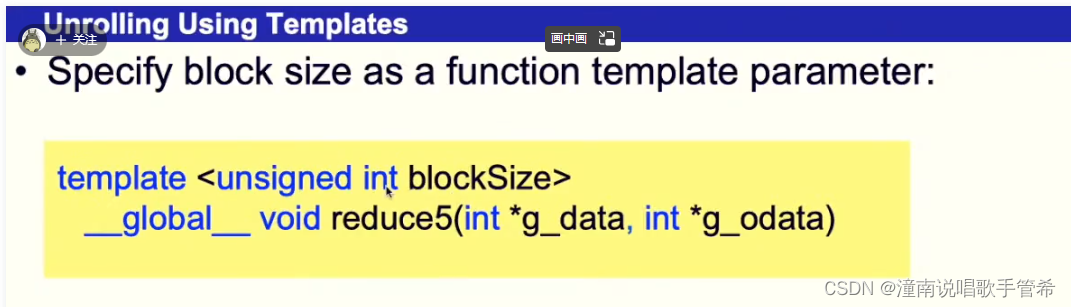


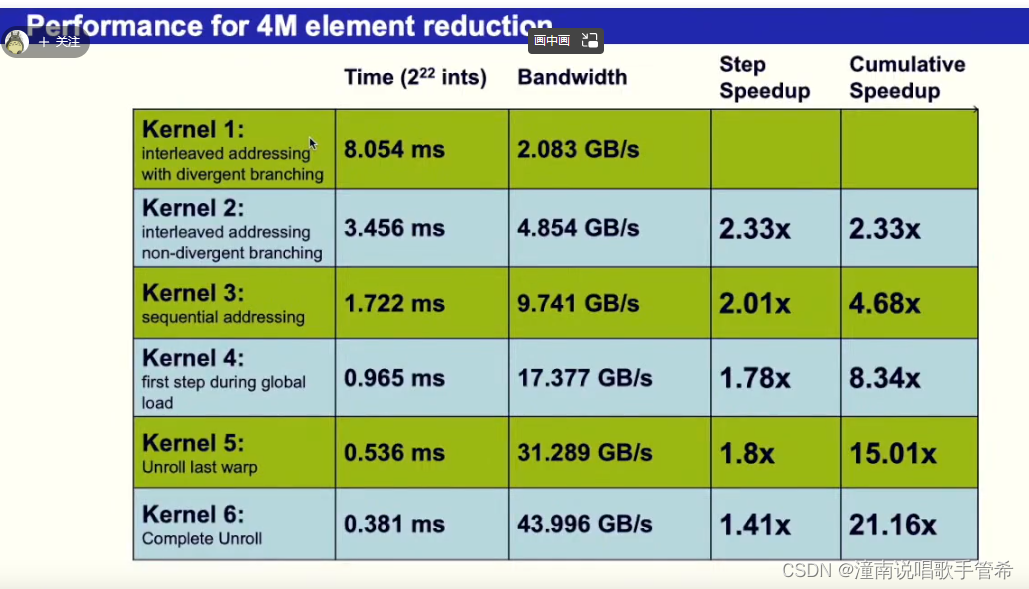
for 循环展开
展开 for 循环可以加快程序的执行速度,但需要权衡性能和代码可读性之间的关系。
循环展开是一种优化方法,它通过将循环体中的代码复制多次,使每次迭代处理多个数据,来减少循环的迭代次数以及循环边界判断的消耗,从而提高程序的执行效率。例如,将一个 for 循环中的迭代次数从 1000 展开到 4 次循环,可以将循环次数的消耗降低到原来的 1/250,由此大大加快了程序的执行速度。
然而,在决定是否展开循环时,我们需要考虑代码的可读性、维护性以及执行效率之间的平衡。当循环体中的代码量很小时(如几行),循环展开往往不会明显提高性能,但会增加代码的复杂度。此外,如果展开循环导致代码量过大,则会降低代码的可读性和维护性,可能会带来其他问题。
因此,在实践中,我们需要根据具体的情况综合考虑,权衡展开循环和保持代码可读性和易维护性之间的平衡。通常情况下,展开小型循环并逐步增加展开的次数是比较安全和有效的做法,以在不损害代码质量的情况下提高程序的性能。
成功优化关键
第五个考虑wrap的特性,规避一些变量更新,比较以及同步操作
第六个考虑cpp模板特性,将循环全部展开
编译器可能会自作聪明,优化使得结构错误
相对位置上的这个值是实时变化的
规避提前把值加入了
两种方法,后面用一个子函数,为什么这里用一个子函数。
共享内存加了volatile
最后一个wrap,子函数中加入volatile
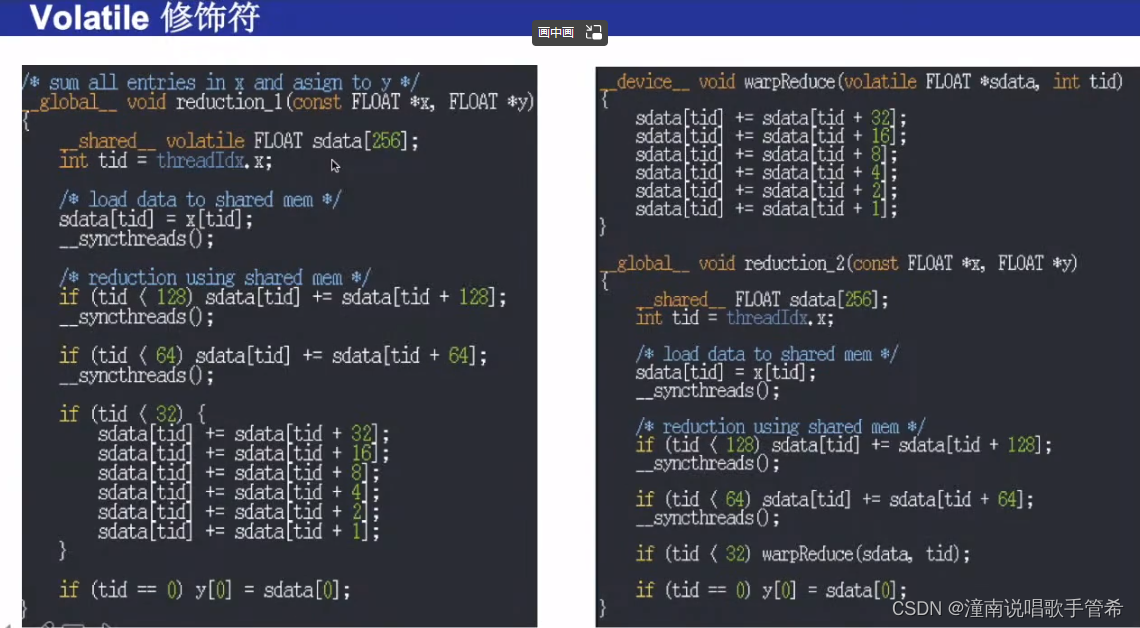
在 CUDA 中,__device__ 表示该函数需要在设备端执行,因此函数中使用的变量一般会放在设备端内存中。而与之对应的 __host__ 则表示该函数需要在主机端执行。
在上述代码中,我们发现在 warpReduce 函数中定义的 sdata 变量是使用 volatile 修饰符声明的。这里使用 volatile 主要是为了提示编译器不要对该变量进行过度优化,从而保证程序的正确性。由于 warpReduce 函数是在设备端执行的,因此使用 volatile 修饰符也可以保证 sdata 这个设备端内存上的变量能够正确地被访问和修改。
而在 VecSumKnl 函数中定义的 sdata 变量则没有使用 volatile,这是因为在该函数中,sdata 变量只被当前线程访问和修改,并且使用了 __shared__ 关键字将其声明为了共享内存。共享内存是一种特殊的设备端内存,它可以用于多个线程之间共享数据。在 CUDA 中,共享内存的使用非常高效,因为它可以直接被线程块中的多个线程所访问,而不需要通过全局内存或其他线程块来传递数据。由于共享内存只被当前线程块所使用,因此使用 volatile 修饰符并不是必需的。
综上所述,只需要在 warpReduce 函数中使用 volatile 修饰符即可保证该函数中访问和修改的变量能够正确地被编译器处理。而对于共享内存等特殊的内存区域,虽然不需要使用 volatile 修饰符,但需要注意合理使用共享内存,以提高程序的效率。
在 CUDA 编程中,__shared__ 变量是线程块内的共享存储器,可以被同一个线程块内的所有线程访问。__shared__ 变量的读取和写入操作是非原子的,因此在多个线程同时访问__shared__ 变量时,需要确保线程之间的同步,避免出现竞争条件。在这里,volatile 用于表示每次访问共享存储器 sdata[tid] 是从共享存储器中直接读取数据,而不是从线程本地缓存中获取,避免了编译器对共享内存读取进行优化,保证了每个线程访问的都是最新的共享内存值。这是为了防止编译器优化将共享存储器变量缓存在寄存器内,导致结果错误的情况。
volatile
在 C/C++ 中,编译器为了优化程序的执行效率,在编译时可能会对代码进行一些优化,如常量折叠、循环展开等。这些优化可能会使程序更快,但也可能会影响程序的正确性。例如,当使用全局变量或共享内存时,如果不加任何修饰符,编译器可能会在编译时自动将变量的值代入使用,而不是每次运行时都读取变量的最新值。这种情况下,程序的行为可能会出现错误。
为了避免编译器对变量进行过度优化,我们可以使用 C/C++ 中的 volatile 关键字来告诉编译器不要对这个变量进行优化。volatile 关键字的作用是告诉编译器该变量在程序运行中可能被意外地修改,因此需要在每次使用时重新读取变量的值。使用 volatile 修饰符声明的变量不会被编译器缓存,而应该在每次访问时都从内存中读取。
例如,下面的代码中,使用 volatile 修饰符声明的变量 x 在每次循环迭代时都会从内存中重新读取,而不是直接使用缓存值:
volatile int x = 0;
while (x == 0) {
// do something
}
需要注意的是,虽然 volatile 可以避免编译器对变量进行过度优化,但并不能保证线程安全和原子性。如果需要保证多线程程序的正确性,还需要使用其他机制,如互斥锁、原子变量等。
综上所述,加入 volatile 修饰符可以防止编译器对变量进行过度优化,从而提高程序的正确性。但同时也需要注意线程安全和原子性的问题。
cuda优化2



wrap逻辑上执行并行的单位
块内线程不能太多也不能太小
太小 开销变大
太大 处于活跃的就会变少


规约算法应用:内积



__device__ void warpReduce(volatile FLOAT *sdata, int tid)
{
sdata[tid] += sdata[tid + 32];
sdata[tid] += sdata[tid + 16];
sdata[tid] += sdata[tid + 8];
sdata[tid] += sdata[tid + 4];
sdata[tid] += sdata[tid + 2];
sdata[tid] += sdata[tid + 1];
}
/* partial dot product */
__global__ void dot_stg_1(const FLOAT *x, FLOAT *y, FLOAT *z, int N)
{
__shared__ FLOAT sdata[256]; 256个线程
int idx = get_tid();
int tid = threadIdx.x;
int bid = get_bid();
/* load data to shared mem */
if (idx < N) {
sdata[tid] = x[idx] * y[idx];
}
else {
sdata[tid] = 0;
}
__syncthreads();
/* reduction using shared mem */
if (tid < 128) sdata[tid] += sdata[tid + 128];
__syncthreads();
if (tid < 64) sdata[tid] += sdata[tid + 64];
__syncthreads();
if (tid < 32) warpReduce(sdata, tid);
if (tid == 0) z[bid] = sdata[0];
}
这段代码是一个使用 CUDA GPU 编写的向量点积优化代码,主要目的是对输入的两个向量做点积,输出一个数。具体地,点积就是将对应位置上的数相乘后求和,可以用以下公式表示:
z = ∑ i = 1 N x i y i z = \sum_{i=1}^N x_i y_i z=∑i=1Nxiyi
分为三个阶段的原因是因为在计算每一步的结果时,可以通过使用共享内存和线程同步实现更好的数据传输和处理,从而提高计算效率。以下是每个阶段的作用:
第一阶段(dot_stg_1):该函数加载输入的两个向量并计算它们的逐元素积并将结果存储到共享内存中,然后将结果通过对共享内存中所有元素求和的方式计算出单个块的点积。每个线程块输出一个部分点积,并将其存储在输出数组z中。
第二阶段(dot_stg_2):该函数将使用 dot_stg_1 函数计算的局部点积合并成一个全局点积,并将该结果存储在输出数组y的第一个元素中。同样,该函数也使用了共享内存和线程同步的优化方法。
第三阶段(dot_stg_3):由于计算出的全局点积可能大于一个块能够存储的最大内存,因此需要进一步对结果进行规约。该函数将使用 dot_stg_2 函数计算出的全局点积,并将其存储在输入数组x的第一个元素中。然后,使用共享内存和线程同步将输入数组x中的所有元素求和,得到最终的点积值。
通过将计算分为三个阶段,可以在不增加计算时间的情况下,减少数据传输次数和内存访问次数,从而更好地利用 CUDA GPU 的并行计算能力,提高计算效率。
使用__syncthreads()函数,同步所有线程的执行,是每个块里的线程吗,每个块这里的tid都是每个块里的局部编号吗
您的理解是正确的。在CUDA编程中,__syncthreads()函数用于将线程块中的所有线程同步,也可以说是一个线程块级别的同步函数。当程序执行到这个函数时,会等待该线程块内的所有线程都到达__syncthreads()的位置之后才能继续往后执行。
在每个线程块中,每个线程都有一个本地ID(local ID),通常称为tid。这个tid变量的取值范围是从0到线程块大小(blockDim.x)减1。在代码中,我们使用tid < 128, tid < 64 和 tid < 32这三个if语句来组织线程对共享内存数据的规约操作。这些if语句只会让相应条件下的线程执行规约操作,其他线程则直接跳过。
因此,在这段代码中,__syncthreads()函数确保了在不同的if语句中,每个线程都已经完成了对sdata数组的规约操作,并确保共享内存中的数据已经被更新,以便在后续的规约操作中正确地累加计算结果。
总之,__syncthreads()函数用于同步当前线程块内的所有线程,以便在共享内存中进行协作式的数据处理。每个线程都有一个本地ID,即tid,用于指示它在该块中的位置,并在代码中使用这些本地ID来组织数据处理操作。
全局的idx分到各个块中的tid
第三阶段是最后的整合,相当于把y中的所有的整合为一个,这里已经确定y的长度为255了,所以下面一个块够了
您的理解是正确的。在第三阶段中,我们已经将每个线程块中的局部点积结果累加到设备端全局内存y数组中了。由于每个线程块中有一个点积结果,所以 y 数组的长度应该等于线程块的数量。
因此,在第三阶段中,我们只需要使用一个线程块来将所有线程块的点积结果累加起来,得到最终的向量点积结果,并将结果存储在 y[0] 中即可。具体而言,我们定义一个只包含一个线程块的核函数dot_stg_3,这个线程块会对 y 数组中的所有元素执行并行求和操作,在 kernel 函数中使用类似于第二阶段中的线程规约操作来对 y 数据进行求和。
在整合的过程中,我们还可以通过分配更多的线程块或使用更高效的算法来实现更高效的计算。但是由于这个向量点积计算问题的规模相对较小,所以使用一个线程块来完成整个计算也足够快速和高效。
总之,在第三阶段中,我们将所有线程块中的点积结果累加起来,得到了最终的向量点积结果,并将其存储在 y[0] 中。这样,在主机端调用kernel函数后,就可以读取 y[0] 中的值,从而得到最终的点积结果。
这里是累加,相当于以128个元素为一组跨越,多个数加到同一个sdata【tid】,最后所以确保整体数目保持在128个